Руководство. Создание сквозного конвейера данных для получения аналитических сведений о продажах в Azure HDInsight
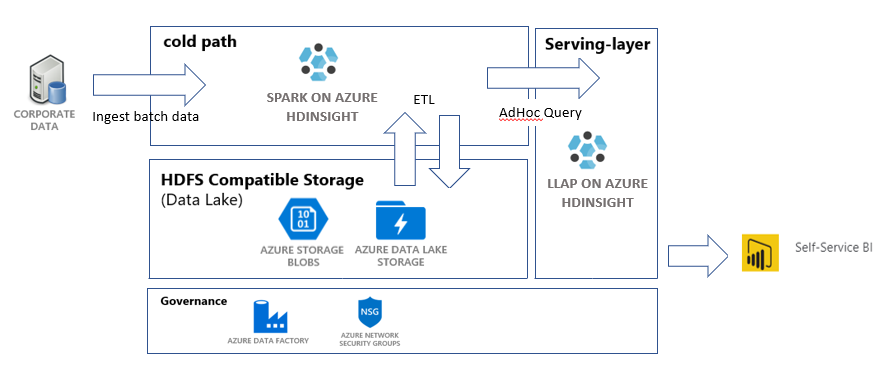
В этом учебнике вы создадите сквозной конвейер данных, который выполняет операции извлечения, преобразования и загрузки (ETL). Конвейер будет использовать кластеры Apache Spark и Apache Hive, работающие в Azure HDInsight, для запроса данных и управления ими. Вы также будете использовать технологии, которые включают Data Lake Storage 2-го поколения для хранения данных и Power BI для визуализации.
Этот конвейер данных объединяет данные из различных магазинов, удаляет ненужные данные, добавляет новые данные и загружает их все обратно в хранилище для визуализации бизнес-аналитики. Дополнительные сведения о конвейерах ETL см. в статье Extract, transform, and load (ETL) at scale (Извлечение, преобразование и загрузка (ETL) в масштабе).
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Необходимые компоненты
Azure CLI — версия не раньше 2.2.0. Подробнее см. статью Установка Azure CLI.
jq — обработчик командной строки JSON. См. раздел https://stedolan.github.io/jq/.
Если для активации конвейера Фабрики данных используется PowerShell, вам понадобится модуль Az.
Power BI Desktop для визуализации бизнес-аналитики в конце этого руководства.
Создание ресурсов
Клонирование репозитория со скриптами и данными
Войдите в подписку Azure. Если вы планируете использовать Azure Cloud Shell, щелкните Попробовать в правом верхнем углу блока кода. В противном случае введите следующую команду:
az login # If you have multiple subscriptions, set the one to use # az account set --subscription "SUBSCRIPTIONID"Убедитесь, что вы являетесь членом роли Azure Владелец. Замените
user@contoso.comсвоей учетной записью, а затем введите команду:az role assignment list \ --assignee "user@contoso.com" \ --role "Owner"Если запись не возвращается, вы не являетесь членом и не сможете завершить работу с этим руководством.
Скачайте данные и скрипты для этого учебника из репозитория ETL данных по продажам HDInsight. Введите следующую команду:
git clone https://github.com/Azure-Samples/hdinsight-sales-insights-etl.git cd hdinsight-sales-insights-etlУбедитесь, что
salesdata scripts templatesсозданы. Выполните проверку с помощью следующей команды:ls
Развертывание ресурсов Azure, необходимых для конвейера
Добавьте разрешения на выполнение для всех скриптов, введя:
chmod +x scripts/*.shЗадайте переменную для группы ресурсов. Замените
RESOURCE_GROUP_NAMEименем существующей или новой группы ресурсов, а затем введите команду:RESOURCE_GROUP="RESOURCE_GROUP_NAME"Выполните скрипт. Замените
LOCATIONжелаемым значением, а затем введите команду:./scripts/resources.sh $RESOURCE_GROUP LOCATIONЕсли вы не знаете, какой регион необходимо задать, можете получить список поддерживаемых регионов для своей подписки, выполнив команду az account list-locations.
Команда развернет следующие ресурсы:
- Учетной записи хранения BLOB-объектов Azure. Эта учетная запись будет содержать данные о продажах компании.
- Учетной записи Azure Data Lake Storage 2-го поколения. Эта учетная запись будет использоваться в качестве учетной записи хранения для обоих кластеров HDInsight. Дополнительные сведения об HDInsight и Data Lake Storage 2-го поколения см. в статье Azure HDInsight integration with Data Lake Storage Gen2 preview — ACL and security update (Интеграция Azure HDInsight с Data Lake Storage 2-го поколения (предварительная версия). Обновление ACL и системы безопасности).
- Управляемое удостоверение, назначаемое пользователем. Эта учетная запись предоставляет кластерам HDInsight доступ к учетной записи Data Lake Storage 2-го поколения.
- Кластер Apache Spark. Этот кластер будет использоваться для очистки и преобразования необработанных данных.
- Кластер Interactive Query Apache Hive. Этот кластер позволяет отправлять запросы к данным о продажах, визуализируя их с помощью Power BI.
- Виртуальная сеть Azure, поддерживаемая правилами группы безопасности сети (NSG). Эта виртуальная сеть позволяет кластерам обмениваться данными, а также защищать их связь.
Создание кластера может занять около 20 минут.
Пароль по умолчанию для доступа к кластерам по SSH — Thisisapassword1. Если вы хотите изменить пароль, перейдите к файлу ./templates/resourcesparameters_remainder.json и измените пароль для параметров sparksshPassword, sparkClusterLoginPassword, llapClusterLoginPassword и llapsshPassword.
Проверка развертывания и получение сведений о ресурсах
Если вы хотите проверить состояние развертывания, перейдите к группе ресурсов на портале Azure. В разделе Параметры выберите элемент Развертывания, а затем выберите нужное развертывание. Здесь можно просмотреть ресурсы, которые уже успешно развернуты и те ресурсы, которые еще выполняются.
Чтобы просмотреть имена кластеров, введите следующую команду:
SPARK_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.sparkClusterName.value') LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') echo "Spark Cluster" $SPARK_CLUSTER_NAME echo "LLAP cluster" $LLAP_CLUSTER_NAMEЧтобы просмотреть учетную запись хранения Azure и ключ доступа, введите следующую команду:
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value') blobKey=$(az storage account keys list \ --account-name $BLOB_STORAGE_NAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $BLOB_STORAGE_NAME echo $BLOB_KEYЧтобы просмотреть учетную запись Data Lake Storage 2-го поколения и ключ доступа, введите следующую команду:
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value') ADLSKEY=$(az storage account keys list \ --account-name $ADLSGEN2STORAGENAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $ADLSGEN2STORAGENAME echo $ADLSKEY
Создание фабрики данных
Фабрика данных Azure — это инструмент, помогающий автоматизировать Azure Pipelines. Это не единственный способ выполнить эти задачи, но он отлично подходит для их автоматизации. Дополнительные сведения о Фабрике данных Azure см. в документации по Фабрике данных Azure.
Эта Фабрика данных будет иметь один конвейер с двумя действиями:
- Первое действие скопирует данные из хранилища BLOB-объектов Azure в учетную запись хранения Data Lake Storage 2-го поколения для имитации приема данных.
- Второе действие будет преобразовывать данные в кластере Spark. Скрипт выполняет преобразование данных, удаляя ненужные столбцы. Он также добавляет новый столбец, который вычисляет доход, создаваемый одной транзакцией.
Чтобы настроить конвейер Фабрики данных Azure, выполните приведенную ниже команду. Вы по-прежнему должны находиться в каталоге hdinsight-sales-insights-etl.
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value')
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value')
./scripts/adf.sh $RESOURCE_GROUP $ADLSGEN2STORAGENAME $BLOB_STORAGE_NAME
Скрипт делает следующее:
- Создает субъект-службу с разрешениями
Storage Blob Data Contributorв учетной записи хранения Data Lake Storage 2-го поколения. - Получает токен проверки подлинности для авторизации запросов POST к REST API файловой системы Data Lake Storage 2-го поколения.
- Заполняет фактическое имя учетной записи хранения Data Lake Storage 2-го поколения в файлах
sparktransform.pyиquery.hql. - Получает ключи к хранилищу данных для учетной записи Data Lake Storage 2-го поколения и хранилища BLOB-объектов.
- Создает еще одно развертывание ресурсов для создания конвейера Фабрики данных Azure со связанными службами и действиями. Он передает ключи хранилища в качестве параметров в файл шаблона, чтобы связанные службы могли правильно получить доступ к учетным записям хранения.
Запуск конвейера данных
Активация действий Фабрики данных
Первое действие в созданном конвейере Фабрики данных перемещает данные из хранилища BLOB-объектов в Data Lake Storage 2-го поколения. Второе действие применяет преобразования Spark к данным и сохраняет преобразованные CSV-файлы в новом расположении. Выполнение всего конвейера может занять несколько минут.
Чтобы получить имя фабрики данных, введите следующую команду:
cat resourcesoutputs_adf.json | jq -r '.properties.outputs.factoryName.value'
Чтобы активировать конвейер, выполните одно из следующих действий:
Активируйте конвейер Фабрики данных в PowerShell. Замените
RESOURCEGROUPиDataFactoryNameсоответствующими значениями, а затем выполните следующие команды:# If you have multiple subscriptions, set the one to use # Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>" $resourceGroup="RESOURCEGROUP" $dataFactory="DataFactoryName" $pipeline =Invoke-AzDataFactoryV2Pipeline ` -ResourceGroupName $resourceGroup ` -DataFactory $dataFactory ` -PipelineName "IngestAndTransform" Get-AzDataFactoryV2PipelineRun ` -ResourceGroupName $resourceGroup ` -DataFactoryName $dataFactory ` -PipelineRunId $pipelineПовторно выполняйте
Get-AzDataFactoryV2PipelineRunпо мере необходимости для отслеживания хода выполнения.Or
Откройте фабрику данных и выберите Author & Monitor (Создание и мониторинг). Активируйте конвейер
IngestAndTransformна портале. Сведения о запуске конвейеров на портале см. в разделе Активация конвейера.
Чтобы убедиться, что конвейер запущен, выполните одно из следующих действий:
- Перейдите к разделу Мониторинг в фабрике данных с помощью портала.
- В Обозревателе службы хранилища Azure перейдите к учетной записи хранения Data Lake Storage 2-го поколения. Перейдите в файловую систему
files, а затем к папкеtransformedи проверьте ее содержимое, чтобы убедиться, что конвейер выполнен.
Другие способы преобразования данных с помощью HDInsight см. в этой статье об использовании Jupyter Notebook.
Создание таблицы в кластере интерактивных запросов для просмотра данных в Power BI
Скопируйте файл
query.hqlв кластер LLAP с помощью SCP. Введите команду :LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') scp scripts/query.hql sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.net:/home/sshuser/Напоминание. Пароль по умолчанию имеет значение
Thisisapassword1.Используйте SSH для доступа к кластеру LLAP. Введите команду :
ssh sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.netВыполните следующую команду, чтобы запустить скрипт.
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -f query.hqlЭтот скрипт создаст управляемую таблицу в кластере интерактивных запросов, к которому можно получить доступ из Power BI.
Создание информационной панели Power BI на основе данных о продажах
Запустите Power BI Desktop.
В меню выберите Получить данные>Другие...>Azure>HDInsight Interactive Query.
Нажмите Подключиться.
В диалоговом окне HDInsight Interactive Query сделайте следующее:
- В текстовом поле Сервер введите имя кластера LLAP в формате
https://LLAPCLUSTERNAME.azurehdinsight.net. - В текстовом поле База данных введите
default. - Нажмите ОК.
- В текстовом поле Сервер введите имя кластера LLAP в формате
В диалоговом окне AzureHive сделайте следующее:
- В текстовом поле Имя пользователя введите
admin. - В текстовом поле Пароль введите
Thisisapassword1. - Нажмите Подключиться.
- В текстовом поле Имя пользователя введите
В поле Навигатор выберите
salesи (или)sales_rawдля предварительного просмотра данных. После загрузки данных можно поэкспериментировать с информационной панелью, которую вы хотите создать. Дополнительные сведения о начале работы с информационными панелями Power BI см. по следующим ссылкам:
- Общие сведения о панелях мониторинга для разработчиков Power BI
- Руководство. Начало работы с служба Power BI
Очистка ресурсов
Если вы не собираетесь использовать это приложение, удалите все ресурсы, выполнив следующую команду, чтобы избежать необходимости оплаты.
Чтобы удалить группу ресурсов, введите такую команду:
az group delete -n $RESOURCE_GROUPЧтобы удалить субъект-службу, введите такие команды:
SERVICE_PRINCIPAL=$(cat serviceprincipal.json | jq -r '.name') az ad sp delete --id $SERVICE_PRINCIPAL
Следующие шаги
Extract, transform, and load (ETL) at scale (Извлечение, преобразование и загрузка (ETL) в масштабе)