Руководство по Комплексное решение с помощью машинного обучения Azure и IoT Edge
Область применения:![]() IoT Edge 1.1
IoT Edge 1.1
Важно!
IoT Edge 1.1 дата окончания поддержки — 13 декабря 2022 г. Чтобы получить сведения о поддержке определенного продукта, службы, технологии или API, перейдите на страницу Политика жизненного цикла поддержки Майкрософт. Дополнительные сведения об обновлении до последней версии IoT Edge см. в разделе Обновление IoT Edge.
Часто приложениям IoT нужно воспользоваться преимуществами умного облака и интеллектуальной границы. Это руководство содержит основные сведения об обучении модели машинного обучения с помощью данных, собранных из устройств Интернета вещей в облаке, развертывании этой модели в IoT Edge и периодической поддержке и уточнении модели.
Примечание
Понятия, описанные в этой серии руководств, применяются ко всем версиям IoT Edge, но на примере устройства, созданного для пробного использования сценария, выполняется IoT Edge версии 1.1.
Основной целью данного руководства является представление обработки данных Интернета вещей с помощью машинного обучения, в частности на пограничных устройствах. Хотя в этом руководстве затрагиваются многие аспекты общего рабочего процесса машинного обучения, оно не предназначено для использования в качестве подробных основных сведений о машинном обучении. В качестве примера мы не пытаемся создать высокооптимизируемую модель для этого варианта использования. Мы просто достаточно, чтобы проиллюстрировать процесс создания и использования жизнеспособной модели для обработки данных Интернета вещей.
В этом разделе учебника рассматриваются следующие темы:
- Необходимые условия для работы с последующими частями учебника.
- Целевая аудитория учебника.
- Вариант использования, описываемый в учебнике.
- Общий процесс для реализации такого варианта.
Если у вас еще нет подписки Azure, создайте бесплатную учетную запись Azure, прежде чем начать работу.
Предварительные требования
Чтобы завершить обучение, необходим доступ к подписке Azure, в которой у вас есть права на создание ресурсов. Несколько служб, используемые в этом руководстве, будут взимать плату за Azure. Если у вас еще нет подписки Azure, можно приступить к работе с помощью бесплатной учетной записи Azure.
Вам также потребуется компьютер с установленным PowerShell, в котором можно запускать сценарии, чтобы установить виртуальную машину Azure в качестве компьютера, на котором ведется разработка.
В этом документе мы будем использовать следующий набор средств:
центр Интернета вещей Azure для сбора данных;
Azure Notebooks в качестве основного интерфейса для подготовки данных и экспериментов с машинным обучением; Выполнение кода Python в записной книжке для подмножества примеров данных — это отличный способ быстрой итеративной и интерактивной обработки во время подготовки данных. Чтобы подготовить сценарии для запуска в масштабе в серверной части вычислений, можно также использовать записные книжки Jupyter.
Машинное обучение Azure в качестве серверной части для машинного обучения в масштабе, а также для создания образа в машинном обучении. Мы используем серверную часть машинного обучения Azure, с помощью сценариев, подготовленных и протестированных в записных книжках Jupyter.
Azure IoT Edge для применения образа виртуальной машины обучения вне облака
Очевидно, есть и другие доступные варианты. Например в некоторых сценариях, IoT Central можно использовать в качестве альтернативы, без необходимости написания кода для записи начальных данных обучения из устройств Интернета вещей.
Целевая аудитория и роли
Этот набор статей предназначен для разработчиков без опыта разработки для Интернета вещей или машинного обучения. Развертывание в машинном обучении на завершающем этапе требует набор знаний о способе подключения широкого ряда технологий. Таким образом в этом руководстве рассматривается весь комплексный сценарий, демонстрирующий один из способов объединения этих технологий для решения Интернета вещей. В реальной среде эти задачи могут быть распределены между несколькими людьми с разными специализациями. Например разработчики будут сосредоточены на коде устройства или облака, в то время как специалисты по анализу данных будут создавать модели аналитики. Чтобы гарантировать успешное завершения этого учебника индивидуальными разработчиками, мы представили дополнительные рекомендации с помощью полезных сведений и ссылок на дополнительные сведения, которые, как мы надеемся, достаточны для понимания того, что делается и почему.
В качестве альтернативы, вы можете объединиться с коллегами с разными ролями, чтобы вместе проходить учебник, используя ваш общий опыт, и, будучи командой, узнать, как взаимодействуют вещи.
В любом случае, чтобы помочь читателю сориентироваться, каждая статья в этом руководстве указывает роль пользователя. Существуют такие роли.
- Разработка в облаке (включая разработку в облаке, которая работает в емкости DevOps)
- аналитика данных.
Вариант использования. Прогнозное обслуживание
Мы основали этот сценарий на примере использования, представленном на "Конференции по прогнозированию и управлению здравоохранением" (PHM08) в 2008 году. Цель состоит в том, чтобы предсказать оставшийся срок полезного использования (RUL) набора турбовентиляторных авиационных двигателей. Эти данные были созданы с помощью C-MAPSS, коммерческой версии программного обеспечения MAPSS (Эмулятор модульной аэродвигательной установки). Это программное обеспечение предоставляет гибкую среду моделирования турбовентиляторного двигателя для удобного моделирования работоспособности, управления и параметров двигателя.
Данные, используемые в этом руководстве берутся из набора данных для симуляции деградации турбореактивного двигателя.
Из файла сведений.
Экспериментальные навыки
Наборы данных состоят из нескольких многомерных временных рядов. Каждый набор данных дополнительно разделен на подмножества для обучения и тестирования. Каждый временный ряд относится к другому двигателю, т. е. данные можно считать из парка двигателей того же типа. Каждый двигатель начинает работу с разной степенью начального износа и производственных допусков, которые неизвестны пользователю. Этот износ и отклонение находится в пределе нормы, то есть не считается неисправным состоянием. Существуют три рабочие настройки, которые существенно влияют на производительность двигателя. Эти параметры также являются частью данных. Данные загрязнены шумом датчика.
Двигатель работает в обычном режиме в начале каждого временного ряда и в какой-то момент во время ряда возникает неисправность. В наборе данных для обучения сбой разрастается, пока не достигнет сбоя системы. В тестовом наборе временные ряды завершаются перед сбоем системы. Цель соревнования — спрогнозировать количество оставшихся рабочих циклов до появления ошибки в тестовом наборе, то есть количество рабочих циклов после последнего цикла, во время которого двигатель будет работать. Здесь также предоставляется вектор значений true для оставшегося срока полезного использования (RUL) для тестовых данных.
Поскольку данные были опубликованы для соревнования, несколько подходов к получению моделей машинного обучения были опубликованы независимо друг от друга. Мы обнаружили, что примеры обучения полезные для понимания процесса и определения, которые являются частью создания конкретной модели обучения. Например, ознакомьтесь со следующими статьями:
Модель прогнозирования сбоев авиадвигателя пользователя GitHub с именем jancervenka.
Ухудшение характеристик турбовентиляторного двигателя пользователя GitHub с именем hankroark.
Процесс
На рисунке ниже показаны приблизительные шаги, которым мы следуем в этом руководстве:
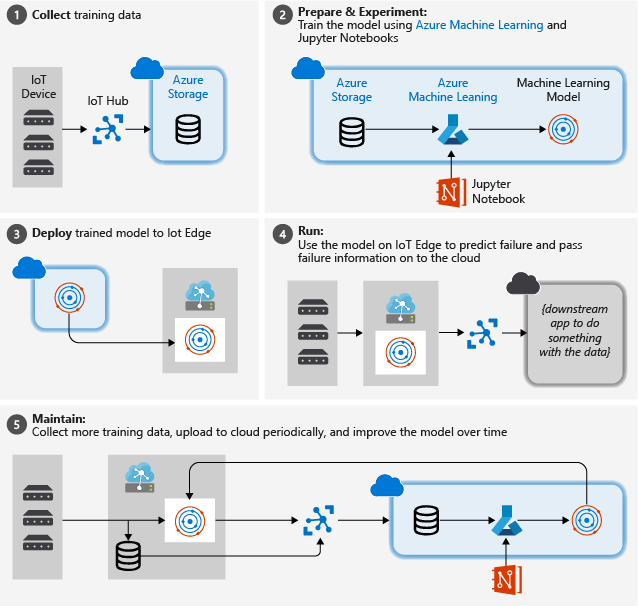
Сбор данных для обучения. Процесс начинается со сбора данных для обучения. В некоторых случаях данные уже были собраны и теперь доступны в базе данных или в виде файлов данных. В других случаях, особенно для сценариев Интернета вещей, данные должны быть собраны из устройств и датчиков Интернета вещей и хранится в облаке.
Мы предполагаем, что вы не имеете коллекцию турбовентиляторных двигателей, поэтому файлы проекта содержат простой симулятор устройств, который отправляет данные устройства NASA в облако.
Подготовка данных. В большинстве случаев, необработанные данные, собранные с устройств и датчиков, потребуют подготовку для машинного обучения. Этот этап может включать очистку или переформатирование данных, а также предварительную обработку для добавления дополнительной информации, которую машинное обучение может выключить.
Для наших данных компьютера авиадвигателя, подготовка данных включает в себя расчет явного времени до сбоя для каждой точки данных в образце на основе фактических наблюдений за данными. Эта информация позволяет алгоритму машинного обучения находить корреляции между фактическими шаблонами данных датчика и ожидаемым оставшимся временем работоспособности двигателя. Этот шаг сильно зависит от домена.
Создание модели машинного обучения. Теперь, на основе подготовленных данных, мы можем экспериментировать с различными алгоритмами машинного обучения и параметризацией, чтобы обучать модели и сравнивать их результаты.
В этом случае для тестирования мы сравним прогнозируемый результат, который вычисляется с помощью модели с реальным результатом, наблюдаемым на наборе двигателей. В машинном обучении Azure можно выполнять управление итерациями моделей, которые создаются в реестре модели.
Развертывание модели. После создания модели, которая соответствует нашим показателям эффективности, можно перейти к развертыванию. Оно включает в себя превращение модели в приложение веб-службы, которое может использовать данные с помощью вызовов REST и возвращать результаты анализа. Приложение веб-службы затем упаковывается в контейнер docker, который в свою очередь можно развернуть в облаке либо в качестве модуля IoT Edge. В этом примере рассматривается развертывание на IoT Edge.
Техническое обслуживание и оптимизация модели. После развертывания модели наша работа не прекращается. В большинстве случаев мы хотим продолжить сбор данных и периодически отправлять эти данные в облако. Затем эти данные можно использовать для повторного обучения и оптимизации нашей модели, которую затем можно повторно развернуть в IoT Edge.
Очистка ресурсов
Этот учебник является частью серии статей, каждая из которых продолжает предыдущую. Не очищайте ресурсы, пока не завершите работу с последним учебником.
Дальнейшие действия
Этот учебник состоит из следующих разделов.
- Настройка компьютера разработки и служб Azure
- Создание данных обучения для модуля машинного обучения.
- Обучение и развертывание модуля машинного обучения.
- Настройка устройства IoT Edge для использования в качестве прозрачного шлюза
- Создание и развертывание модулей IoT Edge
- Отправка данных к устройству IoT Edge
Перейдите к следующей статье, чтобы настроить компьютер для разработки и подготовки ресурсов Azure.