Выбор признаков с помощью фильтра
В этой статье описано, как использовать компонент выбора признаков на основе фильтра в конструкторе Машинного обучения Azure. Этот компонент помогает определить во входном наборе данных столбцы с наибольшей прогнозной значимостью.
Как правило, выбор признаков обозначает процесс применения статистических тестов к входным данным с учетом конкретных выходных данных. Цель состоит в том, чтобы определить столбцы, которые позволяют лучше других спрогнозировать эти выходные данные. Компонент выбора признаков на основе фильтра предоставляет несколько алгоритмов выбора признаков. Данный компонент включает такие методы корреляции, как корреляция Пирсона и значения хи-квадрат.
При работе с компонентом выбора признаков на основе фильтра вы предоставляете набор данных и определяете столбец, который содержит метку или зависимую переменную. Затем вы выбираете один из методов, который будет применяться для оценки важности признака.
Компонент выводит набор данных, который содержит столбцы признаков, ранжированные по их прогнозной значимости. Также он выводит имена признаков и их оценки из выбранной метрики.
Что такое выбор признаков на основе фильтра
Этот компонент выбора признаков имеет в названии формулировку "на основе фильтра", так как выбранная метрика позволяет определить нерелевантные атрибуты. Затем эти ненужные столбцы отфильтровываются из модели. Вы выбираете одну статистическую меру, которая соответствует вашим данным, и компонент вычисляет оценку для каждого столбца признаков. В выходных данных столбцы ранжируются по оценке соответствующих признаков.
Выбрав нужные компоненты, вы можете увеличить точность и эффективность классификации.
Для создания прогнозной модели обычно используются только столбцы с лучшими оценками. Столбцы с низкими оценками выбора признака можно сохранить в наборе данных и игнорировать при создании модели.
Как правильно выбрать метрику выбора признаков
Компонент выбора признаков на основе фильтра предоставляет много разных метрик для оценки информационного значения в каждом столбце. В этом разделе приводится общее описание каждой метрики и способ ее применения. Дополнительные требования для каждой метрики см. в технических примечаниях и инструкциях по настройке каждого компонента.
Корреляция Пирсона
Статистика корреляции Пирсона (коэффициент корреляции Пирсона) также известна в статистическом моделировании как значение
r. Для двух любых переменных он возвращает значение, показывающее степень корреляции.Коэффициент корреляции Пирсона вычисляется путем деления ковариации двух переменных на произведение их стандартных отклонений. Изменение масштаба в двух переменных не влияет на этот коэффициент.
Хи-квадрат
Двустороннее тестирование хи-квадрат является статистическим методом, позволяющим измерить, насколько фактические результаты близки к ожидаемым значениям. Метод предполагает, что переменные случайны и получены из подходящей выборки независимых переменных. Полученная статистика хи-квадрат указывает, насколько отличаются результаты от ожидаемых (случайных) результатов.
Совет
Если вам нужен другой метод выбора настраиваемых признаков, воспользуйтесь компонентом Выполнение скрипта R.
Настройка выбора признаков на основе фильтра
Вы выбираете стандартную статистическую метрику. Компонент рассчитывает корреляцию между парой столбцов: столбца меток и столбца признаков.
Добавьте в конвейер компонент выбора признаков на основе фильтра. Его можно найти в категории Feature Selection (Выбор признаков) в конструкторе.
Подключите входной набор данных, который содержит по крайней мере два столбца, которые потенциально являются признаками.
Чтобы выполнить анализ столбца и сформировать оценку признаков, примените компонент Edit Metadata (Изменение метаданных) для создания атрибута IsFeature (Является признаком).
Важно!
Убедитесь, что предоставленные в качестве входных данных столбцы потенциально являются признаками. Например, столбец с одним значением во всех строках не имеет информационного значения.
Если заранее известно, что некоторые столбцы плохо подходят на роль признаков, их можно удалить на этапе выбора столбцов. Можно также с помощью компонента Изменение метаданных пометить их как категориальные.
В разделе Feature scoring method (Метод оценки признаков) выберите один из готовых статистических методов для вычисления оценок.
Метод Требования Корреляция Пирсона Метка может быть текстовой или числовой. Признаки должны быть числовыми. Хи-квадрат Метки и компоненты могут быть текстовыми или числовыми. Используйте этот метод для вычисления важности признаков для двух категориальных столбцов. Совет
Если вы измените выбор метрики, будут сброшены и все остальные параметры. Поэтому сначала установите именно этот параметр.
Выберите вариант Operate on feature columns only (Работа только со столбцами признаков), чтобы создать оценку только для столбцов, которые ранее были отмечены как признаки.
Если вы снимете этот флаг, компонент создаст оценку для всех столбцов, которые соответствуют остальным заданным условиям, вплоть до числа Number of desired features (Количество требуемых признаков).
В поле Target column (Целевой столбец) выберите вариант Launch column selector (Запустить средство выбора столбцов), чтобы выбрать столбец с метками по его имени или индексу. (Значения индексов начинаются с единицы.)
Столбец меток является обязательным для всех методов, которые используют статистическую корреляцию. Компонент возвращает ошибку времени разработки, если вы не выберете столбец меток или выберете несколько столбцов меток.В поле Number of desired features (Количество требуемых признаков) введите число столбцов, которое вы хотите получить в результате:
Минимально допустимое количество признаков — 1, но мы рекомендуем увеличить это значение.
Если указанное число необходимых компонентов больше, чем количество столбцов в наборе данных, возвращаются все компоненты. Возвращаются даже признаки с нулевыми оценками.
Если вы укажете меньше столбцов результатов, чем будет обнаружено столбцов признаков, признаки будут ранжированы по убыванию оценки. Возвращаются только признаки с наивысшими значениями.
Отправьте конвейер.
Важно!
Если вы хотите использовать для вывода выбор признаков на основе фильтра, вам потребуются модули Select Columns Transform (Преобразование выбора столбцов) для хранения выбранного результата и Apply Transformation (Применение преобразования) для применения выбранного преобразования к набору данных для оценки.
Чтобы создать конвейер, воспользуйтесь следующим снимком экрана, чтобы для процесса оценки использовать тот же выбор столбцов.
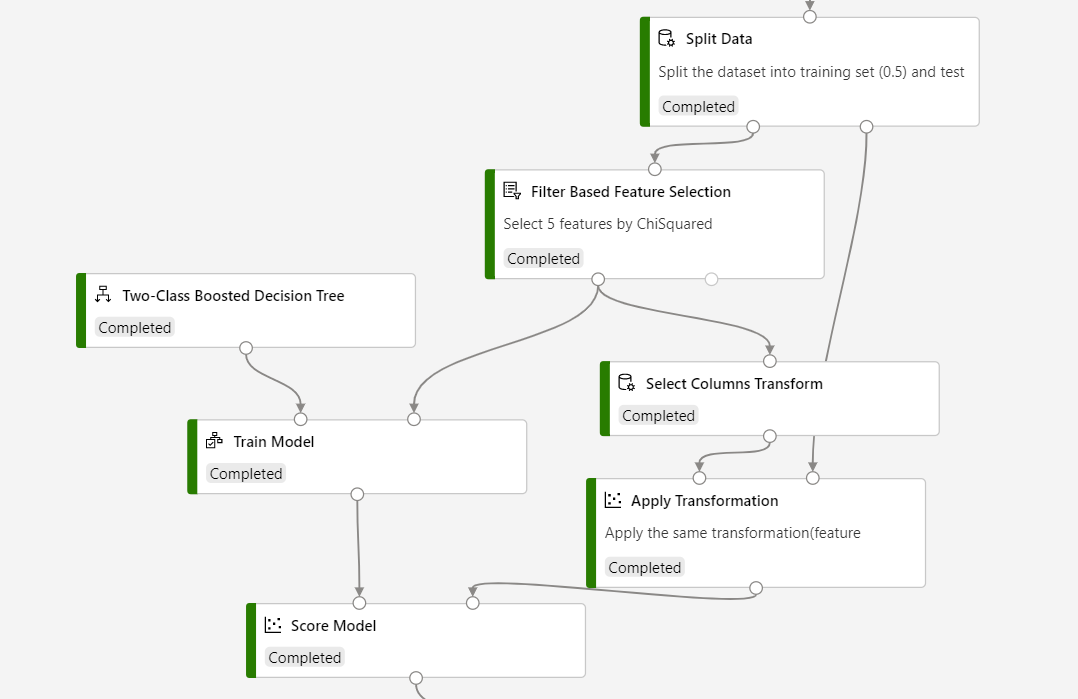
Результаты
Когда обработка будет завершена, сделайте следующее:
Чтобы просмотреть полный список проанализированных столбцов признаков с соответствующими оценками, щелкните компонент правой кнопкой мыши и выберите Visualize (Визуализировать).
Чтобы просмотреть набор данных, созданный по вашим критериям выбора признаков, щелкните компонент правой кнопкой мыши и выберите Visualize (Визуализировать).
Если этот набор данных содержит меньше столбцов, чем ожидалось, проверьте параметры компонента. Также проверьте типы данных столбцов, предоставленных в качестве входных. Например, если параметр Number of desired features (Количество требуемых признаков) имеет значение 1, выходной набор данных будет содержать только два столбца: столбец меток и столбец признаков с самым высоким значением.
Технические примечания
Сведения о реализации
При использовании корреляции Пирсона по числовому признаку и категориальной метке оценка признаков вычисляется следующим образом:
Для каждого уровня в категориальном столбце вычисляется условное среднее значение числового столбца.
Столбец условных средних значений сопоставляется с числовым столбцом.
Требования
Оценка выбора признаков не создается для тех столбцов, которые имеют обозначение Label (Метка) или Score (Оценка).
Если применить метод оценки для столбца с неподдерживаемым типом данных, компонент сгенерирует ошибку. Также возможно, что столбцу будет назначено нулевое значение оценки.
Если столбец содержит логические значения (true/false), они обрабатываются как
True = 1иFalse = 0.Столбец не может считаться признаком, если он имеет обозначение Label (Метка) или Score (Оценка).
Как обрабатываются отсутствующие значения
Вы не можете указать в качестве целевого (метка) такой столбец, в котором отсутствуют все значения.
Если в столбце отсутствуют значения, компонент игнорирует их при вычислении оценки для этого столбца.
Если в столбце, который обозначен как столбец признаков, отсутствуют все значения, ему присваивается нулевая оценка.
Следующие шаги
Ознакомьтесь с набором доступных компонентов для Машинного обучения Azure.