Компонент "Секционирование и выборка"
В этой статье описывается компонент в конструкторе Машинного обучения Azure.
С помощью компонента "Секционирование и выборка" вы можете сделать выборку по набору данных или создать из него секции.
Выборка — это важный инструмент машинного обучения, так как она позволяет уменьшить размер набора данных, сохранив пропорцию значений. Этот компонент поддерживает несколько связанных задач, которые важны для машинного обучения.
Разделение данных на несколько подразделов одинакового размера.
Секции можно использовать для перекрестной проверки или назначения вариантов случайным группам.
Разделение данных на группы и последующая обработка данных из определенной группы.
После случайного назначения вариантов разным группам может потребоваться изменить признаки, связанные только с одной группой.
Выборка.
Вы можете извлечь процент данных, применить случайную выборку или выбрать столбец для использования при балансировке набора данных и выполнить стратифицированную выборку его значений.
Создание набора данных меньшего размера для тестирования.
Если данных очень много, может потребоваться использовать только первые n строк при настройке конвейера, а затем переключиться на полный набор данных при построении модели. Можно также использовать выборку, чтобы создать меньший набор данных для разработки.
Настройка компонента
Этот компонент поддерживает следующие методы для разделения данных на секции или для выборки. Сначала выберите метод, а затем задайте дополнительные параметры.
- Head
- Дискретизация
- Назначение по сверткам
- Выбрать свертку
Получить ПЕРВЫЕ N строк из набора данных
Используйте этот режим, чтобы получить только первые n строк. Этот параметр полезен, если нужно протестировать конвейер на небольшом количестве строк и данные не требуется балансировать или отбирать.
Добавьте модуль Секционирование и выборка в конвейер в интерфейсе и подключите набор данных.
Режим секционирования или выборки: установите для этого параметра значение Head.
Количество строк для выбора: введите количество возвращаемых строк.
Количество строк должно быть неотрицательным целым числом. Если количество выбранных строк превышает количество строк в наборе данных, возвращается весь набор данных.
Отправьте конвейер.
Компонент выводит один набор данных, содержащий только указанное количество строк. Строки всегда считываются из верхней части набора данных.
Создание образца данных
Этот параметр поддерживает простую случайную выборку или стратифицированную случайную выборку. Это полезно, если вы хотите создать репрезентативную выборку набора данных меньшего размера для тестирования.
Добавьте компонент Секционирование и выборка в конвейер и подключите набор данных.
Режим секционирования или выборки: установите для этого параметра значение Выборка.
Частота выборки: введите значение от 0 до 1. Это значение определяет процент строк из исходного набора данных, которые должны быть включены в выходной набор.
Например, если требуется только половина исходного набора данных, введите
0.5, чтобы указать, что частота выборки должна составлять 50 процентов.Строки входного набора данных перемещаются в случайном порядке и выбираются в выходном наборе данных в соответствии с указанным соотношением.
Случайное начальное значение для выборки: при необходимости введите целое число, которое будет использоваться в качестве начального значения.
Этот параметр важен, если нужно, чтобы строки были распределены одинаково каждый раз. Значение по умолчанию — 0. Это означает, что начальное значение генерируется на основе системного времени. Это значение может привести к отличающимся результатам при каждом запуске конвейера.
Стратифицированное разбиение для выборки: выберите этот параметр, если важно, чтобы строки в наборе данных были равномерно распределены по определенному ключевому столбцу перед выборкой.
Для Ключевой столбец стратификации для выборки выберите один столбец стратификации, который будет использоваться при делении набора данных. Строки в наборе данных делятся следующим образом.
Все входные строки группируются (стратифицируются) по значениям в столбце стратификации.
строки перемешиваются внутри каждой группы;
каждая группа выборочно добавляется в выходной набор данных в соответствии с указанной пропорцией.
Отправьте конвейер.
При использовании этого параметра компонент выводит один набор данных, содержащий репрезентативную выборку данных. Оставшаяся часть набора данных, не попавшая в выборку, не выводится.
Разделение данных на секции
Используйте этот параметр, если необходимо разделить набор данных на подмножества. Этот параметр также полезен, если необходимо создать пользовательское число сверток для перекрестной проверки или разделить строки на несколько групп.
Добавьте компонент Секционирование и выборка в конвейер и подключите набор данных.
Для параметра Режим секционирования или выборки выберите Назначение по сверткам.
Использование замены в секционировании: выберите этот параметр, если необходимо вернуть выборку строки в пул строк для возможного повторного использования. В результате одна и та же строка может быть назначена нескольким сверткам.
Если не использовать замену (параметр по умолчанию), то строка выборки не помещается обратно в пул строк для потенциального повторного использования. В результате каждая строка может быть назначена только одной свертке.
Случайное разбиение: выберите этот параметр, чтобы строки были назначены для свертывания случайным образом.
Если этот параметр не выбран, строки будут назначаться сверткам методом циклического перебора.
Случайное начальное значение: при необходимости введите целое число, которое будет использоваться в качестве начального значения. Этот параметр важен, если нужно, чтобы строки были распределены одинаково каждый раз. В противном случае используется значение по умолчанию (0), то есть начальное значение будет случайным.
Укажите метод секционирования: укажите способ распределения данных по каждой секции, используя следующие параметры.
Равномерное секционирование: используйте этот параметр, чтобы разместить одинаковое количество строк в каждой секции. Чтобы указать количество выходных секций, введите целое число в поле Укажите количество сверток для равномерного разбиения.
Разделение с настроенными пропорциями: используйте этот параметр, чтобы указать размер каждой секции в виде списка с разделителями-запятыми.
Например, необходимо создать три секции. Первая секция будет содержать 50 процентов данных. Остальные две секции будут содержать 25 процентов данных каждая. В поле Список пропорций, разделенный запятыми , введите следующие значения: 0,5, 0,25, 0,25.
Сумма всех размеров секций должна быть равна 1.
Если ввести числа, сумма которых меньше 1, создается дополнительная секция для хранения оставшихся строк. Например, если ввести значения 0,2 и 0,3, будет создана третья секция для хранения оставшихся 50 процентов всех строк.
Если ввести числа, сумма которых больше 1, при запуске конвейера возникает ошибка.
Стратифицированное разделение: выберите этот параметр, если нужно, чтобы строки были стратифицированы при разбиении, а затем выберите столбец стратификации.
Отправьте конвейер.
При использовании этого параметра компонент выводит несколько наборов данных. Наборы данных секционируются в соответствии с указанными правилами.
Использование данных из предопределенной секции
Используйте этот параметр, если набор данных разделен на несколько секций и теперь требуется загрузить каждую секцию для дальнейшего анализа или обработки.
Добавьте компонент Секционирование и выборка в конвейер.
Подключите компонент к выходным данным предыдущего экземпляра компонента Секционирование и выборка. Этот экземпляр должен использовать параметр Назначение по сверткам, чтобы создать некоторое количество секций.
Режим секционирования или выборки: выберите параметр Выбрать свертку.
Укажите свертку для выборки: выберите используемую секцию, введя ее индекс. Индексы секций начинаются с 1. Например, если набор данных делится на три части, то для секций будут существовать индексы 1, 2 и 3.
При вводе недопустимого значения индекса возникает ошибка времени разработки: "Ошибка 0018: набор данных содержит недопустимые данные".
Кроме группирования набора данных по сверткам, можно разделить набор данных на две группы: целевая свертка и все остальное. Для этого введите индекс одной свертки, а затем выберите параметр Выбор дополнения указанной свертки, чтобы получить все данные, кроме данных в указанной свертке.
Если вы работаете с несколькими секциями, необходимо добавить дополнительные экземпляры компонента Секционирование и выборка, чтобы обработать каждую секцию.
Например, для компонента Секционирование и выборка во второй строке задано значение Назначение по сверткам, а для компонента в третьей строке — Выбрать свертку.
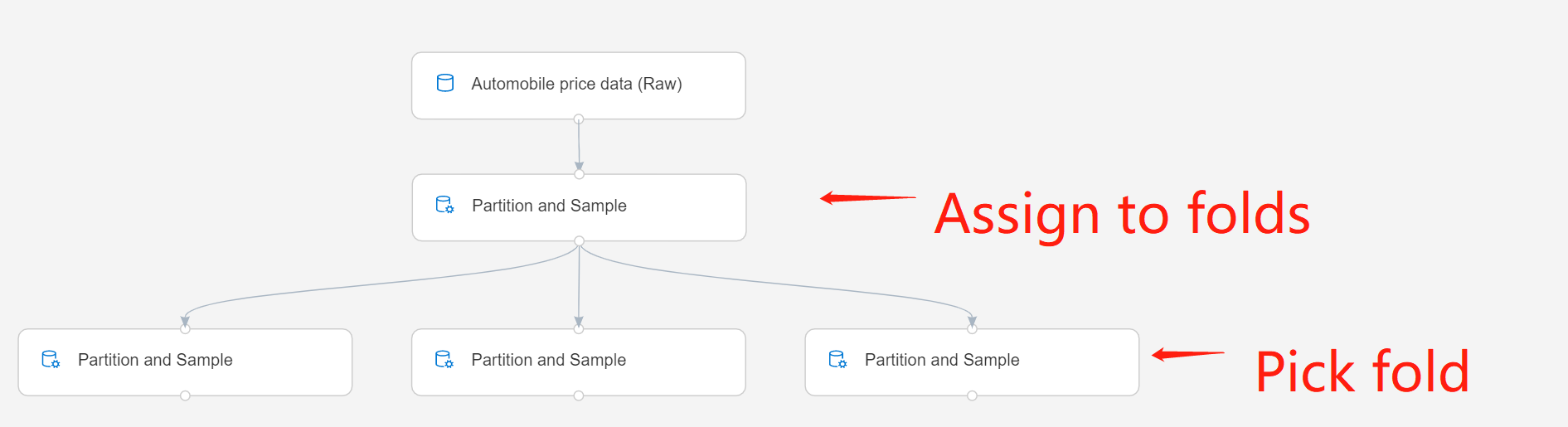
Отправьте конвейер.
При использовании этого параметра компонент выводит один набор данных, содержащий только те строки, которые были назначены этой свертке.
Примечание
Вы не можете просматривать назначенные свертки напрямую. Они представлены только в метаданных.
Дальнейшие действия
Ознакомьтесь с набором доступных компонентов для Машинного обучения Azure.