Обучение модели PyTorch
В этой статье объясняется, как с помощью компонента Обучение модели PyTorch в конструкторе Машинного обучения Azure обучать модели PyTorch, такие как DenseNet. Обучение выполняется после определения модели и установки ее параметров, а также требует наличия размеченных данных.
Сейчас компонент Обучение модели PyTorch поддерживает обучение в одном узле и распределенное обучение.
Как использовать модель "Обучение модели PyTorch"
Добавьте компонент DenseNet или ResNet в черновик конвейера в конструкторе.
Добавьте компонент Обучение модели PyTorch в конвейер. Вы можете найти этот компонент в категории Обучение модели. Раскройте узел Обучение и перетащите компонент Обучение модели PyTorch в свой конвейер.
Примечание
Для работы с большим набором данных компонент Обучение модели PyTorch лучше выполнять в вычислительном ресурсе типа GPU. Иначе может произойти сбой конвейера. Вы можете выбрать тип вычисления для конкретного компонента в правой области компонента, установив параметр Использовать другие целевые объекты вычислений.
В левой части входных данных присоедините необученную модель. Подключите набор данных для обучения и проверочный набор данных к среднему и правому вводу модуля Обучение модели PyTorch.
Для необученной модели нужно использовать такую модель PyTorch, как DenseNet. Иначе поступит сообщение об ошибке InvalidModelDirectoryError.
Для набора данных обучающий набор данных должен быть каталогом размеченных изображений. Сведения о том, как получить каталог размеченных изображений, см. в разделе Преобразование в каталог изображений. Если метки отсутствуют, будет сгенерировано исключение NotLabeledDatasetError.
Обучающий набор данных и проверочный набор данных имеют одинаковые категории меток, в противном случае будет сгенерировано исключение InvalidDatasetError.
Для параметра Эпохи укажите, сколько эпох вы хотите обучить. По умолчанию будет выполняться итерация всего набора данных в каждой эпохе, по умолчанию 5 эпох.
Для параметра Размера пакета укажите, сколько экземпляров следует обучить в пакете, по умолчанию 16.
Для параметра Warmup step number (Число шагов разогрева) укажите, в течение скольких эпох нужно выполнять разогрев для обучения, если его первоначальная скорость слишком высокая, чтобы начать схождение. По умолчанию установлено значение 0.
Для параметра Скорость обучения укажите соответствующее значение. По умолчанию это 0,001. Скорость обучения контролирует размер шага, который используется в оптимизаторе, например SGD, при каждом тестировании и корректировке модели.
При увеличении скорости модель проверяется чаще, но появляется риск блокировки на локальном плато. При увеличении шага схождение будет выполняться быстрее, но появляется риск превышения истинного минимума.
Примечание
Если при обучении для потерь выводится значение "не число", это может быть вызвано слишком высокой скоростью обучения. В таком случае уменьшите ее. При распределенном обучении для поддержания стабильности градиентного спуска фактическая скорость обучения рассчитывается по
lr * torch.distributed.get_world_size(), так как размер пакета группы процессов в несколько раз больше размера для одного процесса. Применяется полиномиальное затухание скорости обучения, что может улучшить результаты в более производительной модели.В параметре Случайное начальное значение дополнительно введите целое значение, которое будет использоваться в качестве начального значения. Рекомендуется использовать начальное значение, если вы хотите обеспечить воспроизводимость эксперимента между заданиями.
В параметре Выносливость укажите количество эпох для раннего завершения обучения, если потери при проверке не уменьшаются последовательно. Значение по умолчанию 3.
Для параметра Print frequency (Частота вывода) укажите частоту вывода журнала обучения для итераций в каждой эпохе. По умолчанию установлено значение 10.
Отправьте конвейер. Если ваш набор данных имеет больший размер, это займет некоторое время, поэтому рекомендуется использовать вычисление GPU.
Распределенное обучение
В распределенном обучении рабочая нагрузка для обучения модели разделяется и совместно используется несколькими мини-процессорами, называемыми рабочими узлами. Эти рабочие узлы работают параллельно, чтобы ускорить обучение модели. Сейчас конструктор поддерживает распределенное обучение для компонента Обучение модели PyTorch.
Время обучения
Распределенное обучение позволяет выполнять обучение больших наборов данных, например ImageNet (1000 классов, 1,2 млн изображений) всего за несколько часов с помощью модуля Обучение модели PyTorch. В представленной ниже таблице приведено время обучения и производительность при обучении для 50 эпох Resnet50 на ImageNet с нуля на основе различных устройств.
| Устройства | Время обучения | Пропускная способность обучения | Самая высокая точность проверки | Точность проверки в первой пятерке |
|---|---|---|---|---|
| 16 GPU V100 | 6 ч 22 мин | ~ 3200 изображений в секунду | 68,83 % | 88,84 % |
| 8 GPU V100 | 12 ч 21 мин | ~ 1670 изображений в секунду | 68,84 % | 88,74 % |
Щелкните вкладку метрик в этом компоненте и просмотрите графики метрик, например Train images per second (Обучение изображений в секунду) и Top 1 accuracy (Самая высокая точность).

Включение распределенного обучения
Чтобы включить распределенное обучение для компонента Обучение модели PyTorch, укажите параметры задания в области компонента справа. Распределенное обучение поддерживает только вычислительный кластер AML .
Примечание
Для активации распределенного обучения необходимо несколько GPU, так как компоненту "Обучение модели PyTorch" во внутреннем компоненте NCCL требуются ядра CUDA.
Выберите компонент и откройте панель справа. Разверните раздел Параметры задания.
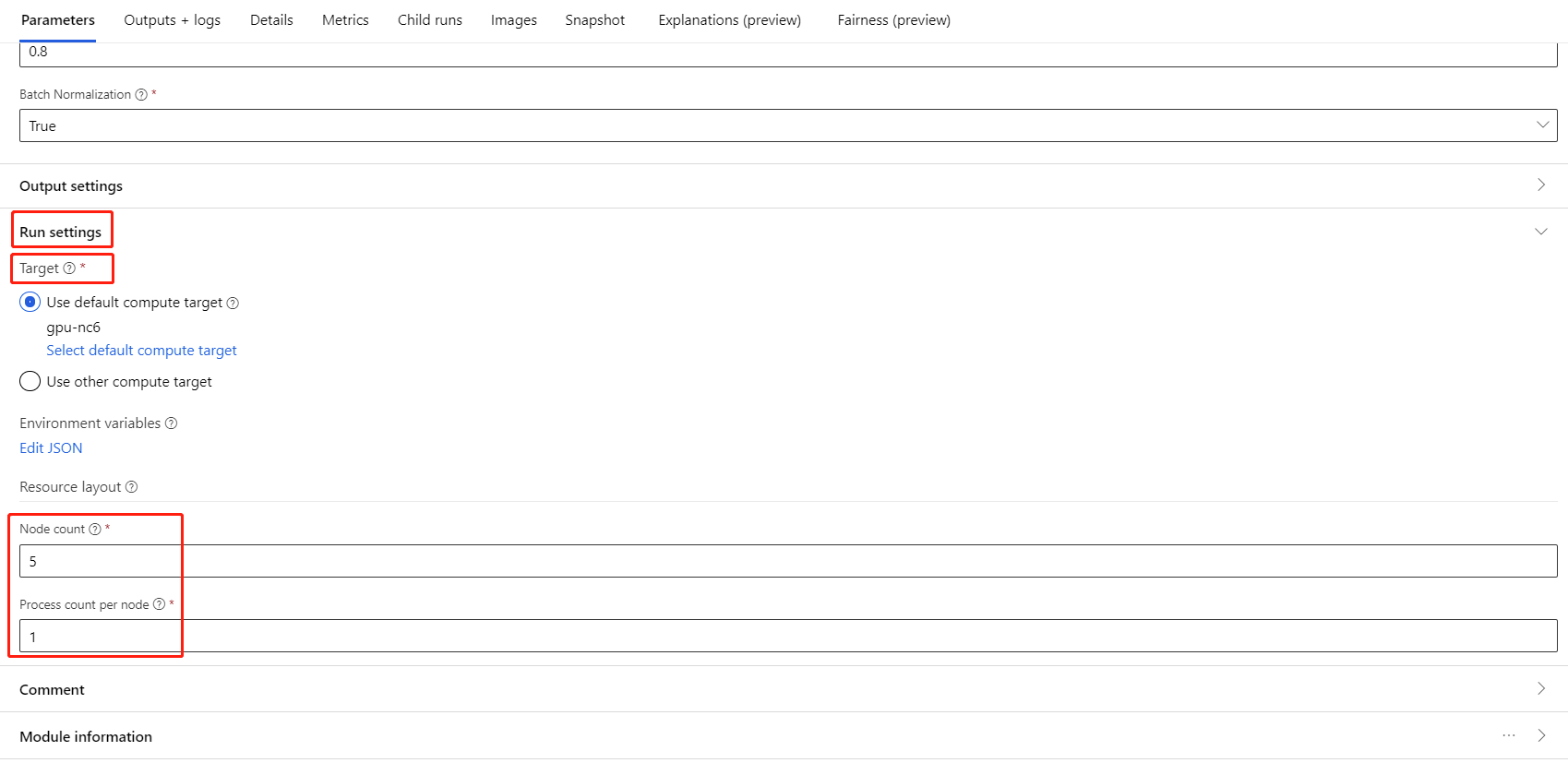
Убедитесь, что для целевого объекта вычислений выбрано вычисление AML.
В разделе Resource layout (Макет ресурса) нужно задать следующие значения:
Число узлов. Число узлов в целевом объекте вычислений, используемых для обучения. Значение должно быть меньше или равномаксимальному числу узлов в вашем вычислительном кластере. По умолчанию это 1, то есть задание выполняется в одном узле.
Process count per node (Количество процессов на узел). Количество процессов, запускаемых в узле. Значение должно быть меньше или равноединице обработки для вашего вычисления. По умолчанию это 1, то есть задание выполняется в одном процессе.
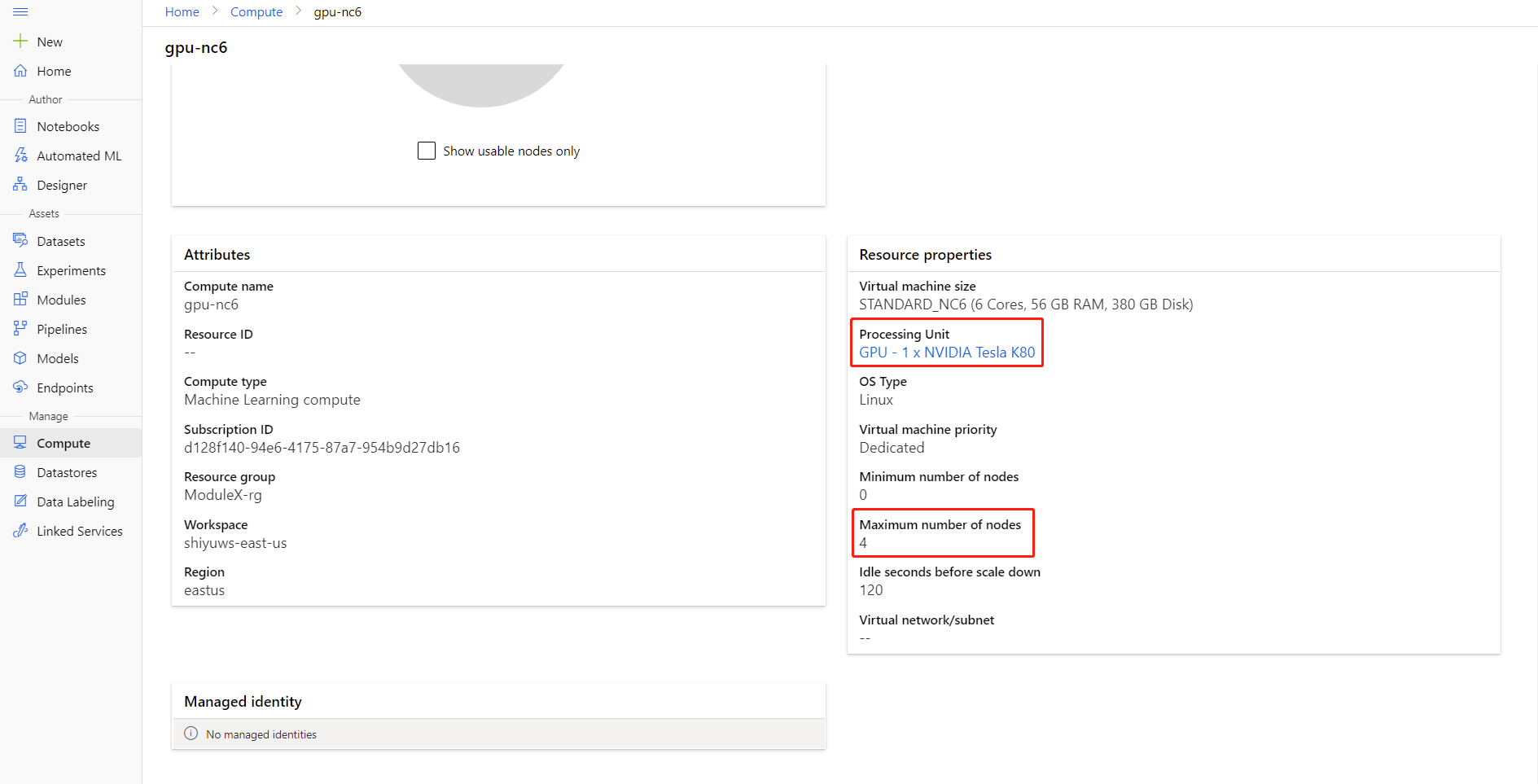
Чтобы просмотреть максимальное число узлов и единицу обработки вычисления, щелкните имя вычисления на странице сведений о нем.


Дополнительные сведения о распределенном обучении в Машинном обучении Azure см. здесь.
Устранение неполадок при распределенном обучении
Если вы включили распределенное обучение для этого компонента, по каждому процессу создаются журналы драйвера. 70_driver_log_0 ведется для главного процесса. В журналах драйвера вы можете просмотреть сведения об ошибках по каждому процессу. Для этого откройте вкладку Выходные данные и журналы в области справа.

Если распределенное обучение на основе компонента завершается сбоем без каких-либо журналов 70_driver, вы можете проверить 70_mpi_log на наличие сведений об ошибках.
В следующем примере показана распространенная ошибка, при которой число процессов на узел превышает единицу обработки для вычисления.

Дополнительные сведения об устранении неполадок с компонентом см. в этой статье.
Результаты
Когда задание конвейера завершит работу, подключите модуль Обучение модели PyTorch к модулю Оценка моделей изображений, чтобы использовать модель для оценки и спрогнозировать значения для новых входных данных.
Технические примечания
Ожидаемые входные данные
| Имя | Тип | Описание |
|---|---|---|
| Необученная модель | UntrainedModelDirectory | Необученная модель, требуется PyTorch |
| Обучающий набор данных | ImageDirectory | Обучающий набор данных |
| Набор данных для проверки | ImageDirectory | Проверочный набор данных для оценки каждой эпохи |
Параметры компонентов
| Имя | Диапазон | Тип | По умолчанию | Описание |
|---|---|---|---|---|
| Эпохи | >0 | Целочисленный тип | 5 | Выберите столбец, который содержит столбец метки или столбец результата |
| Размер пакета | >0 | Целочисленный тип | 16 | Количество экземпляров для обучения в пакете |
| Warmup step number (Число шагов разогрева) | >=0 | Целочисленный тип | 0 | Сколько эпох требуется для разогрева обучения |
| Скорость обучения | >=double.Epsilon | Тип с плавающей запятой | 0.1 | Начальная скорость обучения для оптимизатора понижения стохастического градиента. |
| Случайное начальное значение | Любой | Целое число | 1 | Начальное значение для генератора случайных чисел, используемого моделью. |
| Выносливость | >0 | Целочисленный тип | 3 | Количество эпох для раннего завершения обучения |
| Print frequency (Частота вывода) | >0 | Целое число | 10 | Частота вывода журналов обучения по итерациям в каждой эпохе |
Выходные данные
| Имя | Тип | Описание |
|---|---|---|
| Обученная модель | ModelDirectory | Обученная модель |
Дальнейшие действия
Ознакомьтесь с набором доступных компонентов для Машинного обучения Azure.