Обзор методов прогнозирования в AutoML
В этой статье рассматриваются методы, которые AutoML использует для подготовки данных временных рядов и построения моделей прогнозирования. Инструкции и примеры для обучения моделей прогнозирования в AutoML можно найти в нашей статье по настройке AutoML для прогнозирования временных рядов .
AutoML использует несколько методов для прогнозирования значений временных рядов. Эти методы могут быть примерно назначены двум категориям:
- Модели временных рядов, использующие исторические значения целевого количества для прогнозирования в будущем.
- Регрессия или пояснительные модели, использующие переменные прогнозатора для прогнозирования значений целевого объекта.
Например, рассмотрим проблему прогнозирования ежедневного спроса на конкретный бренд апельсинового сока из продуктового магазина. Пусть $y_t$ представляют спрос на этот бренд в день $t$. Модель временных рядов прогнозирует спрос на $t+1$ с помощью некоторой функции исторического спроса,
$y_{t+1} = f(y_t, y_{t-1}, \ldots, y_{t-s})$.
Функция $f$ часто имеет параметры, которые мы настраиваем с помощью наблюдаемого спроса с прошлого. Объем истории, который $f$ использует для прогнозирования, $s$, также можно рассматривать как параметр модели.
Модель временных рядов в примере спроса на оранжевый сок может быть недостаточно точной, так как она использует только информацию о прошлом спросе. Есть много других факторов, которые, вероятно, влияют на будущий спрос, такие как цена, день недели, и будь то праздник или нет. Рассмотрим модель регрессии, которая использует эти переменные прогнозатора,
$y = g(\text{price}, \text{день недели}, \text{holiday})$.
Опять же, $g$ обычно имеет набор параметров, включая те, которые управляют нормализацией, что AutoML настраивает с использованием прошлых значений спроса и прогнозаторов. Мы опущены $t$ из выражения, чтобы подчеркнуть, что модель регрессии использует корреляционные шаблоны между контемпорно определенными переменными для прогнозирования. То есть, чтобы предсказать $y_{t+1}$ от $g$, мы должны знать, какой день недели $t+1$ падает, будь то праздник, и цена апельсинового сока на день $t+1$. Первые два фрагмента информации всегда легко найти путем консультаций по календарю. Розничная цена обычно устанавливается заранее, поэтому цена апельсинового сока, вероятно, также известна в один день вперед. Однако цена может быть не известна в 10 дней в будущем! Важно понимать, что полезность этой регрессии ограничена тем, насколько далеко в будущем нам нужны прогнозы, также называемые горизонтом прогнозирования, и в какой степени мы знаем будущие значения прогнозаторов.
Важно!
Модели прогнозирования регрессии AutoML предполагают, что все функции, предоставляемые пользователем, известны в будущем, по крайней мере до горизонта прогнозирования.
Модели прогнозирования регрессии AutoML также можно дополнить для использования исторических значений целевых и прогнозаторов. Результатом является гибридная модель с характеристиками модели временных рядов и чистой регрессии. Исторические величины являются дополнительными переменными прогнозора в регрессии, и мы называем их отложенными количествами. Порядок задержки ссылается на то, как далеко назад известно значение. Например, текущее значение задержки заказа-два целевого объекта для нашего апельсинового сока является наблюдаемым спросом на сок с двух дней назад.
Еще одно заметное различие между моделями временных рядов и моделями регрессии заключается в том, как они создают прогнозы. Модели временных рядов обычно определяются отношениями рекурсии и создают прогнозы по одному за раз. Чтобы прогнозировать много периодов в будущем, они итерируют до горизонта прогнозирования, кормя предыдущие прогнозы обратно в модель, чтобы создать следующий прогноз на один период по мере необходимости. В отличие от этого, модели регрессии являются так называемыми прямыми прогнозами, которые создают все прогнозы до горизонта в одном пути. Прямые прогнозировщики могут быть предпочтительнее рекурсивных моделей, так как рекурсивные модели составной ошибки прогнозирования, когда они передают предыдущие прогнозы обратно в модель. Если включены функции задержки, AutoML вносит некоторые важные изменения в обучающие данные, чтобы модели регрессии могли функционировать в качестве прямых прогнозировщиков. Дополнительные сведения см. в статье о функциях задержки.
Модели прогнозирования в AutoML
В следующей таблице перечислены модели прогнозирования, реализованные в AutoML, и к какой категории они относятся:
| Модели временных рядов | модели регрессии; |
|---|---|
| Наивный, сезонный наивный, средний, сезонный средний, ARIMA(X), экспоненциальное сглаживание | Линейный КОД, LARS LASSO, Эластичная сеть, Пророк, K ближайших соседей, дерево принятия решений, случайный лес, чрезвычайно случайные деревья, Градиент увеличенные деревья, LightGBM, XGBoost, TCNForecaster |
Модели в каждой категории перечислены примерно в порядке сложности шаблонов, которые они могут включать, также известные как емкость модели. Наивная модель, которая просто прогнозирует последнее наблюдаемое значение, имеет низкую емкость, в то время как темпоральная сверточная сеть (TCNForecaster), глубокая нейронная сеть с потенциально миллионами параметров, имеет высокую емкость.
Важно, что AutoML также включает в себя модели ансамбля , которые создают взвешнные сочетания наиболее подходящих моделей для дальнейшего повышения точности. Для прогнозирования мы используем мягкий ансамбль голосования, где композиция и весы находятся с помощью алгоритма выбора ансамбля Caruana.
Примечание.
Существует два важных предостережения для ансамблей модели прогнозирования:
- В настоящее время TCN нельзя включить в ансамбли.
- AutoML по умолчанию отключает другой метод ансамбля, ансамбля стека, который включается в задачи регрессии по умолчанию и классификации в AutoML. Стек ансамбля соответствует мета-модели на лучших прогнозах модели для поиска весов ансамбля. Мы обнаружили, что эта стратегия имеет повышенную тенденцию к превышению соответствия данным временных рядов. Это может привести к плохой обобщению, поэтому ансамбль стека отключен по умолчанию. Однако его можно включить, если требуется в конфигурации AutoML.
Как AutoML использует данные
AutoML принимает данные временных рядов в табличном формате; То есть каждая переменная должна иметь собственный соответствующий столбец. AutoML требует, чтобы один из столбцов был осью времени для задачи прогнозирования. Этот столбец должен быть синтаксический анализ в тип datetime. Самый простой набор данных временных рядов состоит из столбца времени и числового целевого столбца. Целевой объект — это переменная, предназначенная для прогнозирования в будущем. Ниже приведен пример формата в этом простом случае:
| TIMESTAMP | quantity |
|---|---|
| 2012-01-01 | 100 |
| 2012-01-02 | 97 |
| 2012-01-03 | 106 |
| ... | ... |
| 2013-12-31 | 347 |
В более сложных случаях данные могут содержать другие столбцы, выровненные с индексом времени.
| TIMESTAMP | номер SKU | цена | Рекламируется | quantity |
|---|---|---|---|---|
| 2012-01-01 | СОК1 | 3.5 | 0 | 100 |
| 2012-01-01 | ХЛЕБ3 | 5.76 | 0 | 47 |
| 2012-01-02 | СОК1 | 3.5 | 0 | 97 |
| 2012-01-02 | ХЛЕБ3 | 5.5 | 1 | 68 |
| ... | ... | ... | ... | ... |
| 2013-12-31 | СОК1 | 3,75 % | 0 | 347 |
| 2013-12-31 | ХЛЕБ3 | 5.7 | 0 | 94 |
В этом примере есть номер SKU, розничная цена и флаг, указывающий, был ли элемент объявлен в дополнение к метке времени и целевому количеству. Очевидно, что в этом наборе данных есть две серии : один для SKU JUICE1 и один для номера SKU BREAD3; SKU Столбец — это столбец идентификатора временных рядов, так как группирование по нему предоставляет две группы, содержащие одну серию. Перед перебором моделей AutoML выполняет базовую проверку входной конфигурации и данных и добавляет инженерные функции.
Требования к длине данных
Чтобы обучить модель прогнозирования, необходимо иметь достаточное количество исторических данных. Это пороговое значение зависит от конфигурации обучения. Если вы предоставили данные проверки, минимальное количество наблюдений, необходимых для каждого временных рядов, будет дано.
$T_{\text{user validation}} = H + \text{max}(l_{\text{max}}, s_{\text{window}}) + 1$,
где $H$ — это горизонт прогнозирования, $l_{\text{max}}$ — максимальный порядок задержки, а $s_{\text{window}}$ — размер окна для скользящей агрегатной функции. Если вы используете перекрестную проверку, минимальное количество наблюдений—
$T_{\text{CV}} = 2H + (n_{\text{CV}} - 1) n_{\text{step}} + \text{max}(l_{\text{max}}, s_{\text{окно}}) + 1$,
где $n_{\text{CV}}$ — это количество сверток перекрестной проверки и $n_{\text{step}}$ — это размер шага CV или смещение между свертками CV. Основная логика этих формул заключается в том, что у вас всегда должен быть по крайней мере горизонт обучающих наблюдений для каждого временных рядов, включая некоторые отставания для задержек и перекрестной проверки разбиения. Дополнительные сведения о перекрестной проверке для прогнозирования см. в разделе выбора модели прогнозирования.
Обработка отсутствующих данных
Для моделей временных рядов AutoML требуется регулярное пространство наблюдений за временем. Регулярное место здесь включает случаи, такие как ежемесячные или ежегодные наблюдения, где количество дней между наблюдениями может отличаться. Перед моделированием AutoML должен гарантировать отсутствие отсутствующих значений рядов и регулярность наблюдений. Таким образом, существует два отсутствующих случая данных:
- Значение отсутствует для некоторых ячеек в табличных данных
- Строка отсутствует, которая соответствует ожидаемому наблюдению с учетом частоты временных рядов
В первом случае AutoML вменяет отсутствующие значения с помощью распространенных настраиваемых методов.
Пример отсутствия ожидаемой строки показан в следующей таблице:
| TIMESTAMP | quantity |
|---|---|
| 2012-01-01 | 100 |
| 2012-01-03 | 106 |
| 2012-01-04 | 103 |
| ... | ... |
| 2013-12-31 | 347 |
Эта серия якобы имеет ежедневную частоту, но нет наблюдения за 2 января 2012 года. В этом случае AutoML попытается заполнить данные, добавив новую строку 2 января 2012 года. Новое значение столбца quantity и любых других столбцов в данных затем будет вменяться так же, как и другие отсутствующие значения. Очевидно, autoML должен знать частоту рядов, чтобы заполнить пробелы наблюдения, как это. AutoML автоматически обнаруживает эту частоту или, при необходимости, пользователь может предоставить его в конфигурации.
Метод оцепления для заполнения отсутствующих значений можно настроить в входных данных. Методы по умолчанию перечислены в следующей таблице:
| Тип столбца | Метод imputation по умолчанию |
|---|---|
| Назначение | Переадресация (последнее наблюдение, перенесенное вперед) |
| Числовая функция | Значение медиана |
Отсутствующие значения для категориальных признаков обрабатываются во время числовой кодировки, включая дополнительную категорию, соответствующую отсутствующим значениям. В этом случае импютация неявна.
Автоматизированное конструирование признаков
AutoML обычно добавляет новые столбцы в пользовательские данные для повышения точности моделирования. Инженерная функция может включать в себя следующее:
| Группа компонентов | Значение по умолчанию или необязательно |
|---|---|
| Функции календаря, производные от индекса времени (например, день недели) | По умолчанию. |
| Категориальные признаки, производные от идентификаторов временных рядов | По умолчанию. |
| Кодировка категориальных типов числовым типом | По умолчанию. |
| Функции индикатора для праздников, связанных с определенной страной или регионом | Необязательно |
| Задержки целевого количества | Необязательно |
| Задержки столбцов признаков | Необязательно |
| Агрегирование окон (например, скользящее среднее) целевого количества | Необязательно |
| Сезонная декомпозиция (STL) | Необязательно |
Вы можете настроить признаки из пакета SDK AutoML с помощью класса ForecastingJob или из веб-интерфейса Студия машинного обучения Azure.
Обнаружение и обработка неустанных временных рядов
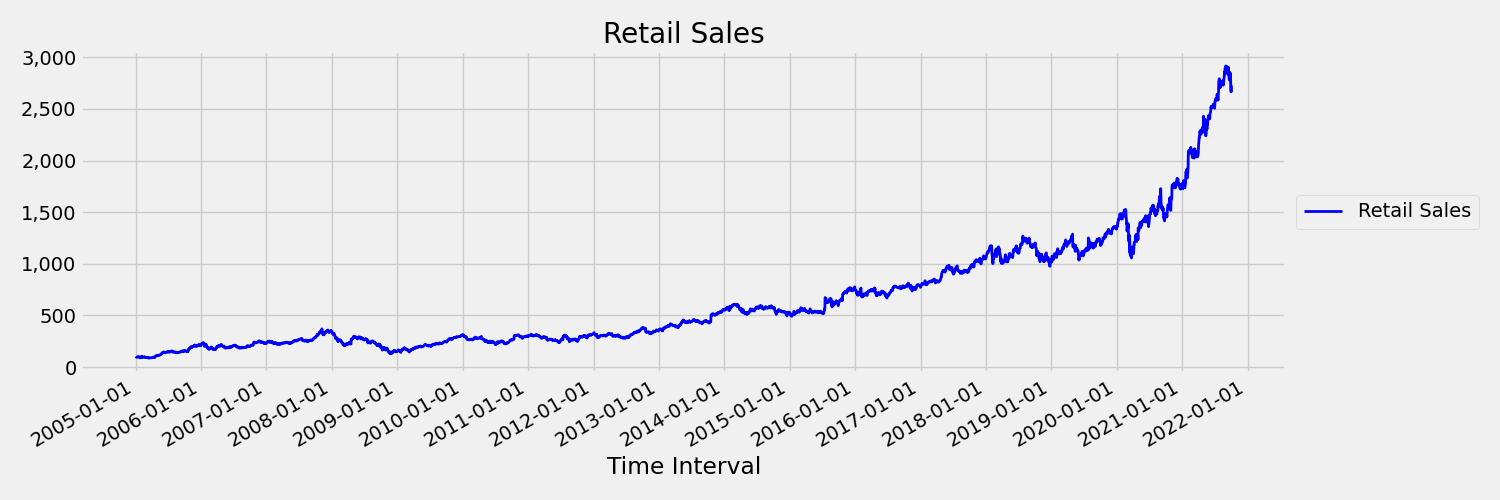
Временные ряды, в которых среднее и дисперсийное изменение со временем называется нестановным. Например, временные ряды, которые демонстрируют стохастические тенденции, являются нестановными по природе. Чтобы визуализировать это, на следующем изображении показан ряд, который, как правило, тренд вверх. Теперь вычислить и сравнить средние (средние) значения для первой и второй половины ряда. Они одинаковы? Здесь среднее значение серии в первой половине сюжета значительно меньше, чем во второй половине. Тот факт, что среднее значение ряда зависит от интервала времени, на который смотрит, является примером временных переменных моментов. Здесь среднее значение серии является первым моментом.
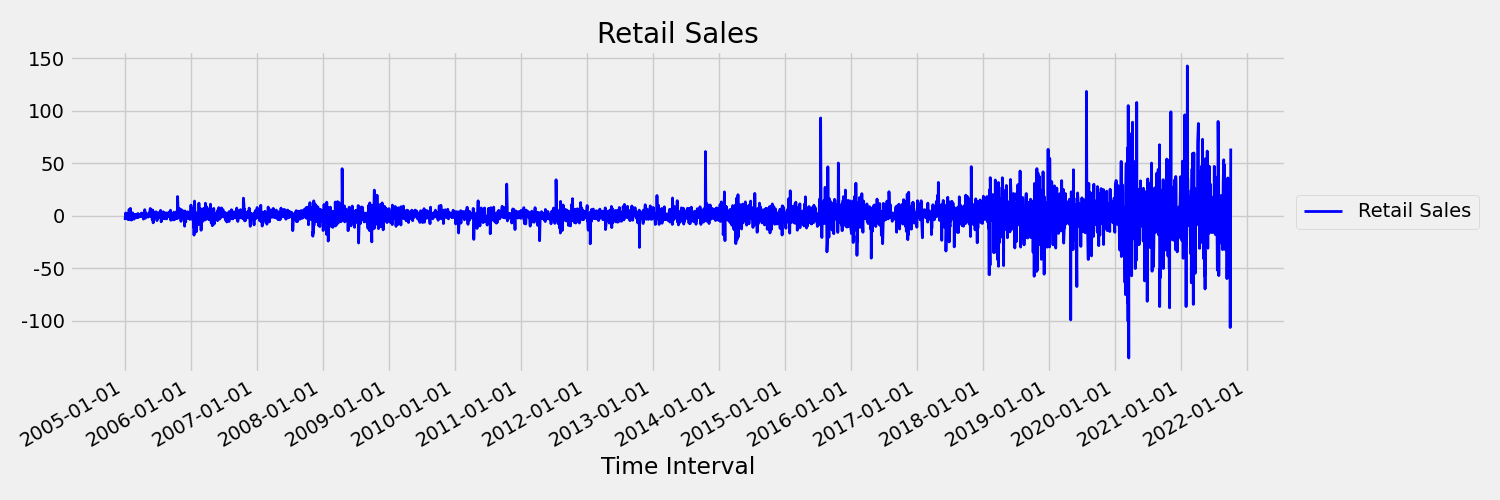
Далее давайте рассмотрим следующее изображение, которое отображает исходную серию в первых различиях, $\Delta y_{t} = y_t - y_{t-1}$. Среднее значение ряда является примерно константой в течение диапазона времени, в то время как дисперсии, как представляется, различаются. Таким образом, это пример первой последовательности временных рядов заказов.
Модели регрессии AutoML не могут по сути справиться с стохастических тенденций или другими известными проблемами, связанными с нестановными временными рядами. В результате точность прогноза вне выборки может быть плохой, если существуют такие тенденции.
AutoML автоматически анализирует набор данных временных рядов для определения станции. При обнаружении нестанционных временных рядов автоML автоматически применяет разностное преобразование, чтобы снизить влияние нестанционного поведения.
Очистка модели
После подготовки данных с отсутствием обработки данных и проектирования функций AutoML выполняет очистку набора моделей и гиперпараметров с помощью службы рекомендаций модели. Модели ранжируются на основе метрик проверки или перекрестной проверки, а затем, при необходимости, первые модели могут использоваться в модели ансамбля. Лучшая модель или любая из обученных моделей может быть проверена, скачанна или развернута для создания прогнозов по мере необходимости. Дополнительные сведения см. в статье о выборе и выборе модели.
Группирование моделей
Если набор данных содержит несколько временных рядов, как и в данном примере данных, существует несколько способов моделирования этих данных. Например, мы можем просто сгруппировать по столбцам идентификаторов временных рядов и обучить независимые модели для каждой серии. Более общий подход заключается в секционирование данных на группы, которые могут содержать несколько связанных рядов и обучать модель для каждой группы. По умолчанию прогнозирование AutoML использует смешанный подход к группировке моделей. Модели временных рядов, а также ARIMAX и Пророк, назначьте одну серию одной группе и другим моделям регрессии назначьте все ряды одной группе. В следующей таблице перечислены группировки моделей в двух категориях: один к одному и ко многим:
| Каждая серия в собственной группе (1:1) | Все серии в одной группе (N:1) |
|---|---|
| Наивный, сезонный наивный, средний, сезонный средний, экспоненциальный сглаживание, ARIMA, ARIMAX, Пророк | Линейный КОД, LARS LASSO, Elastic Net, K ближайших соседей, дерево принятия решений, случайный лес, чрезвычайно случайные деревья, Градиент увеличенные деревья, LightGBM, XGBoost, TCNForecaster |
Более общие группы моделей возможны с помощью решения AutoML для многих моделей; ознакомьтесь с нашей записной книжкой "Многие модели— автоматизированное машинное обучение".
Следующие шаги
- Сведения о моделях глубокого обучения для прогнозирования в AutoML
- Дополнительные сведения о масштабировании и выборе моделей для прогнозирования в AutoML.
- Узнайте, как AutoML создает функции из календаря.
- Узнайте, как AutoML создает функции задержки.
- Ознакомьтесь с ответами на часто задаваемые вопросы о прогнозировании в AutoML.