Настройка AutoML для обучения модели прогнозирования временных рядов с помощью пакета SDK и CLI
ОБЛАСТЬ ПРИМЕНЕНИЯ: Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
В этой статье вы узнаете, как настроить AutoML для прогнозирования временных рядов с помощью Машинное обучение Azure автоматизированного машинного обучения в пакете SDK для Python Машинное обучение Azure.
Для этого сделайте следующее.
Чтобы реализовывать эти возможности без написания большого объема кода, см. руководство по прогнозированию спроса с помощью автоматизированного машинного обучения, в котором приведен пример прогнозирования временных рядов с использованием автоматизированного машинного обучения в Студии машинного обучения Azure.
AutoML использует стандартные модели машинного обучения вместе с известными моделями временных рядов для создания прогнозов. Наш подход включает исторические сведения о целевой переменной, предоставляемых пользователем функциях в входных данных и автоматически спроектированных функциях. Затем алгоритмы поиска моделей работают для поиска модели с оптимальной прогнозной точностью. Дополнительные сведения см. в наших статьях по методологии прогнозирования и поиску моделей.
Необходимые компоненты
Для работы с этой статьей вам потребуется следующее:
Рабочая область Машинного обучения Azure. Сведения о создании рабочей области см. в разделе Создание ресурсов рабочей области.
Возможность запуска заданий обучения AutoML. Следуйте инструкциям по настройке AutoML для получения дополнительных сведений.
Данные для обучения и проверки
Входные данные для прогнозирования AutoML должны содержать допустимые временные ряды в табличном формате. Каждая переменная должна иметь собственный столбец в таблице данных. Для autoML требуется по крайней мере два столбца: столбец времени, представляющий ось времени и целевой столбец , который является количеством для прогнозирования. Другие столбцы могут служить прогнозаторами. Дополнительные сведения см. в статье о том, как AutoML использует данные.
Внимание
При обучении модели для прогнозирования будущих значений убедитесь, что все признаки, используемые при обучении, можно применять при выполнении прогнозов для предполагаемого горизонта.
Например, функция для текущей цены акций может значительно увеличить точность обучения. Однако если вы намерены выполнить прогнозирование с дальним горизонтом, возможно, вам не удастся точно предсказать будущую стоимость акций, соответствующую будущим точкам временного ряда, и точность модели может снизиться.
Для заданий прогнозирования AutoML требуется, чтобы данные обучения были представлены в виде объекта MLTable . MlTable указывает источник данных и шаги по загрузке данных. Дополнительные сведения и варианты использования см. в руководстве по MLTable. В качестве простого примера предположим, что данные обучения содержатся в CSV-файле в локальном каталоге ./train_data/timeseries_train.csv.
Вы можете создать MLTable с помощью mltable Python SDK , как показано в следующем примере:
import mltable
paths = [
{'file': './train_data/timeseries_train.csv'}
]
train_table = mltable.from_delimited_files(paths)
train_table.save('./train_data')
Этот код создает новый файл, ./train_data/MLTableсодержащий формат файла и инструкции по загрузке.
Теперь вы определяете входной объект данных, который требуется для запуска задания обучения, используя пакет SDK для Python Машинное обучение Azure следующим образом:
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml import Input
# Training MLTable defined locally, with local data to be uploaded
my_training_data_input = Input(
type=AssetTypes.MLTABLE, path="./train_data"
)
Вы указываете данные проверки аналогичным образом, создав MLTable и указав входные данные проверки. Кроме того, если вы не предоставляете данные проверки, AutoML автоматически создает перекрестную проверку от обучающих данных, используемых для выбора модели. Дополнительные сведения см. в нашей статье по выбору модели прогнозирования. Дополнительные сведения о том, сколько обучающих данных необходимо обучить модели прогнозирования, см . в разделе "Требования к длине обучающих данных".
Узнайте больше о том, как AutoML применяет перекрестную проверку, чтобы предотвратить перекрестную проверку.
Вычисление для запуска эксперимента
AutoML использует Машинное обучение Azure Вычисление, которое является полностью управляемым вычислительным ресурсом для запуска задания обучения. В следующем примере создается вычислительный cpu-compute кластер:
from azure.ai.ml.entities import AmlCompute
# specify aml compute name.
cpu_compute_target = "cpu-cluster"
try:
ml_client.compute.get(cpu_compute_target)
except Exception:
print("Creating a new cpu compute target...")
compute = AmlCompute(
name=cpu_compute_target, size="STANDARD_D2_V2", min_instances=0, max_instances=4
)
ml_client.compute.begin_create_or_update(compute).result()Настройка эксперимента
Функции фабрики automl используются для настройки заданий прогнозирования в пакете SDK для Python. В следующем примере показано, как создать задание прогнозирования, задав основную метрику и установив ограничения для выполнения обучения:
from azure.ai.ml import automl
# note that the below is a code snippet -- you might have to modify the variable values to run it successfully
forecasting_job = automl.forecasting(
compute="cpu-compute",
experiment_name="sdk-v2-automl-forecasting-job",
training_data=my_training_data_input,
target_column_name=target_column_name,
primary_metric="normalized_root_mean_squared_error",
n_cross_validations="auto",
)
# Limits are all optional
forecasting_job.set_limits(
timeout_minutes=120,
trial_timeout_minutes=30,
max_concurrent_trials=4,
)
Параметры задания прогнозирования
Задачи прогнозирования имеют множество параметров, относящихся к прогнозированию. Наиболее основными из этих параметров являются имя столбца времени в данных обучения и горизонте прогнозирования.
Используйте методы ForecastingJob для настройки следующих параметров:
# Forecasting specific configuration
forecasting_job.set_forecast_settings(
time_column_name=time_column_name,
forecast_horizon=24
)
Имя столбца времени является обязательным параметром, и обычно следует задать горизонт прогнозирования в соответствии с вашим сценарием прогнозирования. Если данные содержат несколько временных рядов, можно указать имена столбцов идентификаторов временных рядов. Эти столбцы при группировке определяют отдельные ряды. Например, предположим, что у вас есть данные, состоящие из часовых продаж из разных магазинов и брендов. В следующем примере показано, как задать столбцы идентификатора временных рядов, предполагая, что данные содержат столбцы с именем store и brand:
# Forecasting specific configuration
# Add time series IDs for store and brand
forecasting_job.set_forecast_settings(
..., # other settings
time_series_id_column_names=['store', 'brand']
)
AutoML пытается автоматически обнаруживать столбцы идентификаторов временных рядов в данных, если они не указаны.
Другие параметры являются необязательными и рассматриваются в следующем разделе.
Необязательные параметры задания прогнозирования
Необязательные конфигурации доступны для задач прогнозирования, таких как включение глубокого обучения и указание агрегата целевого скользящего окна. Полный список параметров доступен в справочной документации по прогнозированию.
Параметры поиска модели
Существует два необязательных параметра, которые управляют пространством модели, в котором AutoML ищет лучшую модель и allowed_training_algorithmsblocked_training_algorithms. Чтобы ограничить пространство поиска заданным набором классов моделей, используйте allowed_training_algorithms параметр, как показано в следующем примере:
# Only search ExponentialSmoothing and ElasticNet models
forecasting_job.set_training(
allowed_training_algorithms=["ExponentialSmoothing", "ElasticNet"]
)
В этом случае задание прогнозирования выполняет поиск только по классам модели Exponential Smoothing и Elastic Net. Чтобы удалить заданный набор классов моделей из пространства поиска, используйте blocked_training_algorithms, как показано в следующем примере:
# Search over all model classes except Prophet
forecasting_job.set_training(
blocked_training_algorithms=["Prophet"]
)
Теперь задание выполняет поиск по всем классам моделей, кроме Пророка. Список имен моделей прогнозирования, принятых в allowed_training_algorithms и , см. в справочной документации по свойствамblocked_training_algorithmsобучения. Либо, но не оба и allowed_training_algorithmsblocked_training_algorithms может применяться к учебному запуску.
Включение глубокого обучения
AutoML поставляется с пользовательской моделью TCNForecasterглубокой нейронной сети (DNN). Эта модель представляет собой временную сверточную сеть или TCN, которая применяет распространенные методы задачи визуализации к моделированию временных рядов. А именно одномерные сверточные свертки образуют магистраль сети и позволяют модели изучать сложные шаблоны в течение длительной длительности в истории обучения. Дополнительные сведения см. в нашей статье TCNForecaster.
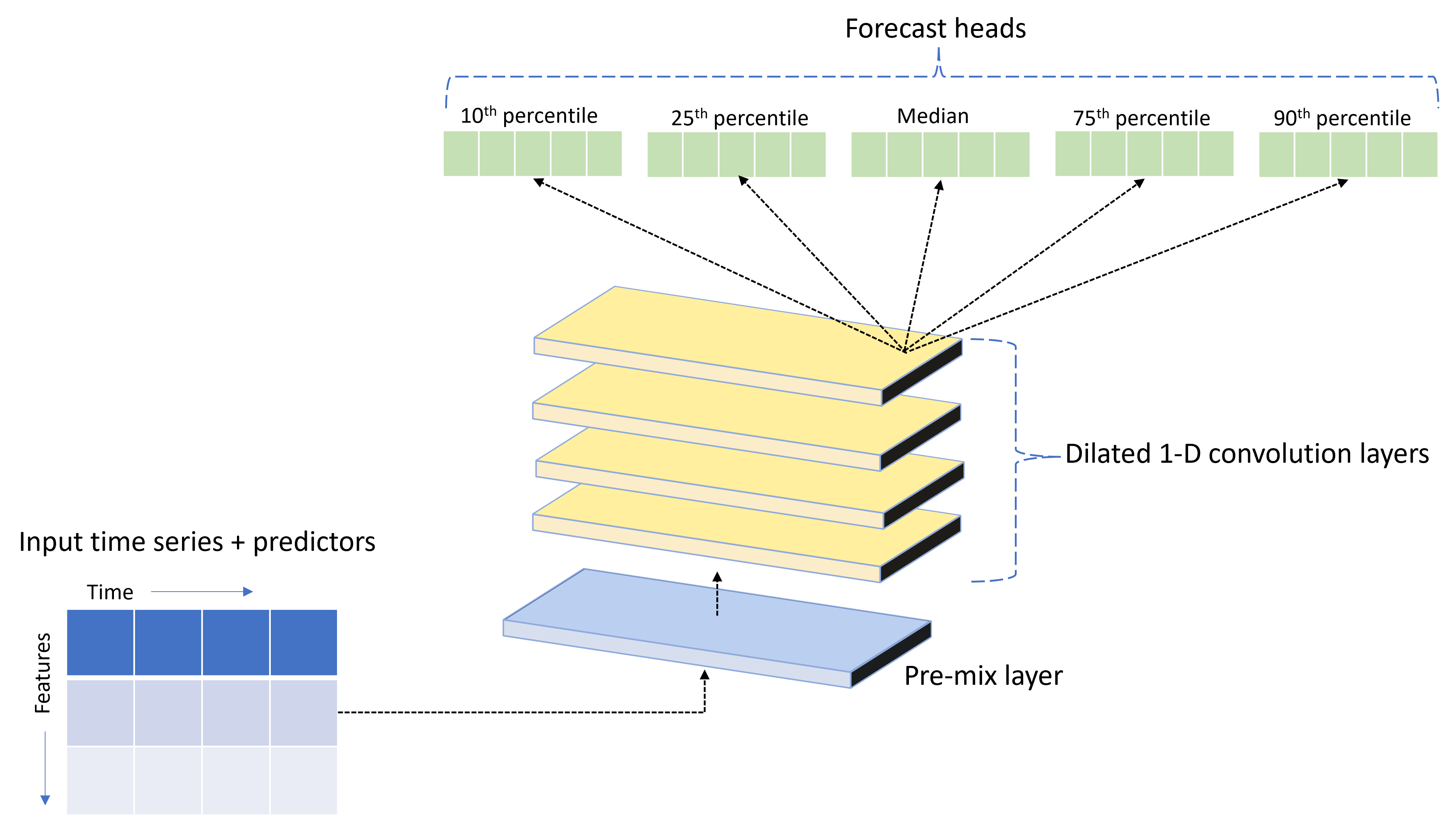
TCNForecaster часто достигает более высокой точности, чем стандартные модели временных рядов, если в истории обучения есть тысячи или более наблюдений. Тем не менее, это также занимает больше времени для обучения и очистки моделей TCNForecaster из-за их более высокой емкости.
Вы можете включить TCNForecaster в AutoML, задав enable_dnn_training флаг в конфигурации обучения следующим образом:
# Include TCNForecaster models in the model search
forecasting_job.set_training(
enable_dnn_training=True
)
По умолчанию обучение TCNForecaster ограничено одним вычислительным узлом и одним GPU, если он доступен для каждой пробной версии модели. Для сценариев больших данных рекомендуется распространять каждую пробную версию TCNForecaster по нескольким ядрам и gpu и узлам. Дополнительные сведения и примеры кода см. в разделе " Распределенное обучение ".
Сведения о включении глубокой нейронной сети для эксперимента AutoML, созданного в Студии машинного обучения Azure, см. в параметрах типов задач в практическом руководстве по пользовательскому интерфейсу студии.
Примечание.
- При включении глубокой нейронной сети для экспериментов, созданных с помощью пакета SDK, лучшие объяснения моделей отключены.
- Поддержка DNN для прогнозирования в автоматизированных Машинное обучение не поддерживается для запусков, инициированных в Databricks.
- Типы вычислений GPU рекомендуется использовать при включении обучения DNN
Функции "Задержка" и "скользякое окно"
Последние значения целевого объекта часто влияют на функции в модели прогнозирования. Соответственно, AutoML может создавать функции агрегирования временных и временных окон, чтобы повысить точность модели.
Рассмотрим сценарий прогнозирования спроса на энергию, в котором доступны данные о погоде и исторический спрос. В таблице показана результирующая инженерия признаков, возникающая при применении агрегирования окна за последние три часа. Столбцы для минимального, максимального и суммного значения создаются в скользящем окне в течение трех часов на основе определенных параметров. Например, для наблюдения, допустимого 8 сентября 2017 г. 4:00 утра, максимальное, минимальное и суммное значения вычисляются с использованием значений спроса на 8 сентября 2017 г. 1:00AM – 3:00AM. Это окно трех часов перемещается вместе, чтобы заполнить данные для оставшихся строк. Дополнительные сведения и примеры см. в статье о функции задержки.

Вы можете включить функции агрегирования окон и задержки для целевого объекта, задав размер скользящего окна, который был три в предыдущем примере, а также заказы на задержку, которые вы хотите создать. Вы также можете включить задержки для функций с параметром feature_lags . В следующем примере мы зададим все эти параметры таким образом, чтобы AutoML автоматически определяет параметры auto , анализируя структуру корреляции данных:
forecasting_job.set_forecast_settings(
..., # other settings
target_lags='auto',
target_rolling_window_size='auto',
feature_lags='auto'
)
Обработка коротких рядов
Автоматизированное машинное обучение считает временный ряд коротким рядом, если недостаточно точек данных для проведения обучения и проверки этапов разработки моделей. Дополнительные сведения о требованиях к длине обучающих данных см . в разделе "Требования к длине".
AutoML имеет несколько действий, которые могут потребоваться для коротких рядов. Эти действия настраиваются с short_series_handling_config помощью параметра. Значение по умолчанию — auto. В следующей таблице описаны параметры:
| Параметр | Description |
|---|---|
auto |
Значение по умолчанию для обработки коротких рядов. - Если все ряды являются короткими, производится заполнение данных. - Если не все ряды являются короткими, то короткие ряды удаляются. |
pad |
Если short_series_handling_config = pad, то автоматизированное ML добавляет случайные значения в каждый обнаруженный короткий ряд. Ниже перечислены типы столбцов и их заполнение. - Столбцы объектов с naNs — числовые столбцы с 0 — логические столбцы или столбцы логики со значением False — Целевой столбец заполняется белым шумом. |
drop |
Если short_series_handling_config = drop, то автоматизированное ML удаляет короткие ряды и они не будут использоваться для обучения или прогнозирования. Прогнозы для этих рядов будут возвращать значения NaN. |
None |
Ряды не заполняются и не удаляются |
В следующем примере мы зададим обработку коротких рядов, чтобы все короткие ряды были заполнены минимальной длиной:
forecasting_job.set_forecast_settings(
..., # other settings
short_series_handling_config='pad'
)
Предупреждение
Заполнение может повлиять на точность результирующей модели, так как мы внедряем искусственные данные, чтобы избежать сбоев обучения. Если коротких рядов много, также возможно некоторое негативное влияние на результаты возможностей объяснения.
Частота и агрегирование целевых данных
Используйте параметры частоты и агрегирования данных, чтобы избежать сбоев, вызванных нерегулярными данными. Ваши данные нерегулярно, если они не соответствуют заданному времени, например почасовой или ежедневной. Данные о точках продаж являются хорошим примером нерегулярных данных. В таких случаях AutoML может объединять данные с требуемой частотой, а затем создавать модель прогнозирования из статистических выражений.
Необходимо задать frequency параметры для target_aggregate_function обработки нерегулярных данных. Параметр частоты принимает строки Pandas DateOffset в качестве входных данных. Поддерживаемые значения для функции агрегирования:
| Function | Description |
|---|---|
sum |
Сумма целевых значений |
mean |
Среднее или среднее от целевых значений |
min |
Минимальное значение целевого объекта |
max |
Максимальное значение целевого объекта |
- Значения целевого столбца агрегируются в соответствии с указанной операцией. Как правило, в большинстве ситуаций подходит операция "sum".
- Числовые столбцы прогнозирования в данных агрегируются по сумме, среднему значению, минимальному и максимальному значению. В результате автоматизированное ML создает новые столбцы с суффиксом, соответствующим имени примененной функции агрегирования, и применяет к ним выбранную операцию агрегирования.
- Для столбцов категориального прогноза данные агрегируются по моде — наиболее выраженной категории в окне.
- Столбцы прогнозирования дат агрегируются по минимальному значению, максимальному значению и моде.
В следующем примере почасовая частота устанавливается, а функция агрегирования — суммирование:
# Aggregate the data to hourly frequency
forecasting_job.set_forecast_settings(
..., # other settings
frequency='H',
target_aggregate_function='sum'
)
Пользовательские параметры перекрестной проверки
Существует два настраиваемых параметра, которые управляют перекрестной проверкой для заданий прогнозирования: количество сверток, n_cross_validationsа также размер шага, определяющий смещение времени между свертками, cv_step_size. Дополнительные сведения о значении этих параметров см . в выборе модели прогнозирования. По умолчанию AutoML настраивает оба параметра автоматически на основе характеристик данных, но расширенные пользователи могут вручную задать их. Например, предположим, что у вас есть ежедневные данные о продажах, и вы хотите, чтобы настройка проверки состояла из пяти сверток с семидневным смещением между смежными свертками. В следующем примере кода показано, как задать следующие параметры:
from azure.ai.ml import automl
# Create a job with five CV folds
forecasting_job = automl.forecasting(
..., # other training parameters
n_cross_validations=5,
)
# Set the step size between folds to seven days
forecasting_job.set_forecast_settings(
..., # other settings
cv_step_size=7
)
Пользовательские признаки
По умолчанию AutoML расширяет обучающие данные с помощью встроенных функций, чтобы повысить точность моделей. Дополнительные сведения см . в автоматизированной разработке функций. Некоторые из этапов предварительной обработки можно настроить с помощью конфигурации признаков задания прогнозирования.
Поддерживаемые настройки для прогнозирования приведены в следующей таблице:
| Пользовательская настройка | Description | Параметры |
|---|---|---|
| Обновление назначения столбца | Переопределение автоматически определенного типа признака для указанного столбца. | "Категориальный", "DateTime", "Numeric" |
| Обновление параметра преобразователя | Обновите параметры для указанного вменителя. | {"strategy": "constant", "fill_value": <value>}, , {"strategy": "median"}{"strategy": "ffill"} |
Например, предположим, что у вас есть сценарий розничного спроса, в котором данные включают цены, флаг "по продаже" и тип продукта. В следующем примере показано, как настроить настраиваемые типы и имитаторы для этих функций:
from azure.ai.ml.automl import ColumnTransformer
# Customize imputation methods for price and is_on_sale features
# Median value imputation for price, constant value of zero for is_on_sale
transformer_params = {
"imputer": [
ColumnTransformer(fields=["price"], parameters={"strategy": "median"}),
ColumnTransformer(fields=["is_on_sale"], parameters={"strategy": "constant", "fill_value": 0}),
],
}
# Set the featurization
# Ensure that product_type feature is interpreted as categorical
forecasting_job.set_featurization(
mode="custom",
transformer_params=transformer_params,
column_name_and_types={"product_type": "Categorical"},
)
Если вы используете для эксперимента Студию машинного обучения Azure, узнайте, как настроить конструирование признаков в Студии.
Отправка задания прогнозирования
После настройки всех параметров запустите задание прогнозирования следующим образом:
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(
forecasting_job
)
print(f"Created job: {returned_job}")
# Get a URL for the job in the AML studio user interface
returned_job.services["Studio"].endpoint
После отправки задания AutoML подготовит вычислительные ресурсы, применит признаки и другие шаги подготовки к входным данным, а затем начнет перебор моделей прогнозирования. Дополнительные сведения см. в наших статьях по методологии прогнозирования и поиску моделей.
Оркестрация обучения, вывода и оценки с помощью компонентов и конвейеров
Внимание
Эта функция сейчас доступна в виде общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания. Ее не следует использовать для производственных рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены.
Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
Рабочий процесс машинного обучения, скорее всего, требует больше, чем просто обучения. Вывод или получение прогнозов модели на более новых данных и оценка точности модели в тестовом наборе с известными целевыми значениями являются другими распространенными задачами, которые можно оркестрировать в AzureML вместе с заданиями обучения. Для поддержки задач вывода и оценки AzureML предоставляет компоненты, которые являются автономными частями кода, которые выполняют один шаг в конвейере AzureML.
В следующем примере мы извлекаем код компонента из клиентского реестра:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Create a client for accessing assets in the AzureML preview registry
ml_client_registry = MLClient(
credential=credential,
registry_name="azureml-preview"
)
# Create a client for accessing assets in the AzureML preview registry
ml_client_metrics_registry = MLClient(
credential=credential,
registry_name="azureml"
)
# Get an inference component from the registry
inference_component = ml_client_registry.components.get(
name="automl_forecasting_inference",
label="latest"
)
# Get a component for computing evaluation metrics from the registry
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
Затем мы определим функцию фабрики, которая создает конвейеры для оркестрации обучения, вывода и вычисления метрик. Дополнительные сведения о параметрах обучения см. в разделе конфигурации обучения.
from azure.ai.ml import automl
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml.dsl import pipeline
@pipeline(description="AutoML Forecasting Pipeline")
def forecasting_train_and_evaluate_factory(
train_data_input,
test_data_input,
target_column_name,
time_column_name,
forecast_horizon,
primary_metric='normalized_root_mean_squared_error',
cv_folds='auto'
):
# Configure the training node of the pipeline
training_node = automl.forecasting(
training_data=train_data_input,
target_column_name=target_column_name,
primary_metric=primary_metric,
n_cross_validations=cv_folds,
outputs={"best_model": Output(type=AssetTypes.MLFLOW_MODEL)},
)
training_node.set_forecasting_settings(
time_column_name=time_column_name,
forecast_horizon=max_horizon,
frequency=frequency,
# other settings
...
)
training_node.set_training(
# training parameters
...
)
training_node.set_limits(
# limit settings
...
)
# Configure the inference node to make rolling forecasts on the test set
inference_node = inference_component(
test_data=test_data_input,
model_path=training_node.outputs.best_model,
target_column_name=target_column_name,
forecast_mode='rolling',
forecast_step=1
)
# Configure the metrics calculation node
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
ground_truth=inference_node.outputs.inference_output_file,
prediction=inference_node.outputs.inference_output_file,
evaluation_config=inference_node.outputs.evaluation_config_output_file
)
# return a dictionary with the evaluation metrics and the raw test set forecasts
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result,
"rolling_fcst_result": inference_node.outputs.inference_output_file
}
Теперь мы определим входные данные обучения и тестирования, предполагая, что они содержатся в локальных папках, ./train_data и ./test_data:
my_train_data_input = Input(
type=AssetTypes.MLTABLE,
path="./train_data"
)
my_test_data_input = Input(
type=AssetTypes.URI_FOLDER,
path='./test_data',
)
Наконец, мы создадим конвейер, задайте для нее вычисления по умолчанию и отправьте задание:
pipeline_job = forecasting_train_and_evaluate_factory(
my_train_data_input,
my_test_data_input,
target_column_name,
time_column_name,
forecast_horizon
)
# set pipeline level compute
pipeline_job.settings.default_compute = compute_name
# submit the pipeline job
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name
)
returned_pipeline_job
После отправки конвейер запускает обучение AutoML, вывод по скользящей оценке и вычисление метрик в последовательности. Вы можете отслеживать и проверять выполнение в пользовательском интерфейсе студии. По завершении выполнения прогнозы и метрики оценки можно скачать в локальный рабочий каталог:
# Download the metrics json
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='metrics_result')
# Download the rolling forecasts
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='rolling_fcst_result')
Затем можно найти результаты метрик и прогнозы ./named-outputs/metrics_results/evaluationResult/metrics.json в формате строк JSON в ./named-outputs/rolling_fcst_result/inference_output_file.
Дополнительные сведения о последовательной оценке см . в статье об оценке модели прогнозирования.
Прогнозирование в масштабе: многие модели
Внимание
Эта функция сейчас доступна в виде общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания. Ее не следует использовать для производственных рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены.
Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
Многие компоненты моделей в AutoML позволяют параллельно обучать миллионы моделей и управлять ими. Дополнительные сведения о многих концепциях моделей см. в разделе "Многие модели".
Настройка обучения многих моделей
Многие компоненты обучения моделей принимают файл конфигурации формата YAML для параметров обучения AutoML. Компонент применяет эти параметры к каждому запущенного экземпляру AutoML. Этот файл YAML имеет ту же спецификацию, что и задание прогнозирования, а также дополнительные параметры partition_column_names и allow_multi_partitions.
| Параметр | Описание |
|---|---|
| partition_column_names | Имена столбцов в данных, которые при группировке определяют секции данных. Компонент обучения многих моделей запускает независимое задание обучения для каждой секции. |
| allow_multi_partitions | Необязательный флаг, позволяющий обучать одну модель на секцию, если каждая секция содержит несколько уникальных временных рядов. Значение по умолчанию равно False. |
В следующем примере представлен шаблон конфигурации:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:<cluster-name>
task: forecasting
primary_metric: normalized_root_mean_squared_error
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: date
time_series_id_column_names: ["state", "store"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
partition_column_names: ["state", "store"]
allow_multi_partitions: false
В последующих примерах предполагается, что конфигурация хранится в пути ./automl_settings_mm.yml.
Конвейер многих моделей
Далее мы определим функцию фабрики, которая создает конвейеры для оркестрации многих моделей обучения, вывода и вычисления метрик. Параметры этой функции фабрики подробно описаны в следующей таблице:
| Параметр | Описание |
|---|---|
| max_nodes | Количество вычислительных узлов, используемых в задании обучения |
| max_concurrency_per_node | Число процессов AutoML, выполняемых на каждом узле. Следовательно, общая параллелизм множества заданий моделей .max_nodes * max_concurrency_per_node |
| parallel_step_timeout_in_seconds | Время ожидания компонента многих моделей, заданное в секундах. |
| retrain_failed_models | Пометка, чтобы включить повторное обучение для неудачных моделей. Это полезно, если вы сделали предыдущие многие модели, которые привели к сбою заданий AutoML в некоторых разделах данных. Если этот флаг включен, многие модели будут запускать задания обучения только для ранее неудачных секций. |
| forecast_mode | Режим вывода для оценки модели. Допустимые значения: "recursive" и "rolling". Дополнительные сведения см. в статье об оценке модели. |
| forecast_step | Размер шага для последовательного прогноза. Дополнительные сведения см. в статье об оценке модели. |
В следующем примере показан метод фабрики для создания множества конвейеров обучения моделей и оценки моделей:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a many models training component
mm_train_component = ml_client_registry.components.get(
name='automl_many_models_training',
version='latest'
)
# Get a many models inference component
mm_inference_component = ml_client_registry.components.get(
name='automl_many_models_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML Many Models Forecasting Pipeline")
def many_models_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
compute_name,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
retrain_failed_model=False,
forecast_mode="rolling",
forecast_step=1
):
mm_train_node = mm_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
retrain_failed_model=retrain_failed_model,
compute_name=compute_name
)
mm_inference_node = mm_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=mm_train_node.outputs.run_output,
forecast_mode=forecast_mode,
forecast_step=forecast_step,
compute_name=compute_name
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=mm_inference_node.outputs.evaluation_data,
ground_truth=mm_inference_node.outputs.evaluation_data,
evaluation_config=mm_inference_node.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Теперь мы создадим конвейер с помощью функции фабрики, предполагая, что обучающие и тестовые данные находятся в локальных папках и ./data/train./data/testсоответственно. Наконец, мы задали вычисления по умолчанию и отправим задание, как показано в следующем примере:
pipeline_job = many_models_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_mm.yml"
),
compute_name="<cluster name>"
)
pipeline_job.settings.default_compute = "<cluster name>"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
После завершения задания метрики оценки можно скачать локально с помощью той же процедуры, что и в конвейере единого обучения.
Кроме того, ознакомьтесь с прогнозом спроса с несколькими моделями записной книжки для более подробного примера.
Примечание.
Многие компоненты обучения и вывода моделей условно разделяют данные в соответствии с параметром partition_column_names , чтобы каждая секция была в собственном файле. Этот процесс может быть очень медленным или неудачным, если данные очень большие. В этом случае рекомендуется секционирование данных вручную перед выполнением многих моделей обучения или вывода.
Прогнозирование в масштабе: иерархические временные ряды
Внимание
Эта функция сейчас доступна в виде общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания. Ее не следует использовать для производственных рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены.
Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
Компоненты иерархических временных рядов (HTS) в AutoML позволяют обучать большое количество моделей на основе данных с иерархической структурой. Дополнительные сведения см. в разделе статьи HTS.
Конфигурация обучения HTS
Компонент обучения HTS принимает файл конфигурации формата YAML параметров обучения AutoML. Компонент применяет эти параметры к каждому запущенного экземпляру AutoML. Этот файл YAML имеет ту же спецификацию, что и задание прогнозирования, а также дополнительные параметры, связанные с сведениями о иерархии:
| Параметр | Описание |
|---|---|
| hierarchy_column_names | Список имен столбцов в данных, определяющих иерархическую структуру данных. Порядок столбцов в этом списке определяет уровни иерархии; степень агрегирования уменьшается с индексом списка. То есть последний столбец в списке определяет конечный (наиболее разделенный) уровень иерархии. |
| hierarchy_training_level | Уровень иерархии, используемый для обучения модели прогнозирования. |
Ниже показан пример конфигурации:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:cluster-name
task: forecasting
primary_metric: normalized_root_mean_squared_error
log_verbosity: info
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: "date"
time_series_id_column_names: ["state", "store", "SKU"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
hierarchy_column_names: ["state", "store", "SKU"]
hierarchy_training_level: "store"
В последующих примерах предполагается, что конфигурация хранится в пути ./automl_settings_hts.yml.
Конвейер HTS
Затем мы определим функцию фабрики, которая создает конвейеры для оркестрации обучения HTS, вывода и вычисления метрик. Параметры этой функции фабрики подробно описаны в следующей таблице:
| Параметр | Описание |
|---|---|
| forecast_level | Уровень иерархии для получения прогнозов |
| allocation_method | Метод выделения, используемый при разбивке прогнозов. Допустимые значения — "proportions_of_historical_average" и "average_historical_proportions". |
| max_nodes | Количество вычислительных узлов, используемых в задании обучения |
| max_concurrency_per_node | Число процессов AutoML, выполняемых на каждом узле. Следовательно, общая параллелизм задания HTS — max_nodes * max_concurrency_per_nodeэто . |
| parallel_step_timeout_in_seconds | Время ожидания компонента многих моделей, заданное в секундах. |
| forecast_mode | Режим вывода для оценки модели. Допустимые значения: "recursive" и "rolling". Дополнительные сведения см. в статье об оценке модели. |
| forecast_step | Размер шага для последовательного прогноза. Дополнительные сведения см. в статье об оценке модели. |
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a HTS training component
hts_train_component = ml_client_registry.components.get(
name='automl_hts_training',
version='latest'
)
# Get a HTS inference component
hts_inference_component = ml_client_registry.components.get(
name='automl_hts_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML HTS Forecasting Pipeline")
def hts_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
forecast_mode="rolling",
forecast_step=1,
forecast_level="SKU",
allocation_method='proportions_of_historical_average'
):
hts_train = hts_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
max_nodes=max_nodes
)
hts_inference = hts_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=hts_train.outputs.run_output,
forecast_level=forecast_level,
allocation_method=allocation_method,
forecast_mode=forecast_mode,
forecast_step=forecast_step
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=hts_inference.outputs.evaluation_data,
ground_truth=hts_inference.outputs.evaluation_data,
evaluation_config=hts_inference.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Теперь мы создадим конвейер с помощью функции фабрики, предполагая, что обучающие и тестовые данные находятся в локальных папках и ./data/train./data/testсоответственно. Наконец, мы задали вычисления по умолчанию и отправим задание, как показано в следующем примере:
pipeline_job = hts_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_hts.yml"
)
)
pipeline_job.settings.default_compute = "cluster-name"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
После завершения задания метрики оценки можно скачать локально с помощью той же процедуры, что и в конвейере единого обучения.
Кроме того, см. более подробный пример прогнозирования спроса с помощью иерархической записной книжки временных рядов.
Примечание.
Компоненты обучения и вывода HTS условно разделяют данные в соответствии с параметром hierarchy_column_names , чтобы каждая секция была в собственном файле. Этот процесс может быть очень медленным или неудачным, если данные очень большие. В этом случае рекомендуется секционирование данных вручную перед выполнением обучения или вывода HTS.
Прогнозирование в масштабе: распределенное обучение DNN
- Сведения о том, как работает распределенное обучение для задач прогнозирования, см . в нашей статье по прогнозированию в масштабе.
- Сведения о примерах кода см. в разделе статьи о распределенном обучении по настройке табличных данных .
Примеры записных книжек
Подробные примеры кода для расширенной настройки прогнозирования см. в записных книжках примеров прогнозирования, в том числе:
- Примеры конвейера прогнозирования спроса
- Модели машинного обучения.
- Контроль сплошности и конструирование признаков
- Настройка вручную для функций агрегирования окон и задержки
Следующие шаги
- Узнайте больше о развертывании модели AutoML в подключенной конечной точке.
- Узнайте о том, что такое интерпретируемость: пояснения к модели в автоматизированном машинном обучении (предварительная версия).
- Узнайте, как AutoML создает модели прогнозирования.
- Узнайте о прогнозировании в масштабе.
- Узнайте, как настроить AutoML для различных сценариев прогнозирования.
- Узнайте о выводе и оценке моделей прогнозирования.