Использование панели мониторинга ответственного ИИ в Студия машинного обучения Azure
Панели мониторинга "Ответственное применение ИИ" связаны с зарегистрированными моделями. Чтобы просмотреть панель мониторинга "Ответственное применение ИИ", перейдите в реестр моделей и выберите зарегистрированную модель, для которой вы создали панель мониторинга "Ответственное применение ИИ". Затем откройте вкладку "Ответственный ИИ" , чтобы просмотреть список созданных панелей мониторинга.

Вы можете настроить несколько панелей мониторинга и присоединить их к зарегистрированной модели. К каждой панели "Ответственное применение ИИ" можно подключить различные сочетания компонентов (интерпретируемость, анализ ошибок, анализ причинно-следственных связей и т. д.). На следующем рисунке показана настройка панели мониторинга и компоненты, созданные в ней. На каждой панели мониторинга можно просматривать или скрывать различные компоненты в самом пользовательском интерфейсе панели мониторинга.

Выберите имя панели мониторинга, чтобы открыть ее во весь экран в браузере. Чтобы вернуться к списку панелей мониторинга, можно в любое время выбрать Назад к просмотру сведений о модели.

Полная функциональность с интегрированным вычислительным ресурсом
Для некоторых функций панели мониторинга ответственного применения ИИ требуются динамические и оперативные вычисления в режиме реального времени (например, анализ "что если"). Без подключения вычислительного ресурса к панели мониторинга некоторые функции могут отсутствовать. Подключении к вычислительному ресурсу обеспечит полную функциональность панели мониторинга "Ответственное применение ИИ" для следующих компонентов:
- Анализ ошибок
- Если задать для глобальной когорты данных любую интересующую когорту, дерево ошибок будет обновлено, а не отключено.
- Поддерживается выбор других метрик ошибок или производительности.
- Поддерживается выбор любого подмножества признаков для обучения карты дерева ошибок.
- Поддерживается изменение минимального количества выборок, необходимых для каждого конечного объекта и глубины дерева ошибок.
- Поддерживается динамическое обновление тепловой карты для двух признаков.
- Важность функции
- Поддерживается график индивидуального условного ожидания (ICE) на вкладке важности отдельных признаков.
- Противоречащие фактам предположения "что если"
- Поддерживается создание новой гипотетической точки данных "что если", чтобы понять минимальные изменения, необходимые для достижения желаемого результата.
- Анализ причинно-следственных связей
- Поддерживается выбор любой отдельной точки данных, изменение ее признаков обработки и просмотр ожидаемого причинно-следственного результата причинно-следственной связи "что если" (только для сценариев регрессионного машинного обучения).
Эти сведения также можно найти на странице панели мониторинга ответственного применения ИИ. Для этого щелкните значок Сведения, как показано на следующем рисунке:

Включение полной функциональности панели мониторинга "Ответственное применение ИИ"
Выберите выполняющийся вычислительный экземпляр в раскрывающемся списке вычислений в верхней части панели мониторинга. Если у вас нет запущенных вычислений, создайте новый вычислительный экземпляр, выбрав знак плюса (+) рядом с раскрывающимся списком. Вы также можете нажать кнопку Запуск вычислений, чтобы запустить остановленный вычислительный экземпляр. Создание или запуск вычислительного экземпляра может занять несколько минут.

Как только вычисления перейдут в состояние Выполняется, панель мониторинга "Ответственное применение ИИ" начнет подключаться к вычислительному экземпляру. Для этого в выбранном вычислительном экземпляре будет создан процесс терминала, а на терминале будет запущена конечная точка панели "Ответственное применение ИИ". Выберите Просмотреть выходные данные терминала, чтобы просмотреть текущий процесс терминала.

Когда панель мониторинга "Ответственное применение ИИ" подключена к вычислительному экземпляру, вы увидите зеленую панель сообщений, теперь эта панель мониторинга полностью функциональна.

Если процесс затянется и через какое-то время панель мониторинга "Ответственное применение ИИ" так и не подключится к вычислительному экземпляру или отобразится красная панель сообщений об ошибке, это означает, что есть проблемы с запуском конечной точки панели "Ответственное применение ИИ". Выберите Просмотрите выходные данные терминала и прокрутите вниз, чтобы просмотреть сообщение об ошибке.

Если у вас возникли трудности с определением способа устранения проблемы "Не удалось подключиться к вычислительному экземпляру", щелкните значок с улыбкой в правом верхнем углу. Отправьте нам сообщение обо всех ошибках или проблемах, с которыми вы столкнулись. Вы можете добавить снимок экрана и указать свой адрес электронной почты в форме для отзыва.




Обзор пользовательского интерфейса панели мониторинга "Ответственное применение ИИ"
Панель мониторинга "Ответственное применение ИИ" включает надежный и широкий набор визуализаций и функциональных возможностей для анализа модели машинного обучения или принятия бизнес-решений на основе данных:
- Глобальные элементы управления
- Анализ ошибок
- Общие сведения о модели и метрики справедливости
- Анализ данных
- Важность признаков (пояснения к модели)
- Противоречащие фактам предположения "что если"
- Анализ причинно-следственных связей
Глобальные элементы управления
В верхней части панели мониторинга можно создавать когорты (подгруппы точек данных, имеющих общие указанные характеристики), чтобы сфокусировать анализ в каждом компоненте. Имя когорты, применяемой в данный момент к панели мониторинга, всегда отображается в левом верхнем углу панели мониторинга. Представление по умолчанию на панели мониторинга — это весь набор данных, который называется Все данные (по умолчанию).

- Параметры когорты. Позволяют просматривать и изменять сведения о каждой когорте на боковой панели.
- Конфигурация панели мониторинга. Позволяет просматривать и изменять макет общей панели мониторинга на боковой панели.
- Переключатель когорты. Позволяет выбрать другую когорту и просмотреть статистику во всплывающем окне.
- Новая когорта. Позволяет создавать и добавлять новую когорту на панель мониторинга.
Выберите Параметры когорты, чтобы открыть панель со списком когорт, где можно создавать, редактировать, дублировать или удалять когорты.

Выберите Новая когорта в верхней части панели мониторинга или в параметрах когорты, чтобы открыть новую панель с параметрами для фильтрации по следующим параметрам:
- Индекс. Фильтрация по позиции точки данных в полном наборе данных.
- Набор данных. Фильтрация по значению определенного признака в наборе данных.
- Прогнозируемое значение Y. Фильтрация по прогнозу, сделанному моделью.
- Истинное значение Y. Фильтрация по фактическому значению целевого признака.
- Ошибка (регрессия). Фильтрация по ошибкам или результатам классификации (классификация): фильтрация по типу и точности классификации.
- Категориальные значения. Фильтрация по списку значений, которые должны быть включены.
- Числовые значения. Фильтрация по логическим операциям со значениями (например, выбрать точки данных, где age < 64).

Вы можете присвоить новой когорте набора данных имя, выбрать Добавить фильтр, чтобы добавить каждый фильтр, который необходимо использовать, а затем выполнить одно из следующих действий:
- Нажать кнопку Сохранить, чтобы сохранить новую когорту в списке когорт.
- Нажать кнопку Сохранить и переключить, чтобы сохранить и немедленно переключить глобальную когорту панели мониторинга на только что созданную когорту.

Выберите конфигурацию панели мониторинга, чтобы открыть панель со списком компонентов, настроенных на панели мониторинга. Вы можете скрыть компоненты на панели мониторинга, щелкнув значок корзины, как показано на следующем рисунке:

Вы можете добавить компоненты обратно на панель мониторинга, используя синий круглый значок со знаком плюс (+) в разделителе между каждым компонентом, как показано на следующем рисунке:

Анализ ошибок
В следующих разделах описано, как интерпретировать и использовать карты дерева ошибок и тепловые карты.
Карта дерева ошибок
Первая панель компонента "Анализ ошибок" — это карта дерева, которая показывает, как сбой модели распределяется между различными когортами с помощью визуализации дерева. Выберите любой узел, чтобы просмотреть путь прогнозирования для признаков, в которых обнаружена ошибка.

- Представление тепловой карты. Осуществляет переключение на визуализацию тепловой карты распределения ошибок.
- Список признаков. Позволяет изменять признаки, используемые в тепловой карте, с помощью боковой панели.
- Охват ошибок. Отображает процент всех ошибок в наборе данных, сосредоточенном на выбранном узле.
- Ошибка (регрессия) или частота ошибок (классификация). Отображает ошибку или процент сбоев всех точек данных в выбранном узле.
- Узел. Представляет когорту набора данных, потенциально с примененными фильтрами, а также количество ошибок из общего числа точек данных в когорте.
- Линия заполнения. Визуализирует распределение точек данных в дочерние когорты на основе фильтров с числом точек данных, представленных через толщину линии.
- Сведения о выборе. Содержат сведения о выбранном узле на боковой панели.
- Сохранить как новую когорту. Создает новую когорту с заданными фильтрами.
- Экземпляры в базовой когорте. Отображает общее количество точек во всем наборе данных, а также количество правильно и неправильно прогнозируемых точек.
- Экземпляры в выбранной когорте. Отображает общее количество точек в выбранном узле, а также количество правильно и неправильно прогнозируемых точек.
- Путь прогнозирования (фильтры). Список фильтров, применяемых к полному набору данных для создания этой меньшей когорты.
Нажмите кнопку списка компонентов, чтобы открыть боковую панель, из которой можно переобучить дерево ошибок для определенных признаков.

- Поиск признаков. Позволяет находить определенные признаки в наборе данных.
- Признаки. Вносит имя признака в список набора данных.
- Важность. Рекомендации о том, насколько признак может быть связан с ошибкой. Вычисляется с помощью оценки взаимной информации между признаком и ошибкой на метках. Эту оценку можно использовать для определения того, какие признаки следует выбрать в анализе ошибок.
- Флажок. Позволяет добавлять или удалять признак с карты дерева.
- Максимальная глубина. Максимальная глубина визуализации суррогатного дерева, обученного на ошибках.
- Количество листьев. Количество листьев суррогатного дерева, обученного на ошибках.
- Минимальное количество выборок на одном листе. Минимальное количество данных, необходимых для создания одного листового узла.
Тепловая карта ошибок
Выберите вкладку Тепловая карта, чтобы переключиться на другое представление ошибки в наборе данных. Вы можете выбрать одну или несколько ячеек тепловой карты и создать новые когорты. Для создания тепловой карты можно выбрать не более двух признаков.

- Ячейки. Отображает количество выбранных ячеек.
- Покрытие ошибок. Отображает процентную долю всех ошибок, сосредоточенных в выбранных ячейках.
- Коэффициент ошибок. Отображает процент сбоев всех точек данных в выбранных ячейках.
- Признаки оси. Выбирает пересечение признаков для отображения на тепловой карте.
- Ячейки. Представляет когорту набора данных с примененными фильтрами, а также процент ошибок из общего числа точек данных в когорте. Синий контур указывает на выбранные ячейки, а темнота красного цвета означает концентрацию сбоев.
- Путь прогнозирования (фильтры). Перечисляет фильтры, применяемые к полному набору данных для каждой выбранной когорты.
Общие сведения о модели и метрики справедливости
Компонент "Обзор модели" предоставляет комплексный набор метрик производительности и справедливости для оценки модели, а также ключевые метрики неравенства в производительности вместе с указанными когортами признаков и наборов данных.
Когорты наборов данных
Вкладка Когорты наборов данных позволяет исследовать модель, сравнивая ее производительность для различных пользовательских когорт наборов данных (их можно открыть с помощью значка Параметры когорты в правом верхнем углу панели мониторинга).

- Нужна помощь в выборе метрик: нажмите этот значок, чтобы открыть панель для получения дополнительных сведений о доступных метриках производительности модели, которые можно отобразить в таблице. Вы сможете легко выбрать метрики для просмотра, в раскрывающемся списке с поддержкой выбора нескольких элементов.
- Отображение тепловой карты: используется для отображения или скрытия визуализации тепловой карты в таблице. Градиент тепловой карты соответствует диапазону, нормализованному между наименьшим и наибольшим значением в каждом столбце.
- Таблица метрик для каждой когорты набора данных: таблица со столбцами для когорт набора данных, размером выборки и выбранными метриками производительности модели для каждой когорты.
- Линейчатая диаграмма для визуализации отдельных метрик: просмотр средней абсолютной погрешности по когортам для простого сравнения.
- Выберите метрику (ось x): нажмите эту кнопку, чтобы выбрать метрики для просмотра на линейчатой диаграмме.
- Выберите когорты (ось y): нажмите эту кнопку, чтобы выбрать когорты для просмотра на линейчатой диаграмме. Параметр Когорта признаков может быть недоступен, если вы предварительно не укажете нужные признаки на вкладке "Когорта признаков" компонента.
Выберите Помочь мне выбрать метрики, чтобы открыть панель со списком метрик производительности модели и их определениями, которые помогут выбрать нужные метрики для просмотра.
| Сценарий машинного обучения | Метрики |
|---|---|
| Регрессия | Средняя абсолютная погрешность, среднеквадратическая погрешность, коэффициент детерминации, среднее прогнозирование. |
| Классификация | Правильность, точность, полнота, показатель F1, частота ложноположительных результатов, частота ложноотрицательных результатов, степень отбора. |
Когорты признаков
На панели Когорты признаков можно исследовать модель, сравнивая ее производительность по задаваемым пользователем признакам, требующим и не требующим особого обращения (например, по когортам разных гендеров, рас и уровней дохода).

Нужна помощь в выборе метрик: нажмите этот значок, чтобы открыть панель для получения дополнительных сведений о доступных метриках, которые можно отобразить в таблице. Вы сможете легко выбрать метрики для просмотра в раскрывающемся списке с поддержкой выбора нескольких элементов.
Нужна помощь в выборе признаков: нажмите на этот значок, чтобы открыть панель с дополнительными сведениями о доступных для показа в таблице признаках ниже с соответствующими описаниями и возможностью группирования (см. ниже). Вы сможете легко настроить признаки для просмотра, выбирая их и отменяя их выбор в раскрывающемся списке с несколькими вариантами.

Показать тепловую карту: включение и выключение визуализации тепловой карты. Градиент тепловой карты соответствует диапазону, нормализованному между наименьшим и наибольшим значением в каждом столбце.
Таблица метрик для каждой когорты признаков: таблица со столбцами для когорт признаков (вложенная когорта выбранного признака), размером выборки для каждой когорты и метриками производительности модели, выбранными для каждой когорты признаков.
Метрики справедливости и различий: таблица, которая соответствует таблице метрик и в которой показано максимальное различие или максимальное соотношение оценок производительности между любыми двумя когортами признаков.
Линейчатая диаграмма для визуализации отдельных метрик: просмотр средней абсолютной погрешности по когортам для простого сравнения.
Выберите когорты (ось y): нажмите эту кнопку, чтобы выбрать когорты для просмотра на линейчатой диаграмме.
При выборе команды Выбрать когорты открывается панель, на которой можно отобразить сравнение выбранных когорт наборов данных или когорт признаков в зависимости от того, что выбрано ниже в раскрывающемся списке с несколькими вариантами. Нажмите кнопку Подтвердить, чтобы сохранить изменения в представлении линейчатой диаграммы.

Выберите метрику (ось x): нажмите эту кнопку, чтобы выбрать метрики для просмотра на линейчатой диаграмме.


Анализ данных
С помощью компонента анализа данных область представления таблиц отображает представление таблицы набора данных для всех функций и строк.
На панели представления диаграммы показаны статистические и отдельные графики точек данных. Статистику данных можно анализировать по оси X и оси Y с помощью фильтров, таких как прогнозируемый результат, функции набора данных и группы ошибок. Это представление помогает понять чрезмерное представление и недопредставление в наборе данных.

Выбор когорты набора данных для изучения. Укажите, для какой когорты набора данных из вашего списка когорт вы хотите просмотреть статистику данных.
Ось X: отображает тип значения абсциссы на графике. Измените значения, нажав кнопку, чтобы открыть боковую панель.
Ось Y: отображает тип значения ординаты на графике. Измените значения, нажав кнопку, чтобы открыть боковую панель.
Тип диаграммы: указывает тип диаграммы. Выберите агрегированные диаграммы (линейчатые диаграммы) или отдельные точки данных (точечная диаграмма).
При выборе параметра Отдельные точки данных в разделе Тип диаграммы происходит переход к разъединенному представлению данных с добавлением цветовой оси.

Важность признаков (пояснения к модели)
С помощью компонента объяснения модели можно увидеть, какие функции наиболее важны в прогнозах модели. Вы можете просмотреть, какие функции повлияли на прогноз модели в целом на панели " Агрегатная важность признаков" или просмотреть значения функций для отдельных точек данных на панели " Важность отдельных компонентов".
Агрегированная важность признаков (глобальные пояснения)

Основные признаки (K). Отображаются наиболее важные глобальные признаки для прогнозирования, которые можно изменить с помощью ползунка.
Совокупная важность признаков. Визуализирует вес каждого признака, влияющего на решения модели для всех прогнозов.
Сортировать по. Можно выбрать, по какой важности когорты следует сортировать график совокупной важности признаков.
Тип диаграммы. Можно выбрать между представлением гистограммы средней важности для каждого признака и блочной диаграммы важности для всех данных.
При выборе одного из признаков на гистограмме создается график зависимости, как показано на следующем рисунке. Этот график зависимости показывает связь значений признаков с соответствующими значениями важности признаков, влияющих на прогноз модели.
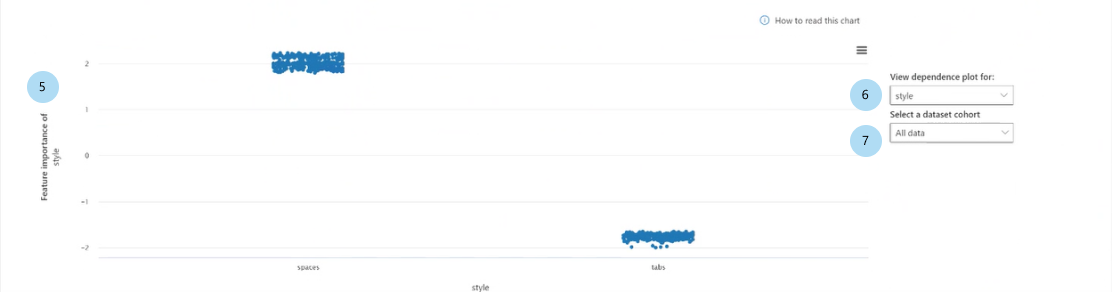
Важность признака [признак] (регрессия) или важность признака [признак] в [прогнозируемый класс] (классификация). Отображает важность определенного признака для прогнозов. Для сценариев регрессии значения важности выражены с точки зрения результата, поэтому положительная важность признаков означает, что признак способствовал достижению результата. Если признак препятствовал достижению результата, ему присваивается отрицательная важность. Для сценариев классификации положительная важность признака означает, что значение признака способствует прогнозированию класса указанному по оси Y, а отрицательная важность признака означает, что он не способствует прогнозированию класса.
Показать график зависимостей для: позволяет выбрать признак, важность которого требуется отобразить.
Выберите когорту набора данных: позволяет выбрать когорту, важность которой вы хотите отобразить.

Важность отдельных признаков (локальные пояснения)
На следующем рисунке показано, как признаки влияют на прогнозы, сделанные на основе определенных точек данных. Для сравнения важности признаков можно выбрать до пяти точек данных.

Таблица выбора точек: просмотр точек данных и выбор до пяти точек для отображения на диаграмме важности признаков или на графике ICE под таблицей.

График важности признака. Гистограмма важности каждого признака для прогноза модели по выбранным точкам данных.
- Основные признаки (K). Можно указать с помощью ползунка количество признаков, для которых будет отображаться важность.
- Сортировать по. Можно выбрать точку (из отмеченных выше), важность признаков которой отображается в порядке убывания на графике важности признаков.
- Просмотр абсолютных значений: переключатель для сортировки линейчатой диаграммы по абсолютным значениям. Это позволяет видеть наиболее важные признаки независимо от их положительного или отрицательного влияния.
- Гистограмма. Отображает важность каждого признака в наборе данных для прогноза модели выбранных точек данных.
График индивидуального условного ожидания (ICE). Переключение на график ICE, показывающий прогнозы модели для диапазона значений определенного признака.

- Мин. (числовые признаки). Указывает нижнюю границу диапазона прогнозов на графике ICE.
- Макс. (числовые признаки). Указывает верхнюю границу диапазона прогнозов на графике ICE.
- Шаги (числовые признаки). Указывает количество точек для отображения прогнозов в пределах интервала.
- Значения признаков (категориальные признаки). Указывает, для каких категориальных значений признаков необходимо отображать прогнозы.
- Признак. Указывает признак, для которого отображаются прогнозы.
Противоречащие фактам предположения "что если"
Анализ гипотетического предположения предоставляет разнообразный набор примеров что если, созданных путем минимального изменения значений признаков для получения желаемого класса прогноза (классификация) или диапазона (регрессия).

Выбор точки. Выбирает точку для создания гипотетического предположения и для отображения на графике наиболее важных признаков под ними.
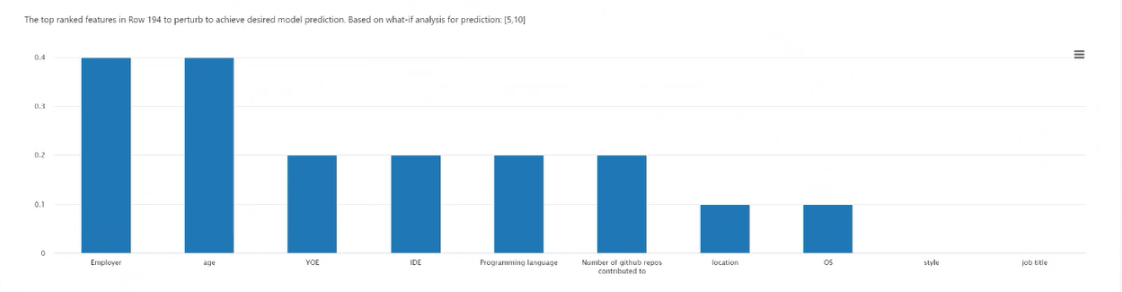
График наиболее важных признаков. Отображает признаки в порядке убывания средней частоты, которые нужно изменить, чтобы создать разнообразный набор гипотетических предположений требуемого класса. Чтобы построить эту диаграмму, необходимо создать по крайней мере 10 различных гипотетических предположений для каждой точки данных, поскольку при меньшем количестве гипотетических предположений точность будет ниже.
Выбранная точка данных. Выполняются те же действия, что и при выборе точки в таблице, за исключением раскрывающегося меню.
Требуемый класс для гипотетических предположений. Указывает класс или диапазон для создания гипотетических предположений.
Создать гипотетическое предположение "что, если". Открывает панель для создания гипотетической точки данных "что если".
При нажатии кнопки Создать гипотетическое предположение "что, если" откроется полная панель окна.
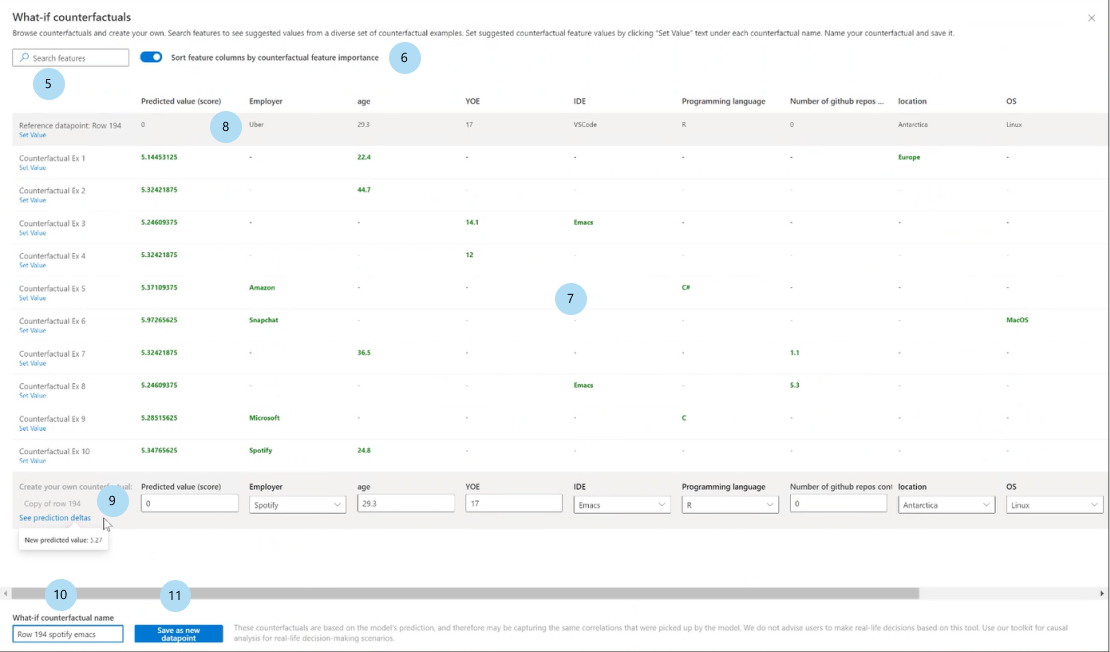
Поиск признаков. Ищет признаки для наблюдения и изменения значений.
Сортировка гипотетических предположений по ранжированным признакам. Сортирует гипотетические примеры в порядке эффекта искажения. (См. также график основных ранжированных признаков, рассмотренный ранее.)
Примеры гипотез. Перечисляет значения признаков примеров гипотетических предположений с требуемым классом или диапазоном. Первая строка — исходная эталонная точка данных. Выберите Задать значение, чтобы задать все значения собственной точки гипотетических данных в нижней строке со значениями предварительно созданного гипотетического примера.
Прогнозируемое значение или класс. Содержит прогноз модели гипотетического класса с учетом этих измененных признаков.
Создать собственную гипотезу. Позволяет изменять собственные признаки для изменения гипотезы. Признаки, исходные значения которых были изменены, обозначаются полужирным шрифтом (например, работодатель и язык программирования). Нажмите кнопку Просмотреть дельту прогноза, чтобы увидеть разницу между новым значением прогноза и исходной точкой данных.
Имя гипотезы "что если". Позволяет указать имя гипотезы уникальным образом.
Сохранить как новую точку данных. Сохраняет созданную гипотезу.


Анализ причинно-следственных связей
В следующих разделах описывается, как считывать причинный анализ набора данных при выборе пользовательских методов лечения.
Совокупные причинно-следственные эффекты
Выберите вкладку Совокупные причинно-следственные эффекты компонента "Анализ причинно-следственных связей", чтобы отобразить средние причинно-следственные эффекты для предопределенных признаков обработки (признаки, которые вы хотите обработать, чтобы оптимизировать результат).
Примечание.
Глобальные функции когорты не поддерживаются для компонента анализа причинно-следственных связей.

Таблица прямых совокупных причинно-следственных эффектов. Отображает причинно-следственный эффект каждого признака, объединенных во всем наборе данных, а также соответствующую статистику достоверности.
- Непрерывные обработки. В среднем по этой выборке увеличение этого признака на одну единицу приведет к увеличению вероятности класса на X единиц, где X — причинно-следственный эффект.
- Двоичные обработки. В среднем по этой выборке, включение этого признака приведет к увеличению вероятности класса на X единиц, где X — причинно-следственный эффект.
График прямого совокупного причинно-следственного эффекта. Визуализация причинно-следственных эффектов и доверительного уровня интервалов точек в таблице.
Отдельные причинно-следственные эффекты и причинно-следственная связь "что если"
Для получения подробного представления о причинно-следственных связях в отдельной точке данных перейдите на вкладку Отдельная причинно-следственная операция "что если".

- Ось X. Выбирает признак для отображения по оси X.
- Ось Y. Выбирает признак для отображения по оси Y.
- График причинно-следственных связей отдельного признака. Отображает точки в таблице в виде точечной диаграммы, на котором можно выбрать точки данных для анализа причинно-следственной связи "что если" и просмотра отдельных причинно-следственных эффектов (ниже).
- Задайте новое значение лечения:
- (числовой). Отображает ползунок для изменения значения числового признака в качестве реального вмешательства.
- (категориальный). Отображает раскрывающийся список для выбора значения категориального признака.
Политика обработки
Выберите вкладку Политика обработки, чтобы переключиться на представление, помогающее определить реальные вмешательства и показать методы обработки, которые необходимо применить для достижения определенного результата.

Установить признак обработки. Выбирает признак для изменения в качестве реального вмешательства.
Рекомендуемая глобальная политика обработки. Отображает рекомендуемые вмешательства для когорт данных, чтобы улучшить целевое значение признака. Таблицу можно считывать слева направо, при этом набор данных сегментируется сначала по строкам, а затем по столбцам. Например, для 658 человек, чьим работодателем не является Snapchat, а их языком не является JavaScript, рекомендуемая политика обработки заключается в увеличении количества репозиториев GitHub, в которые они добавляют свои программы.
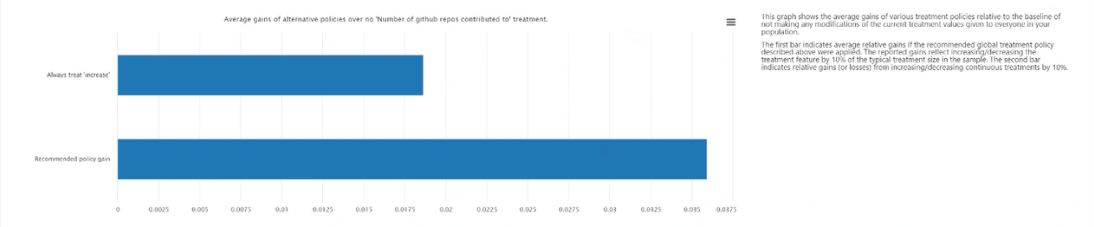
Средний выигрыш от альтернативных политик по сравнению с постоянным применением обработок. Отображает значение целевого признака в виде гистограммы среднего выигрыша в вашем результате для рекомендуемой выше политики обработки по сравнению с постоянным применением обработки.
Рекомендуемая политика индивидуального лечения:
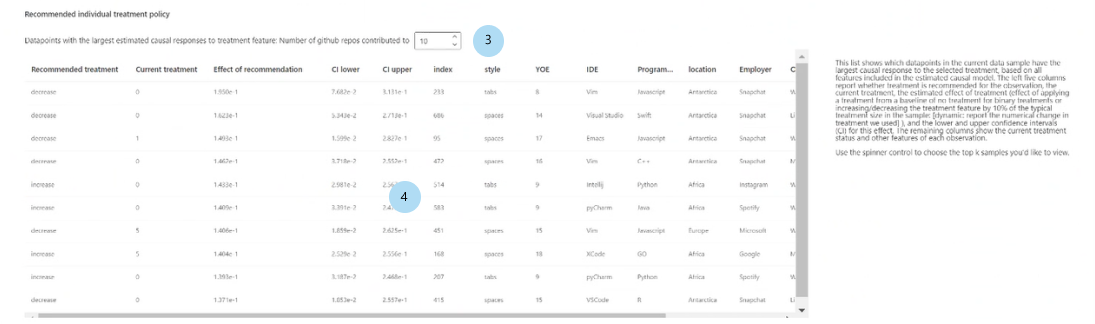
Показать лучшие выборки данных (К), упорядоченных согласно причинно-следственным эффектам, для рекомендуемого признака обработки. Выбор количества точек данных для отображения в таблице.
Таблица рекомендуемой индивидуальной политики обработки. Списки в порядке убывания причинно-следственного эффекта, точки данных, целевые признаки которых будут наиболее улучшены посредством вмешательства.


Следующие шаги
- Резюмируйте аналитику ответственного применения ИИ и делитесь эти данными с помощью системы показателей ответственного применения ИИ в формате PDF.
- Ознакомьтесь с дополнительными сведениями о концепциях и методах, на основе которых работает панель мониторинга ответственного применения ИИ.
- Просмотрите примеры блокнотов YAML и Python для создания панели мониторинга "Ответственное применение ИИ" с помощью YAML или Python.
- Ознакомьтесь с возможностями панели мониторинга ответственного применения ИИ, просмотрев эту интерактивную веб-демонстрацию лаборатории ИИ.
- Дополнительные сведения об использовании панели мониторинга и системы показателей ответственного применения ИИ для отладки данных и моделей и принятия более обоснованных решений см. в этой записи блога Tech Community.
- Чтобы узнать об использовании панели мониторинга и системы показателей ответственного применения ИИ Национальной службой здравоохранения (NHS) Великобритании, ознакомьтесь с реальной историей клиента.