Интерактивная обработка данных с помощью Apache Spark в Машинное обучение Azure
Обработка данных становится одним из наиболее важных шагов в проектах машинного обучения. Интеграция Машинное обучение Azure с Azure Synapse Analytics предоставляет доступ к пулу Apache Spark с поддержкой Azure Synapse для интерактивных данных с помощью Машинное обучение Azure Записных книжек.
В этой статье вы узнаете, как выполнять обработку данных с помощью
- Бессерверные вычисления Spark
- Присоединенный пул Synapse Spark
Необходимые компоненты
- Подписка Azure; Если у вас нет подписки Azure, создайте бесплатную учетную запись перед началом работы.
- Рабочая область Машинного обучения Azure. См.раздел Создание ресурсов рабочей области.
- Учетная запись хранения Azure Data Lake служба хранилища (ADLS) 2-го поколения. См. статью "Создание учетной записи хранения Azure Data Lake служба хранилища (ADLS) 2-го поколения.
- (Необязательно): Azure Key Vault. См. статью "Создание Azure Key Vault".
- (Необязательно): субъект-служба. См. статью "Создание субъекта-службы".
- (Необязательно): подключенный пул Synapse Spark в рабочей области Машинное обучение Azure.
Прежде чем запускать задачи обработки данных, ознакомьтесь с процессом хранения секретов
- Ключ доступа к учетной записи хранения BLOB-объектов Azure
- Маркер подписанного URL-адреса (SAS)
- Сведения о субъекте-службе Azure Data Lake служба хранилища (ADLS) 2-го поколения
в Azure Key Vault. Кроме того, необходимо знать, как обрабатывать назначения ролей в учетных записях хранения Azure. В следующих разделах рассматриваются эти понятия. Затем мы рассмотрим сведения об интерактивном обработке данных с помощью пулов Spark в Машинное обучение Azure записных книжек.
Совет
Сведения о конфигурации назначения ролей учетной записи хранения Azure или доступ к данным в учетных записях хранения с помощью сквозного руководства удостоверения пользователя см. в статье "Добавление назначений ролей в учетных записях хранения Azure".
Интерактивное взаимодействие с данными с помощью Apache Spark
Машинное обучение Azure предоставляет бессерверные вычислительные ресурсы Spark и присоединенный пул Synapse Spark для интерактивных данных с помощью Apache Spark в Машинное обучение Azure Notebook. Для бессерверных вычислений Spark не требуется создание ресурсов в рабочей области Azure Synapse. Вместо этого полностью управляемое бессерверное вычисление Spark становится доступным непосредственно в Машинное обучение Azure Записных книжек. Использование бессерверных вычислений Spark — самый простой подход к доступу к кластеру Spark в Машинное обучение Azure.
Бессерверные вычисления Spark в записных книжках Машинное обучение Azure
Бессерверные вычисления Spark доступны в Машинное обучение Azure Записных книжек по умолчанию. Чтобы получить доступ к ней в записной книжке, выберите бессерверные вычисления Spark в разделе Машинное обучение Azure Бессерверный Spark в меню выбора вычислений.
Пользовательский интерфейс записных книжек также предоставляет параметры конфигурации сеанса Spark для бессерверных вычислений Spark. Чтобы настроить сеанс Spark, выполните действия.
- Выберите " Настройка сеанса " в верхней части экрана.
- Выберите версию Apache Spark в раскрывающемся меню.
Важно!
Среда выполнения Azure Synapse для Apache Spark: объявления
- Среда выполнения Azure Synapse для Apache Spark 3.2:
- Дата объявления EOLA: 8 июля 2023 г.
- Дата окончания поддержки: 8 июля 2024 г. После этой даты среда выполнения будет отключена.
- Для непрерывной поддержки и оптимальной производительности рекомендуется перенести в Apache Spark 3.3.
- Среда выполнения Azure Synapse для Apache Spark 3.2:
- Выберите тип экземпляра в раскрывающемся меню. В настоящее время поддерживаются следующие типы экземпляров:
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
- Введите значение времени ожидания сеанса Spark в минутах.
- Выбор того, следует ли динамически выделять исполнителей
- Выберите количество исполнителей для сеанса Spark.
- Выберите размер исполнителя в раскрывающемся меню.
- Выберите размер драйвера в раскрывающемся меню.
- Чтобы использовать файл Conda для настройки сеанса Spark, проверка папку "Отправить файл conda" проверка box. Затем нажмите кнопку "Обзор" и выберите файл Conda с нужной конфигурацией сеанса Spark.
- Добавьте свойства параметров конфигурации, входные значения в текстовые поля "Свойство и значение" и нажмите кнопку "Добавить".
- Нажмите Применить.
- Выберите "Остановить сеанс" во всплывающем окну "Настройка нового сеанса"
Изменения конфигурации сеанса сохраняются и становятся доступными для другого сеанса записной книжки, запущенного с помощью бессерверных вычислений Spark.
Совет
Если вы используете пакеты Conda уровня сеанса, вы можете улучшить время холодного запуска сеанса Spark, если задать для переменной spark.hadoop.aml.enable_cache конфигурации значение true. Холодный запуск сеанса с пакетами Conda уровня сеанса обычно занимает от 10 до 15 минут, когда сеанс начинается в первый раз. Однако последующий холодный сеанс начинается с переменной конфигурации, заданной значением true, обычно занимает три–пять минут.
Импорт и обработка данных из Azure Data Lake служба хранилища (ADLS) 2-го поколения
Вы можете получить доступ к данным и выполнять обработку данных, хранящихся в учетных записях хранения Azure Data Lake служба хранилища (ADLS) 2-го поколения с abfss:// помощью URI данных после одного из двух механизмов доступа к данным:
- Сквозное руководство по идентификации пользователя
- Доступ к данным на основе субъекта-службы
Совет
Для доступа к данным в учетной записи хранения Azure Data Lake служба хранилища (ADLS) 2-го поколения требуется наименьшее количество действий по настройке.
Чтобы начать интерактивные действия по обработке данных с помощью сквозного руководства удостоверения пользователя:
Убедитесь, что удостоверение пользователя имеет участника и служба хранилища назначения ролей участникаданных BLOB-объектов в учетной записи хранения Azure Data Lake служба хранилища (ADLS) 2-го поколения.
Чтобы использовать бессерверные вычисления Spark, выберите бессерверные вычисления Spark в разделе Машинное обучение Azure Бессерверный Spark в меню выбора вычислений.
Чтобы использовать подключенный пул Synapse Spark, выберите подключенный пул Synapse Spark в пулах Synapse Spark в меню выбора вычислений .
В этом примере кода для обработки титанических данных показано использование URI данных в формате
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>иpyspark.pandaspyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled", index_col="PassengerId", )Примечание.
В этом примере кода Python используется
pyspark.pandas. Поддерживается только среда выполнения Spark версии 3.2 или более поздней.
Чтобы выполнить обработку данных путем доступа через субъект-службу, выполните приведенные далее действия.
Убедитесь, что субъект-служба имеет участника и служба хранилища назначения ролей участникаданных BLOB-объектов в учетной записи хранения Azure Data Lake служба хранилища (ADLS) 2-го поколения.
Создайте секреты Azure Key Vault для идентификатора клиента субъекта-службы, идентификатора клиента и значений секрета клиента.
Выберите бессерверные вычисления Spark в разделе Машинное обучение Azure Бессерверный Spark в меню выбора вычислений или выберите подключенный пул Synapse Spark в пулах Synapse Spark в меню выбора вычислений.
Чтобы задать идентификатор клиента субъекта-службы, идентификатор клиента и секрет клиента в конфигурации, и выполнить следующий пример кода.
Вызов
get_secret()в коде зависит от имени Azure Key Vault и имен секретов Azure Key Vault, созданных для идентификатора клиента субъекта-службы, идентификатора клиента и секрета клиента. Задайте в конфигурации следующие соответствующие имена и значения свойств:- Свойство идентификатора клиента:
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Свойство секрета клиента:
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Свойство идентификатора клиента:
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Значение идентификатора клиента:
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary # Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>") # Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set( "fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_id, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_secret, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", )- Свойство идентификатора клиента:
Импорт и обработка данных с помощью URI данных в формате
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>, как показано в примере кода, с помощью титанических данных.
Импорт и обработка данных из хранилища BLOB-объектов Azure
Доступ к данным хранилища BLOB-объектов Azure можно получить с помощью ключа доступа к учетной записи хранения или маркера подписанного URL-адреса (SAS). Эти учетные данные следует хранить в Azure Key Vault в качестве секрета и задать их в качестве свойств в конфигурации сеанса.
Чтобы начать интерактивное взаимодействие с данными, выполните приведенные далее действия.
На панели Студия машинного обучения Azure слева выберите "Записные книжки".
Выберите бессерверные вычисления Spark в разделе Машинное обучение Azure Бессерверный Spark в меню выбора вычислений или выберите подключенный пул Synapse Spark в пулах Synapse Spark в меню выбора вычислений.
Чтобы настроить ключ доступа к учетной записи хранения или маркер подписанного URL-адреса (SAS) для доступа к данным в записных книжках Машинное обучение Azure:
Для ключа доступа задайте свойство
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net, как показано в этом фрагменте кода:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key )Для маркера SAS задайте свойство
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net, как показано в этом фрагменте кода:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", sas_token, )Примечание.
Для
get_secret()вызовов в приведенных выше фрагментах кода требуется имя Azure Key Vault и имена секретов, созданных для ключа доступа к учетной записи хранения BLOB-объектов Azure или маркера SAS.
Выполните код обработки данных в той же записной книжке. Форматируйте универсальный код ресурса (URI) данных следующим
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>образом:import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled", index_col="PassengerId", )Примечание.
В этом примере кода Python используется
pyspark.pandas. Поддерживается только среда выполнения Spark версии 3.2 или более поздней.
Импорт и обработка данных из хранилища данных Машинное обучение Azure
Чтобы получить доступ к данным из хранилища данных Машинное обучение Azure, определите путь к данным в хранилище данных с форматомazureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA> URI. Чтобы выполнять обработку данных из хранилища данных Машинное обучение Azure в сеансе записных книжек в интерактивном режиме:
Выберите бессерверные вычисления Spark в разделе Машинное обучение Azure Бессерверный Spark в меню выбора вычислений или выберите подключенный пул Synapse Spark в пулах Synapse Spark в меню выбора вычислений.
В этом примере кода показано, как считывать и выполнять обработку титанических данных из хранилища данных Машинное обучение Azure, используя
azureml://URIpyspark.pandasхранилища данных иpyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "azureml://datastores/workspaceblobstore/paths/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "azureml://datastores/workspaceblobstore/paths/data/wrangled", index_col="PassengerId", )Примечание.
В этом примере кода Python используется
pyspark.pandas. Поддерживается только среда выполнения Spark версии 3.2 или более поздней.
Хранилища данных Машинное обучение Azure могут получить доступ к данным с помощью учетных данных учетной записи хранения Azure.
- Ключ доступа
- Маркер SAS
- участник службы
или предоставьте доступ к данным без учетных данных. В зависимости от типа хранилища данных и базового типа учетной записи хранения Azure выберите соответствующий механизм проверки подлинности, чтобы обеспечить доступ к данным. В этой таблице перечислены механизмы проверки подлинности для доступа к данным в хранилищах данных Машинное обучение Azure:
| Storage account type | Доступ к данным без учетных данных | Механизм доступа к данным | Назначения ролей |
|---|---|---|---|
| Большой двоичный объект Azure | No | Ключ доступа или маркер SAS | Нет необходимых назначений ролей |
| Большой двоичный объект Azure | Да | Сквозное руководство по идентификации пользователя* | Удостоверение пользователя должно иметь соответствующие назначения ролей в учетной записи хранения BLOB-объектов Azure. |
| Azure Data Lake служба хранилища (ADLS) 2-го поколения | No | Субъект-служба | Субъект-служба должен иметь соответствующие назначения ролей в учетной записи хранения Azure Data Lake служба хранилища (ADLS) 2-го поколения |
| Azure Data Lake служба хранилища (ADLS) 2-го поколения | Да | Сквозное руководство по идентификации пользователя | Удостоверение пользователя должно иметь соответствующие назначения ролей в учетной записи хранения Azure Data Lake служба хранилища (ADLS) 2-го поколения. |
* Сквозное руководство пользователя работает для хранилищ данных без учетных данных, указывающих на учетные записи хранения BLOB-объектов Azure, только если обратимое удаление не включено.
Доступ к данным в общей папке по умолчанию
Общая папка по умолчанию подключена как к бессерверным вычислительным ресурсам Spark, так и к подключенным пулам Synapse Spark.
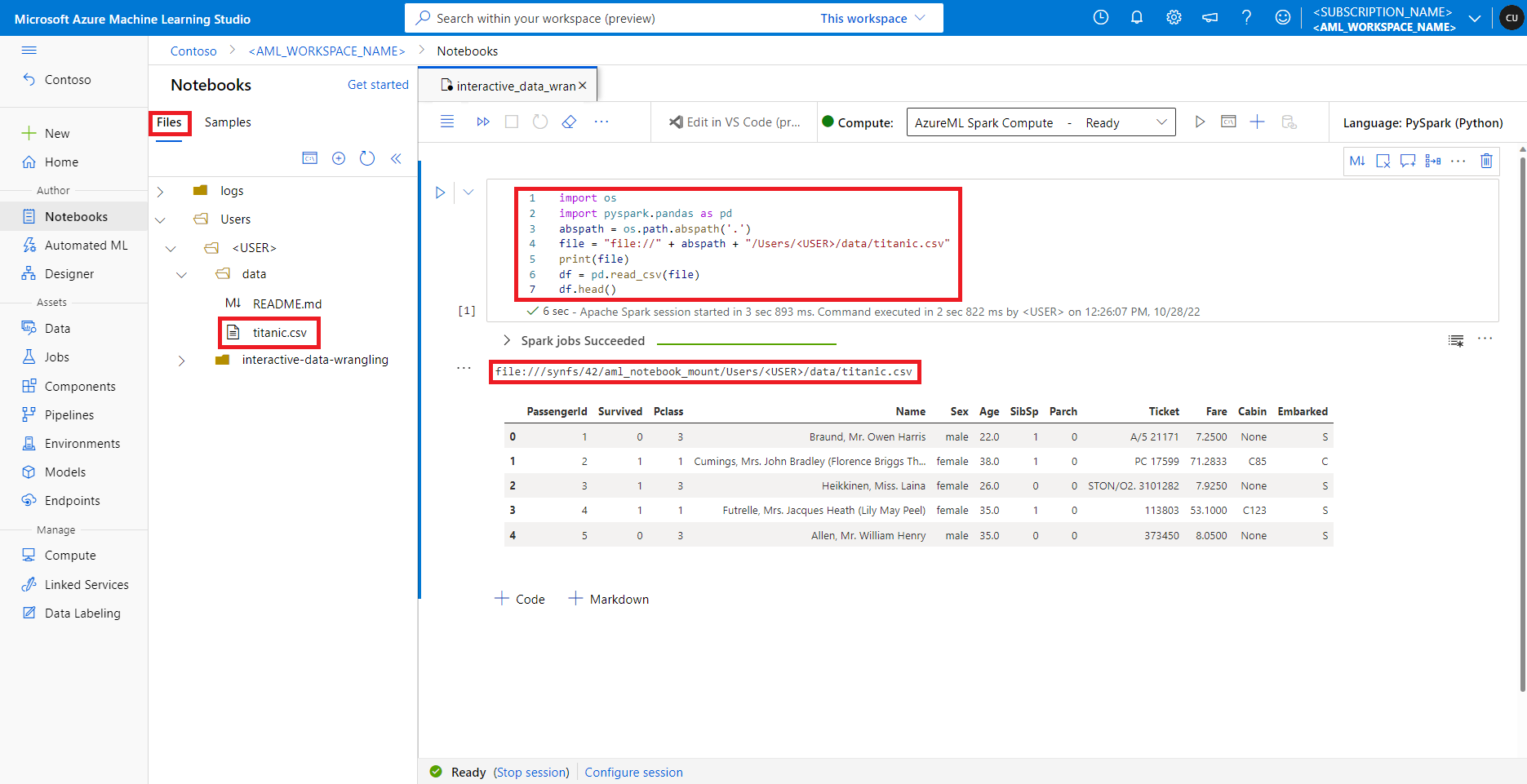
В Студия машинного обучения Azure файлы в общей папке по умолчанию отображаются в дереве каталогов на вкладке "Файлы". Код записной книжки может напрямую обращаться к файлам, хранящимся в этой общей папке с file:// протоколом, а также абсолютным путем к файлу без дополнительных конфигураций. В этом фрагменте кода показано, как получить доступ к файлу, хранящейся в общей папке по умолчанию:
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
abspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(
inputCols=["Age"],
outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
Примечание.
В этом примере кода Python используется pyspark.pandas. Поддерживается только среда выполнения Spark версии 3.2 или более поздней.