Учебник. Прогнозирование спроса с помощью автоматизированного машинного обучения без кода в студии машинного обучения Azure
Узнайте, как с помощью автоматизированного машинного обучения в Студии машинного обучения Azure создать прогностическую модель временных рядов, не написав ни одной строки кода. Эта модель прогнозирует спрос на аренду для службы общего доступа к велосипедам.
Вы не пишете код в этом руководстве, используйте интерфейс студии для обучения. Вы узнаете, как выполнить следующие задачи:
- создание и загрузка набора данных;
- настройка и выполнение эксперимента автоматического машинного обучения;
- Укажите параметры прогнозирования.
- анализ результатов эксперимента;
- развертывание лучшей модели.
Также опробуйте автоматизированное машинное обучение для таких типов моделей:
- Пример модели классификации без кода см. в руководстве по созданию модели классификации с использованием автоматизированного машинного обучения в службе "Машинное обучение Azure".
- Первый пример кода модели обнаружения объектов см. в руководстве по обучению модели обнаружения объектов с помощью AutoML и Python.
Необходимые компоненты
Рабочая область Машинного обучения Azure. См.раздел Создание ресурсов рабочей области.
Файл данных bike-no.csv.
Вход в Студию
В рамках этого учебника вы создадите эксперимент автоматизированного машинного обучения, который будет выполняться в Студии машинного обучения Azure — объединенном веб-интерфейсе, включающем в себя средства машинного обучения для выполнения сценариев обработки и анализа данных, основанных на всех уровнях навыков. Студия не поддерживается в браузерах Обозреватель Интернета.
Войдите в Студию машинного обучения Azure.
Выберите свою подписку и рабочую область, которую создали.
Выберите Приступая к работе.
На панели слева выберите Automated ML (Автоматизированное ML) в разделе Автор.
Выберите +Создать задание автоматизированного машинного обучения.
Создание и загрузка набора данных
Прежде чем настроить эксперимент, отправьте файл данных в рабочую область в виде набора данных Машинного обучения Azure. Это позволит правильно отформатировать данные для эксперимента.
В форме Выбор набора данных выберите элемент Из локальных файлов в раскрывающемся списке + Создать набор данных.
В форме Общие сведения присвойте набору данных имя и по желанию добавьте описание. По умолчанию следует использовать тип набора данных Табличный, так как автоматизированное машинное обучение в Студии машинного обучения Azure сейчас поддерживает только табличные наборы данных.
Выберите Далее внизу слева.
В форме Выбор хранилища данных и файлов выберите хранилище данных по умолчанию, которое было автоматически настроено при создании рабочей области workspaceblobstore (хранилище BLOB-объектов Azure). Это расположение хранилища, в котором вы отправляете файл данных.
Выберите элемент Отправка файлов в раскрывающемся списке Отправка.
Выберите файл bike-no.csv на локальном компьютере. Это тот файл, который вы скачали при подготовке необходимых компонентов.
Выберите Далее
Когда загрузка завершится, форма Настройки и предварительный просмотр будет автоматически заполнена в зависимости от типа файла.
Убедитесь, что форма Settings and preview (Настройки и предварительный просмотр) заполнена, как описано ниже, и щелкните Далее.
Поле Description Значение для руководства File format Свойство определяет структуру и тип данных, хранящихся в файле. с разделением Разделитель Один или несколько символов для указания границы между отдельными, независимыми регионами в виде простого текста или других потоков данных. Comma Кодировка Определяет, какой бит следует использовать в таблице схемы символов, чтобы считать набор данных. UTF-8 Заголовки столбцов Указывает, как будут обрабатываться заголовки набора данных, если таковые имеются. Только первый файл имеет заголовки Пропустить строки Указывает, сколько строк, если таковые имеются, пропускается в наборе данных. нет Форма Схема позволяет выполнять дальнейшую настройку данных для этого эксперимента.
В этом примере игнорируйте столбцы casual и registered. Эти столбцы предназначены для разбивки данных из столбца cnt, поэтому мы их исключаем.
Кроме того, в этом примере оставьте значения по умолчанию для параметров Свойства и Тип.
Выберите Далее.
В форме Подтверждение сведений проверьте соответствие сведений, которые ранее были указаны в формах Базовые сведения и Параметры и просмотр.
Выберите Создать, чтобы завершить создание набора данных.
Выберите набор данных, когда он появится в списке.
Выберите Далее.
Настроить задание
После загрузки и настройки данных настройте удаленный целевой объект вычислений и выберите столбец данных, который вы хотите спрогнозировать.
- Заполните форму задания "Настройка", как показано ниже.
Укажите для эксперимента имя
automl-bikeshare.Выберите cnt в качестве целевого столбца, данные в котором нужно спрогнозировать. В этом столбце указывается общее число велосипедов, взятых напрокат.
Выберите в качестве типа вычислений вычислительный кластер.
Выберите +Создать, чтобы настроить целевой объект вычислений. Автоматизированное машинное обучение поддерживает только вычисления в Службе машинного обучения Azure.
Заполните форму Выбрать виртуальную машину, чтобы настроить вычислительную среду.
Поле Description Значение для руководства Уровень виртуальных машин Выберите приоритет, который должен иметь ваш эксперимент. Выделенные Тип виртуальной машины Выберите тип виртуальной машины для вычислительной среды. ЦП (центральный процессор) размер виртуальной машины; Выберите размер виртуальной машины для вычислительной среды. Список рекомендуемых размеров выводится с учетом ваших данных и типа эксперимента. Standard_DS12_V2 Выберите Далее, чтобы заполнить форму Настройка параметров.
Поле Description Значение для руководства Имя вычислительной среды Уникальное имя для идентификации контекста вычислительной среды. bike-compute Min/Max nodes (Минимальное и максимальное количество узлов) Чтобы профилировать данные, необходимо указать один или несколько узлов. Минимальные узлы: 1
Максимальное число узлов: 6Время до уменьшения масштаба (сек) Время простоя перед автоматическим уменьшением масштаба кластера до минимального количества узлов. 120 (по умолчанию) Дополнительные параметры Параметры для настройки и авторизации виртуальной сети для эксперимента. нет Выберите Создать, чтобы получить целевой объект вычислений.
Операция займет несколько минут.
Когда создание целевого объекта вычислений завершится, выберите его из раскрывающегося списка.
Выберите Далее.
Выбор параметров прогнозирования
Завершите настройку эксперимента автоматического машинного обучения, указав тип задачи и параметры конфигурации машинного обучения.
В форме Тип задачи и параметры в качестве типа задачи машинного обучения выберите Прогнозирование временных рядов.
В качестве столбца времени выберите date, а значение Time series identifiers (Идентификаторы временных рядов) оставьте пустым.
Частота — это периодичность сбора исторических данных. Не снимайте флажок Автоматическое обнаружение.
Горизонт прогноза — продолжительность времени в будущем, на которое требуется прогноз. Снимите флажок Автоматическое обнаружение и введите 14 в поле.
Выберите View additional configuration settings (Просмотреть дополнительные параметры конфигурации) и заполните поля следующим образом. Эти параметры позволяют лучше контролировать задание обучения и указывать параметры для прогнозирования. В противном случае применяются значения по умолчанию, основанные на выборе эксперимента и данных.
Дополнительные конфигурации Description Значение для руководства Основная метрика Оценочная метрика, по которой будет проверяться алгоритм машинного обучения. Нормализованный КСКП Пояснения для наилучшей модели Автоматическое отображение пояснений для лучшей модели, созданной с помощью автоматизированного машинного обучения. Enable Заблокированные алгоритмы Алгоритмы, которые вы хотите исключить из задания обучения. Крайне случайные деревья Дополнительные параметры прогнозирования Следующие параметры помогают повысить точность модели.
Прогноз целевых задержек: как далеко назад вы хотите создать задержки целевой переменной
Целевое скользякое окно: указывает размер скользящего окна, в котором создаются такие функции, как макс, мин и сумма.
Прогноз целевых задержек: Нет
Размер целевого скользящего интервала: нетКритерий выхода Если условия соблюдены, задание обучения останавливается. Время задания обучения (часы): 3
Порог оценки метрики: нетПараллелизм Максимальное число выполняемых параллельных итераций за одну итерацию. Максимальное число итераций: 6 Выберите Сохранить.
Выберите Далее.
В форме [необязательно] Проверка и тестирование:
- Выберите перекрестную проверку в k-кратном порядке в качестве Типа проверки.
- Установите для Числа перекрестных проверок значение 5.
Выполнение эксперимента
Чтобы выполнить эксперимент, щелкните Готово. Откроется экран Сведения о задании, в верхней части которого рядом с номером задания указано состояние задания. Это состояние обновляется по мере выполнения эксперимента. Уведомления также отображаются в правом верхнем углу студии, сообщая о состоянии эксперимента.
Важно!
Подготовка задания эксперимента занимает 10-15 минут.
С начала эксперимента на каждую итерацию уходит 2-3 минуты.
В рабочей среде у вас будет время заняться другими делами, так как это длительный процесс. Пока вы ждете, рекомендуем начинать изучение протестированных алгоритмов на вкладке Модели по мере их завершения.
Изучение моделей
Перейдите на вкладку Модели, чтобы просмотреть протестированные алгоритмы (модели). По умолчанию модели упорядочиваются по оценке метрики по мере их завершения. В рамках работы с этим руководством в начале списка отображается модель, имеющая максимальное значение выбранной метрики Нормализованная среднеквадратическая погрешность.
В ожидании завершения всех моделей эксперимента вы можете щелкнуть Algorithm name (Имя алгоритма) для любой завершенной модели, чтобы просмотреть сведения о ее эффективности.
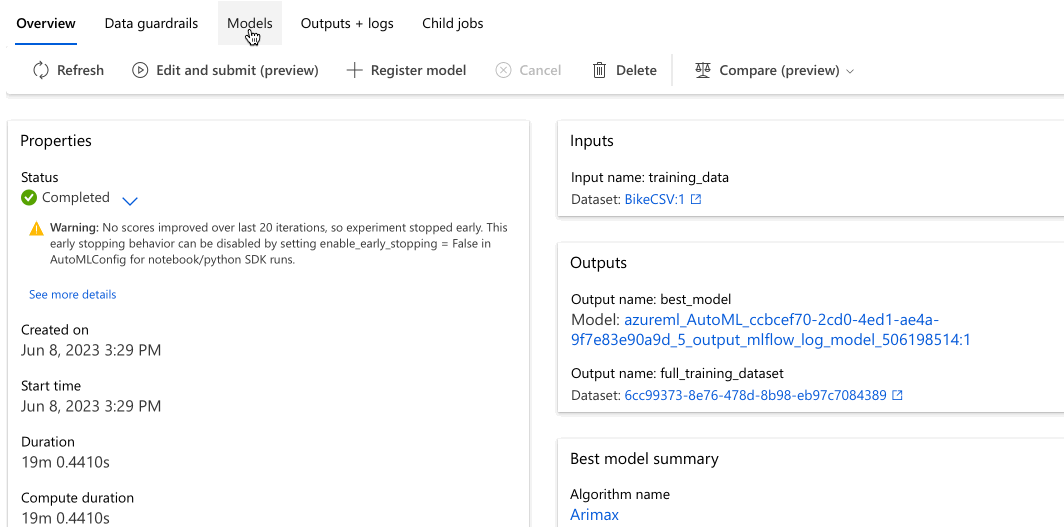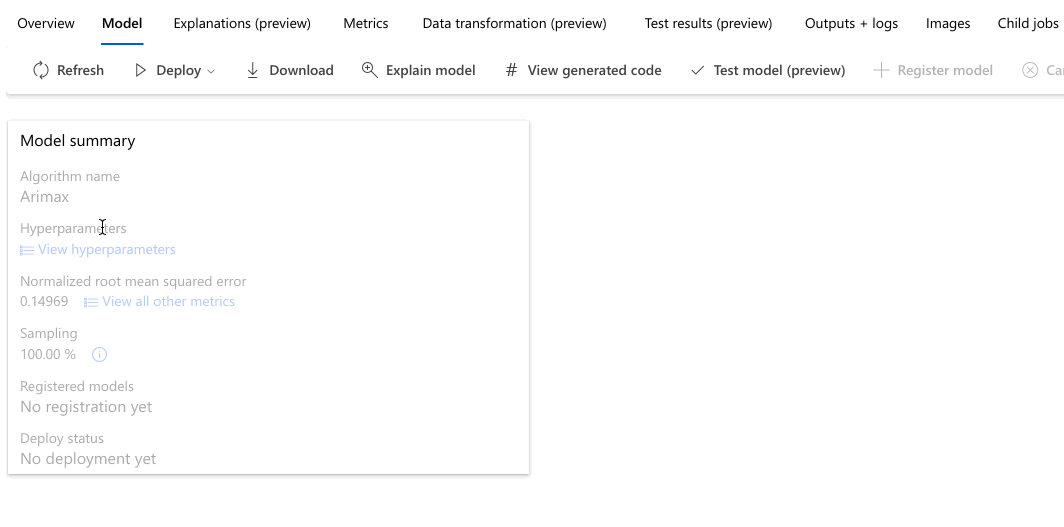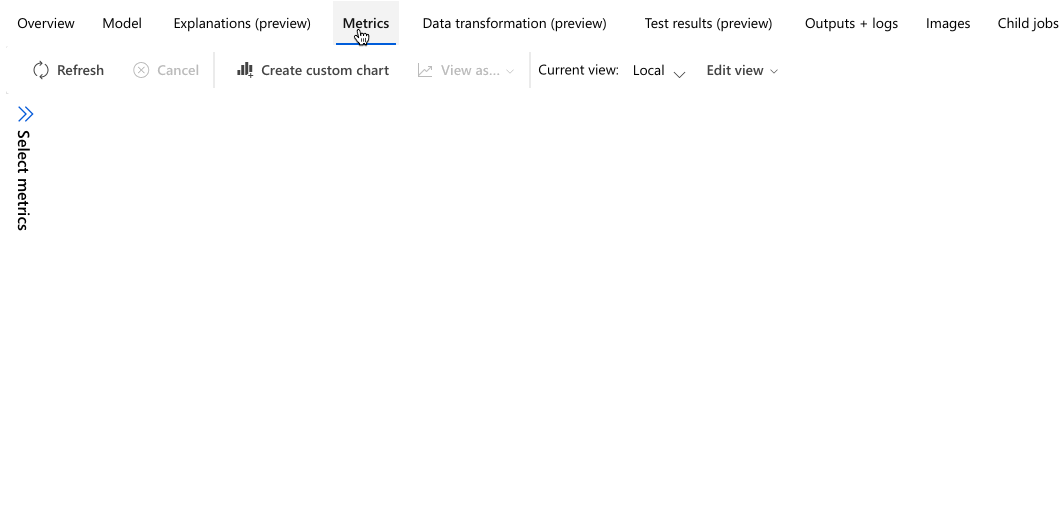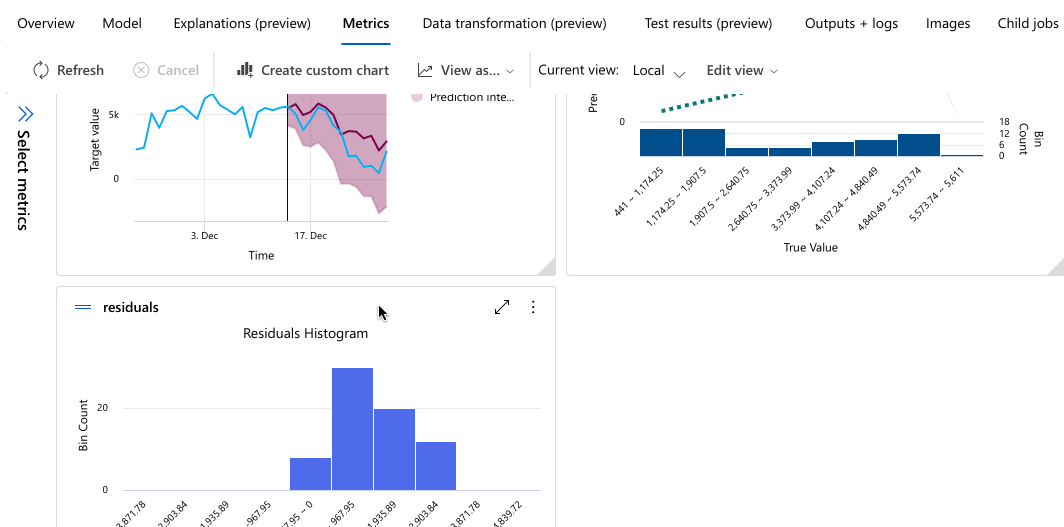
В следующем примере показано, как выбрать модель из списка моделей, созданных заданием. Затем выберите вкладки "Обзор " и "Метрики" , чтобы просмотреть свойства выбранной модели, метрики и диаграммы производительности.
Развертывание модели
Автоматизированное машинное обучение в Студии машинного обучения Azure позволяет развернуть лучшую модель как веб-службу всего с помощью нескольких действий. Развертывание — это интеграция модели для прогнозирования по новым данным и определения потенциальных новых возможностей.
В этом эксперименте развертывание в веб-службе означает, что у компании по прокату велосипедов теперь есть итеративное масштабируемое веб-решение для прогнозирования спроса на прокат велосипедов.
После завершения задания вернитесь на страницу родительского выполнения, выбрав Job 1 (Задание 1) в верхней части экрана.
В разделе Сводка по лучшей модели лучшая модель в контексте этого эксперимента выбирается на основе метрики Нормализованная среднеквадратическая погрешность.
Мы развернем эту модель. Учитывайте, что процесс развертывания занимает около 20 минут. Процесс развертывания выполняется за несколько шагов, включая регистрацию модели, создание ресурсов и их настройку для веб-службы.
Выберите лучшую модель, чтобы открыть страницу для этой модели.
Нажмите кнопку Развернуть в левой верхней области экрана.
Заполните панель Deploy a model (Развертывание модели), как показано ниже.
Поле значение Deployment name (Имя развертывания) bikeshare-deploy Deployment description (Описание развертывания) Развертывание модели спроса на прокат велосипедов Тип вычисления Выберите "Вычислительная операция Azure (ACI)" Включение проверки подлинности Отключить. Использовать настраиваемые ресурсы развертывания Отключить. Отключение позволяет автоматически создавать файл драйвера (скрипт оценки) и файл среды по умолчанию. Для этого примера мы воспользуемся стандартными параметрами, доступными в меню Дополнительно.
Выберите Развернуть.
В верхней части окна задания появится зеленое сообщение об успешном завершении, в котором указано, что развертывание было начато успешно. Ход выполнения развертывания можно просмотреть в области Сводка по модели в разделе Deploy status (Состояние развертывания).
Если развертывание завершилось успешно, теперь у вас есть рабочая веб-служба для создания прогнозов.
Перейдите к дальнейшим действиям, чтобы узнать больше о том, как использовать новую веб-службу, и протестируйте прогнозы, используя встроенную поддержку Power BI в Машинном обучении Azure.
Очистка ресурсов
Файлы развертывания имеют больший размер, чем файлы данных и экспериментов, поэтому их хранение обходится дороже. Вы можете удалить только файлы развертывания, чтобы снизить затраты на учетную запись, если хотите сохранить рабочую области и файлы экспериментов. В противном случае, если вы не планируете дальше использовать эти файлы, удалите всю группу ресурсов.
Удаление промежуточного развертывания
Чтобы сохранить группу ресурсов и рабочую область для изучения других руководств и собственных исследований, удалите из Студии машинного обучения Azure только экземпляр развертывания.
Перейдите в Студию машинного обучения Azure. Перейдите в рабочую область и слева под областью Ресурсы выберите Конечные точки.
Выберите развертывание для удаления и щелкните Удалить.
Выберите Продолжить.
Удаление группы ресурсов
Важно!
Созданные вами ресурсы могут использоваться в качестве необходимых компонентов при работе с другими руководствами по Машинному обучению Azure.
Если вы не планируете использовать созданные вами ресурсы, удалите их, чтобы с вас не взималась плата:
На портале Azure выберите Группы ресурсов в левой части окна.
Выберите созданную группу ресурсов из списка.
Выберите команду Удалить группу ресурсов.
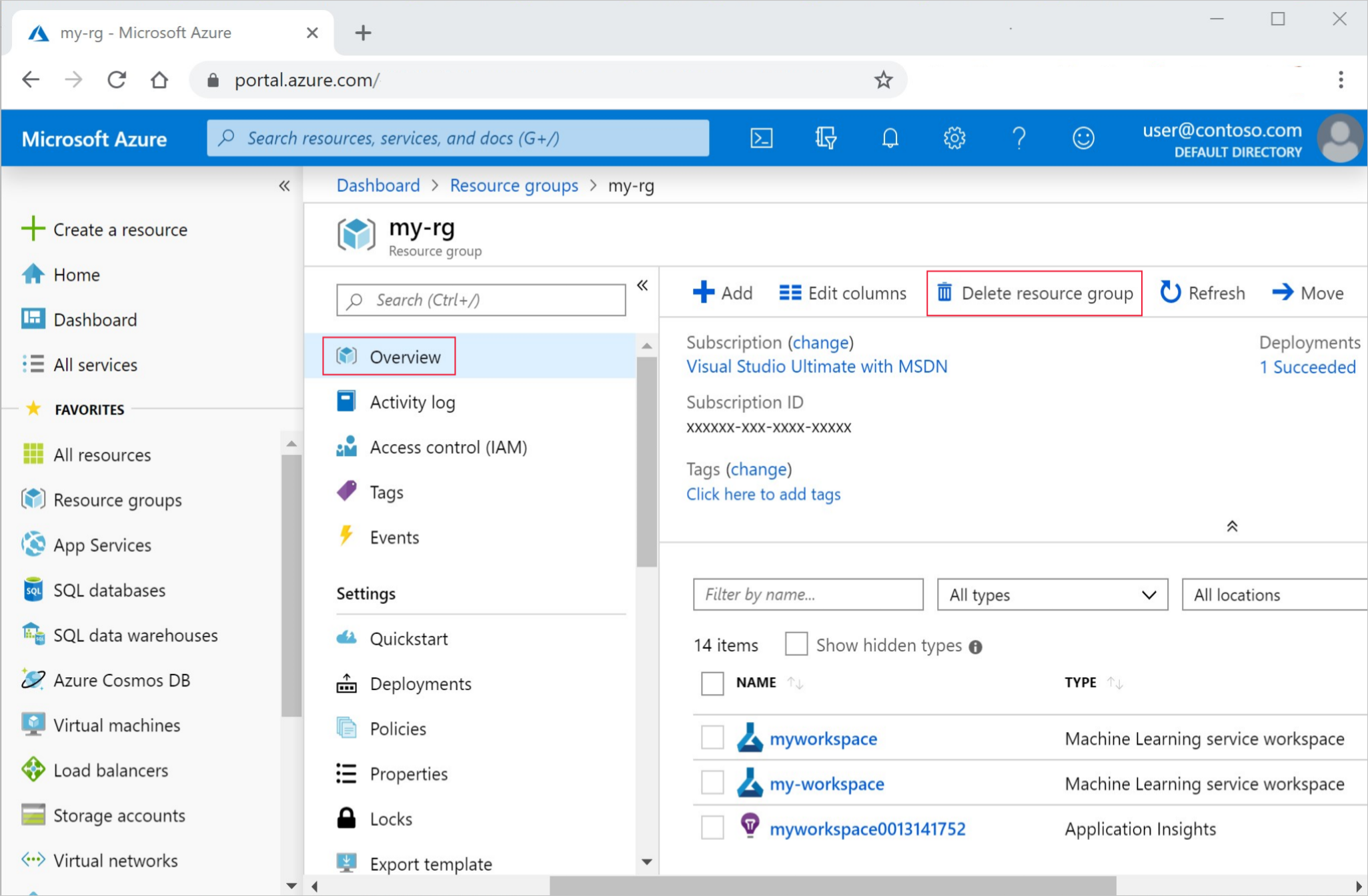
Введите имя группы ресурсов. Затем выберите Удалить.
Следующие шаги
Во время работы с этим руководством вы создали и развернули в Студии машинного обучения Azure с помощью автоматизированного машинного обучения модель прогнозирования временных рядов для прогнозирования спроса для службы проката велосипедов.
В этой статье приведены инструкции о том, как создать схему с поддержкой Power BI для облегчения использования новой развернутой веб-службы:
- Дополнительные сведения об автоматическом машинном обучении.
- Дополнительные сведения о классификационных метриках и графиках см. в статье Общие сведения об автоматических результатах машинного обучения.
Примечание.
Набор данных о прокате велосипедов был изменен для этого руководства. Этот набор данных был представлен в рамках конкурса Kaggle и изначально был доступен на сайте Capital Bikeshare. Его также можно найти в базе данных машинного обучения UCI.
Источник: Fanaee-T, Hadi и Gama, Joao, Event labeling объединение детекторов ансамбля и фоновых знаний, Progress in Artificial Intelligence (2013): pp. 1-15, Springer Berlin Heidelberg.