Учебник. Конструктор — развертывание модели машинного обучения
Воспользуйтесь конструктором, чтобы развернуть модель машинного обучения для прогнозирования цен на автомобили. Это руководство представляет собой вторую часть серии, состоящей из двух частей.
Примечание
Designer поддерживает два типа компонентов: классические предварительно созданные компоненты (версия 1) и пользовательские компоненты (версия 2). Эти два типа компонентов НЕ совместимы.
Классические предварительно созданные компоненты предоставляют предварительно созданные компоненты в основном для обработки данных и традиционных задач машинного обучения, таких как регрессия и классификация. Этот тип компонента по-прежнему поддерживается, но новые компоненты добавляться не будут.
Пользовательские компоненты позволяют создать оболочку для собственного кода в качестве компонента. Она поддерживает совместное использование компонентов в рабочих областях и удобную разработку в интерфейсах Studio, CLI версии 2 и ПАКЕТА SDK версии 2.
Для новых проектов настоятельно рекомендуется использовать настраиваемый компонент, который совместим с AzureML версии 2 и будет продолжать получать новые обновления.
Эта статья относится к классическим предварительно созданным компонентам и несовместима с CLI версии 2 и пакетом SDK версии 2.
В первой части учебника описывалось, как обучить модель линейной регрессии для цен на автомобили. Во второй части вы развернули модель для использования другими пользователями. Изучив это руководство, вы:
- Создание конвейера вывода в режиме реального времени.
- Создание кластера вывода.
- Развертывание конечной точки в режиме реального времени.
- Тестирование конечной точки в режиме реального времени.
Предварительные требования
Изучите первую часть учебника, чтобы узнать, как обучать и оценивать модель машинного обучения в конструкторе.
Важно!
Если вы не видите графические элементы, упомянутые в этом документе, такие как кнопки в студии или конструкторе, возможно, у вас нет соответствующих разрешений для рабочей области. Обратитесь к администратору подписки Azure, чтобы убедиться, что вам предоставлен правильный уровень доступа. Дополнительные сведения см. в статье Управление доступом к рабочей области Машинного обучения Azure.
Создание конвейера вывода в реальном времени
Чтобы развернуть конвейер, сначала преобразуйте обучающий конвейер в конвейер вывода в режиме реального времени. При этом удаляются обучающие компоненты и добавляются входные и выходные данные веб-службы для обработки запросов.
Примечание
Создание конвейера вывода возможно только из конвейеров обучения, которые содержат только встроенные компоненты конструктора. Они должны иметь такой компонент, как Train Model, который выводит обученную модель.
Создание конвейера вывода в реальном времени
На странице сведений о задании конвейера над холстом конвейера выберите Create inference pipeline (Создать конвейер вывода)>Real-time inference pipeline (Конвейер вывода в режиме реального времени).
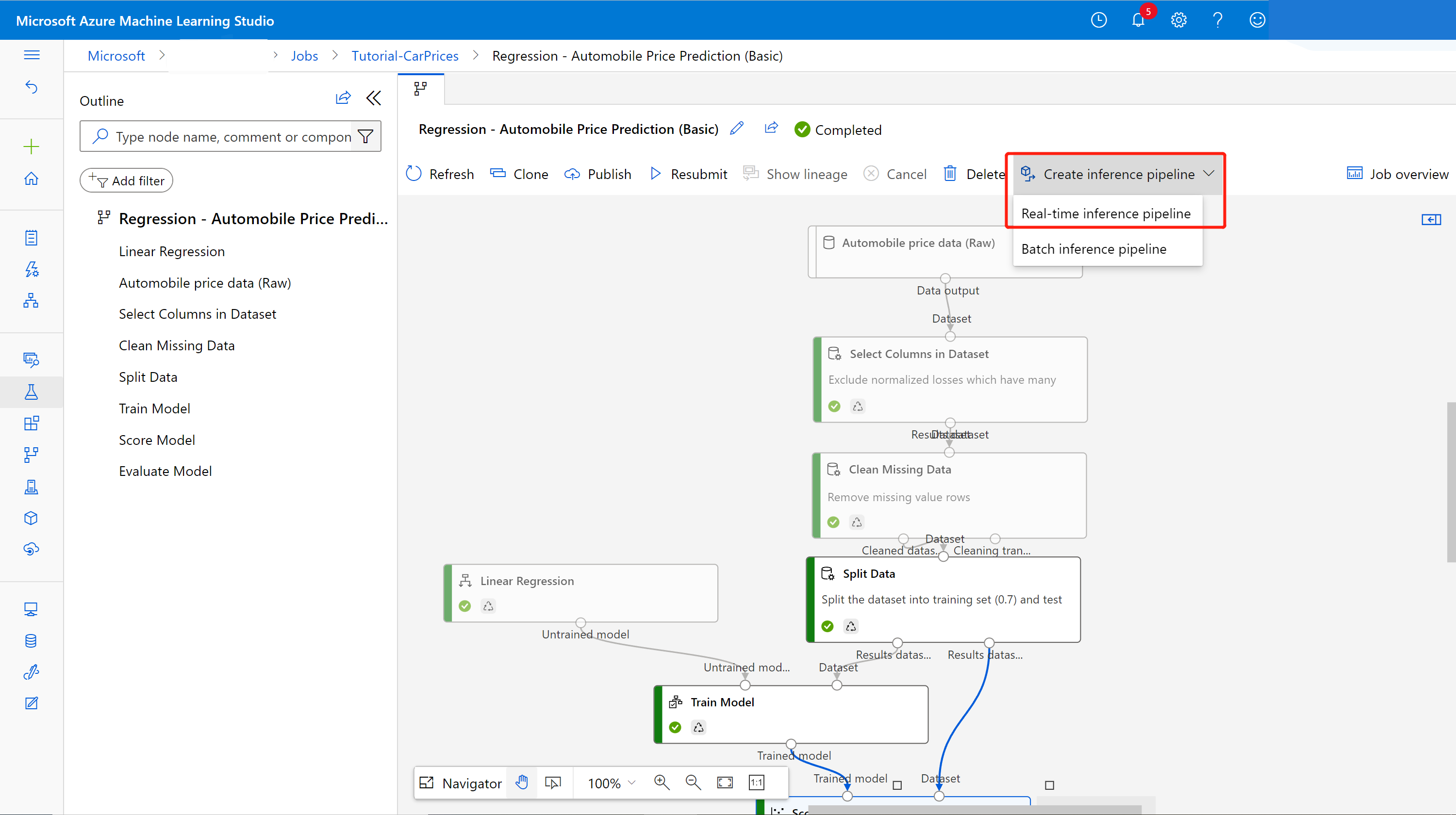
Ваш новый конвейер должен выглядеть примерно так:
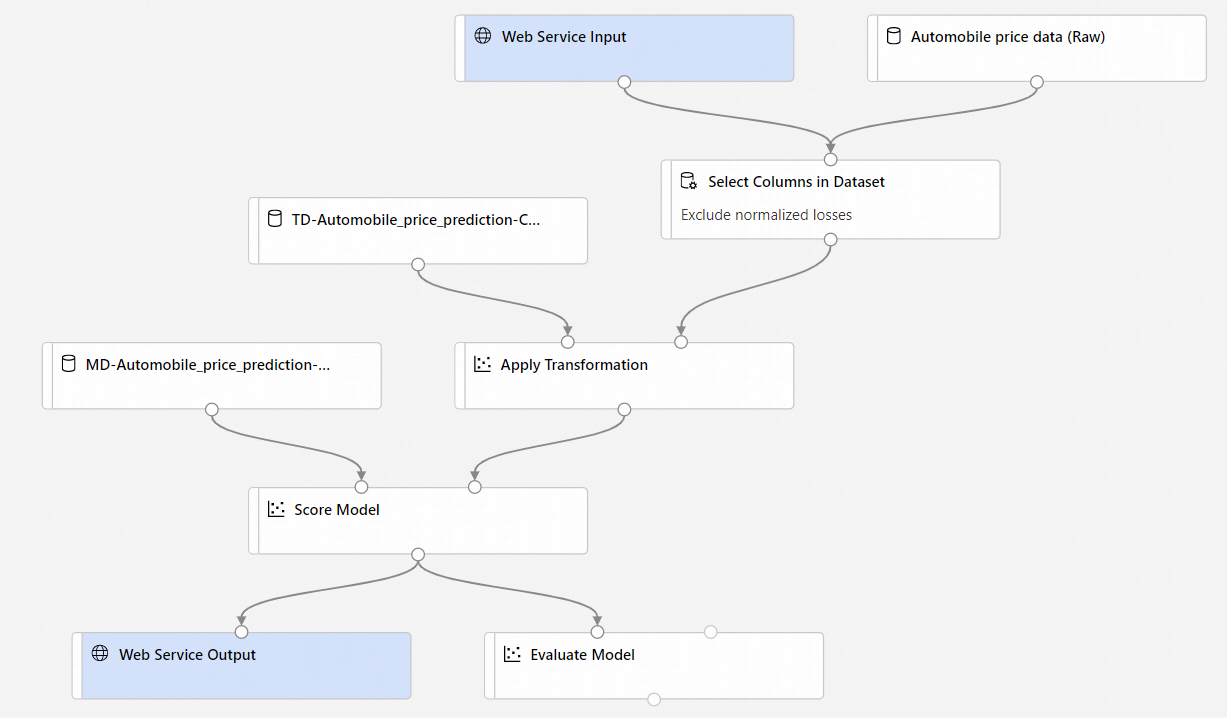
При нажатии кнопки Create inference pipeline (Создать конвейер вывода) произойдет несколько вещей:
- Обученная модель будет сохранена в виде компонента Dataset (Набор данных) в палитре компонентов. Его можно найти в разделе My Datasets (Мои наборы данных).
- Удаляются такие обучающие компоненты, как Train Model (Обучение модели) и Split Data (Разделение данных).
- Сохраненная обученная модель добавляется обратно в конвейер.
- Добавляются компоненты Web Service Input (Входные данные веб-службы) и Web Service Output (Выходные данные веб-службы). В этих компонентах показано, откуда пользовательские данные поступают в конвейер и куда они возвращаются.
Примечание
По умолчанию компонент Web Service Input (Входные данные веб-службы) будет ожидать ту же схему данных, что и выходные данные компонента, подключенного к тому же нисходящему порту. В этом примере компоненты Web Service Input (Входные данные веб-службы) и Automobile price data (Raw) (Необработанные данные о ценах на автомобили) подключаются к одному и тому же нисходящему компоненту, поэтому компонент Web Service Input (Входные данные веб-службы) ожидает ту же схему данных, что и компонент Automobile price data (Raw) (Необработанные данные о ценах на автомобили), а столбец целевой переменной
priceвключен в схему. Однако, как правило, при оценке данных вы не узнаете значения целевых переменных. В таком случае можно удалить столбец целевой переменной в конвейере вывода с помощью компонента Select Columns in Dataset (Выбор столбцов в наборе данных). Убедитесь, что выходные данные компонента Select Columns in Dataset (Выбор столбцов в наборе данных), удаляющего столбец целевой переменной, подключены к тому же порту, что и выходные данные компонента Web Service Intput (Входные данные веб-службы).Выберите Отправить и используйте тот же целевой объект вычислений и эксперимент, который использовался в первой части.
При запуске первого задания для завершения работы конвейера может потребоваться 20 минут. В параметрах вычислений по умолчанию минимальный размер узла равен 0. Это означает, что конструктор должен выделить ресурсы после простоя. Последующие выполнения задания конвейера займут меньше времени, так как ресурсы вычислений уже будут выделены. Кроме того, конструктор использует кэшированные результаты для каждого компонента, чтобы повысить эффективность.
Перейдите к сведениям о задании конвейера вывода в режиме реального времени, щелкнув ссылку Job detail (Сведения о задании) в левой области.
На странице сведений о задании нажмите Deploy (Развернуть).
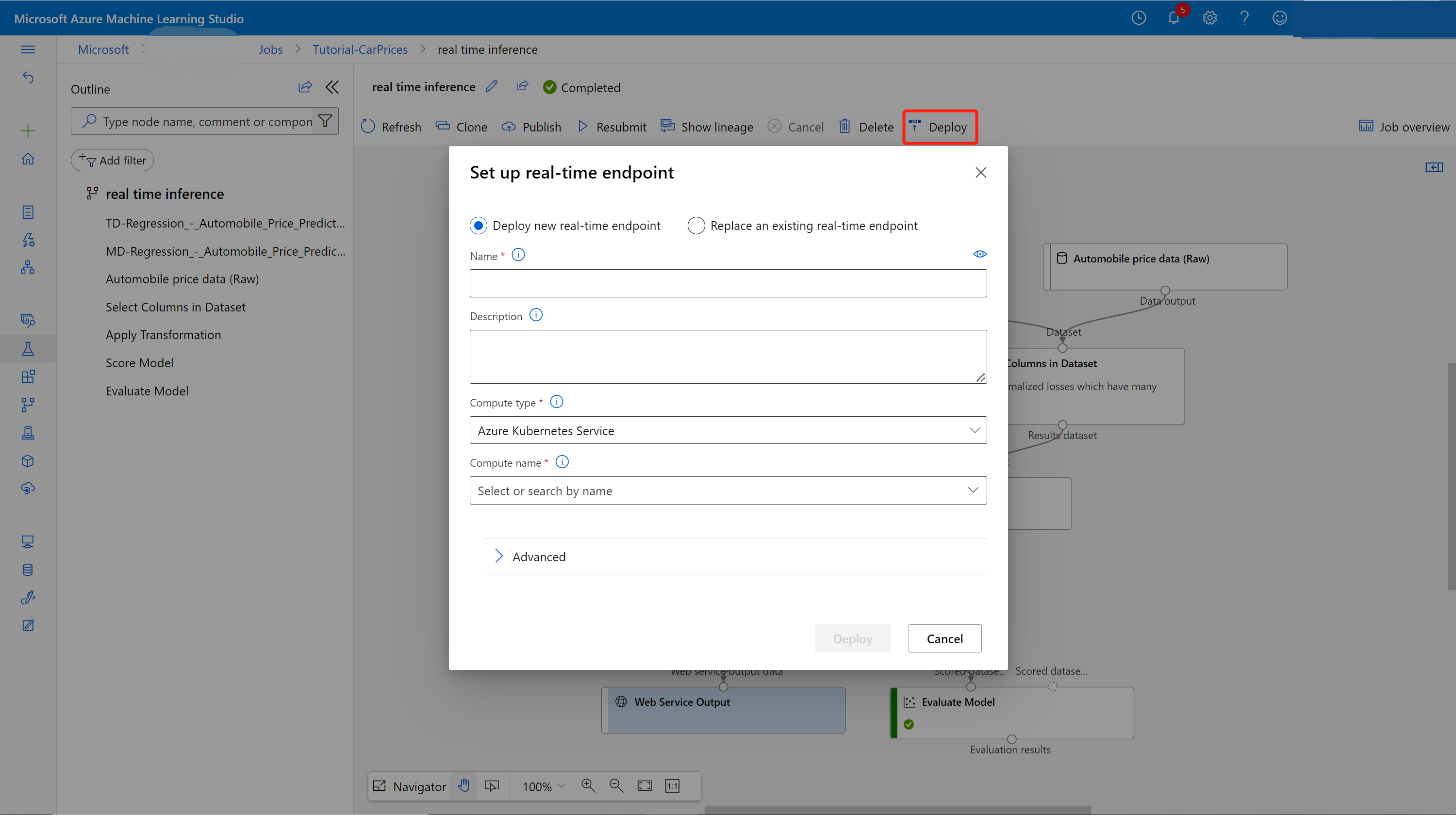
Создание кластера вывода
Для развертывания модели можно выбрать любой кластер Службы Azure Kubernetes (AKS) в открывшемся диалоговом окне. Если у вас нет кластера AKS, создайте его, сделав следующее.
В открывшемся диалоговом окне выберите Вычисления, чтобы перейти к странице Вычисления.
В ленте навигации выберите Inference Clusters (Кластеры вывода) >+ Создать.
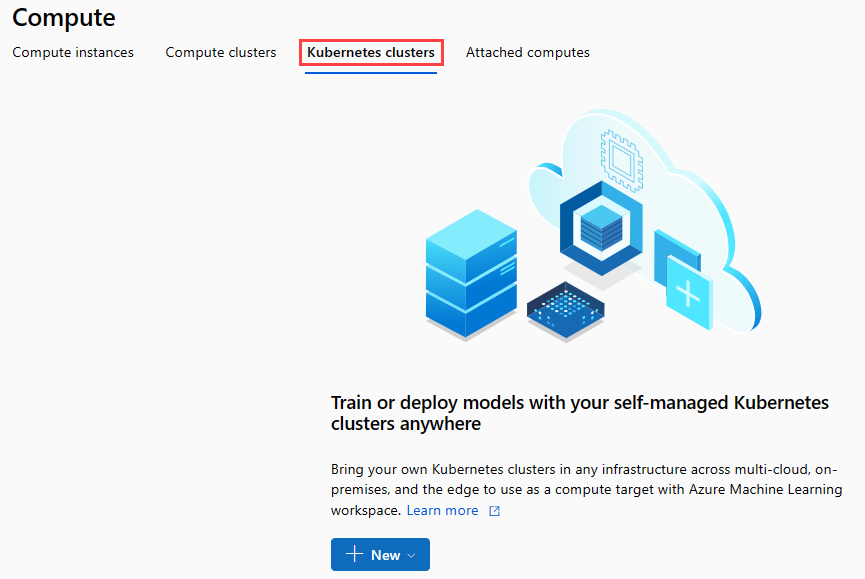
В области кластера вывода настройте новую службу Kubernetes.
Введите aks-compute в поле Имя вычислений.
Выберите ближайший регион, доступный для модуля Регион.
Нажмите кнопку создания.
Примечание
Создание службы AKS занимает около 15 минут. Состояние подготовки можно проверить на странице Inference Clusters (Кластеры вывода).
Развертывание конечной точки для прогнозирования в реальном времени
После завершения подготовки службы AKS вернитесь к конвейеру вывода в режиме реального времени для завершения развертывания.
Выберите Развернуть над холстом.
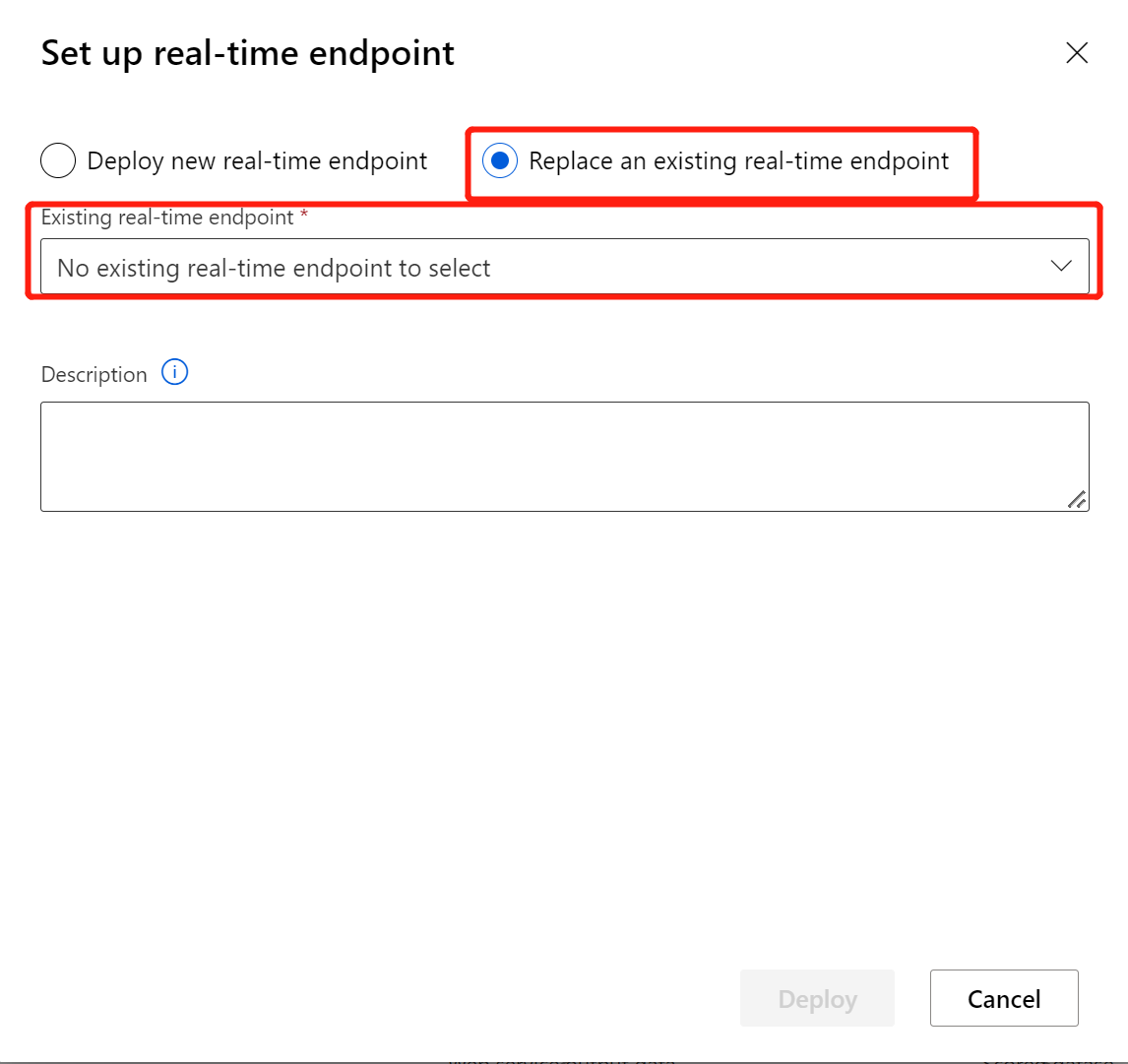
Выберите Deploy new real-time endpoint (Развертывание новой конечной точки для прогнозирования в реальном времени).
Выберите созданный кластер AKS.
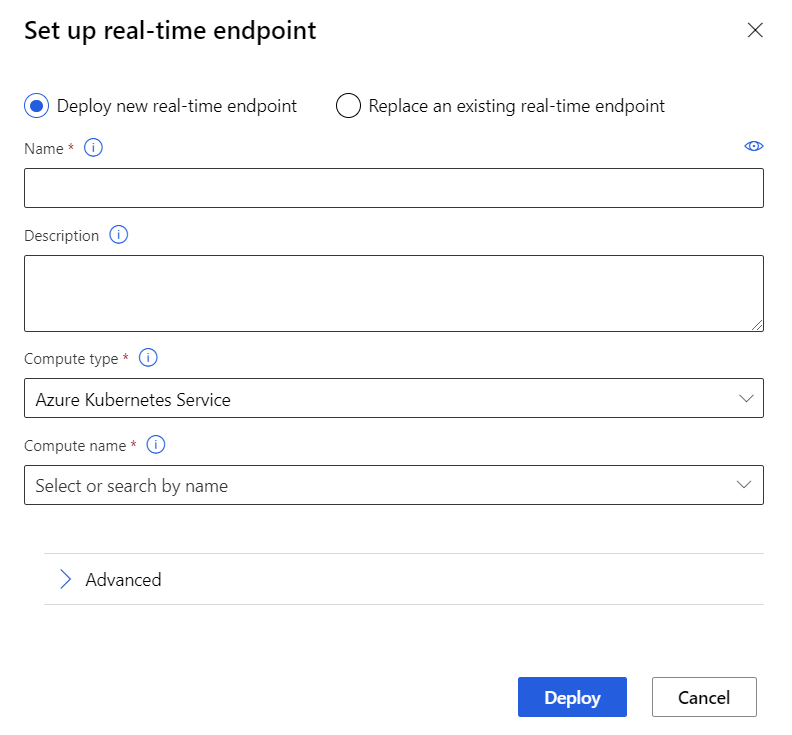
Кроме того, вы можете изменить параметр Дополнительно для своей конечной точки для прогнозирования в реальном времени.
Расширенный параметр Описание Включить сбор данных и диагностику Application Insights Определяет, следует ли разрешить Azure Application Insights сбор данных из развернутых конечных точек.
Значение по умолчанию: false.Время ожидания оценки Принудительное время ожидания вызовов оценки веб-службы (в миллисекундах).
Значение по умолчанию: 60000.Автоматическое масштабирование включено Позволяет указать, нужно ли включить автомасштабирование для веб-службы.
Значение по умолчанию: true.Минимум реплик Минимальное число используемых контейнеров при автомасштабировании этой веб-службы.
Значение по умолчанию: 1.Максимум реплик Максимальное число используемых контейнеров при автомасштабировании этой веб-службы.
Значение по умолчанию: 10.Целевое использование Целевой объем использования, который нужно пытаться поддерживать при автомасштабировании этой веб-службы (в процентах до 100).
Значение по умолчанию: 70.Период обновления Частота попыток автомасштабирования этой веб-службы (в секундах).
Значение по умолчанию: 1.Резервная мощность ЦП Количество ядер ЦП, выделяемых для этой веб-службы.
Значение по умолчанию: 0,1.Резервная мощность памяти Объем памяти (в ГБ), выделяемой для этой веб-службы.
Значение по умолчанию: 0,5.Выберите Развернуть.
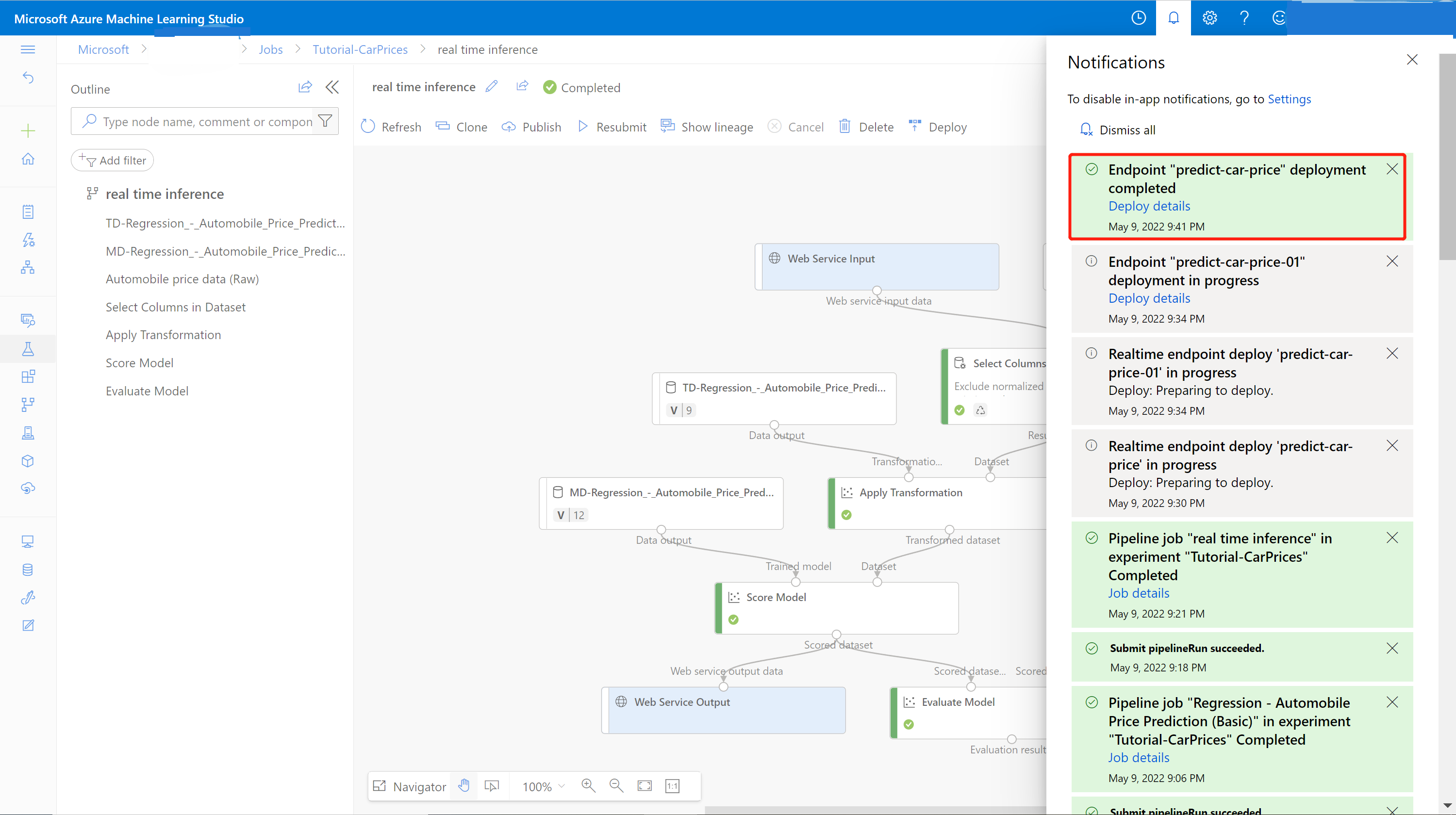
После завершения развертывания появится уведомление из центра уведомлений об успешном выполнении. Это может занять несколько минут.
Совет
Кроме того, можно выполнить развертывание в экземпляр контейнера Azure (ACI). Для этого выберите элемент Экземпляр контейнера Azure в качестве типа вычислений в поле параметров конечной точки для прогнозирования в реальном времени. Экземпляр контейнера Azure используется для тестирования или разработки. Используйте ACI для небольших рабочих нагрузок на основе ЦП, которым требуется менее 48 ГБ ОЗУ.
Тестирование конечной точки для прогнозирования в реальном времени
После развертывания вы можете просмотреть конечную точку для прогнозирования в реальном времени. Для этого перейдите к странице Конечные точки.
На странице Конечные точки выберите развернутую конечную точку.
На вкладке Сведения можно просмотреть дополнительную информацию, такую как URI REST, определение Swagger, сведения о состоянии и теги.
На вкладке Использование можно найти пример кода использования, ключи безопасности и задать методы аутентификации.
На вкладке Журналы развертывания можно найти подробные журналы с данными о развертывании конечной точки для прогнозирования в реальном времени.
Чтобы проверить конечную точку, перейдите на вкладку Тестирование. Здесь можно ввести тестовые данные и выбрать Тестировать, чтобы проверить выходные данные конечной точки.
Изменение конечной точки для прогнозирования в реальном времени
Вы можете изменить подключенную конечную точку на новую модель, обученную в конструкторе. На странице сведений о подключенной конечной точке найдите предыдущее задание конвейера обучения и задание конвейера вывода.
Вы можете найти и изменить черновик конвейера обучения прямо на домашней странице конструктора.
Вы также можете открыть ссылку задания конвейера обучения, а затем скопировать ее в новый черновик конвейера, чтобы продолжить редактирование.
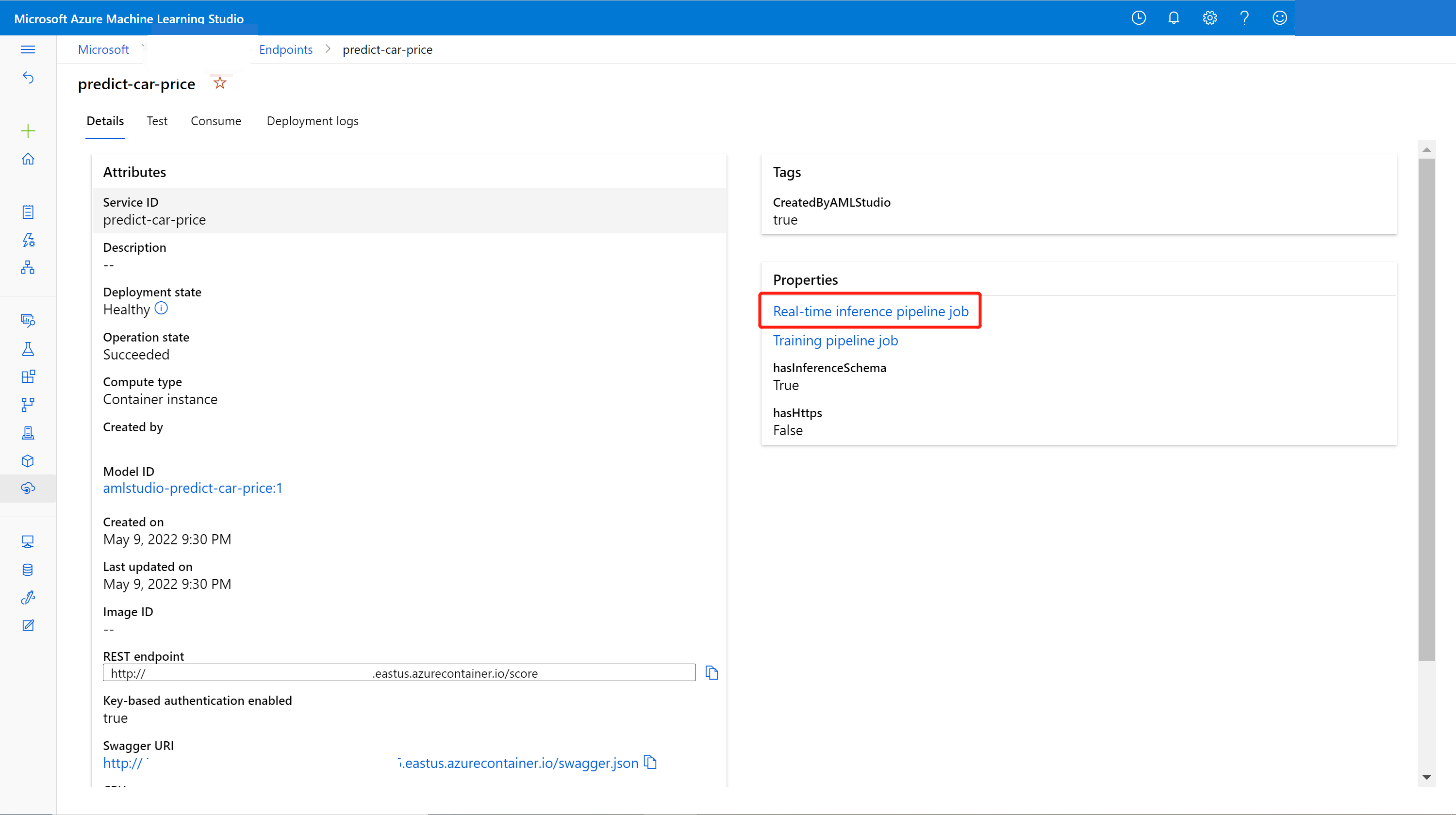
После отправки измененного конвейера обучения перейдите на страницу сведений о задании.
По завершении задания щелкните правой кнопкой мыши Train Model (Обучение модели) и выберите Register data (Зарегистрировать данные).
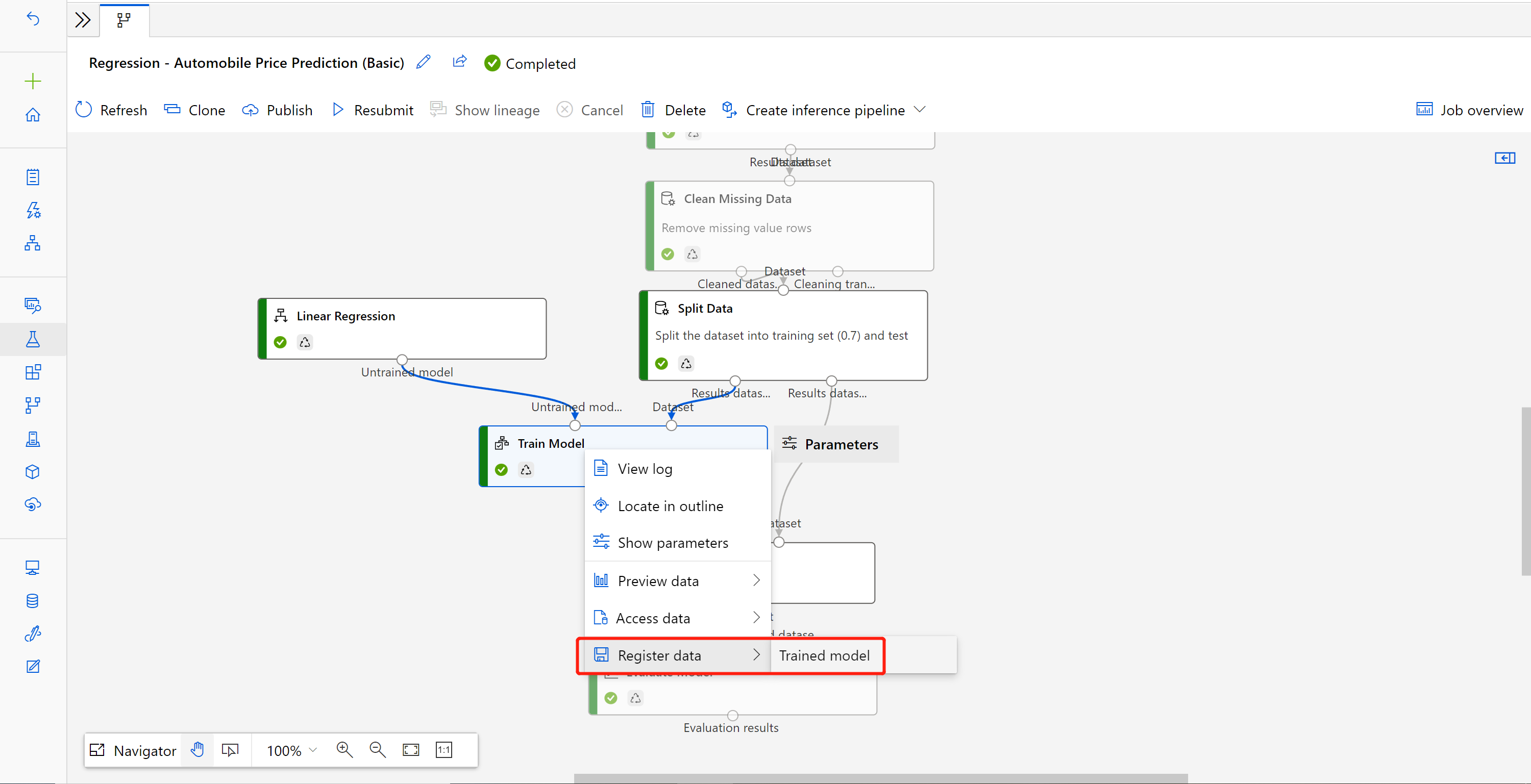
Введите имя и выберите тип File (Файл).
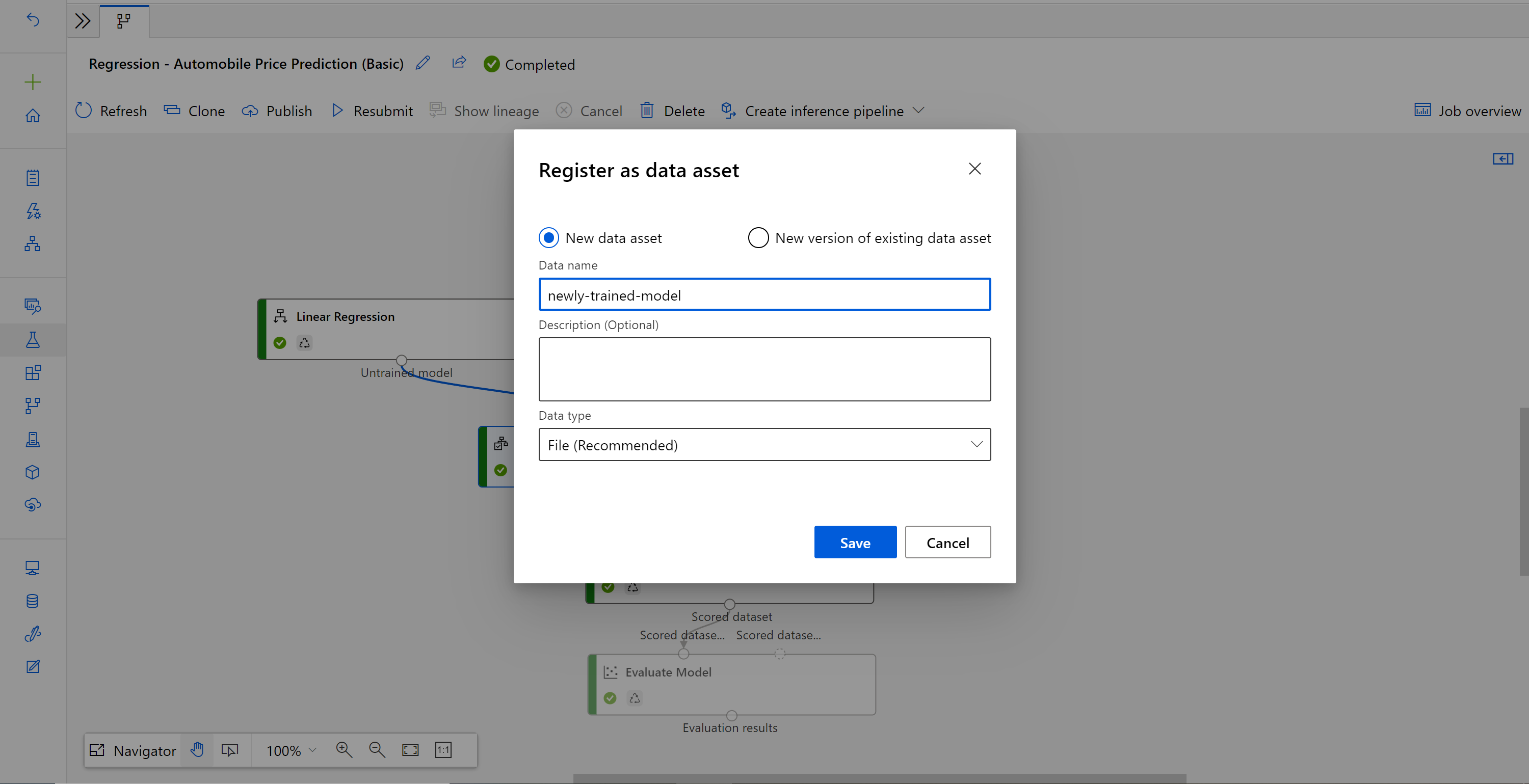
После успешной регистрации набора данных откройте черновик конвейера вывода или скопируйте предыдущее задание конвейера вывода в новый черновик. В черновике конвейера вывода замените предыдущую обученную модель, показанную как узел MD-XXXX, который подключен к компоненту Score Model (Оценка модели), на зарегистрированный набор данных.
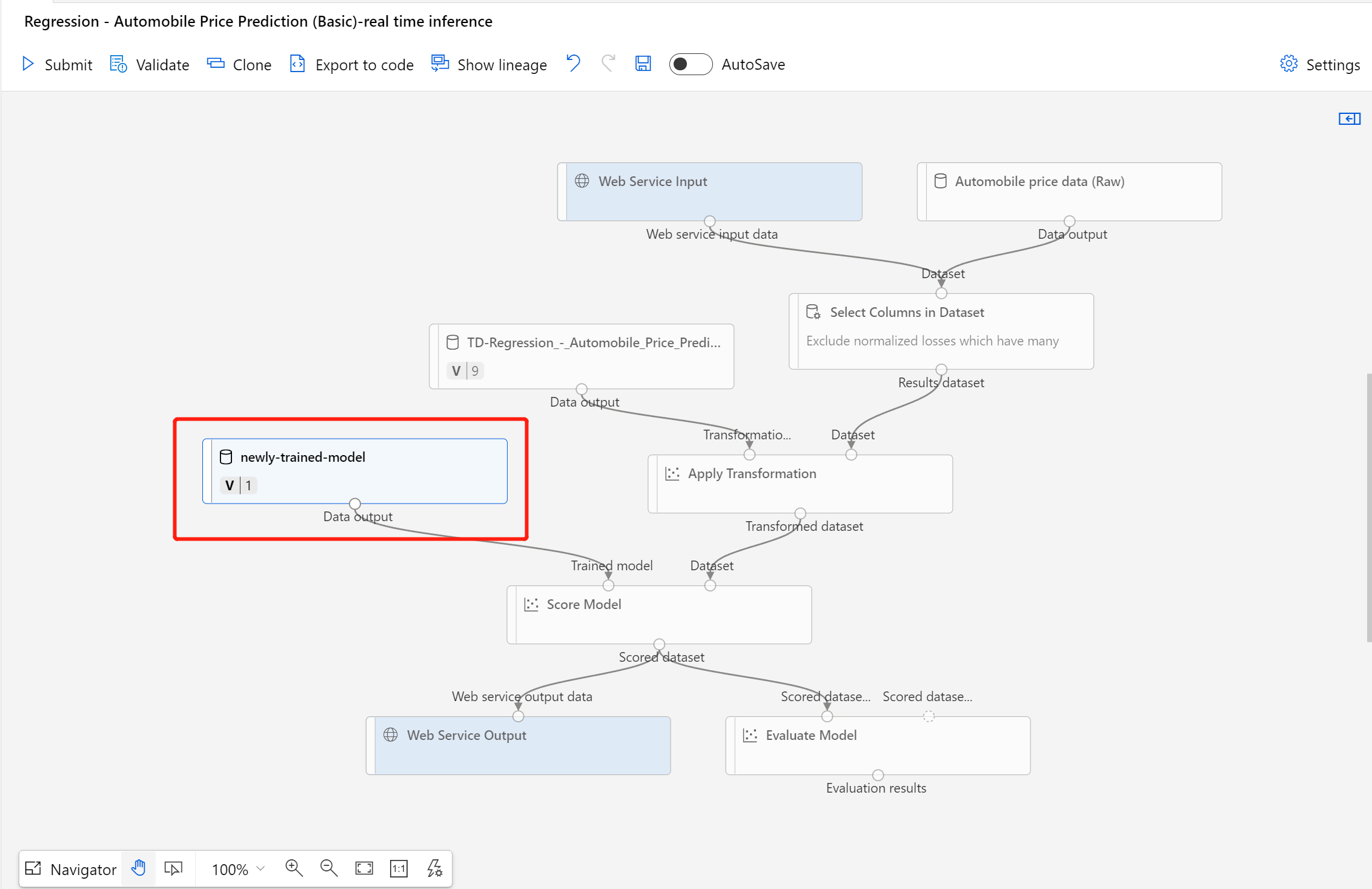
Если вам необходимо изменить часть предварительной обработки данных в конвейере обучения и вы хотите внести такое же изменение в конвейере вывода, процесс будет таким же, как описано выше.
Вам нужно только зарегистрировать выход преобразования компонента преобразования в качестве набора данных.
Затем вручную замените компонент TD- в конвейере вывода зарегистрированным набором данных.
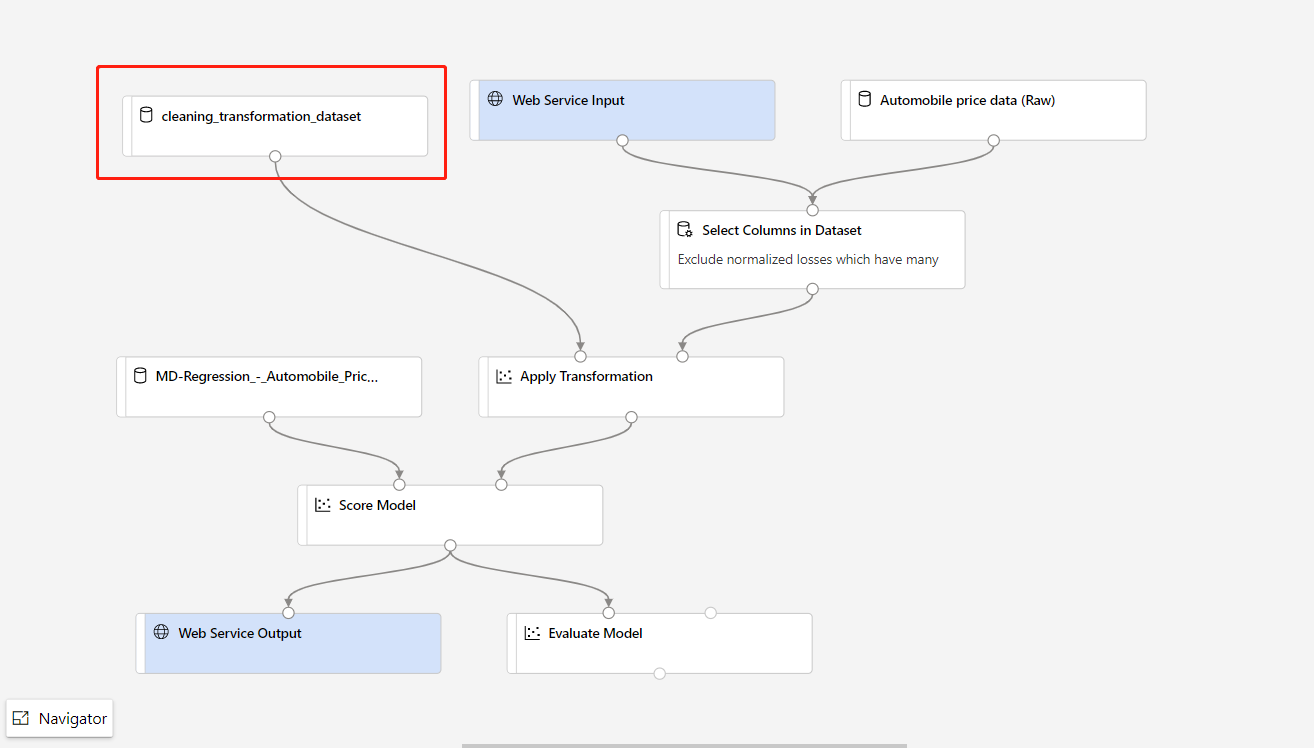
После замены конвейера вывода на недавно обученную модель или преобразование вам нужно отправить его. После завершения задания разверните его в существующей сетевой конечной точке, развернутой ранее.
Ограничения
Если конвейер вывода содержит компонент Import Data (Импорт данных) или Export Data (Экспорт данных), они будут автоматически удалены при развертывании в конечной точке для прогнозирования в реальном времени из-за ограничений доступа к хранилищу данных.
Если у вас есть наборы данных в конвейере вывода в режиме реального времени и вы хотите развернуть их в конечной точке реального времени, в настоящее время этот поток поддерживает только наборы данных, зарегистрированные из хранилища данных BLOB-объектов . Если вы хотите использовать наборы данных из хранилищ данных другого типа, можно использовать команду Select Column для подключения к исходному набору данных с параметрами выбора всех столбцов, регистрации выходных данных Select Column в качестве файлового набора данных, а затем замены исходного набора данных в конвейере вывода в режиме реального времени новым зарегистрированным набором данных.
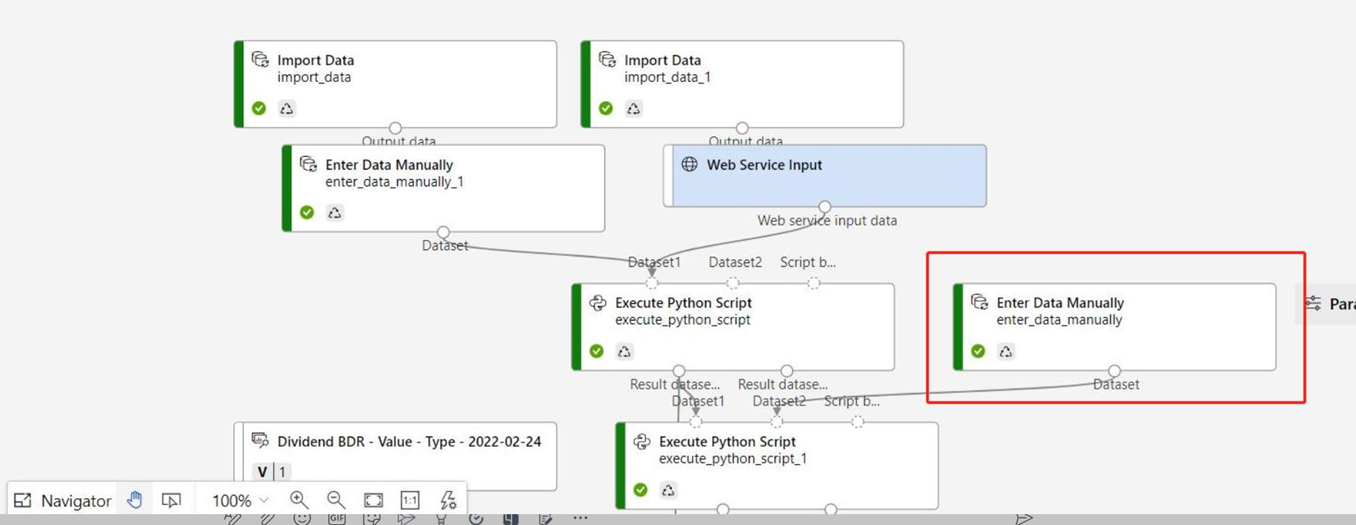
Если граф вывода содержит компонент "Ввод данных вручную", который не подключен к тому же порту, что и компонент "Входные данные веб-службы", компонент "Ввод данных вручную" не будет выполняться во время обработки HTTP-вызова. Обходной путь — зарегистрировать выходные данные этого компонента "Ввод данных вручную" в качестве набора данных, а затем в черновике конвейера вывода замените компонент "Ввод данных вручную" на зарегистрированный набор данных.
Очистка ресурсов
Важно!
Созданные ресурсы можно использовать в качестве необходимых компонентов для других учебников и статей с практическими рекомендациями по Машинному обучению Azure.
Удаление всех ресурсов
Если вы не планируете использовать созданные ресурсы, удалите всю группу ресурсов, чтобы с вас не взималась плата.
На портале Azure слева выберите Группы ресурсов.
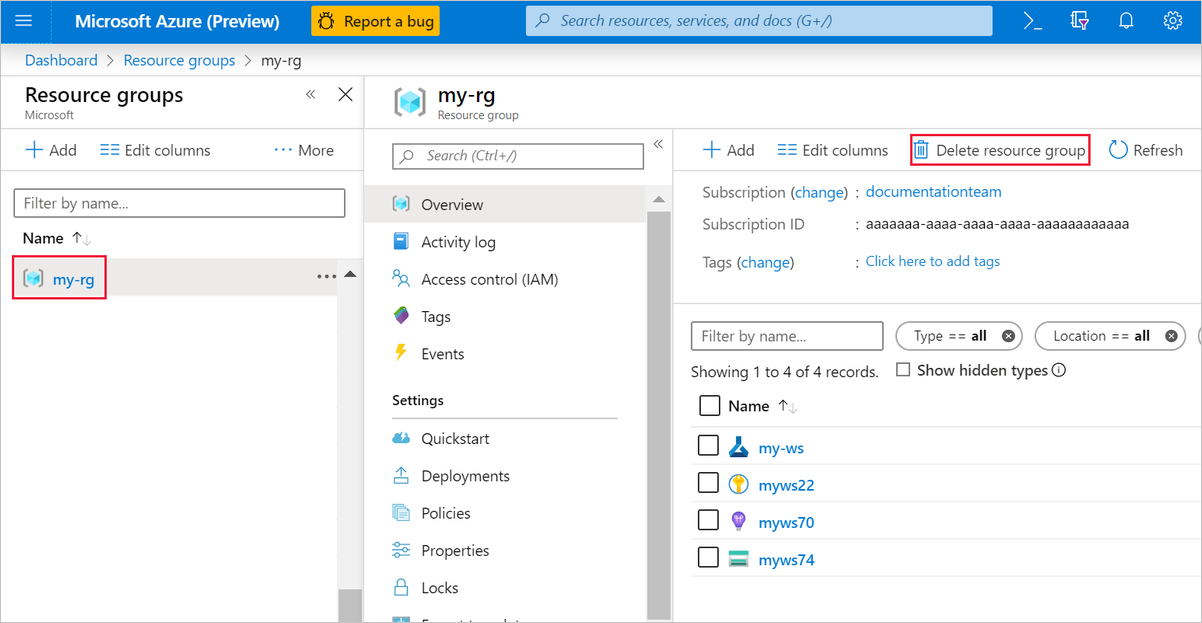
В списке выберите созданную группу ресурсов.
Выберите команду Удалить группу ресурсов.
При удалении группы ресурсов будут также удалены все ресурсы, созданные в конструкторе.
Удаление отдельных ресурсов
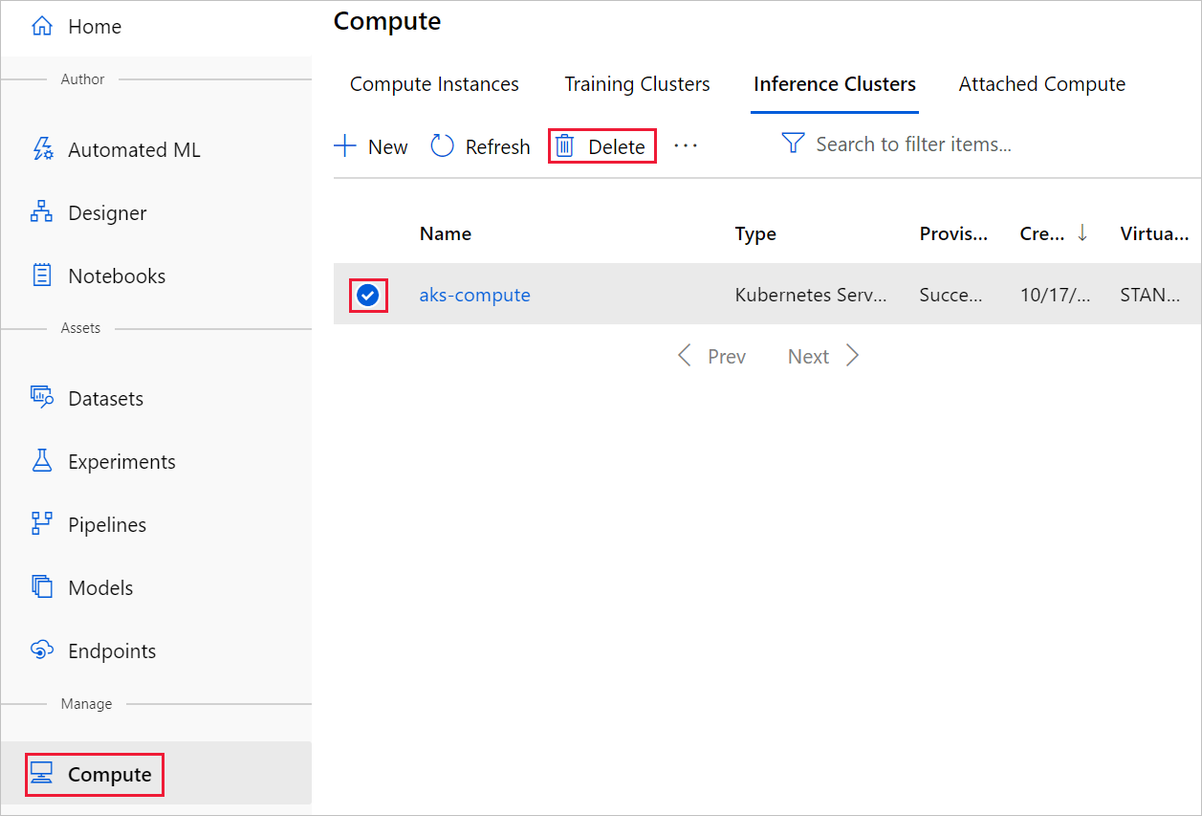
В конструкторе, в котором вы создали эксперимент, удалите отдельные ресурсы, выбрав их и нажав кнопку Удалить.
Созданный вами целевой объект вычислений автоматически масштабируется до нуля узлов, когда он не используется. Это действие предпринимается для снижения расходов. Чтобы удалить целевой объект вычислений, сделайте следующее:
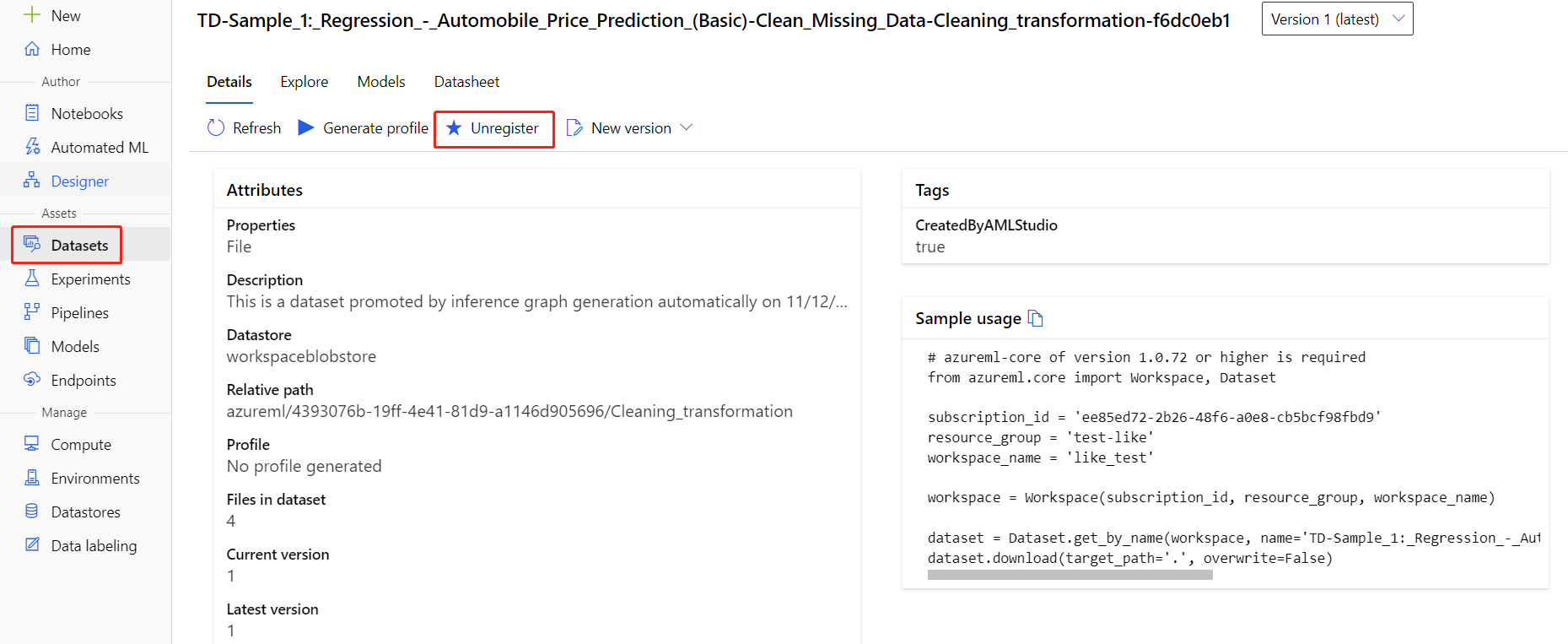
Вы можете отменить регистрацию наборов данных в рабочей области. Для этого выберите каждый набор данных и щелкните Отменить регистрацию.
Чтобы удалить набор данных, перейдите к учетной записи хранения на портале Azure или в приложении "Обозреватель службы хранилища Azure", а затем вручную удалите эти ресурсы.
Дальнейшие действия
В этом учебнике вы узнали как создать, развернуть и использовать модели машинного обучения в конструкторе. Дополнительные сведения об использовании конструктора см. по следующим ссылкам:
- Примеры из конструктора: узнайте, как использовать конструктор для решения других типов проблем.
- Использование Студии машинного обучения Azure в виртуальной сети Azure.