Предварительная обработка данных с помощью хранимой процедуры перед загрузкой в Lakehouse
В этом руководстве показано, как использовать действие скрипта конвейера для выполнения хранимой процедуры для создания таблицы и предварительной обработки данных в хранилище данных Synapse. После этого мы загружаем предварительно обработанную таблицу в Lakehouse.
Необходимые компоненты
Рабочая область с поддержкой Microsoft Fabric. Если у вас еще нет его, см. статью "Создание рабочей области".
Подготовьте хранимую процедуру в хранилище данных Azure Synapse. Заранее создайте следующую хранимую процедуру:
CREATE PROCEDURE spM_add_names AS --Create initial table IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[names]') AND TYPE IN (N'U')) BEGIN DROP TABLE names END; CREATE TABLE names (id INT,fullname VARCHAR(50)); --Populate data INSERT INTO names VALUES (1,'John Smith'); INSERT INTO names VALUES (2,'James Dean'); --Alter table for new columns ALTER TABLE names ADD first_name VARCHAR(50) NULL; ALTER TABLE names ADD last_name VARCHAR(50) NULL; --Update table UPDATE names SET first_name = SUBSTRING(fullname, 1, CHARINDEX(' ', fullname)-1); UPDATE names SET last_name = SUBSTRING(fullname, CHARINDEX(' ', fullname)+1, LEN(fullname)-CHARINDEX(' ', fullname)); --View Result SELECT * FROM names;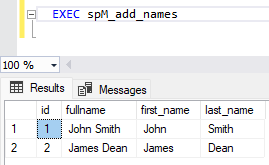
Создание действия скрипта конвейера для выполнения хранимой процедуры
В этом разделе мы используем действие скрипта для запуска хранимой процедуры, созданной в предварительных требованиях.
Выберите действие "Скрипт" и выберите "Создать ", чтобы подключиться к хранилищу данных Azure Synapse.
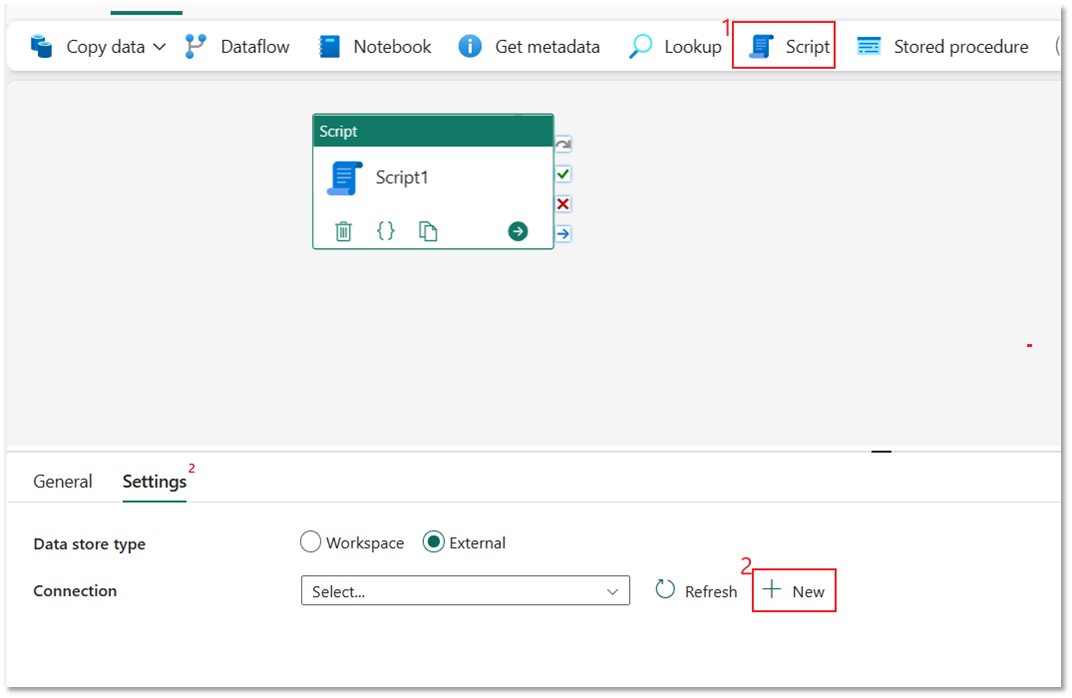
Выберите Azure Synapse Analytics и нажмите кнопку "Продолжить".
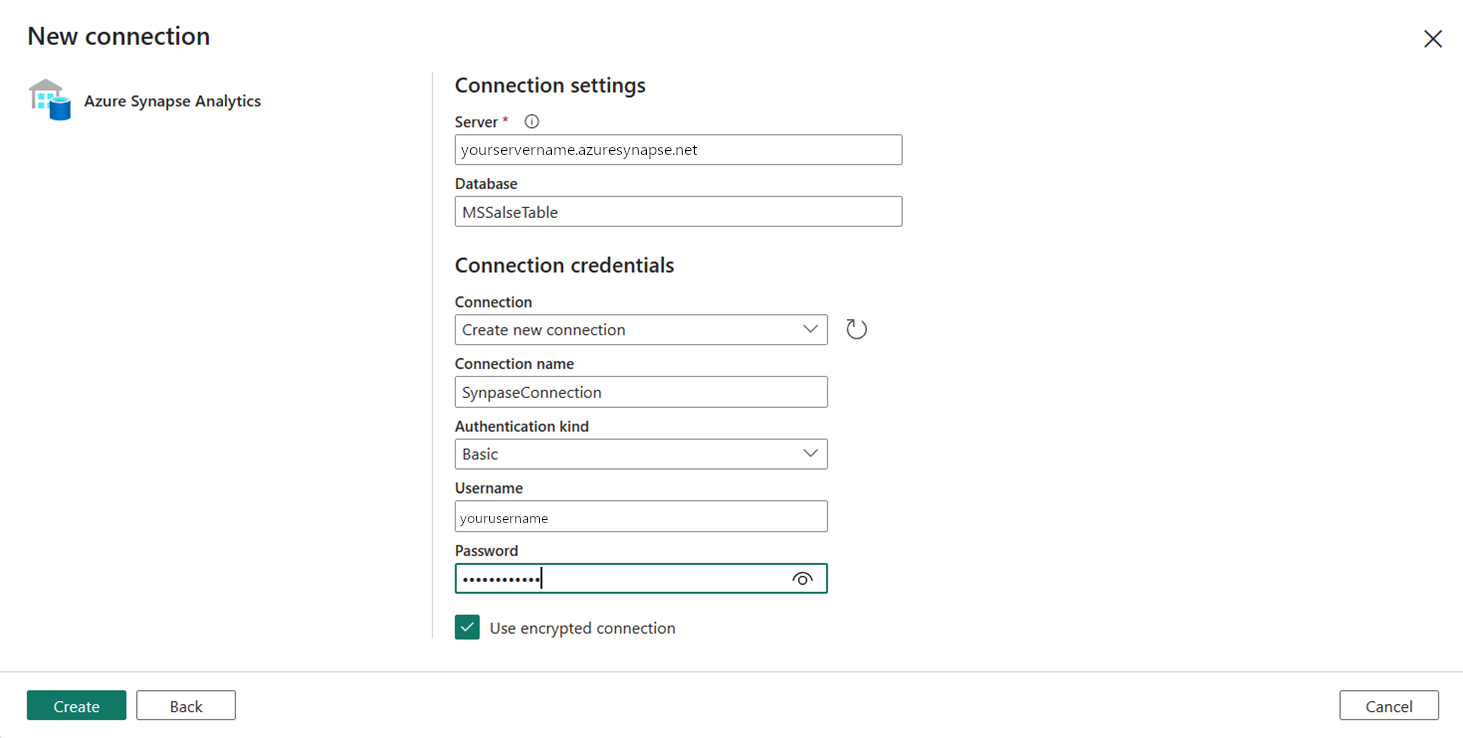
Укажите поля "Сервер", "База данных" и "Пароль" для базовой проверки подлинности и введите Synapse Подключение ion для имени Подключение ion. Затем нажмите кнопку "Создать ", чтобы создать новое подключение.
Входной файл EXEC spM_add_names для выполнения хранимой процедуры. Он создает новую таблицу dbo.name и предварительно обрабатывает данные с помощью простого преобразования, чтобы изменить поле полного имени на два поля, first_name и last_name.
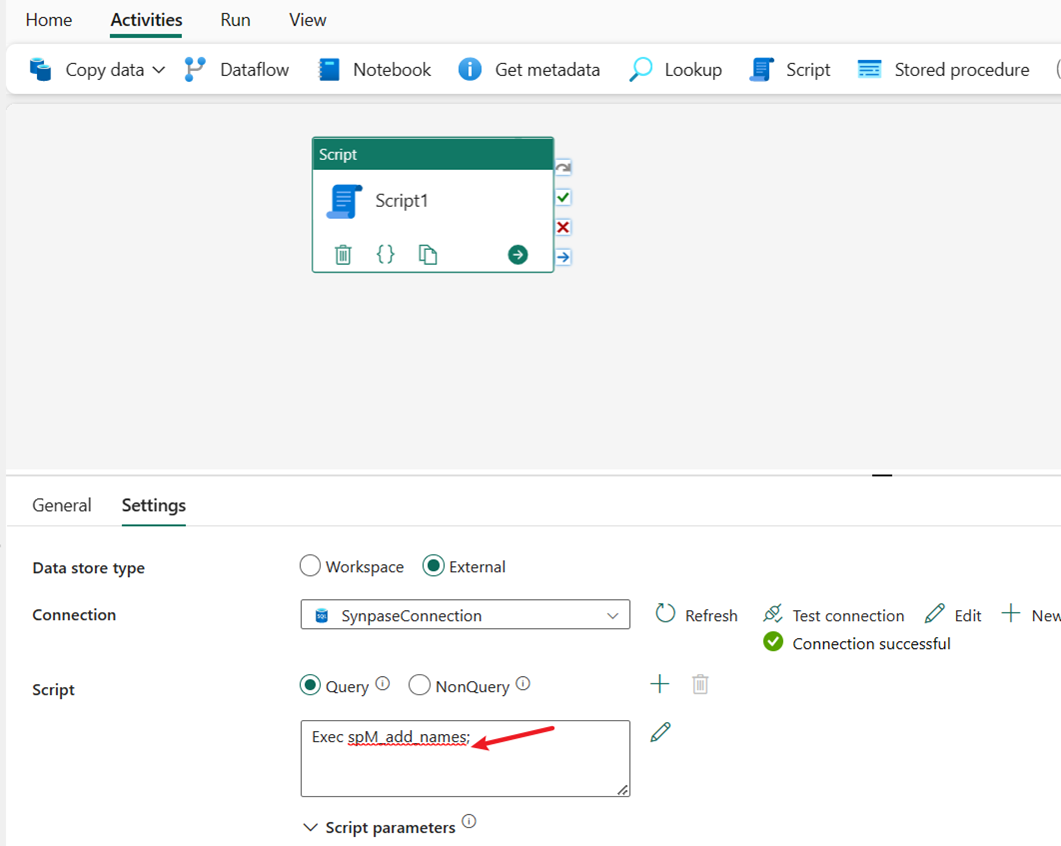


Использование действия конвейера для загрузки предварительно обработанных данных таблицы в Lakehouse
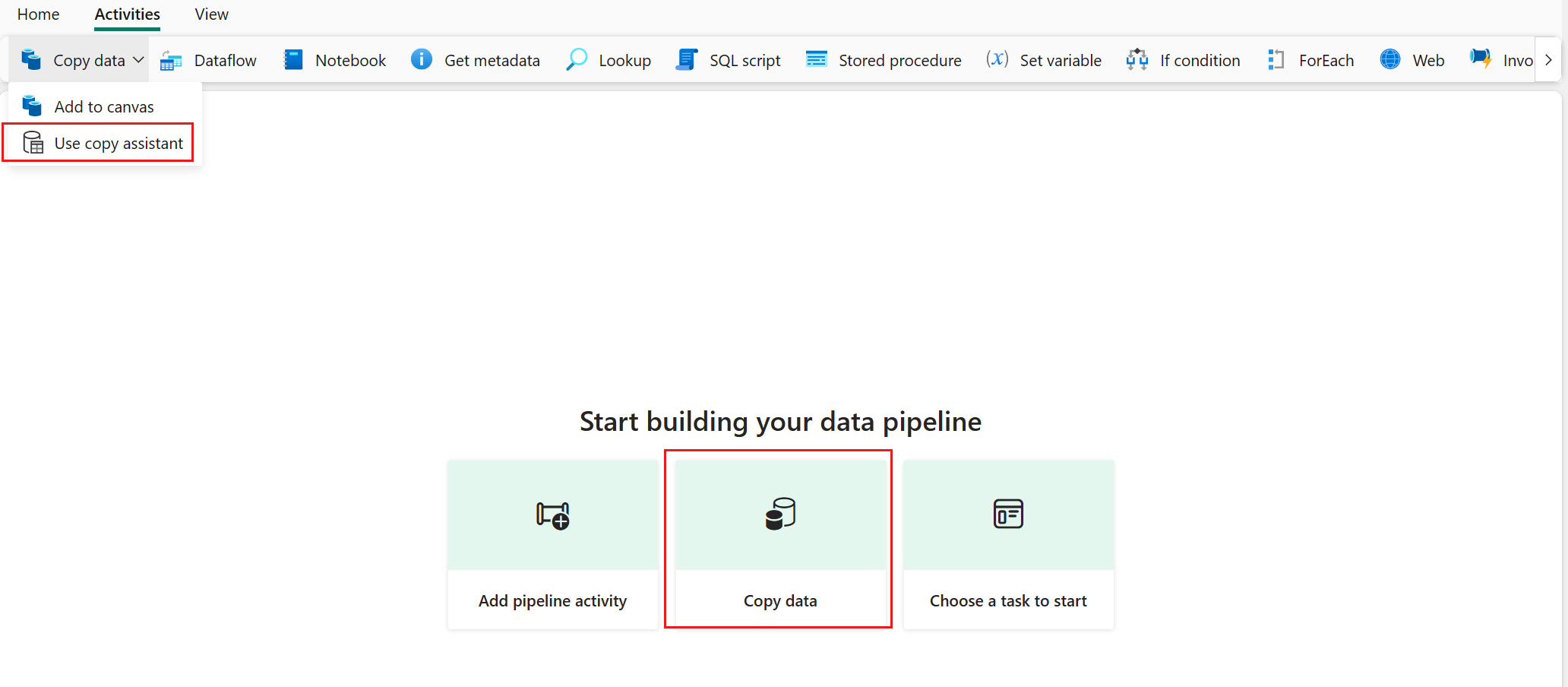
Выберите "Копировать данные", а затем выберите "Использовать помощник копирования".
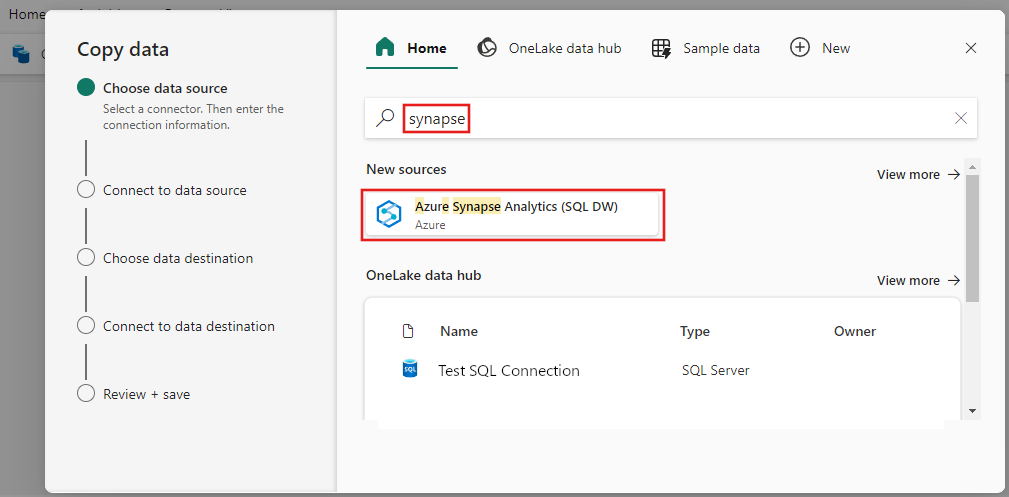
Выберите Azure Synapse Analytics для источника данных и нажмите кнопку "Далее".
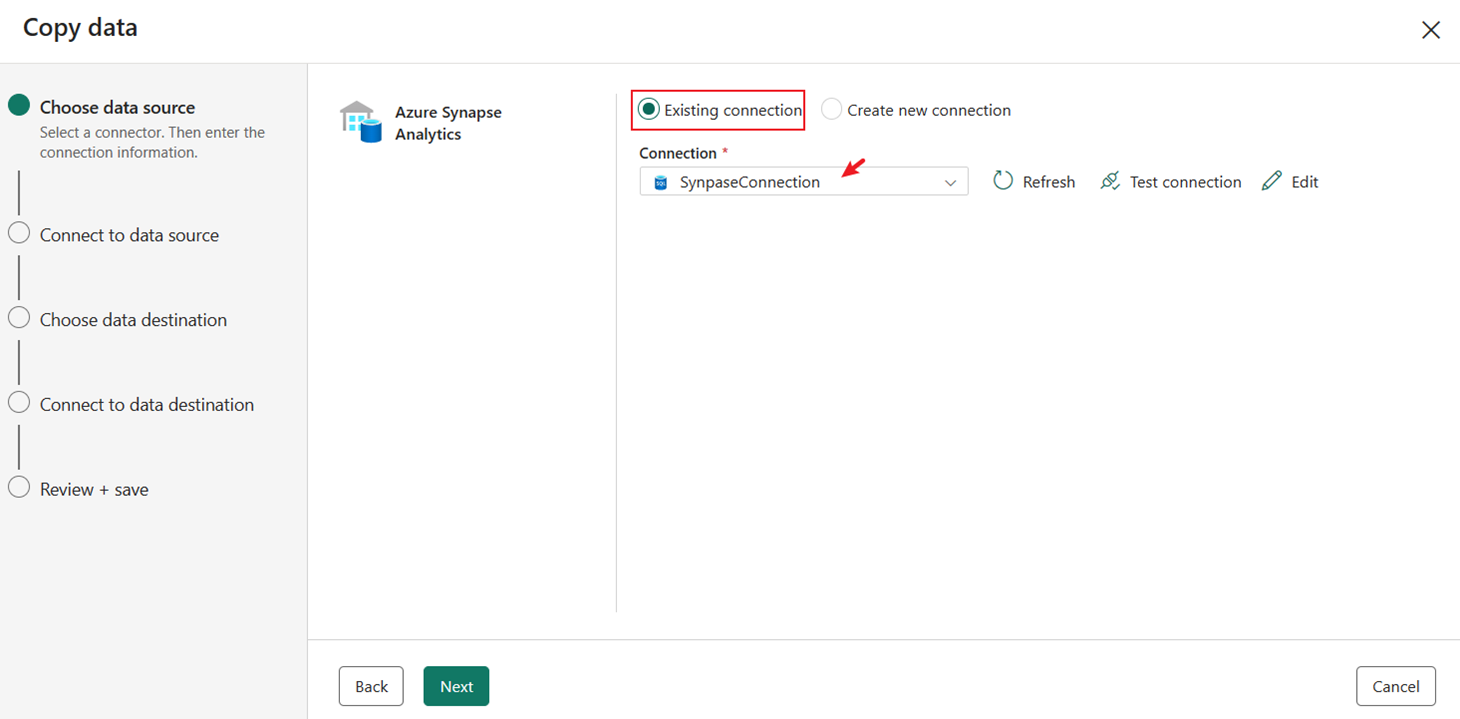
Выберите существующее подключение Synapse Подключение ion, созданное ранее.
Выберите таблицу dbo.name , созданную и предварительно обработанную хранимой процедурой. Затем выберите Далее.
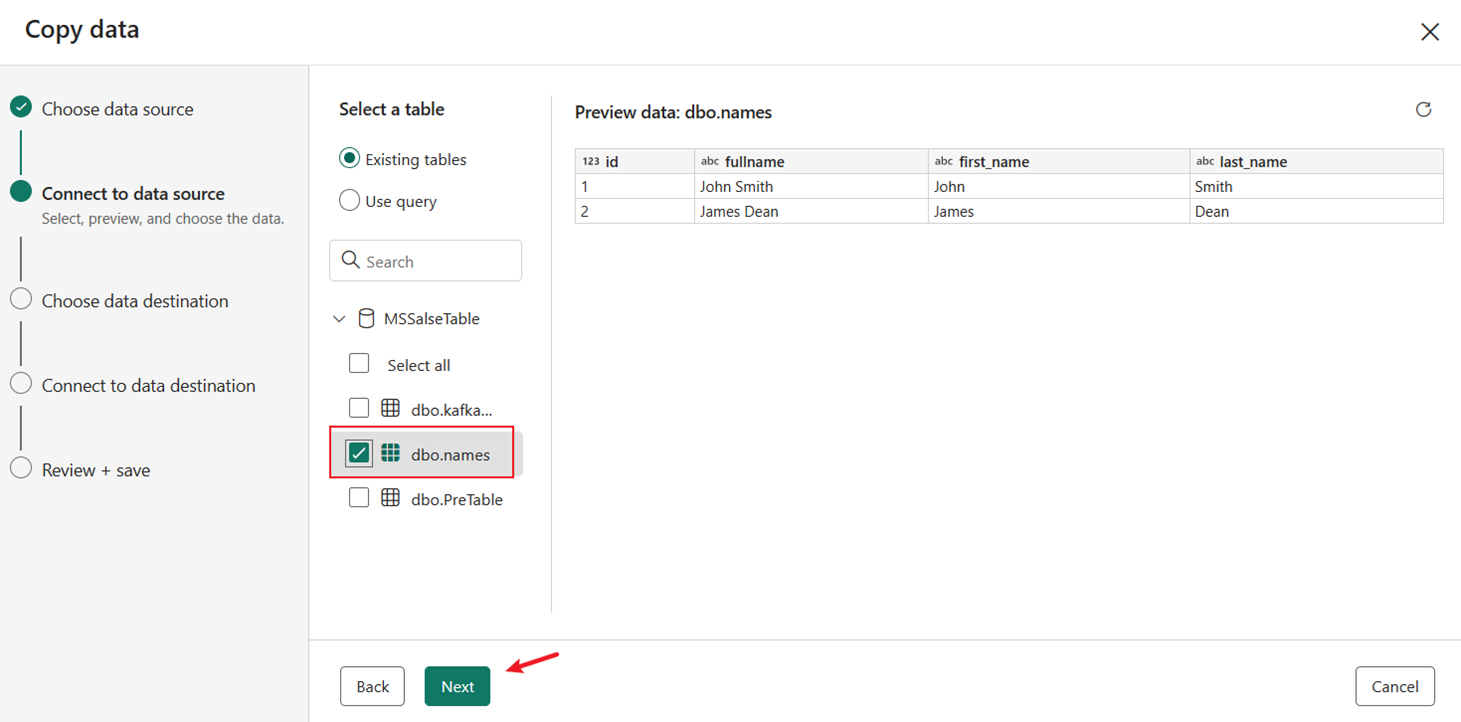
Выберите Lakehouse на вкладке "Рабочая область " в качестве назначения, а затем нажмите кнопку "Далее ".
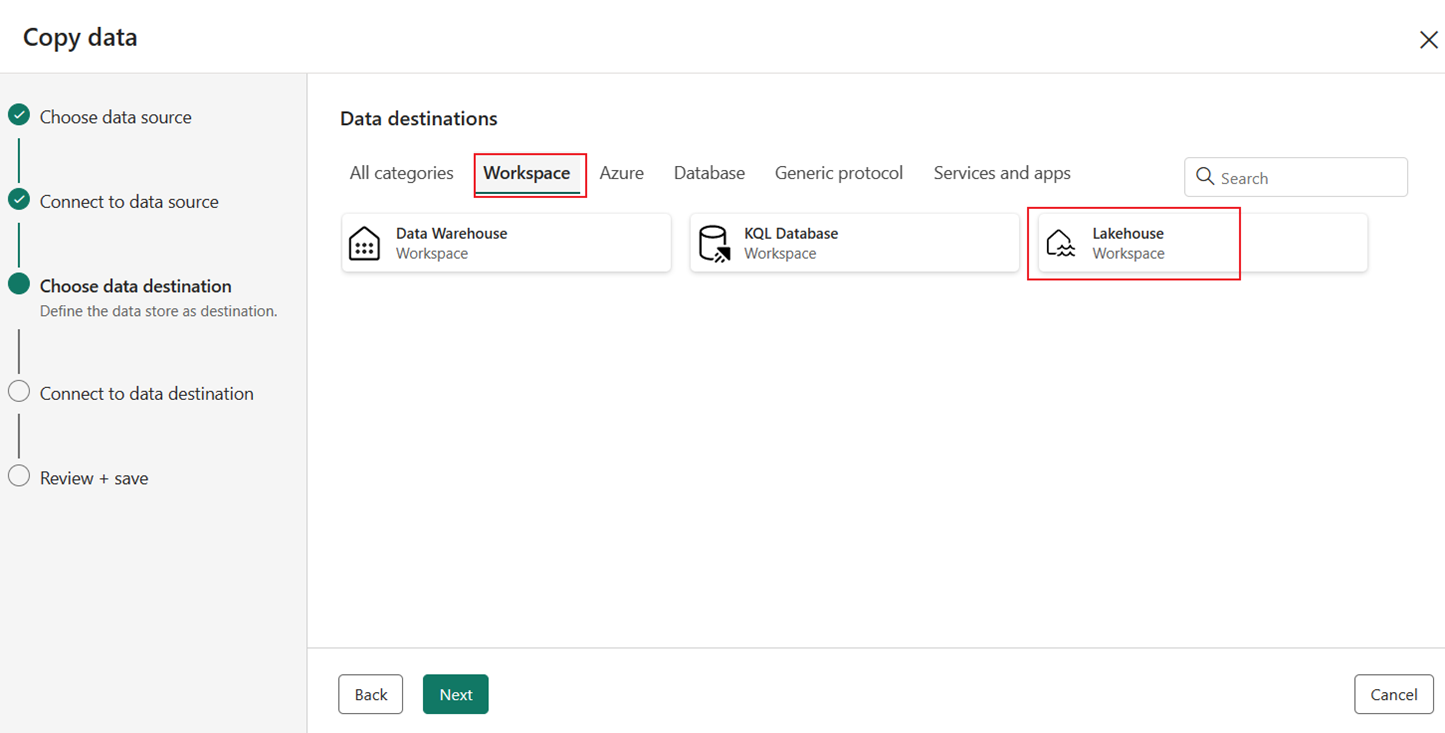
Выберите существующий или создайте новый Lakehouse, а затем нажмите кнопку "Далее".
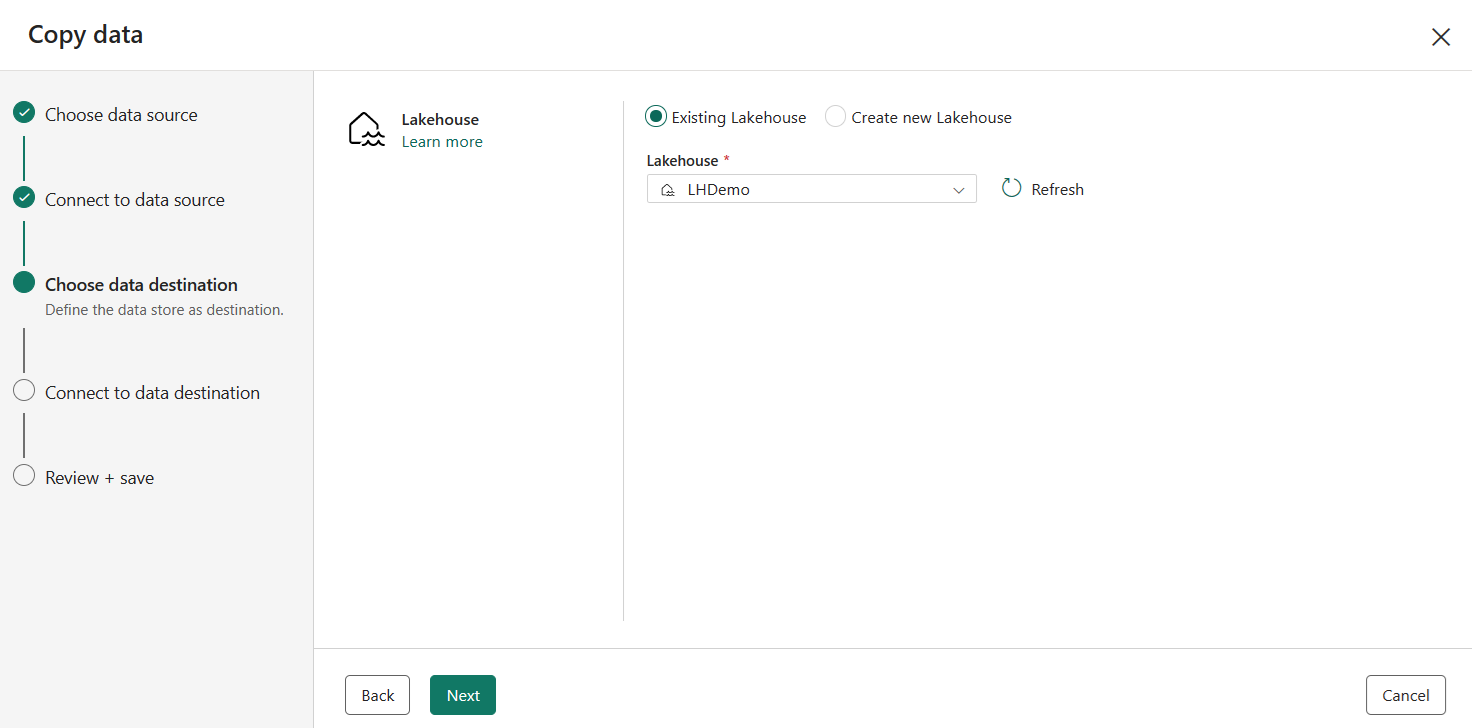
Введите имя целевой таблицы для копирования данных в место назначения Lakehouse и нажмите кнопку "Далее".

Просмотрите сводку на окончательной странице помощник копирования и нажмите кнопку "ОК".
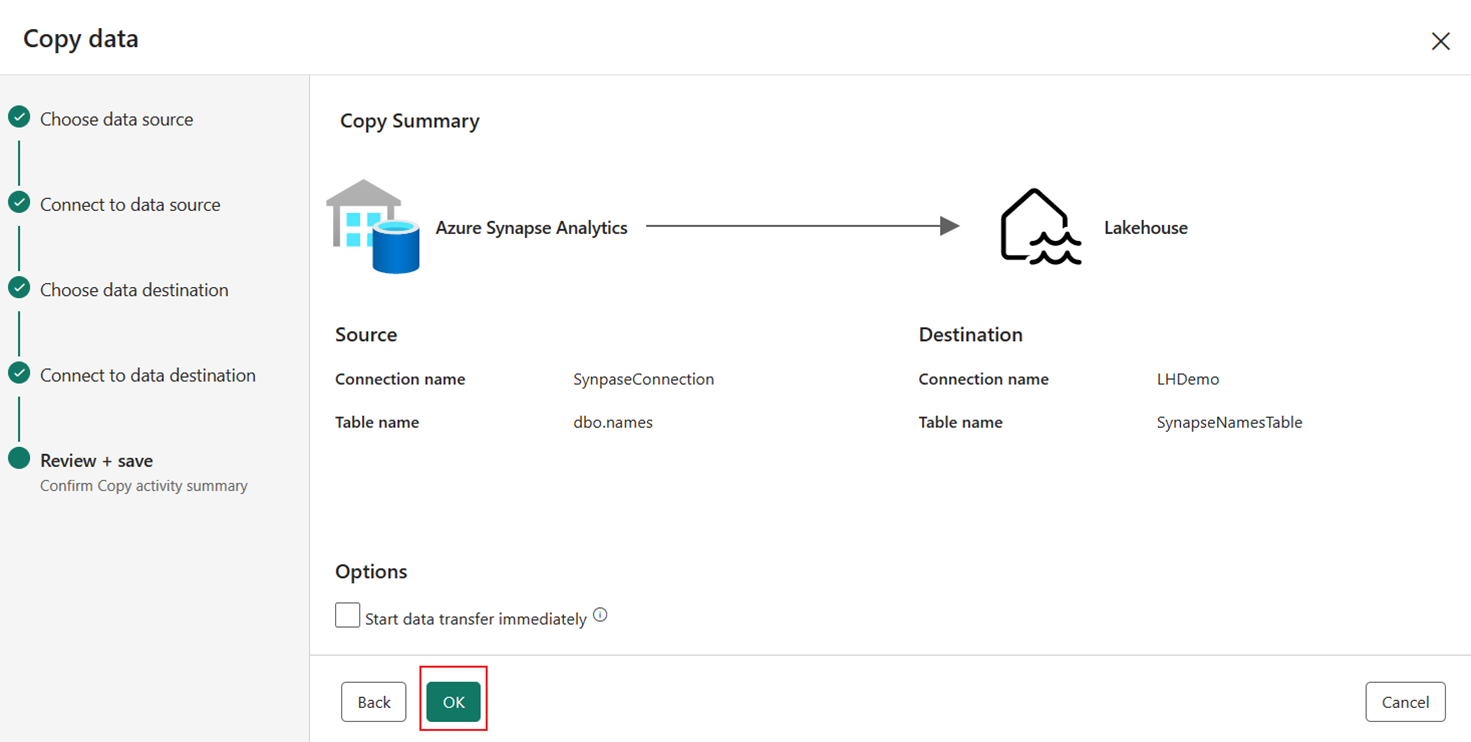
После нажатия кнопки "ОК" на холст конвейера будет добавлен новый действие Copy.
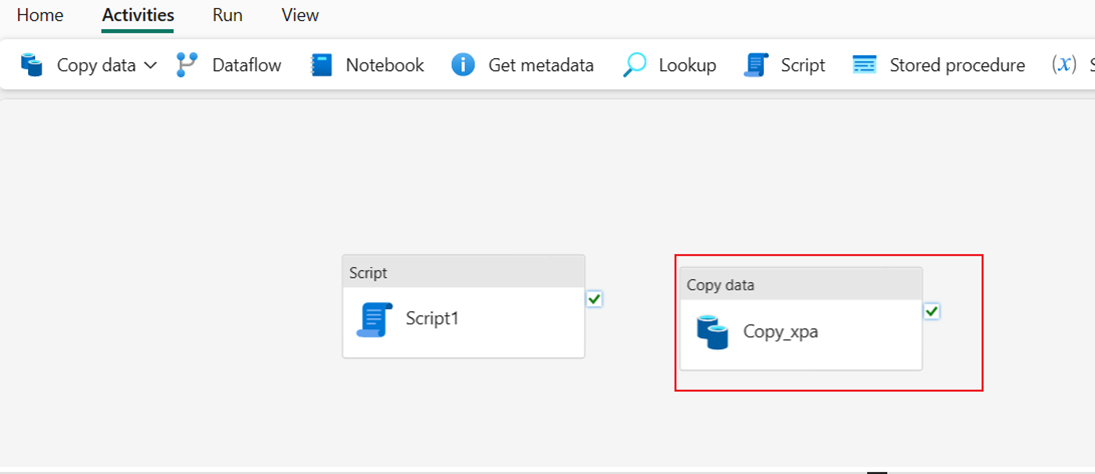



Выполнение двух действий конвейера для загрузки данных
Подключение действия скрипта и копирования данных по При успешном выполнении действия скрипта.
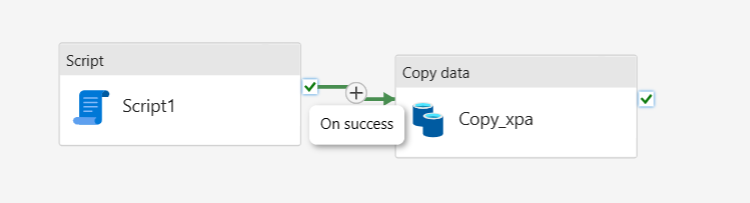
Нажмите кнопку "Выполнить ", а затем "Сохранить" и запустите для выполнения двух действий в конвейере.
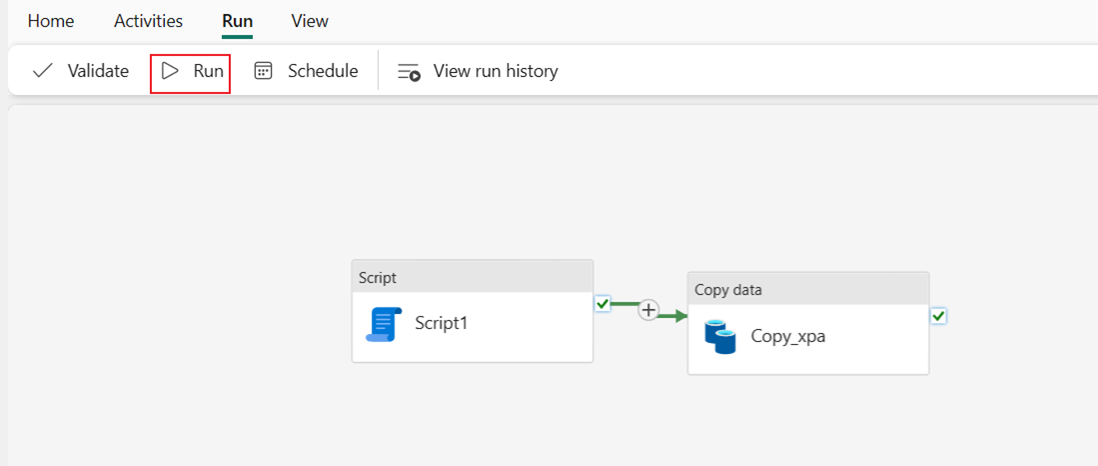
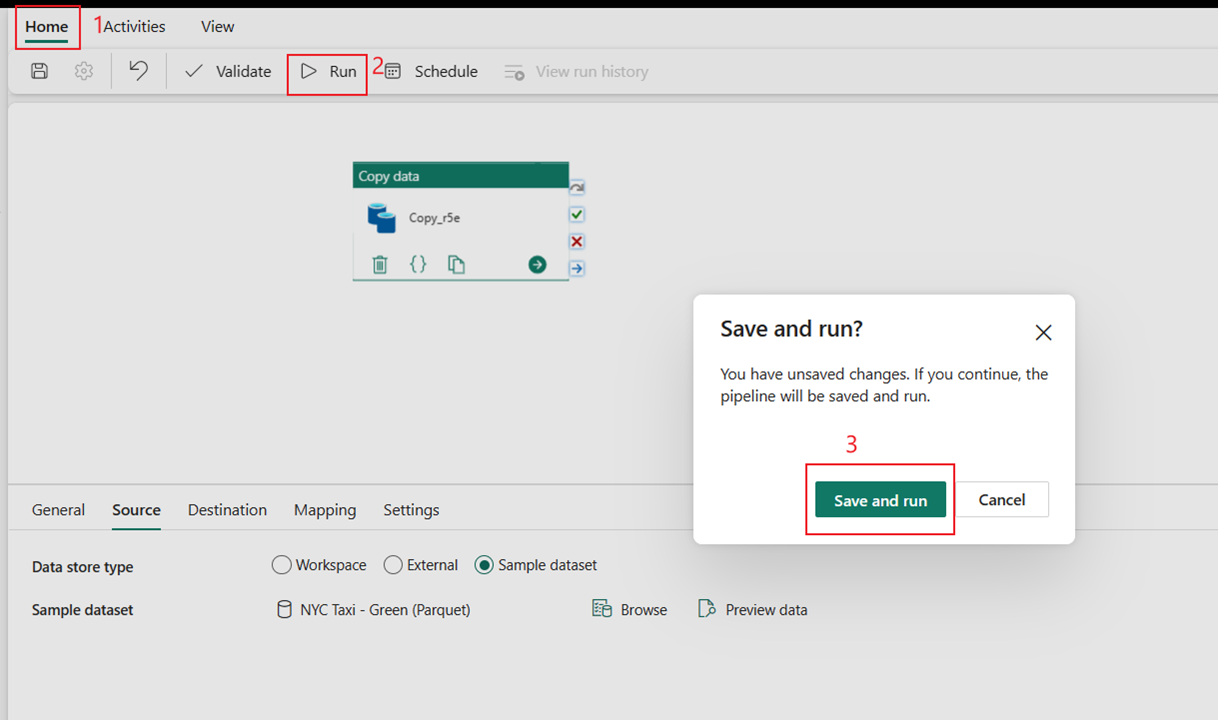
После успешного запуска конвейера можно просмотреть дополнительные сведения.
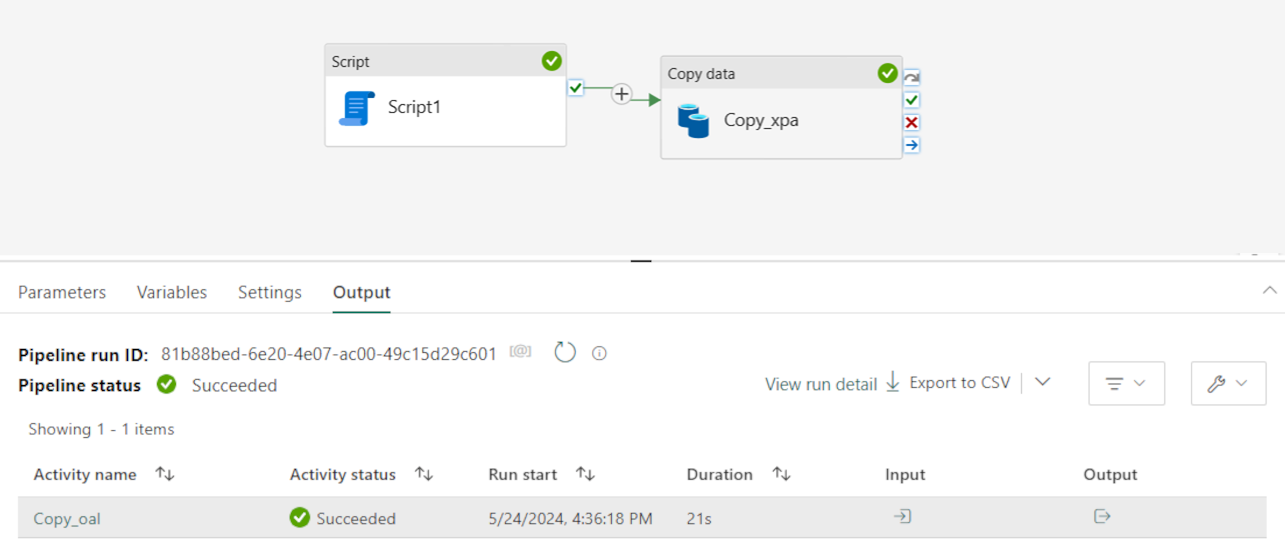
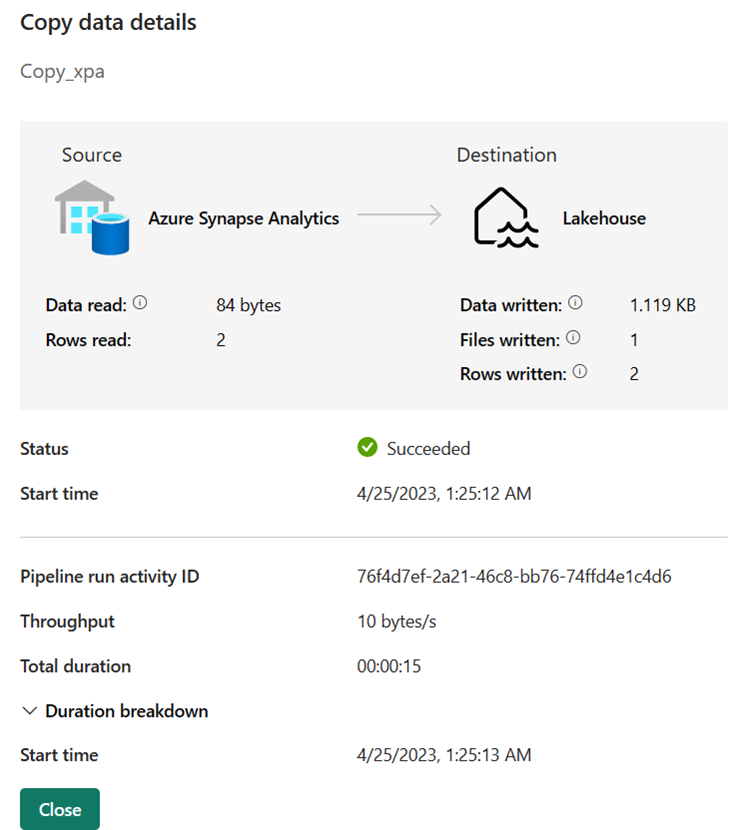
Перейдите в рабочую область и выберите Lakehouse, чтобы проверка результаты.
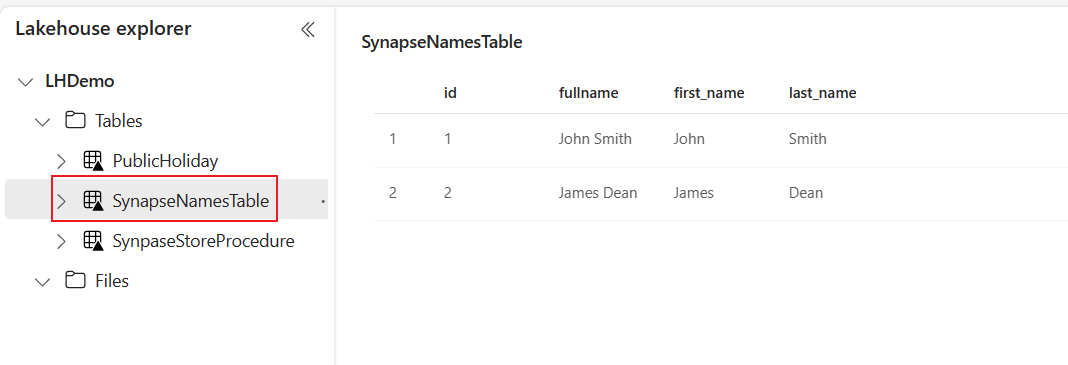
Выберите таблицу SynapseNamesTable, чтобы просмотреть dat, загруженный в Lakehouse.
Связанный контент
В этом примере показано, как предварительно обработать данные с помощью хранимой процедуры перед загрузкой результатов в Lakehouse. Вы научились выполнять следующие задачи:
- Создайте конвейер данных с действием скрипта для выполнения хранимой процедуры.
- Используйте действие конвейера для загрузки предварительно обработанных данных таблицы в Lakehouse.
- Выполните действия конвейера для загрузки данных.
Затем перейдите к дополнительным сведениям о мониторинге выполнения конвейера.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по