Интеграция OneLake с Azure HDInsight
Azure HDInsight — это управляемая облачная служба для аналитики больших данных, которая помогает организациям обрабатывать большие объемы данных. В этом руководстве показано, как подключиться к OneLake с помощью записной книжки Jupyter из кластера Azure HDInsight.
Использование Azure HDInsight
Чтобы подключиться к OneLake с записной книжкой Jupyter из кластера HDInsight:
Создание кластера HDInsight (HDI) Spark. Выполните следующие инструкции. Настройка кластеров в HDInsight.
При предоставлении сведений о кластере запомните имя пользователя и пароль для входа в кластер, так как им потребуется получить доступ к кластеру позже.
Создайте назначаемое пользователем управляемое удостоверение (UAMI): создайте для Azure HDInsight — UAMI и выберите его в качестве удостоверения на экране служба хранилища.
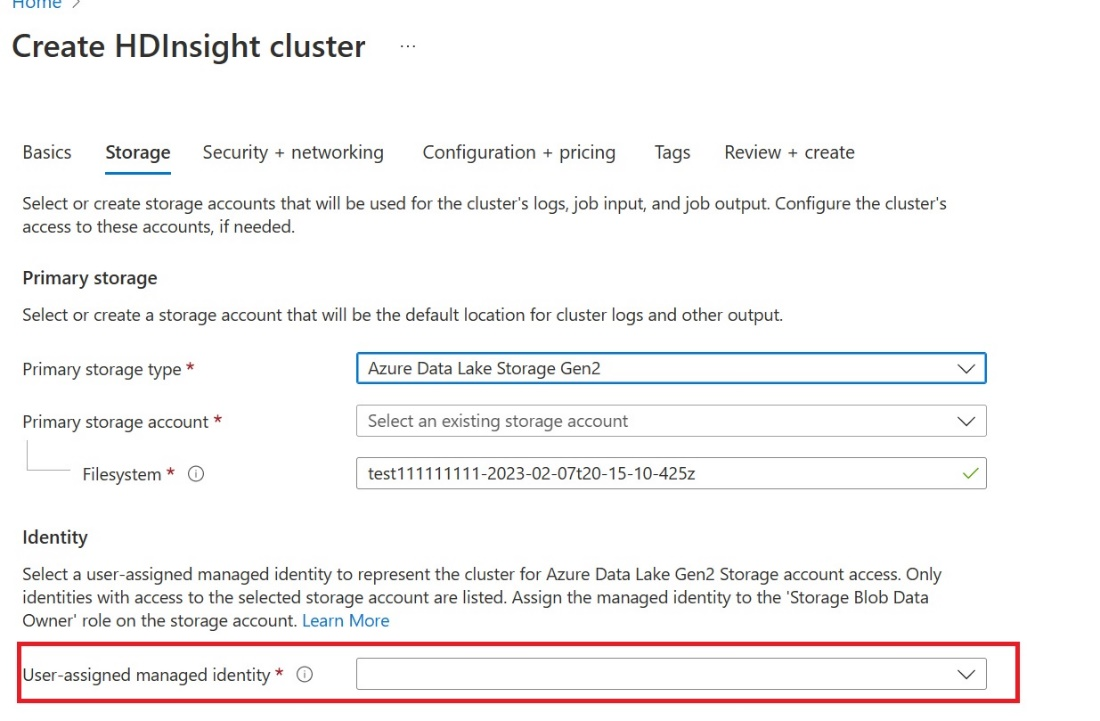
Предоставьте этому UAMI доступ к рабочей области Fabric, содержащей ваши элементы. Сведения о том, какая роль лучше всего подходит, см. в разделе "Роли рабочей области".
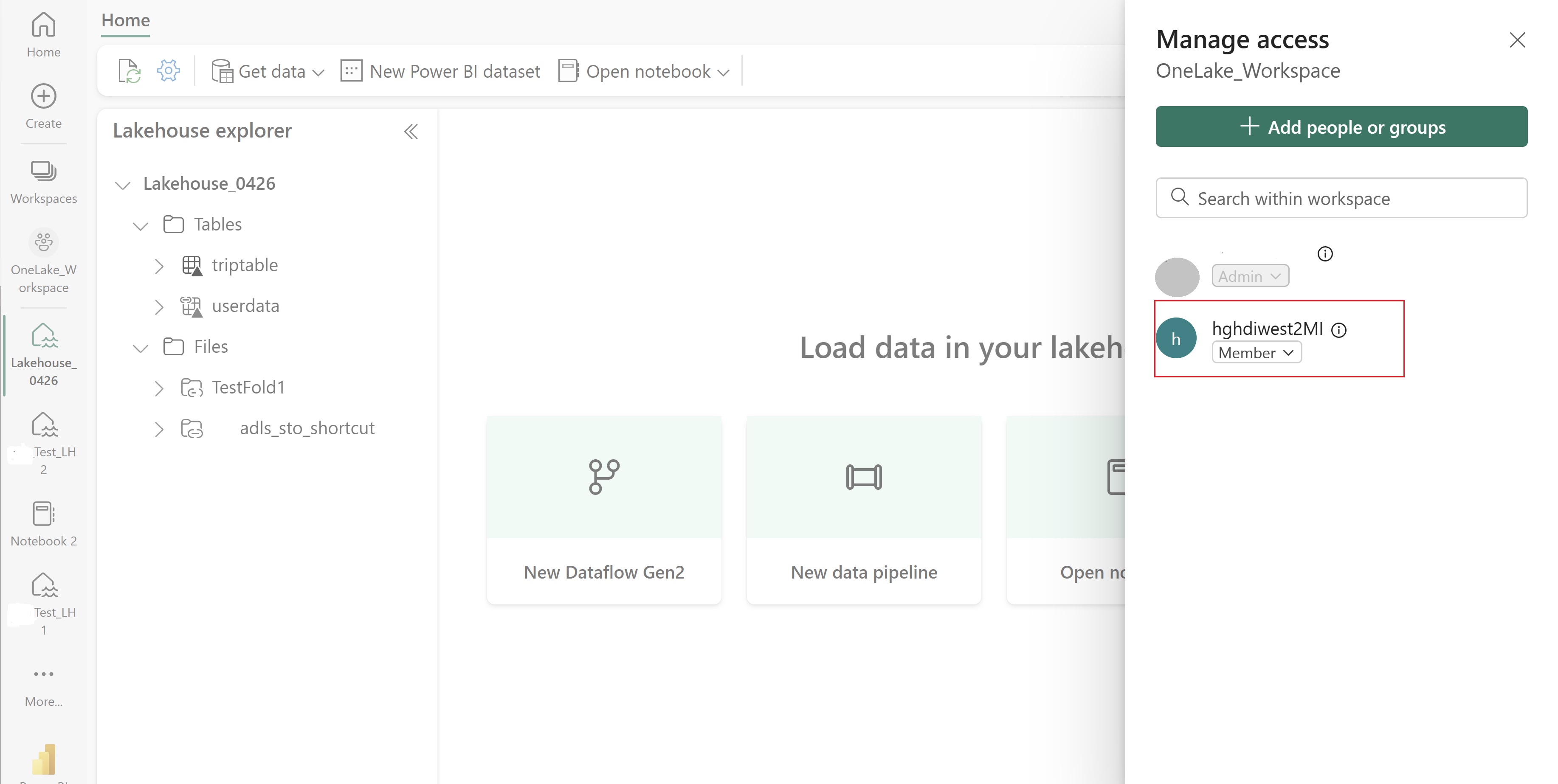
Перейдите к озеру и найдите имя рабочей области и lakehouse. Их можно найти в URL-адресе озера или области "Свойства " для файла.
В портал Azure найдите кластер и выберите записную книжку.
Введите учетные данные, предоставленные при создании кластера.
Создайте записную книжку Spark.
Скопируйте имена рабочей области и озера в записную книжку и создайте URL-адрес OneLake для lakehouse. Теперь вы можете прочитать любой файл из этого пути.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()Попробуйте записать некоторые данные в lakehouse.
writecsvdf = df.write.format("csv").save(fp + "out.csv")Убедитесь, что данные были успешно записаны, проверка озера или прочитав только что загруженный файл.




Теперь вы можете читать и записывать данные в OneLake с помощью записной книжки Jupyter в кластере HDI Spark.
Связанный контент
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по