Получение данных из хранилища Azure
В этой статье вы узнаете, как получить данные из хранилища Azure (контейнер ADLS 2-го поколения, контейнер BLOB-объектов или отдельные BLOB-объекты) в новую или существующую таблицу.
Необходимые компоненты
- Рабочая область с емкостью с поддержкой Microsoft Fabric
- База данных KQL с разрешениями на редактирование
- Учетная запись хранения
Оригинал
На нижней ленте базы данных KQL выберите " Получить данные".
В окне "Получение данных" выбрана вкладка "Источник".
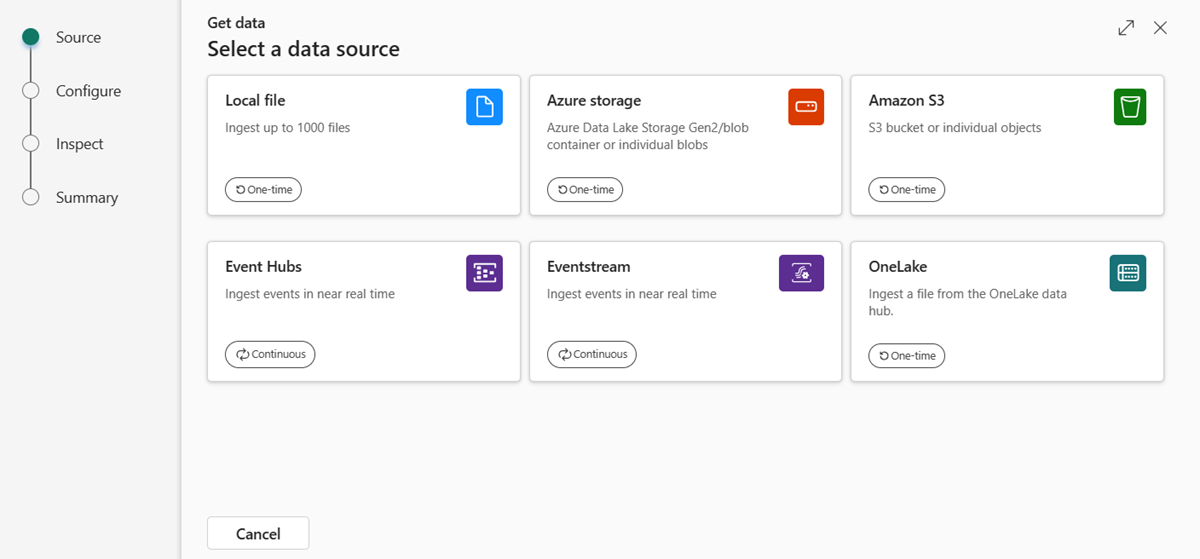
Выберите источник данных из доступного списка. В этом примере вы используете данные из хранилища Azure.

Конфигурирование
Выберите целевую таблицу. Если вы хотите принять данные в новую таблицу, нажмите кнопку +Создать таблицу и введите имя таблицы.
Примечание.
Имена таблиц могут содержать до 1024 символов, включая пробелы, буквенно-цифровые символы, дефисы и символы подчеркивания. Специальные символы не поддерживаются.
Чтобы добавить источник данных, вставьте строка подключения хранилища в поле URI и выберите +. В следующей таблице перечислены поддерживаемые методы проверки подлинности и разрешения, необходимые для приема данных из хранилища Azure.
Authentication method Отдельный большой двоичный объект Контейнер BLOB-объектов Azure Data Lake Storage 2-го поколения Маркер общего доступа (SAS) Чтение и запись Чтение и список Чтение и список ключ доступа к учетной записи служба хранилища Примечание.
- Можно добавить до 10 отдельных BLOB-объектов или принять до 5000 BLOB-объектов из одного контейнера. Вы не можете одновременно прием обоих.
- Каждый большой двоичный объект может быть максимум 1 ГБ без сжатия.
Если вы вставили строка подключения для контейнера BLOB-объектов или Azure Data Lake Storage 2-го поколения, можно добавить следующие необязательные фильтры:
Параметр Описание поля Фильтры файлов (необязательно) Folder path Фильтрует данные для приема файлов с определенным путем к папке. Расширение файла Фильтрует данные для приема файлов только с определенным расширением файла.
Выберите Далее

Проверка
Откроется вкладка "Проверка " с предварительным просмотром данных.
Чтобы завершить процесс приема, нажмите кнопку Готово.

Необязательно.
- Выберите средство просмотра команд, чтобы просмотреть и скопировать автоматические команды, созданные из входных данных.
- Используйте раскрывающийся список файла определения схемы, чтобы изменить файл, из который выводится схема.
- Измените автоматически выведенный формат данных, выбрав нужный формат из раскрывающегося списка. Дополнительные сведения см. в разделе "Форматы данных", поддерживаемые аналитикой в режиме реального времени.
- Изменение столбцов.
- Изучите дополнительные параметры на основе типа данных.
Изменить столбцы
Примечание.
- Для табличных форматов (CSV, TSV, PSV) невозможно сопоставить столбец дважды. Чтобы сопоставить существующий столбец, сначала удалите новый столбец.
- Нельзя изменить тип существующего столбца. При попытке выполнить сопоставление для столбца, имеющего другой формат, могут отобразиться пустые столбцы.
Изменения, которые вы можете внести в таблицу, зависят от следующих параметров:
- Тип таблицы — новая или существующая.
- Тип сопоставления — новое или существующее.
| Тип таблицы | Тип сопоставления | Доступные корректировки |
|---|---|---|
| Новая таблица | Создать сопоставление | Переименование столбца, изменение типа данных, изменение источника данных, преобразование сопоставления, добавление столбца, удаление столбца |
| Существующая таблица | Создать сопоставление | Добавьте столбец (в котором можно изменить тип данных, переименовать и обновить) |
| Существующая таблица | Существующее сопоставление | ничего |

Преобразования сопоставлений
Некоторые сопоставления форматов данных (Parquet, JSON и Avro) поддерживают простые преобразования во время приема. Чтобы применить преобразования сопоставления, создайте или обновите столбец в окне "Изменение столбцов ".
Преобразования сопоставления можно выполнять в столбце строки типа или даты и времени с источником с типом данных int или long. Поддерживаются следующие преобразования сопоставлений:
- DateTimeFromUnixSeconds;
- DateTimeFromUnixMilliseconds;
- DateTimeFromUnixMicroseconds;
- DateTimeFromUnixNanoseconds.
Дополнительные параметры на основе типа данных
Табличные (CSV, TSV, PSV):
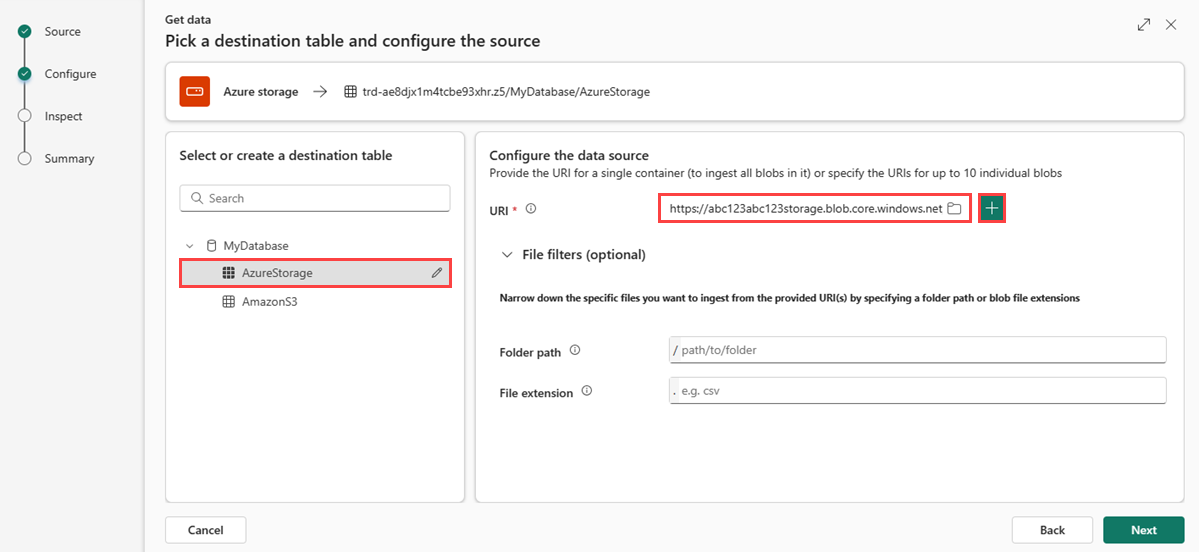
При приеме табличных форматов в существующей таблице можно выбрать> схему расширенного сохранения таблицы. Табличные данные не обязательно включают имена столбцов, которые используются для сопоставления исходных данных с существующими столбцами. Если этот параметр проверка, сопоставление выполняется по порядку, а схема таблицы остается той же. Если этот параметр не является проверка, для входящих данных создаются новые столбцы независимо от структуры данных.
Чтобы использовать первую строку в качестве имен столбцов, выберите "Дополнительно>первая строка" — заголовок столбца.
JSON:
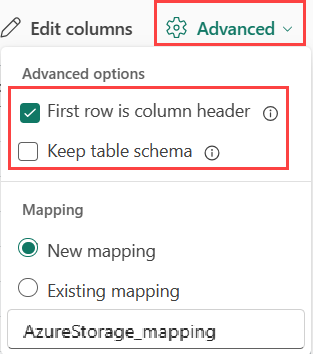
Чтобы определить деление данных JSON, выберите расширенные>вложенные уровни от 1 до 100.
Если выбрать строки JSON расширенного>пропускания с ошибками, данные будут приема в формате JSON. Если оставить это поле проверка не выбрано, данные будут приема в формате multijson.
Итоги
В окне подготовки данных все три шага помечаются зеленым проверка пометками после успешного приема данных. Вы можете выбрать карта для запроса, удалить прием данных или просмотреть панель мониторинга сводки приема.

Связанный контент
- Сведения об управлении базой данных см. в разделе "Управление данными"
- Сведения о создании, хранении и экспорте запросов см. в разделе "Запрос данных" в наборе запросов KQL
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по