Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Язык запросов Kusto (KQL) имеет встроенные функции обнаружения аномалий и прогнозирования для проверки аномального поведения. После обнаружения такого шаблона можно запустить анализ первопричин (RCA), чтобы устранить или устранить аномалию.
Процесс диагностики является сложным и длительным, и выполняется экспертами домена. Процесс состоит из следующих шагов.
- Получение и присоединение дополнительных данных из разных источников для одного и того же интервала времени
- Поиск изменений в распределении значений по нескольким измерениям
- Диаграмма дополнительных переменных
- Другие методы, основанные на знаниях и интуиции домена
Так как эти сценарии диагностики являются общими, подключаемые модули машинного обучения доступны для упрощения этапа диагностики и сокращения длительности RCA.
Все три из следующих подключаемых модулей машинного обучения реализуют алгоритмы кластеризации: autocluster, basketи diffpatterns. Модули autocluster и basket группируют один набор записей, а модуль diffpatterns группирует различия между двумя наборами записей.
Кластеризация одного набора записей
Распространенный сценарий включает набор данных, выбранный определенными критериями, такими как:
- Окно времени, показывающее аномальное поведение
- Чтение устройства с высокой температурой
- Команды длительности
- Основные расходы пользователей
Вы хотите быстро и легко найти общие шаблоны (сегменты) в данных. Шаблоны — это подмножество набора данных, записи которого используют одинаковые значения по нескольким измерениям (категориальным столбцам).
В следующем запросе создается и отображается временной ряд исключений служб в пределах недели с интервалом в десять минут.
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m
| render timechart with(title="Service exceptions over a week, 10 minutes resolution")
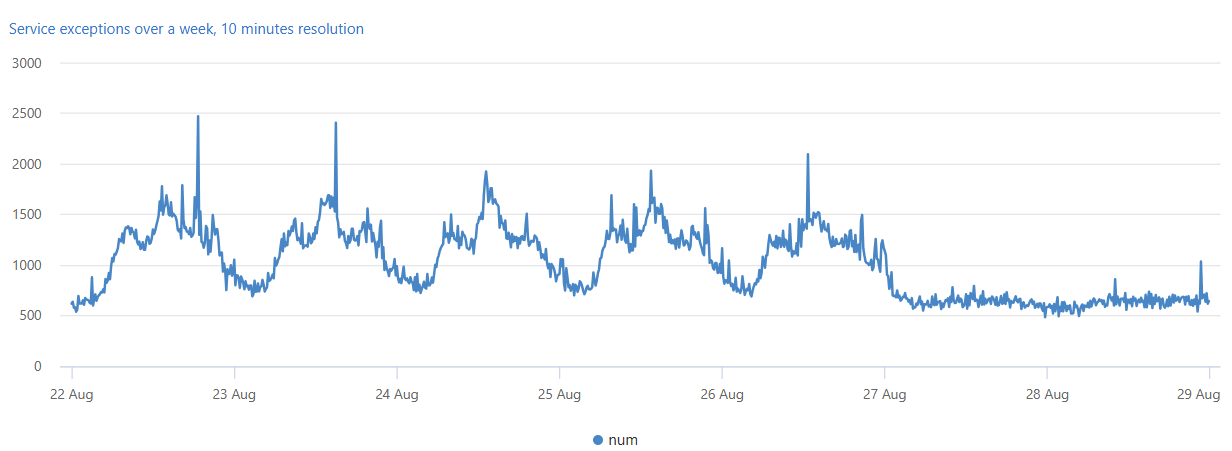
Число исключений службы коррелирует с общим трафиком службы. Вы можете четко видеть ежедневный шаблон для рабочих дней, понедельник до пятницы. В середине дня наблюдается рост числа исключений в сервисах, а их количество в течение ночи снижается. Плоские низкие показания видны в выходные дни. Пики исключений можно обнаружить с помощью обнаружения аномалий временных рядов.
Второй всплеск данных происходит во вторник днем. Следующий запрос используется для дальнейшей диагностики и проверки того, является ли он резким пиком. Запрос перерисовывает диаграмму вокруг всплеска в более высоком разрешении 8 часов в одноминутных ячейках. Затем можно изучить границы.
let min_t=datetime(2016-08-23 11:00);
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to min_t+8h step 1m
| render timechart with(title="Zoom on the 2nd spike, 1 minute resolution")
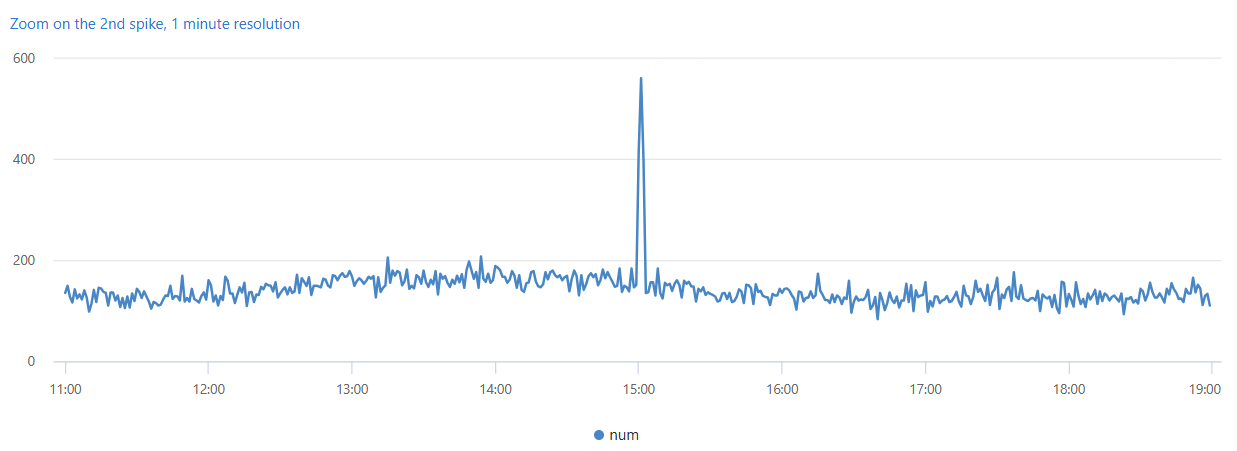
Вы видите узкий двухминутный пик с 15:00 до 15:02. В следующем запросе подсчитывать исключения в этом двухминутном окне:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| count
| Численность |
|---|
| 972 |
В следующем запросе пример 20 исключений из 972:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| take 20
| PreciseTimeStamp | Регион | ScaleUnit | Идентификатор развертывания | Точка трассировки | СервисХост |
|---|---|---|---|---|---|
| 2016-08-23 15:00:08.7302460 | скус | su5 | 9dbd1b161d5b4779a73cf19a7a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:09.9496584 | скус | su5 | 9dbd1b161d5b4779a73cf19a7a7836ebd6 | 10007006 | 8d257da1-7a1c-44f5-9acd-f9e02ff507fd |
| 2016-08-23 15:00:10.5911748 | скус | su5 | 9dbd1b161d5b4779a73cf19a7a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:12.2957912 | скус | su5 | 9dbd1b161d5b4779a73cf19a7a7836ebd6 | 10007007 | f855fcef-ebfe-405d-aaf8-9c5e2e43d862 |
| 2016-08-23 15:00:18.5955357 | скус | su5 | 9dbd1b161d5b4779a73cf19a7a7836ebd6 | 10007006 | 9d390e07-417d-42eb-bebd-793965189a28 |
| 2016-08-23 15:00:20.7444854 | скус | su5 | 9dbd1b161d5b4779a73cf19a7a7836ebd6 | 10007006 | 6e54c1c8-42d3-4e4e-8b79-9bb076ca771f1f1 |
| 2016-08-23 15:00:23.8694999 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 36109 | 19422243-19b9-4d85-9ca6-bc961861d287 |
| 2016-08-23 15:00:26.4271786 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 36109 | 3271bae4-1c5b-4f73-98ef-cc117e9be914 |
| 2016-08-23 15:00:27.8958124 | скус | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 904498 | 8cf38575-fca9-48ca-bd7c-211196f6d6765 |
| 2016-08-23 15:00:32.9884969 | скус | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007007 | d5c7c825-9d46-4ab7-a0c1-8e2ac1d83ddb |
| 2016-08-23 15:00:34.5061623 | скус | su5 | 9dbd1b161d5b4779a73cf19a7a7836ebd6 | 1002110 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:37.4490273 | скус | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | f2ee8254-173c-477d-a1de-4902150ea50d |
| 2016-08-23 15:00:41.2431223 | скус | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 103200 | 8cf38575-fca9-48ca-bd7c-211196f6d6765 |
| 2016-08-23 15:00:47.2983975 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 423690590 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:50.5932834 | скус | su5 | 9dbd1b161d5b4779a73cf19a7a7836ebd6 | 10007006 | 2a41b552-aa19-4987-8cdd-410a3af016ac |
| 2016-08-23 15:00:50.8259021 | скус | su5 | 9dbd1b161d5b4779a73cf19a7a7836ebd6 | 1002110 | 0d56b8e3-470d-4213-91da-97405f8d005e |
| 2016-08-23 15:00:53.2490731 | скус | su5 | 9dbd1b161d5b4779a73cf19a7a7836ebd6 | 36109 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:57.0000946 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 64038 | cb55739e-4afe-46a3-970f-1b49d8ee7564 |
| 2016-08-23 15:00:58.2222707 | скус | su5 | 9dbd1b161d5b4779a73cf19a7a7836ebd6 | 10007007 | 8215dcf6-2de0-42bd-9c90-181c70486c9c |
| 2016-08-23 15:00:59.9382620 | скус | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | 451e3c4c-0808-4566-a64d-84d85cf30978 |
Несмотря на то что существует менее тысячи исключений, все еще трудно найти общие сегменты, так как в каждом столбце имеется несколько значений. Плагин autocluster() можно использовать для мгновенного извлечения краткого списка общих сегментов и поиска интересных кластеров в течение двухминутного всплеска, как показано в следующем запросе.
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate autocluster()
| Идентификатор сегмента | Численность | Процент | Регион | ScaleUnit | Идентификатор развертывания | СервисХост |
|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | вода | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 1 | 94 | 9.67078189300411 | скус | su5 | 9dbd1b161d5b4779a73cf19a7a7836ebd6 | |
| 2 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 3 | 68 | 6.99588477366255 | скус | su3 | 90d3d2fc7ecc430c9621ece335651a01 | |
| 4 | 55 | 5,65843621399177 | weu | su4 | be1d6d7ac9574cbc9a2cb8ee20f16fc |
В результатах выше видно, что наиболее доминирующий сегмент содержит 65,74% общих записей исключений и использует четыре измерения. Следующий сегмент гораздо менее распространен. Он содержит только 9,67% записей и делится тремя измерениями. Другие сегменты еще менее распространены.
Autocluster использует собственный алгоритм для интеллектуального анализа нескольких измерений и извлечения интересных сегментов. "Интересно" означает, что каждый сегмент имеет значительное покрытие как набора записей, так и набора функций. Сегменты также различаются, то есть каждый из них отличается от других. Один или несколько этих сегментов могут быть релевантными для процесса RCA. Чтобы свести к минимуму проверку и оценку сегментов, автокластер извлекает только небольшой список сегментов.
Вы также можете использовать подключаемый модуль basket(), как показано в следующем запросе.
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate basket()
| Идентификатор сегмента | Численность | Процент | Регион | ScaleUnit | Идентификатор развертывания | Точка трассировки | СервисХост |
|---|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | вода | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec | |
| 1 | 642 | 66.0493827160494 | вода | su7 | b5d1d4df547d4a04ac15885617edba57 | ||
| 2 | 324 | 33.3333333333333 | вода | su7 | b5d1d4df547d4a04ac15885617edba57 | 0 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 3 | 315 | 32.4074074074074 | вода | su7 | b5d1d4df547d4a04ac15885617edba57 | 16108 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 4 | 328 | 33.7448559670782 | 0 | ||||
| 5 | 94 | 9.67078189300411 | скус | su5 | 9dbd1b161d5b4779a73cf19a7a7836ebd6 | ||
| 6 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | ||
| 7 | 68 | 6.99588477366255 | скус | su3 | 90d3d2fc7ecc430c9621ece335651a01 | ||
| 8 | 167 | 17.1810699588477 | скус | ||||
| 9 | 55 | 5,65843621399177 | weu | su4 | be1d6d7ac9574cbc9a2cb8ee20f16fc | ||
| 10 | 92 | 9.46502057613169 | 10007007 | ||||
| 11 | девяносто | 9,25925925925926 | 10007006 | ||||
| 12 | 57 | 5.8641975308642 | 00000000-0000-0000-0000-000000000000 |
Корзина реализует алгоритм Apriori для интеллектуального анализа элементов. Он извлекает все сегменты, охват которых набора записей превышает пороговое значение (по умолчанию 5%). Вы можете увидеть, что было извлечено больше сегментов с похожими, такими, как сегменты 0, 1 или 2, 3.
Оба плагина являются мощными и простыми в использовании. Их ограничение заключается в том, что они кластеризуют один набор записей в неконтролируемом режиме без меток. Неясно, характеризуются ли извлеченные шаблоны выбранным набором записей, аномальными записями или глобальным набором записей.
Кластеризация разницы между двумя наборами записей
Плагин diffpatterns() преодолевает ограничения autocluster и basket.
Diffpatterns принимает два набора записей и извлекает основные сегменты, которые отличаются. Один набор обычно содержит аномальный набор записей, который изучается. Анализ проводится с помощью autocluster и basket. Другой набор содержит набор ссылочных записей, базовый план.
В следующем запросе diffpatterns находятся интересные кластеры в течение двух минут всплеска, которые отличаются от кластеров в базовом уровне. Базовое окно определяется как восемь минут до 15:00, когда начался всплеск. Вы расширяете двоичный столбец (AB) и указываете, принадлежит ли определенная запись к эталонному или аномальному набору.
Diffpatterns реализует защищенный алгоритм обучения, в котором два метки класса были созданы аномальным флагом и базовым флагом (AB).
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
let min_baseline_t=datetime(2016-08-23 14:50);
let max_baseline_t=datetime(2016-08-23 14:58); // Leave a gap between the baseline and the spike to avoid the transition zone.
let splitime=(max_baseline_t+min_peak_t)/2.0;
demo_clustering1
| where (PreciseTimeStamp between(min_baseline_t..max_baseline_t)) or
(PreciseTimeStamp between(min_peak_t..max_peak_t))
| extend AB=iff(PreciseTimeStamp > splitime, 'Anomaly', 'Baseline')
| evaluate diffpatterns(AB, 'Anomaly', 'Baseline')
| Идентификатор сегмента | СчетА | CountB | Процент | ПроцентБ | РазницаПроцентовAB | Регион | ScaleUnit | Идентификатор развертывания | Точка трассировки |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 639 | двадцать один | 65.74 | 1,7 | 64.04 | вода | su7 | b5d1d4df547d4a04ac15885617edba57 | |
| 1 | 167 | 544 | 17.18 | 44.16 | 26.97 | скус | |||
| 2 | 92 | 356 | 9.47 | 28,9 | 19.43 | 10007007 | |||
| 3 | девяносто | 336 | 9.26 | 27.27 | 18.01 | 10007006 | |||
| 4 | 82 | 318 | 8.44 | 25,81 | 17.38 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 5 | 55 | 252 | 5.66 | 20.45 | 14.8 | weu | su4 | be1d6d7ac9574cbc9a2cb8ee20f16fc | |
| 6 | 57 | 204 | 5.86 | 16.56 | 10.69 |
Наиболее доминирующим сегментом является тот же сегмент, который был извлечен autocluster. Его охват на двухминутном аномальном окне также составляет 65,74%. Однако его охват в восьмиминутном базовом окне составляет всего 1,7%. Разница составляет 64,04%. Эта разница, кажется, связана с аномальным пиком. Чтобы проверить это предположение, следующий запрос разбивает исходную диаграмму на записи, принадлежащие этому проблемном сегменту, и записи из других сегментов.
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| extend seg = iff(Region == "eau" and ScaleUnit == "su7" and DeploymentId == "b5d1d4df547d4a04ac15885617edba57"
and ServiceHost == "e7f60c5d-4944-42b3-922a-92e98a8e7dec", "Problem", "Normal")
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m by seg
| render timechart
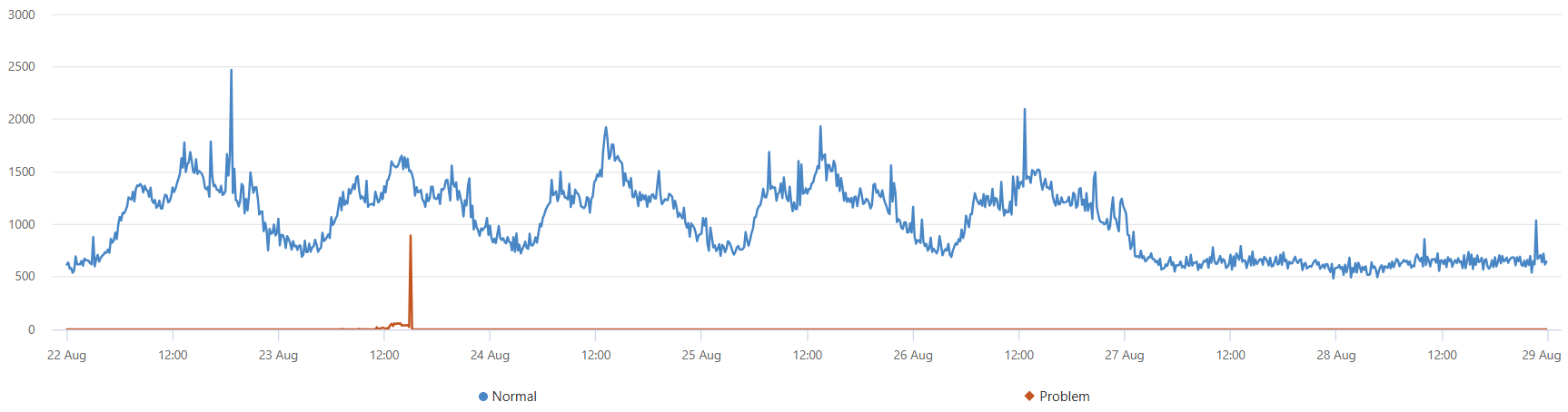
Эта диаграмма позволяет увидеть, что всплеск во вторник днем был из-за ошибок в этом конкретном сегменте, обнаруженных с помощью плагина diffpatterns.
Сводка
Подключаемые модули машинного обучения полезны для многих сценариев. Оба autocluster и basket реализуют безнадзорный алгоритм обучения и легки в использовании.
Diffpatterns реализует защищенный алгоритм обучения и, хотя и более сложный, он более мощный для извлечения сегментов дифференцировки для RCA.
Эти подключаемые модули используются интерактивно в нерегламентированных сценариях и в автоматических службах мониторинга практически в режиме реального времени. За обнаружением аномалий временных рядов следует процесс диагностики. Этот процесс оптимизирован для удовлетворения необходимых стандартов производительности.