Обновление реплик группы доступности
Применимо к:![]() SQL Server
SQL Server
При обновлении экземпляра SQL Server, на котором размещена группа доступности Always On до новой версии SQL Server, до нового пакета обновления SQL Server или накопительного обновления, а также при установке в новый пакет обновления Windows или накопительное обновление, можно сократить время простоя основного реплика до одного перехода на другой ресурс вручную путем последовательного обновления (или двух ручных переходов на другой ресурс, если выполняется отработка отказа на исходный основной ресурс).
В процессе обновления дополнительный реплика будет недоступен для отработки отказа или операций только для чтения, а после обновления дополнительному реплика может потребоваться некоторое время, чтобы догнать основной реплика узел в зависимости от объема действий на основном реплика узле (поэтому ожидайте большой сетевой трафик).
Кроме того, имейте в виду, что после начальной отработки отказа на дополнительный реплика, использующий более новую версию SQL Server, базы данных в этой группе доступности будут выполнять процесс обновления, чтобы перевести их на последнюю версию. При этом для таких баз данных не будут доступны реплики для чтения. Время простоя после первоначальной отработки отказа будет зависеть от количества баз данных в группе доступности. Если вы планируете вернуться к исходному основному ресурсу, этот шаг не будет повторяться при восстановлении размещения.
Примечание
В этой статье мы ограничимся обсуждением обновления только SQL Server. Здесь не рассматривается обновление операционной системы с отказоустойчивым кластером Windows Server (WSFC). Обновление операционной системы Windows, на которой размещен отказоустойчивый кластер, не поддерживается для операционных систем ниже Windows Server 2012 R2. Обновление узла кластера под управлением Windows Server 2012 R2 описано в статье Cluster Operating System Rolling Upgrade (Последовательное обновление операционной системы в кластере).
Предварительные требования
Перед установкой ознакомьтесь со следующими важными сведениями.
Поддерживаемые версии и обновления выпусков. Убедитесь, что вы можете обновить SQL Server до последней версии операционной системы Windows и версии SQL Server. Например, при обновлении непосредственно с экземпляра SQL Server 2005 уровень совместимости базы данных будет обновлен.
Выберите метод обновления ядра СУБД. Чтобы выполнить обновление в правильном порядке, выберите соответствующий метод обновления и шаги на основе проверки поддерживаемых обновлений версий и выпусков, а также на основе других компонентов, установленных в вашей среде.
Составление и тестирование плана обновления ядра СУБД. Просмотрите заметки о выпуске и известные проблемы, связанные с обновлением, изучите контрольный список предварительных требований, а затем разработайте и протестируйте план обновления.
Требования к оборудованию и программному обеспечению для установки SQL Server. Изучите требования к программному обеспечению для установки SQL Server. Если требуется дополнительное программное обеспечение, установите его на каждом узле перед запуском обновления, чтобы минимизировать время простоя.
Проверьте, используется ли отслеживание измененных данных или репликация для баз данных в группах доступности. Если для баз данных включено отслеживание измененных данных (CDC), выполните эти инструкции.
Примечание
Использование различных версий экземпляров SQL Server в одной и той же группе доступности не поддерживается вне последовательного обновления; такое состояние не должно возникать на длительное время, так как обновление должно осуществляться быстро. Другой вариант обновления SQL Server 2016 (13.x) и более поздних версий — использование распределенной группы доступности.
Основы последовательного обновления для групп доступности
При модернизации или обновлении сервера, следует руководствоваться следующими рекомендациями, чтобы минимизировать время простоя и потерю данных для групп доступности.
Перед началом последовательного обновления:
Выполните тестовый переход на другой ресурс вручную по крайней мере для одного из экземпляров реплик синхронной фиксации.
Защитите данные, выполнив полное резервное копирование базы данных на каждой базе данных доступности.
Запуск
DBCC CHECKDBв каждой базе данных доступности
Всегда сначала обновляйте удаленные экземпляры вторичных реплик, затем локальные экземпляры вторичных реплик, и только в последнюю очередь — экземпляр первичной реплики.
Резервные копии не могут выполняться в базе данных, которая находится в процессе обновления. Перед обновлением вторичных реплик настройте автоматическое резервное копирование так, чтобы оно создавало резервные копии только первичной реплики. При обновлении до новой версии реплики недоступны для чтения или резервного копирования. При обновлении в рамках одной версии перед запуском обновления первичной реплики можно настроить автоматическое резервное копирование на вторичных репликах.
Во время обновления версии вторичные файлы, доступные для чтения, невозможно прочитать после обновления читаемой вторичной базы данных и до отработки отказа основного реплика на обновленную вторичную базу данных или обновления основного реплика.
Чтобы предотвратить для групп доступности непреднамеренный переход на другой ресурс при обновлении, перед началом операции удалите на всех репликах с синхронной фиксацией конфигурацию перехода на другой ресурс для групп доступности.
Не обновляйте основной экземпляр реплика перед отработкой отказа группы доступности до обновленного экземпляра с сначала дополнительным реплика. В противном случае время простоя клиентских приложений, запущенных на обновляемом экземпляре первичной реплики, может увеличиться.
Обязательно выполняйте для группы доступности переход на другой ресурс (экземпляр вторичной реплики с синхронной фиксацией). Использование режима асинхронной фиксации связано с риском потери данных в базах данных и приведет к автоматической приостановке перемещения данных (возобновление выполняется вручную).
Не обновляйте основной экземпляр реплика перед обновлением или обновлением любого другого дополнительного экземпляра реплика. Обновленный основной реплика больше не может отправлять журналы в дополнительные реплика, SQL Server экземпляр которого еще не был обновлен до той же версии. Если перемещение данных к вторичной реплике приостанавливается, то для этой реплики не может осуществляться автоматический переход на другой ресурс, а базы данных доступности становятся подверженными потере данных. Это также относится к последовательному обновлению, когда вы выполняете переход со старой первичной реплики на новую вручную. Таким образом, после обновления старой первичной реплики может потребоваться возобновить синхронизацию.
Перед отработки отказа группы доступности убедитесь, что для целевого объекта отработки отказа задано
SYNCHRONIZEDсостояние синхронизации .Предупреждение
Установка нового экземпляра или новой версии SQL Server на сервер, на котором установлена более ранняя версия SQL Server, может случайно вызвать сбой для любой группы доступности, размещенной в более старой версии SQL Server. Это связано с тем, что во время установки экземпляра или новой версии SQL Server выполняется обновление модуля высокой доступности (RHS.EXE) для SQL Server. В результате временно прерывается работа существующих групп доступности в первичной роли на сервере. Таким образом, при установке новой версии SQL Server в системе, где уже размещена более старая версия SQL Server с группой доступности, настоятельно рекомендуется выполнить одно из следующих действий:
установить новую версию SQL Server во время периода обслуживания;
Отработка отказа группы доступности на дополнительный реплика поэтому она не является основной во время установки нового экземпляра SQL Server.
Последовательный процесс обновления
На практике способ организации процесса зависит от многих факторов, в том числе топологии развертывания групп доступности и режима фиксации каждой реплики. Но даже в рамках простейшего сценария последовательное обновление — это процесс с несколькими этапами:

- Удаление конфигурации автоматического перехода на другой ресурс на всех репликах с синхронной фиксацией
- Обновление всех экземпляров вторичной реплики с асинхронной фиксацией.
- Обновление всех удаленных экземпляров вторичной реплики с синхронной фиксацией.
- Обновление всех локальных экземпляров вторичной реплики с синхронной фиксацией.
- Выполнение для группы доступности перехода на другой ресурс (обновленную локальную вторичную реплику с синхронной фиксацией) вручную.
- Обновление локального экземпляра реплики, на котором ранее размещалась первичная реплика.
- Настройка участников автоматического перехода на другой ресурс желаемым образом.
В случае необходимости можно выполнить дополнительный переход на другой ресурс вручную, чтобы возвратить группу доступности к ее исходной конфигурации.
Примечание
При обновлении реплики с синхронной фиксацией и переводе ее в автономный режим транзакции в первичной реплике не откладываются. После отключения вторичной реплики транзакции фиксируются в первичной реплике без ожидания записи журнала во вторичной реплике.
Если REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT для параметра задано значение 1 или 2, основной реплика может быть недоступен для операций чтения и записи, если в процессе обновления недоступно соответствующее количество вторичных реплик синхронизации.
Примечание
При выполнении обновления на месте вторичного реплика до более новой версии SQL Server база данных в группе доступности остается в состоянии Synchronizing / In recovery or Synchronized / In Recovery ( Синхронизированный / In Recovery) до тех пор, пока группа доступности не выполнит отработку отказа вручную, что завершит восстановление и обновление базы данных. Обновленный основной реплика больше не может отправлять журналы в более раннюю версию вторичных реплика и останавливается перемещение данных, а для этого реплика не может происходить автоматическая отработка отказа, а базы данных доступности уязвимы к потере данных. После обновления старого основного сервера может потребоваться возобновить синхронизацию. Рекомендуется обновить все вторичные реплики перед отработкой отказа на реплика с новой версией. Таким образом, вы можете выполнить отработку отказа после обновления баз данных до нового формата.
Группа доступности с одним удаленным вторичным реплика
Если группа доступности развернута только для аварийного восстановления, то может потребоваться возобновить работу группы доступности для вторичной реплики с асинхронной фиксацией. Такая конфигурация показана на следующем рисунке.

В этом сценарии при последовательном обновлении следует выполнить для группы доступности переход на другой ресурс (вторичную реплику с асинхронной фиксацией). Чтобы предотвратить потерю данных, измените режим фиксации на синхронную и дождитесь синхронизации дополнительного реплика перед отработки отказа группы доступности. Следовательно, процесс последовательного обновления может выглядеть так:
- Обновление экземпляра вторичной реплики на удаленном сайте.
- Изменение режима фиксации на синхронную фиксацию
- Дождитесь, пока состояние синхронизации не будет задано.
SYNCHRONIZED - Выполнение для группы доступности перехода на другой ресурс (удаленную реплику на вторичном сайте).
- Обновление локального (на первичном сайте) экземпляра реплики.
- Выполнение для группы доступности обратного перехода на другой ресурс (первичный сайт).
- Изменение режима фиксации на асинхронную фиксацию
Так как режим синхронной фиксации не является рекомендуемым параметром для синхронизации данных с удаленным сайтом, клиентские приложения могут заметить немедленное увеличение задержки базы данных после изменения параметра. Кроме того, выполнение перехода на другой ресурс приводит к тому, что все неподтвержденные сообщения журнала будут отброшены. Количество отброшенных сообщений журнала может быть значительным из-за высокой задержки сети между этими двумя сайтами, а это приведет к тому, что клиенты столкнутся с увеличением количества сбоев транзакций. Вы можете свести к минимуму влияние на клиентские приложения, выполнив следующие действия.
Тщательный выбор перерыва на профилактическое техобслуживание в период снижения клиентского трафика
При обновлении SQL Server на первичном сайте снова включите режим асинхронной фиксации. Когда вы будете готовы снова выполнить переход на другой ресурс (первичный сайт), вернитесь к синхронной фиксации.
Группа доступности с узлами экземпляров отказоустойчивого кластера
Если группа доступности содержит узлы экземпляра отказоустойчивого кластера (FCI), сначала нужно обновлять неактивные узлы, а затем — активные. На приведенном ниже рисунке показан обычный сценарий для групп доступности с использованием экземпляров FCI для достижения локального высокого уровня доступности и асинхронной фиксации между экземплярами FCI для удаленного аварийного восстановления, а также последовательность обновления.
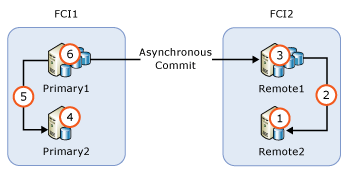
- Обновление или обновление
REMOTE2 - Отработка отказа FCI2 на
REMOTE2 - Обновление или обновление
REMOTE1 - Обновление или обновление
PRIMARY2 - Отработка отказа FCI1 на
PRIMARY2 - Обновление или обновление
PRIMARY1
Обновление или обновление экземпляров SQL Server с помощью нескольких групп доступности
Если вы используете несколько групп доступности с первичными репликами на разных узлах (режим "активный — активный"), процесс обновления будет включать больше циклов перехода на другие ресурсы. Это позволит сохранить высокий уровень доступности на протяжении всей операции. Предположим, что эксплуатируются три группы доступности на трех узлах сервера, а все реплики работают в режиме синхронной фиксации, как показано в следующей таблице.
| ГД | Узел1 | Узел2 | Node3 |
|---|---|---|---|
| ГД1 | Первичная | ||
| ГД2 | Первичная | ||
| ГД3 | Первичная |
Иногда уместно будет выполнить последовательное обновление с балансировкой нагрузки. Операция будет включать следующие шаги:
- Отработка отказа AG2 в
Node3(для освобожденияNode2) - Обновление или обновление
Node2 - Отработка отказа AG1 в
Node2(для освобожденияNode1) - Обновление или обновление
Node1 - Отработка отказа ag2 и AG3 в
Node1(для освобожденияNode3) - Обновление или обновление
Node3 - Отработка отказа ag3 на
Node3
Такая последовательность обновления обеспечит более короткое среднее время простоя, чем при двух переходах на другой ресурс для каждой группы доступности. Результирующая конфигурация показана в приведенной ниже таблице.
| ГД | Узел1 | Узел2 | Node3 |
|---|---|---|---|
| ГД1 | Первичная | ||
| ГД2 | Первичная | ||
| ГД3 | Первичная |
Фактический процесс обновления (как и время простоя клиентских приложений) может отличаться в зависимости от особенностей реализации вашей системы.
Примечание
Во многих случаях после завершения последовательного обновления будет выполнен переход на другой ресурс (исходную первичную реплику).
Последовательное обновление распределенной группы доступности
Чтобы выполнить последовательное обновление распределенной группы доступности, сначала обновите все вторичные реплики. Далее проведите отработку отказа сервера пересылки и обновите оставшийся экземпляр второй группы доступности. После обновления всех вторичных реплик проведите отработку отказа глобальной первичной реплики и обновите последний экземпляр первой группы доступности. Ниже приводится подробная схема с пошаговыми инструкциями.
Фактический процесс обновления (как и время простоя клиентских приложений) может отличаться в зависимости от особенностей реализации вашей системы.
Примечание
Во многих случаях после завершения последовательного обновления будет выполнен переход на другой ресурс (исходную первичную реплику).
Общие шаги для обновления распределенной группы доступности
- Создайте резервную копию всех баз данных, включая системные базы данных, а также базы данных, участвующие в группе доступности.
- Обновите и перезапустите все вторичные реплики второй группы доступности (подчиненные).
- Обновите и перезапустите все вторичные реплики первой группы доступности (вышестоящие).
- Проведите отработку отказа первичной реплики сервера пересылки в обновленную вторичную реплику второй группы доступности.
- Дождитесь синхронизации данных. Базы данных должны отображаться как синхронизированные во всех репликах с синхронной фиксаций, и глобальная первичная реплика должна быть синхронизирована с сервером пересылки.
- Обновите и перезапустите последний экземпляр второй группы доступности.
- Проведите отработку отказа глобальной первичной реплики в обновленную вторичную реплику первой группы доступности.
- Обновите последний экземпляр первой группы доступности.
- Перезапустите обновленный сервер.
- (Необязательно) Восстановите в обеих группах доступности исходные первичные реплики.
Важно!
Между всеми шагами проверяйте, что синхронизация выполнена. Прежде чем перейти к следующему шагу, убедитесь, что реплики с синхронной фиксацией синхронизированы в группе доступности, а глобальная первичная реплика синхронизирована с сервером пересылки в распределенной группе доступности.
Рекомендация. При каждой проверке синхронизации рекомендуется обновлять узел базы данных и узел распределенной группы доступности в SQL Server Management Studio. Когда все будет синхронизировано, создайте снимок экрана состояний каждой реплики. С его помощью вы сможете отслеживать, на каком шаге находитесь; перед переходом к следующему шагу он послужит подтверждением того, что все работает правильно, а при возникновении проблем поможет в устранении неполадок.
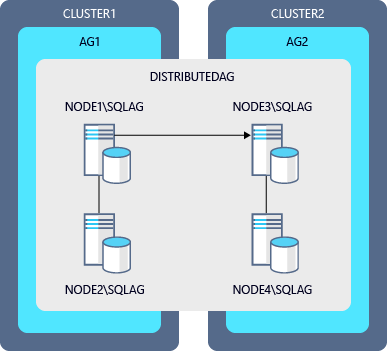
Пример схемы последовательного обновления распределенной группы доступности
| группа доступности | Первичная реплика | Вторичная реплика |
|---|---|---|
| ГД1 | NODE1\SQLAG |
NODE2\SQLAG |
| ГД2 | NODE3\SQLAG |
NODE4\SQLAG |
| DistributedAG | Группа доступности 1 (глобальная) | Группа доступности 2 (сервер пересылки) |
Инструкции по обновлению экземпляров по этой схеме
- Создайте резервную копию всех баз данных, включая системные базы данных, а также базы данных, участвующие в группе доступности.
- Обновите
NODE4\SQLAG(вторичную группу доступности 2) и перезапустите сервер. - Обновите
NODE2\SQLAG(вторичную группу доступности 1) и перезапустите сервер. - Отработка отказа AG2 с
NODE3\SQLAGнаNODE4\SQLAG. - Обновите
NODE3\SQLAGи перезапустите сервер. - Отработка отказа AG1 с
NODE1\SQLAGнаNODE2\SQLAG. - Обновите
NODE1\SQLAGи перезапустите сервер. - (Необязательно) Восстановите исходные первичные реплики.
- Отработка отказа AG2 с
NODE4\SQLAGобратной стороны наNODE3\SQLAG. - Отработка отказа AG1 со
NODE2\SQLAGспины наNODE1\SQLAG.
- Отработка отказа AG2 с
Если в каждой группе доступности существовал третий реплика, он был бы обновлен до NODE3\SQLAG и NODE1\SQLAG.
Важно!
Между всеми шагами проверяйте, что синхронизация выполнена. Прежде чем перейти к следующему шагу, убедитесь, что реплики с синхронной фиксацией синхронизированы в группе доступности, а глобальная первичная реплика синхронизирована с сервером пересылки в распределенной группе доступности.
Рекомендации: При каждой проверке синхронизации обновляйте узел базы данных и узел распределенной группы доступности в SQL Server Management Studio. Когда все будет синхронизировано, создайте снимок экрана состояний каждой реплики. С его помощью вы сможете отслеживать, на каком шаге находитесь; перед переходом к следующему шагу он послужит подтверждением того, что все работает правильно, а при возникновении проблем поможет в устранении неполадок.
Особые действия для записи измененных данных или репликации
В зависимости от применяемого обновления для баз данных реплики группы доступности, включенных для записи измененных данных или репликации, могут потребоваться дополнительные действия. См. заметки о выпуске для обновления, чтобы определить необходимость выполнения приведенных далее шагов.
Обновление каждой вторичной реплики.
Перенос группы доступности на обновленный экземпляр после обновления всех вторичных реплик.
Выполнение следующего запроса Transact-SQL на экземпляре, где размещена первичная реплика.
EXECUTE [master].[sys].[sp_vupgrade_replication];Примечание
Выполнение этой команды может занять несколько минут. Пропустите этот шаг, если вы используете SQL Server 2019 CU1 или более поздней версии. Дополнительные сведения см. в статье KB4530283.
Обновление экземпляра, который изначально был первичной репликой.
Дополнительные сведения см. в статье CDC functionality may break after upgrading to the latest (Возможное нарушение функциональности записи измененных данных после обновления до последнего накопительного обновления).
См. также раздел
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по