Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В Service Manager данные, присутствующих в хранилище данных, можно объединить из различных источников. Он представлен в Service Manager с использованием предопределенных и настраиваемых кубов данных Microsoft Online Analytical Processing (OLAP). Короче говоря, расширенная аналитика в Service Manager состоит из публикации, просмотра и управления данными куба, как правило, в Microsoft Excel или Microsoft SharePoint. Excel в основном используется для просмотра и манипулирования данными. SharePoint в основном используется как средство публикации данных куба и открытия общего доступа к ним.
Service Manager включает в себя хранилище данных на уровне System Center. Таким образом, данные из Operations Manager, Configuration Manager и Service Manager можно объединить в хранилище данных, где можно легко использовать несколько представлений данных для получения любой нужной информации. Кроме того, предусмотрен интерфейс, позволяющий поместить в хранилище данные из собственных пользовательских источников, таких как приложения SAP или приложения отдела кадров от сторонних разработчиков. Подобная консолидация создает общую модель данных и дает возможность выполнять обогащенный анализ, что позволяет вашему ИТ-отделу построить хранилище данных, способное обеспечить все его нужды в сфере производства отчетов и бизнес-аналитики.
Помещение данных в общую модель позволяет манипулировать информацией и создавать общие определения и таксономию для всего предприятия. Это достигается путем развертывания кубов OLAP и просмотра имеющейся в них информации с помощью стандартных средств, таких как Excel и SharePoint. Такой подход позволяет пользователям использовать уже имеющиеся у них навыки. Вы контролируете определение своей бизнес-логики в централизованном режиме. К примеру, вы можете определить ключевые показатели эффективности, такие как пороги допустимого времени устранения инцидента и указать, какие значения будут расцениваться как "зеленый", "желтый" и "красный" пороги. Вы можете управлять этими выборами централизованно и при этом позволять пользователям с легкостью использовать данные, чтобы единое определение отображалось в их отчетах Excel и панелях мониторинга SharePoint.
Сведения о кубах OLAP Service Manager
OLAP-кубы — это функция в Service Manager, которая использует существующую инфраструктуру хранилища данных для предоставления возможностей самостоятельного проведения бизнес-анализа конечным пользователям.
Куб OLAP представляет собой структуру данных, которая обеспечивает возможность быстрого анализа данных за рамками ограничений реляционных баз данных. Кубы способны отображать и суммировать большие объёмы данных, также предоставляя пользователям доступ к любым точкам данных с возможностью поиска. Таким образом, данные можно свернуть, срезать и выделить по мере необходимости, чтобы обрабатывать самые разнообразные вопросы, относящиеся к области интересов пользователя.
Поставщики программного обеспечения или ИТ-разработчики с рабочим знанием кубов OLAP могут создавать пакеты управления для определения собственных расширяемых и настраиваемых кубов OLAP, созданных на основе инфраструктуры хранилища данных. Такие кубы хранятся в службах SQL Server Analysis Services (SSAS). Средства самостоятельной бизнес-аналитики, такие как Excel и SQL Server Reporting Services (SSRS), могут работать с этими кубами в SSAS и использовать их для анализа данных с разных точек зрения.
Базы данных, в которых компании хранят свои транзакции и записи, называются базами данных оперативной обработки транзакций (OLTP). Как правило, записи в эти базы данных вносятся поочередно и содержат большой объем информации, которая может быть использована стратегами для принятия обоснованных решений в сфере бизнеса. Однако базы данных, используемые для хранения данных, не предназначены для анализа. Поэтому извлечение ответов из этих баз данных требует много времени и усилий. Базы данных OLAP специально предназначены для упрощения извлечения необходимых сведений бизнес-аналитики из данных.
Кубы OLAP — это звено, завершающее облик решения по созданию и обслуживанию хранилищ данных. Куб OLAP, также известный как многомерный куб или "гиперкуб", представляет из себя структуру данных в составе служб SQL Server Analysis Services (SSAS), которая создается на основе баз данных OLAP и позволяет выполнять почти моментальный анализ данных. Топология данной системы показана на иллюстрации ниже.
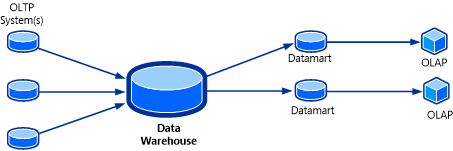
Полезной функцией куба OLAP является то, что данные в кубе могут содержаться в статистическом ("агрегатном") виде. Для пользователя это выглядит так, словно в кубе уже заранее есть все необходимые ответы, поскольку куб содержит множество предварительно вычисленных значений. Не отправляя запрос в исходную базу данных OLAP, куб может почти мгновенно возвращать ответы на широкий спектр вопросов.
Основной целью кубов OLAP Service Manager является предоставление поставщикам программного обеспечения или ит-разработчикам возможности выполнять практически мгновенный анализ данных как для исторического анализа, так и для целей тенденций. Service Manager делает это следующим образом:
- Возможность встраивать определения кубов OLAP в пакеты управления. Такие кубы автоматически создаются в службах SSAS при развертывании пакета управления.
- Автоматическое обслуживание куба без вмешательства пользователей, включая ряд задач, в том числе выполнение обработки, секционирования, перевода и локализации, а также изменения схемы.
- Предоставление пользователям средств самостоятельной бизнес-аналитики, таких как Excel, для анализа данных с различных перспектив.
- Сохранение созданных отчетов Excel для дальнейшего использования.
Чтобы узнать, как кубы хранилища данных представлены в консоли Service Manager, перейдите в рабочую область хранилища данных и выберите куби.
Кубы OLAP Менеджера сервиса
На рисунке ниже показано изображение из среды SQL Server Business Intelligence Development Studio (BIDS), на котором представлены основные части, необходимые для создания и работы кубов OLAP. Эти части — источник данных, представление источника данных, кубы и измерения. В приведенных ниже разделах описываются части куба OLAP и действия, которые могут выполнять пользователи с их помощью.
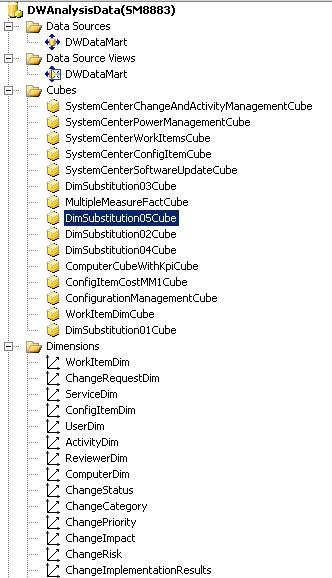
Источник данных
Источник данных является источником всех данных, содержащихся в кубе OLAP. Куб OLAP подключается к источнику данных для считывания и обработки исходных данных, выполняя агрегирование и вычисление связанных мер. Источник данных для всех кубов OLAP в Service Manager — это витрины данных, которые включают витрины данных как для Operations Manager, так и для Configuration Manager. Чтобы установить правильный уровень разрешений, сведения аутентификации для источника данных должны быть сохранены в службах SQL Server Analysis Services (SSAS).
Представление источника данных
Представление источника данных (DSV) — это коллекция видов, представляющих таблицы измерений, фактов и вспомогательных таблиц из источника данных, таких как витрины данных Service Manager. DSV отображает все отношения между таблицами, в том числе первичные и внешние ключи. Другими словами, DSV показывает, как база данных SSAS будет сопоставлена с реляционной схемой, и предоставляет слой абстрагирования поверх реляционной базы данных. Данный слой абстрагирования позволяет определять отношения между таблицами фактов и измерений даже при отсутствии отношений в исходной реляционной базе данных. В DSV можно определять именованные вычисления, пользовательские меры и новые атрибуты, которые изначально могут отсутствовать в схеме измерений хранилища данных. Например, именованное вычисление, которое определяет логическое значение для устраненных инцидентов, вычисляет значение как истинное, если статус инцидента является устраненным или закрытым. С помощью именованного вычисления Service Manager может определить меру для отображения полезных сведений, таких как процент разрешенных инцидентов, общее число разрешенных инцидентов и общее количество инцидентов, которые не разрешены.
Еще один краткий пример именованного вычисления — ReleasesImplementedOnSchedule. Это именованное вычисление быстро проверяет состояние процесса, подсчитывая количество записей о релизах, в которых фактическая дата окончания не превышает запланированную.
Кубы OLAP
Куб OLAP представляет собой структуру данных, которая обеспечивает возможность быстрого анализа данных, выходя за рамки ограничений реляционных баз данных. Кубы OLAP могут отображать и суммировать большие объемы данных, а также предоставлять пользователям доступ к любым точкам данных, чтобы данные можно было свернуть, срезать и выделить по мере необходимости для обработки самых разнообразных вопросов, которые относятся к интересующей области пользователя.
Измерения
Измерение в SSAS ссылается на измерение из хранилища данных Service Manager. В Service Manager измерение примерно эквивалентно классу пакета управления. Каждый класс пакета управления имеет набор свойств, а каждое измерение — набор атрибутов, при этом каждый атрибут сопоставляется с одним свойством класса. Измерения позволяют выполнять фильтрацию, группирование и маркировку данных. К примеру, можно отфильтровать компьютеры по установленной операционной системе или сгруппировать людей по категориям, используя пол или возраст. Затем данные можно представить в формате, в котором данные классифицируются естественно в этих иерархиях и категориях, чтобы обеспечить более подробный анализ. Измерения также могут иметь естественные иерархии, чтобы пользователи могли подробнее исследовать данные до более детализированных уровней. К примеру, измерение даты обладает иерархией, позволяющей выполнять детализацию до уровня лет, затем — до уровней кварталов, месяцев, недель и отдельных дней.
В следующем рисунке показан куб OLAP, содержащий измерения даты, региона и продукта.
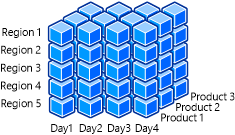
Например, участникам команды Майкрософт может потребоваться быстрая и простая сводка о продажах игровой консоли Xbox One в применимой версии. Они могут детализировать данную сводку для получения сведений о продажах за более узкий интервал времени. Бизнес-аналитики могут изучить, как продажи консоли Xbox One повлияли на запуск нового дизайна консоли и Kinect для Xbox One. Такая информация позволяет им выявить происходящие в сфере продаж тренды и разработать потенциальную корректировку бизнес-стратегии компании. Фильтрация с использованием измерения даты позволяет быстро доставлять и использовать эту информацию. Описанное создание объемных и плоскостных срезов данных возможно благодаря наличию в измерениях атрибутов и данных, позволяющих клиенту с легкостью выполнять их фильтрацию и группирование.
В Service Manager все куби OLAP используют общий набор измерений. Все измерения используют в качестве источника основную витрину данных склада данных, даже в сценариях с несколькими витринами данных. В сценариях с несколькими хранилищами данных это может привести к ошибкам ключей измерений в ходе обработки куба.
Группа мер
Концепция группы мер совпадает с термином "факт" в контексте хранилища данных. Подобно тому, как факты содержат числовые меры в хранилище данных, группа мер содержит меры для куба OLAP. Все меры в кубе OLAP, происходящие от одной таблицы фактов в представлении источника данных, также могут считаться группой мер. Тем не менее, бывают случаи, когда меры в кубе OLAP могут извлекаться из нескольких таблиц фактов. Меры одинакового уровня детализации объединяются в одну группу мер. Группы мер определяют, какие данные будут загружены в систему, каким образом они будут загружены, а также как данные будут привязаны к многомерному кубу.
Каждая группа мер также содержит список разделов, в которых находятся сами данные в виде отдельных, неперекрывающихся блоков. Группы мер также содержат проектирование агрегатов, которое определяет предварительно суммированные наборы данных, рассчитываемые для каждой группы мер для улучшения производительности пользовательских запросов.
Меры
Меры — это числовые значения, которые пользователи хотят срезать, уточнять, агрегировать и анализировать; это одна из основных причин, по которой стоит создавать кубы OLAP с использованием инфраструктуры хранения данных. При помощи служб SSAS можно создавать кубы OLAP, использующие бизнес-правила и вычисления для форматирования и отображения мер в настраиваемом формате. Большой объем времени разработки куба OLAP тратится на определение того, какие меры будут отображены, и каким образом они будут вычисляться.
Меры — это значения, обычно сопоставляемые с числовыми столбцами в таблице фактов хранилища данных, но их также можно создать из атрибутов измерения или вырожденного измерения. Эти меры являются самыми важными анализируемыми значениями куба OLAP и представляют основной интерес для пользователей, просматривающих куб OLAP. Пример меры, существующей в хранилище данных — ActivityTotalTimeMeasure. ActivityTotalTimeMeasure — это показатель из данных ActivityStatusDurationFact, обозначающий время нахождения каждой активности в конкретном статусе. Уровень детализации меры состоит из всех охваченных ей измерений. К примеру, уровень детализации связи ComputerHostsOperatingSystem состоит из измерений Компьютера и Операционной Системы.
Функции агрегирования вычисляются по показателям для дальнейшего анализа данных. Наиболее распространенной функцией агрегирования является "Сумма". Один из распространенных запросов к кубу OLAP, к примеру, суммирует продолжительность всех действий, имеющих состояние In Progress. Другие распространенные функции агрегирования — Min, Max и Count.
После завершения обработки необработанных данных в кубе OLAP пользователи могут выполнять более сложные вычисления и запросы, используя многомерные выражения (MDX) для определения собственных выражений мер и их вычисляемых элементов. MDX — это отраслевой стандарт для операций запроса и доступа к данным, сохраненным в системах OLAP. SQL Server не был разработан для работы с моделью данных, которая поддерживает многомерные базы данных.
Углубленный анализ
Когда пользователь углубляется в данные в кубе OLAP, он анализирует данные на другом уровне суммирования. Уровень детальности данных повышается с каждой операцией детализации, что позволяет пользователю изучать данные на разных уровнях иерархии. Когда пользователи углубляются, они переходят от сводной информации к данным с более узкой специализацией. Ниже приведены примеры детализации.
- Углублённый анализ данных для изучения демографической информации о населении Соединенных Штатов, затем о населении штата Вашингтон, далее о городской агломерации Сиэтла, потом о городе Редмонд и, наконец, о сотрудниках компании Майкрософт.
- Углубленный анализ данных о продажах консолей Xbox One за 2015 календарный год, тогда четвертый квартал года, тогда месяц декабря, тогда неделю до Рождества и, наконец, канун Рождества.
Детальный просмотр
Когда пользователи выполняют детализацию данных, они хотят просмотреть все отдельные транзакции, которые способствовали агрегированным данным куба OLAP. Другими словами, пользователь может извлечь данные на самом низком уровне детализации для определенного значения меры. Например, при получении данных о продажах в течение определенного месяца и категории продуктов можно детализировать эти данные, чтобы просмотреть список каждой строки таблицы, содержащейся в этой ячейке данных.
Обычно путаются термины углубление в данные и просмотр сквозь данные друг с другом. Основное различие между ними заключается в том, что детализация работает с предопределенной иерархией данных, например, США, затем в Вашингтон, затем в Сиэтл в кубе OLAP. Детализация "drill-through" позволяет перейти на самый низший уровень детализации и извлечь из источника данных набор строк, сгруппированных в одну ячейку.
Ключевой показатель производительности
Организации могут использовать ключевые показатели эффективности для отслеживания продвижения своего предприятия в сторону заданных целей, таким образом измеряя его работоспособность и производительность. Показатели KPI представляют из себя бизнес-метрики, создаваемые для наблюдения за продвижением в сторону определенных заданных целей. Ключевой показатель эффективности имеет целевое значение и фактическое значение, представляющее количественную цель, которая имеет решающее значение для успеха организации. Ключевые показатели эффективности отображаются группами на шкале оценок, чтобы показать общее состояние компании одним взглядом.
Пример показателя KPI: выполнить все запросы на изменение в течение 48 часов. Показатель KPI можно использовать для определения процентной доли выполненных в течение этого интервала времени запросов на изменение. Для визуального представления показателей KPI предусмотрена возможность создания панелей мониторинга. Например, можно определить целевое значение KPI как "выполнить все запросы на изменение в течение 48 часов на 75 процентов".
Перегородки
Раздел — это структура данных, содержащая частичные или полные данные группы мер. Все группы мер поделены на разделы. Раздел определяет подмножество фактических данных, загруженных в группу показателей. SSAS Standard Edition поддерживает только один раздел на группу мер, а в SSAS Enterprise Edition поддерживается несколько разделов. Секции — это функция, которая является прозрачной для конечного пользователя, но они оказывают значительное влияние как на производительность, так и на масштабируемость кубов OLAP. Все разделы группы мер всегда существуют в одной и той же физической базе данных.
Секции позволяют администратору лучше управлять кубом OLAP и повысить производительность куба OLAP. Например, можно удалить или повторно обработать данные в одной секции группы мер, не затрагивая остальную часть группы мер. При загрузке новых данных в таблицу фактов затрагиваются только секции, которые должны содержать новые данные.
Секционирование также повышает производительность обработки и запросов для кубов OLAP. Службы SSAS могут параллельно обрабатывать несколько секций, в результате чего ресурсы ЦП и памяти на сервере используются гораздо более эффективно. Хотя он выполняет запрос, SSAS извлекает, обрабатывает и агрегирует данные из нескольких секций, а также только секции, содержащие данные, относящиеся к запросу, сканируются, что снижает общий объем входных и выходных данных.
Одним из примеров стратегии секционирования служит размещение данных фактов для каждого месяца в месячной секции. В конце каждого месяца все новые данные переносятся в новую секцию, в результате чего выполняется естественное распределение данных с неперекрывающимися значениями.
Агрегации
Агрегаты в кубе OLAP — это предварительно просуммированные наборы данных. Они аналогичны инструкции SQL SELECT с предложением GROUP BY. Службы SSAS могут использовать эти агрегаты при ответе на запросы, чтобы сократить количество необходимых вычислений и быстро возвращать ответы пользователю. Агрегаты, встроенные в куб OLAP, сокращают количество операций агрегирования, выполняемых службами SSAS во время запроса. Построение правильных агрегатов может существенно улучшить эффективность запросов. Зачастую это процесс, развивающийся в течение времени существования куба OLAP по мере изменения его запросов и использования.
Обычно создается базовый набор агрегатов, которые будут использоваться для большинства запросов к кубу OLAP. Агрегации строятся для каждого раздела куба OLAP в пределах группы мер. Когда создаётся агрегация, определённые атрибуты измерений включаются в уже просуммированный набор данных. При просмотре кубов OLAP пользователи могут быстро запрашивать данные на базе этих агрегатов. К разработке агрегаций следует подходить с особой тщательностью, потому что количество потенциальных агрегаций настолько велико, что их создание заняло бы слишком много времени и места для хранения.
Service Manager использует следующие два варианта для сборки и проектирования агрегаций в OLAP-кубах системы Service Manager.
- Прирост производительности достиг
- Оптимизация с учетом использования
Параметр "Достижение прироста производительности" задается, чтобы определить, какой процент агрегатов создается. Например, если для этого параметра установить используемое по умолчанию рекомендуемое значение в 30 процентов, построение агрегатов будет продолжаться до тех пор, пока предполагаемый рост производительности куба OLAP не составит 30 процентов. Однако это не означает, что будет создано 30 процентов возможных агрегаций.
Оптимизация с учетом использования позволяет службам SSAS вести журнал запросов данных, чтобы при выполнении запроса сведения передавались в процесс разработки агрегатов. Затем службы SSAS проверяют данные и рекомендуют агрегации для построения с целью достижения наилучшего оценочного повышения производительности.
Секционирование кубов программы Service Manager
Все группы мер в кубе поделены на разделы, каждый из которых определяет часть данных факта, загружаемую в группу мер. Службы SQL Server Analysis Services (SSAS) в версии SQL Server Standard позволяют использовать только один раздел для каждой группы мер, а в версии Enterprise разрешено несколько разделов. Разделы полностью прозрачны для пользователя, однако они имеют большое влияние на производительность и масштабируемость. Например, разделы могут быть обработаны по отдельности и параллельно. Они могут иметь различные структуры агрегирования. Вы можете повторно обработать раздел, не затрагивая другие разделы группы мер. Кроме того, система SSAS автоматически сканирует только те разделы, которые содержат необходимые для запроса данные, что позволяет значительно повысить производительность запросов.
Секционирование кубов выполняется при каждом запуске задания по обслуживанию хранилища данных — по умолчанию ежечасно. Выполняемый модуль данного процесса называется ManageCubePartitions. Его выполнение происходит всегда после этапа CreateMartPartitions. Данные зависимостей хранятся в таблице infra.moduletriggercondition.
Основная динамическая библиотека связей (DLL), ответственная за секционирование, находится в служебной библиотеке DLL хранилища, Microsoft.EnterpriseManagement.Warehouse.Utility, в классе PartitionUtil. В частности, в классе есть метод ManagePartitions(), который обрабатывает все обслуживание секций. Используемые для обслуживания и оперативной аналитической обработки хранилища данных библиотеки DLL Microsoft.EnterpriseManagement.Warehouse.Maintenance и Microsoft.EnterpriseManagement.Warehouse.Olap, вызывают библиотеку Microsoft.EnterpriseManagement.Warehouse.Utility для обработки разделов во время обслуживания хранилища и развертывания куба. Таким образом фактическое управление разделами осуществляется в общей служебной библиотеке DLL во избежание дублирования логики и кода.
Функция обслуживания секционирования куба выполняет следующие задачи:
- Создайте разделы
- Удаление разделов
- Обновление границ разделов
При выполнении этих задач осуществляется чтение таблицы SQL etl.TablePartition с целью определить все разделы фактов, созданные для данной группы мер. Происходят следующие действия:
- Запуск обработки куба для каждой группы измерений в кубе
- Получение всех партиций из таблицы etl.TablePartition для группы мер
- Удалите любые разделы, имеющиеся в группе мер, но отсутствующие в таблице etl.TablePartition
- Добавьте любые новые разделы, которые были созданы и существуют только в таблице etl.TablePartition
- Обновление разделов, которые могли измениться, путем сопоставления каждого раздела с параметрами RangeStartDate и RangeEndDate в таблице etl.TablePartition
Помните о следующих нюансах обработки куба:
- Только группы мер, направленные на факты, содержат несколько разделов в стандартной редакции SQL Server. По умолчанию все группы мер и измерения содержат только один раздел. Поэтому раздел не имеет граничных условий.
- Границы раздела определяются с помощью привязки запроса, основанной на ключах дат, совпадающих с ключами дат соответствующего раздела факта в таблице etl.TablePartition.
Развертывание OLAP-куба Service Manager
Развертывание кубов в системе оперативной аналитической обработки (OLAP) использует инфраструктуру развертывания Service Manager для создания кубов OLAP в базе данных SQL Server Analysis Services (SSAS).
Развертываемый элемент возвращает развертывающий объект с коллекцией ресурсов, которые сериализуются и используются для создания куба OLAP в базе данных SSAS. В кубах OLAP развертываемый объект называется CubeDeployable (для элемента SystemCenterCubе) или CubeExtensionDeployable (для элемента CubeExtension). Развертывающим объектом для обоих элементов является CubeDeployer.
Таблица dbo.Selector в базе данных DWStagingAndConfig содержит данные по обоим элементам пакета управления (SystemCenterCube и CubeExtension). Подсистема развертывания использует эти метаданные в том случае, если при импорте пакета управления в хранилище данных с применением задания MPSync требуется дополнительная обработка элемента пакета управления.
В ходе развертывания используется программный интерфейс объектов AMO для создания и модификации всех компонентов куба в базе данных SSAS. В частности, AMO в отключенном режиме используется, так как элемент CubeDeployable не будет подключен к базе данных SSAS. Работа с объектами AMO в разъединенном режиме позволяет создавать полное дерево объектов AMO без подключения к серверу. Затем Service Manager сериализует иерархию объектов в виде потоковых ресурсов и присоединяет их к объекту развертывания, который передается обратно в инфраструктуру развертывания. Затем выполняется десериализация развертывающего объекта, устанавливается подключение к базе данных SSAD и создаются объекты с помощью отправки соответствующих запросов в базу данных.
Возможна сериализация только главных объектов. В контексте объектов AMO главными объектами считаются классы, которые представляют собой завершенный объект в виде завершенной сущности, не являющийся частью другого объекта. Например, основные объекты включают сервер, куб и измерение, которые являются всеми автономными сущностями. Однако DimensionAttribute не является основным объектом, так как он может быть создан только в рамках родительского основного объекта Dimension. DimensionAttribute, таким образом, является дополнительным объектом. Проектировочный этап куба OLAP сфокусирован на создании всех главных объектов, необходимых для кубов, вместе с любыми зависимыми второстепенными объектами. Эти основные объекты — это объекты, которые будут сериализованы и в конечном итоге десериализированы перед созданием объектов в базе данных SSAS.
Для успешного завершения развертывания и удовлетворения зависимостей, предъявляемых элементами куба OLAP, ресурсы, обертывающие главные объекты, должны быть созданы в определенном порядке. В двух представленных ниже списках показана последовательность развертывания элементов SystemCenterCube и CubeExtension, соответственно.
- элементы DataSourceView
- элементы измерения
- компонент измерения даты
- элемент куба
- элементы DataSourceView
- элемент куба
Обработка OLAP-куба Service Manager
При развертывании куба интерактивной аналитической обработки (OLAP) и создании всех его секций он готов к обработке, чтобы он был доступен для просмотра. Обработка куба — финальный шаг перед запуском процессов извлечения, преобразования и загрузки (ETL). Эти действия происходят в следующем порядке:
- Извлечение: извлечение данных из исходной системы.
- Преобразование: применение функций для приведения данных в соответствие со стандартной схемой измерений.
- Загрузка: загрузка данных в киоск данных для потребления.
- Процесс: загрузка данных из киоска данных в куб OLAP для просмотра.
Обработка куба OLAP начинается после того, как выполнено вычисление всех агрегатов куба и куб загружен вместе с этими агрегатами и данными. Выполняется чтение таблиц фактов и измерений, а также вычисление данных и их загрузка в куб. При проектировании куба OLAP следует учитывать потенциально сильное влияние, которое процесс обработки способен оказать на рабочую среду, где могут существовать миллионы записей. Полный процесс всех разделов в такой среде может занять от нескольких дней до нескольких недель, что может сделать инфраструктуру и кубы Service Manager непригодными для конечных пользователей. Одна из рекомендаций заключается в том, чтобы отключить расписание обработки любых кубов, которые не используются, для уменьшения нагрузки на систему.
Обработка куба OLAP состоит из двух отдельных задач:
- Обработка измерений.
- Обработка разделов.
Каждый куб OLAP имеет соответствующее задание обработки в консоли Service Manager и выполняется в настраиваемом пользователем расписании. Каждый вид задачи обработки подробно описан в следующих разделах.
Обработка измерений.
Каждое добавляемое в базу данных SSAS измерение должно подвергнуться полной обработке, чтобы получить состояние "обработано". Однако после обработки измерения нет никаких гарантий, что оно будет обработано снова, когда обрабатывается другой куб, нацеленный на то же измерение. Не выполняя автоматическую обработку измерения, Service Manager предотвращает повторную обработку каждого измерения для каждого куба. Это особенно верно, если измерение недавно обработано, потому что вряд ли существуют новые данные, которые еще не обработаны. Для оптимизации эффективности обработки существует одиночный класс, который определён в пакете управления Microsoft.SystemCenter.Datawarehouse.OLAP.Base и называется Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval. Образец данного класса приведен ниже.
<!-- This singleton class defines the minimum interval of time in minutes that must elapse before a shared dimension is reprocessed. -->
<ClassType ID="Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval" Accessibility="Public" Abstract="false" Base="AdminItem!System.AdminItem" Singleton="true">
<Property ID="IntervalInMinutes" Type="int" Required="true" DefaultValue="60"/>
</ClassType>
Данный Singleton-класс содержит свойство IntervalInMinutes, определяющее частоту обработки измерения. По умолчанию это свойство имеет значение 60 минут. Например, если измерение было обработано в 3:05 вечера и другой куб, предназначенный для того же измерения, обрабатывается в 3:45 вечера, измерение не будет повторно обработано. Недостатком данного подхода является повышение вероятности ошибок в ключах измерения. Механизм повторной попытки обрабатывает ошибки ключей измерения, чтобы выполнить повторную обработку измерения с последующей обработкой раздела куба. Дополнительные сведения о сбоях обработки см. в разделе "Распространенные проблемы с отладкой и устранением неполадок".
После полной обработки измерения выполняется добавочная обработка с помощью операции ProcessUpdate . Операция ProcessFull выполняется лишь в еще одном случае — при изменении схемы измерения, поскольку это действие приводит к возврату измерения в необработанное состояние. Помните, что если ProcessFull выполняется на размерности, все затронутые кубы и их разделы окажутся в необработанном состоянии, и их необходимо будет полностью обработать при следующем запланированном запуске.
Обработка разделов.
Обработка секций должна быть тщательно рассмотрена, так как повторная обработка большого раздела медленна, и она потребляет много ресурсов ЦП на сервере, на котором размещена служба SSAS. Как правило, обработка разделов занимает больше времени, чем обработка измерений. В отличие от обработки измерений, обработка разделов не имеет влияния на другие объекты. Единственными двумя типами обработки, выполняемыми в OLAP-кубах System Center Service Manager, являются ProcessFull и ProcessAdd.
Подобно измерениям, для создания новых разделов в кубе OLAP необходимо выполнить задачу ProcessFull, чтобы раздел находился в состоянии, позволяющем выполнять запросы. Поскольку задача ProcesFull — ресурсоемкая операция, ее следует выполнять только при необходимости, например, при создании раздела или при обновлении строки. В сценариях, в которых были добавлены строки, и никакие строки не были обновлены, Service Manager может выполнять задачу ProcessAdd. Для этого Service Manager использует подложки и другие метаданные. Для этого проводится запрос к таблицам etl.cubepartition и etl.tablepartition для определения типа обработки, которую необходимо выполнить.
На следующей схеме показано, как Service Manager определяет, какой тип обработки выполнять на основе данных водяной метки.
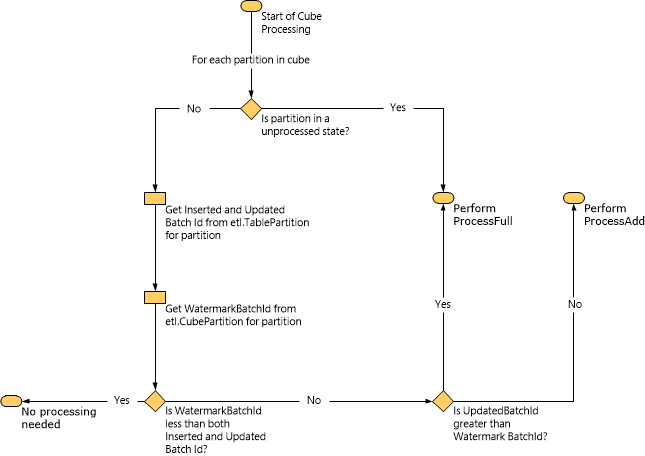
При выполнении задачи ProcessAdd, Service Manager ограничивает область запроса с помощью водяных знаков. Например, если значение InsertedBatchId равно 100, а значение WatermarkBatchId — 50, запрос загружает данные только из той витрины данных, где значение InsertedBatchId больше 50, но меньше 100.
Наконец, важно отметить, что Service Manager не поддерживает ручную обработку кубов OLAP с помощью SSAS или Business Intelligence Development Studio. Обработка кубов за пределами методов, предоставляемых в System Center Service Manager, включая консоль Service Manager и командлеты Service Manager, не обновляет таблицы подложки. Поэтому возможно, что проблемы целостности данных могут возникнуть. Если вы случайно повторно обработали куб вручную, один из возможных обходных способов — аннулировать обработку куба OLAP вручную. Затем в следующий раз, когда Service Manager обработает куб, он автоматически выполнит задачу ProcessFull, так как разделы будут находиться в необработанном состоянии. Это приведет к корректному обновлению всех водяных знаков и метаданных, что позволит устранить все возможные проблемы целостности данных.
Поддержка OLAP-кубов Service Manager
Информация в следующих разделах описывает лучшие практики по обслуживанию кубов OLAP (онлайн аналитическая обработка).
Периодическая повторная обработка измерений службы Analysis Services
Лучшие практики SQL Server Analysis Services (SSAS) рекомендуют регулярно выполнять полную обработку измерений SSAS. При полной обработке измерений происходит перестройка индексов и оптимизация хранения многомерных данных, что повышает производительность запросов (а также производительность куба), которая может снижаться с течением времени. Это процесс подобен регулярной дефрагментации жесткого диска на компьютере.
Негативным последствием полной обработки измерения SSAS является то, что все соответствующие кубы OLAP становятся необработанными и должны тоже быть полностью обработаны для возврата в состояние, позволяющее им отвечать на запросы. Менеджер служб явно не полностью обрабатывает измерения SSAS. Время выполнения этой задачи обслуживания необходимо выбрать самостоятельно.
Соображения по памяти
Если все операции хранилища данных по извлечению, преобразованию и загрузке (ETL), а также функции куба OLAP выполняются на одном сервере, будьте внимательны при подсчете памяти, необходимой для работы операционной системы, хранилища данных и служб SSAS. Убедитесь, что сервер способен обеспечить одновременное выполнение множества операций обработки данных. Этот момент особенно важен, поскольку операция обработки кубов OLAP требовательна к памяти.
Следующие шаги
- Моделировать кубы OLAP в пакетах управления.