Варианты PaaS для развертывания SQL Server в Azure
Платформа как услуга (PaaS) предоставляет полноценную среду разработки и развертывания в облаке, которую можно использовать для простых облачных приложений и для более сложных корпоративных приложений.
База данных SQL Azure и Управляемый экземпляр SQL Azure являются частью предложения PaaS для SQL Azure.
База данных SQL Azure — часть семейства продуктов, созданных на основе подсистемы SQL Server в облаке. Она предоставляет разработчикам гибкие возможности для создания новых служб приложений и детальные варианты развертывания в большом масштабе. База данных SQL предлагает решение, почти не требующее обслуживания, которое может стать отличным вариантом для определенных рабочих нагрузок.
Управляемый экземпляр SQL Azure— лучше всего подходит для большинства сценариев миграции в облако, так как он предоставляет полностью управляемые службы и возможности.
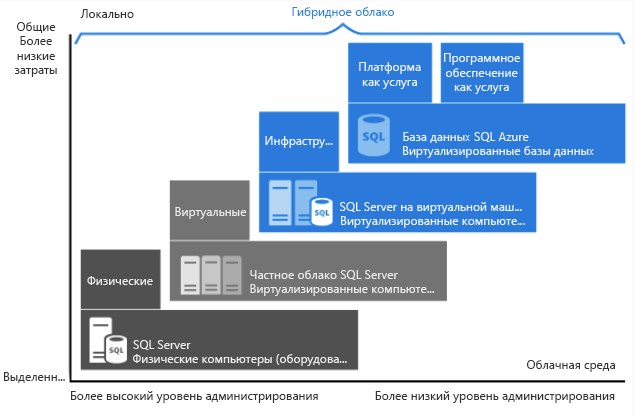
Как видно на изображении выше, каждое предложение обеспечивает определенный уровень администрирования вашей инфраструктуры согласно степени экономической эффективности.
Модели развертывания
База данных SQL Azure доступна в двух различных моделях развертывания.
Отдельная база данных — отдельная база данных, которая оплачивается и управляется на уровне баз данных. Управление каждой базой данных осуществляется индивидуально с точки зрения масштабирования и размера данных. Каждая база данных, развернутая в этой модели, имеет собственные выделенные ресурсы, даже если они развернуты на одном и том же логическом сервере.
Эластичные пулы — группа баз данных, которые управляются вместе и совместно используют общий набор ресурсов. Эластичные пулы предоставляют экономичное решение для модели "программное обеспечение как услуга", так как ресурсы являются общими для всех баз данных. Вы можете настроить ресурсы с использованием модели приобретения на основе DTU или модели приобретения на основе виртуальных ядер.
Модель приобретения
В Azure все службы поддерживаются физическим оборудованием, и вы можете выбрать одну из двух различных моделей приобретения:
Единица транзакций базы данных (DTU)
Единицы транзакций базы данных (DTU) рассчитываются на основе формулы, объединяющей вычислительные ресурсы, ресурсы хранения и ввода-вывода. Это хороший выбор для клиентов, которым нужны простые предварительно настроенные параметры ресурсов.
Модель приобретения DTU поставляется на нескольких разных уровнях служб, таких как "Базовый", "Стандартный" и Premium. Каждый уровень имеет различные возможности, что значительно расширяет выбор при использовании этой платформы.
С точки зрения производительности уровень "Базовый" используется для менее ресурсоемких рабочих нагрузок, а Premium используется для интенсивной рабочей нагрузки.
Ресурсы вычислений и хранения зависят от уровня DTU и предоставляют ряд возможностей по повышению производительности с фиксированным ограничением хранилища, сроком хранения резервных копий и затратами.
Примечание.
Модель приобретения DTU поддерживается только Базой данных SQL Azure.
Дополнительные сведения о моделях приобретения DTU см. в разделе Обзор модели приобретения на основе DTU.
Виртуальное ядро
Модель на основе виртуальных ядер позволяет приобрести указанное количество виртуальных ядер на основе заданных рабочих нагрузок. Модель приобретения на основе виртуальных ядер используется по умолчанию при приобретении ресурсов Базы данных SQL Azure. Базы данных на основе виртуальных ядер имеют четкую связь между числом ядер и объемом памяти и хранилища, предоставленных базе данных. Модель приобретения виртуальных ядер поддерживается Базой данных SQL Azure и Управляемым экземпляром SQL Azure.
Базы данных на основе виртуальных ядер вы также можете приобрести на трех разных уровнях служб.
Общего назначения — этот уровень предназначен для рабочих нагрузок общего назначения. Для него используется хранилище класса Premium Azure. Этот уровень будет иметь большую задержку, чем уровень "Критически важный для бизнеса". Он также предоставляет следующие уровни вычислений:
- Подготовленный — Вычислительные ресурсы выделяются заранее. Почасовое выставление счетов по числу настроенных виртуальных ядер.
- Бессерверный — Вычислительные ресурсы автоматически масштабируются. Посекундное выставление счетов по числу используемых виртуальных ядер.
Критически важный для бизнеса — этот уровень предназначен для высокопроизводительных рабочих нагрузок и обеспечивает наименьшую задержку из всех уровней служб. Для этого уровня используются локальные диски SSD, а не Хранилище BLOB-объектов Azure. Кроме того, этот уровень обеспечивает наилучшую устойчивость к сбоям, а также предоставляет встроенную реплику базы данных только для чтения, которую можно использовать для разгрузки рабочих нагрузок ведения отчетов.
Гипермасштабирование — базы данных с гипермасштабированием могут масштабироваться далеко за пределы ограничения в 4 ТБ, установленного для других предложений Базы данных SQL Azure, и имеют уникальную архитектуру, поддерживающую базы данных размером до 100 ТБ.
Бессерверные приложения
Термин "бессерверный" может приводить к небольшой путанице, так как вы по-прежнему развертываете Базу данных SQL Azure на логическом сервере, к которому подключаетесь. Бессерверная База данных SQL Azure — это уровень вычислений, который автоматически масштабирует ресурсы для заданной базы данных на основе потребности в рабочей нагрузке. Если вычислительные ресурсы рабочей нагрузке больше не требуются, база данных будет «приостановлена», а плата будет взиматься только за хранилище в течение периода, когда база данных неактивна. При попытке установить соединение база данных возобновит работу и станет доступной.
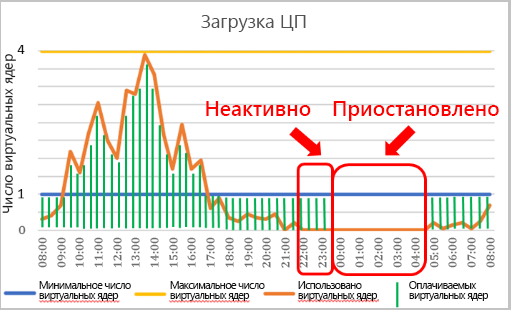
Параметр для управления приостановкой работы называется задержкой автоматической приостановки и имеет минимальное значение в 60 минут и максимальное значение в 7 дней. Если база данных бездействует в течение этого периода времени, она будет приостановлена.
После отсутствия активности базы данных в течение указанного периода времени она будет приостановлена до тех пор, пока не будет предпринята следующая попытка подключения. Настройка диапазона автомасштабирования вычислений и задержка автоматической приостановки влияют на производительность базы данных и затраты на вычисления.
Все приложения, использующие бессерверную модель, должны быть настроены для обработки ошибок подключения и использовать логику повторных попыток, так как подключение к приостановленной базе данных приведет к возникновению ошибки подключения.
Еще одно различие между бессерверной и обычной моделью на основе виртуальных ядер для Базы данных SQL Azure заключается в том, что для бессерверной модели можно указать минимальное и максимальное число виртуальных ядер. Ограничения по памяти и операциям ввода-вывода пропорциональны указанному диапазону.
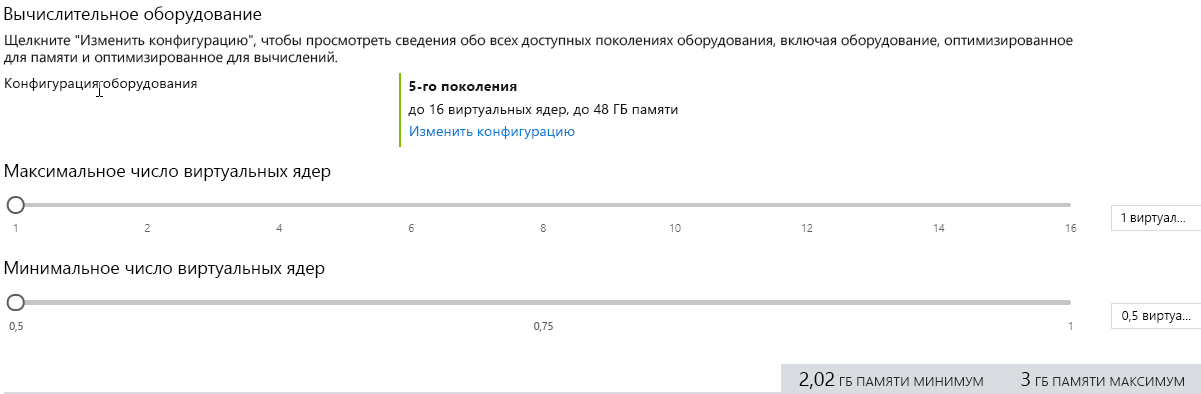
На рисунке выше показан экран конфигурации для бессерверной базы данных на портале Azure. Вы можете выбрать не менее половины виртуального ядра и не более 16 виртуальных ядер.
«Бессерверная» не полностью совместима со всеми функциями в Базы данных SQL Azure, так как для некоторых из них требуется выполнять фоновые процессы в любое время, например:
- Георепликация
- Долгосрочное хранение резервных копий
- База данных заданий в заданиях обработки эластичных баз данных
- База данных синхронизации в службе синхронизации данных SQL (это служба, которая реплицирует данные между группами баз данных)
Примечание.
Бессерверная База данных SQL сейчас поддерживается только на уровне общего назначения в модели приобретения виртуальных ядер.
Резервные копии
Одной из важнейших функций предложения "платформа как услуга" является резервное копирование. В данном случае резервное копирование осуществляется автоматически и без вмешательства пользователя. Резервные копии помещаются в геоизбыточное хранилище BLOB-объектов Azure и по умолчанию хранятся в течение 7 и 35 дней в зависимости от уровня служб базы данных. Для баз данных уровня "Базовый" и на основе виртуальных ядер по умолчанию используется срок хранения в семь дней, при этом в базах данных на основе виртуальных ядер администратор может изменить это значение. Срок хранения можно увеличить, настроив долгосрочное хранение (LTR), что позволит хранить резервные копии до 10 лет.
Чтобы обеспечить избыточность, вы также можете использовать геоизбыточное хранилище BLOB-объектов с доступом на чтение. Это хранилище реплицирует резервные копии вашей базы данных в дополнительный регион по вашему выбору. Кроме того, при необходимости вы можете осуществлять чтение из этого дополнительного региона. Ручное резервное копирование баз данных не поддерживается, и платформа отклонит любой подобный запрос.
Резервное копирование базы данных выполняется по заданному расписанию.
- Полное — раз в неделю
- Разностное — каждые 12 часов
- Журнал — каждые 5–10 минут в зависимости от активности журнала транзакций
Это расписание резервного копирования должно соответствовать потребностям по большинству целевых показателей (целевая точка восстановления и целевое время восстановления — RPO/RTO), однако каждый клиент должен оценить, соответствует ли он вашим бизнес-требованиям.
Доступны несколько вариантов восстановления базы данных. Из-за характера модели "платформа как услуга" вы не можете восстановить базу данных вручную с помощью традиционных методов, например выполнив команду T-SQL RESTORE DATABASE.
Независимо от реализуемого метода восстановления, восстановление поверх существующей базы данных невозможно. Если необходимо восстановить базу данных, следует удалить или переименовать существующую базу данных перед началом процесса восстановления. Кроме того, помните, что в зависимости от уровня служб платформы, время восстановления не является гарантированным и может варьироваться. Рекомендуется протестировать процесс восстановления, чтобы получить базовые метрики, показывающие потенциальную продолжительность восстановления.
Доступны следующие варианты восстановления.
Восстановление с помощью портала Azure — вы можете использовать портал Azure, чтобы восстановить базу данных на том же сервере Базы данных SQL Azure, а также с помощью этого варианта восстановления можно создать базу данных на новом сервере в любом регионе Azure.
Восстановление с помощью языков сценариев — для восстановления базы данных можно использовать PowerShell и Azure CLI.
Примечание.
Резервная копия только для копирования в хранилище BLOB-объектов Azure доступна для Управляемого экземпляра SQL. База данных SQL не поддерживает эту возможность.
Дополнительные сведения об автоматическом резервном копировании см. в разделе Автоматическое резервное копирование — База данных SQL Azure и Управляемый экземпляр SQL Azure.
Активная георепликация
Георепликация — это функция обеспечения непрерывности бизнес-процессов, которая асинхронно реплицирует базу данных во вторичные реплики (до четырех). По мере фиксации транзакций в базе данных — источнике (и ее репликах в пределах одного региона) они отправляются в базы данных — получатели для воспроизведения. Так как такое взаимодействие осуществляется асинхронно, вызывающему приложению не нужно ждать, пока вторичная реплика зафиксирует транзакцию, прежде чем SQL Server возвратит управление вызывающей стороне.
Базы данных — получатели доступны для чтения и могут использоваться для разгрузки рабочих нагрузок только для чтения, тем самым освобождая ресурсы для транзакционных рабочих нагрузок в базе данных — источнике или размещая данные ближе к конечным пользователям. Более того, базы данных — получатели могут находиться в том же регионе, что и база данных — источник, либо в другом регионе Azure.
При использовании георепликации отработка отказа может быть инициирована либо вручную пользователем, либо из приложения. В случае отказа может потребоваться изменить строки подключения приложения, чтобы указать новую конечную точку, которая теперь является базой данных — источником.
Группы отработки отказа
Группы отработки отказа основаны на технологии, используемой для георепликации, но предоставляют единую конечную точку для подключения. Основная причина использования групп отработки отказа заключается в том, что эта технология предоставляет конечные точки, которые можно использовать для маршрутизации трафика в соответствующую реплику. В этом случае после отработки отказа ваше приложение сможет подключиться без изменения строк подключения.