Новые возможности дедупликации данных
Область применения: Windows Server 2022, Windows Server 2019, Windows Server 2016, Azure Stack HCI, версии 21H2 и 20H2
Дедупликация данных в Windows Server оптимизирована для обеспечения высокой производительности, гибкости и управления в масштабе частного облака. Дополнительные сведения о программно определенном стеке хранилища в Windows Server см. в статье "Новые возможности" служба хранилища в Windows Server.
Windows Server 2022
Дедупликация данных не имеет дополнительных улучшений в Windows Server 2022.
Windows Server 2019
Дедупликация данных имеет следующие улучшения в Windows Server 2019:
| Функция | Новинка или обновление | Description |
|---|---|---|
| Поддержка ReFS | Новый | Храните до 10X больше данных на томе с дедупликацией и сжатием файловой системы ReFS. (Это всего один щелчк, чтобы включить в Windows Администратор Center.) Хранилище блоков переменной размера с необязательным сжатием максимально повышает скорость экономии, а архитектура после обработки с несколькими потоками обеспечивает минимальное влияние на производительность. Поддерживает тома до 64 ТБ и дедупликирует первые 4 ТБ каждого файла. |
Windows Server 2016
Дедупликация данных имеет следующие улучшения, начиная с Windows Server 2016:
| Функция | Новинка или обновление | Description |
|---|---|---|
| Поддержка больших томов | Обновлено | До выхода Windows Server 2016 приходилось подгонять размер тома к масштабу обработки, при этом том с размером больше 10 ТБ обычно не подходил для дедупликации данных. В Windows Server 2016 дедупликация данных поддерживает тома размером до 64 ТБ. |
| Поддержка больших файлов) | Обновлено | До выпуска Windows Server 2016 файлы с размером около 1 ТБ обычно не подходили для дедупликации данных. В Windows Server 2016 файлы размером до 1 ТБ полностью поддерживаются. |
| Поддержка Nano Server | Новый | Дедупликация данных полностью поддерживается и является доступной в новом развертывании Nano Server для Windows Server 2016. |
| Упрощенная поддержка резервного копирования | Новый | Виртуализированные приложения резервного копирования (например, Microsoft Data Protection Manager) в Windows Server 2012 R2 поддерживались посредством многоэтапной настройки вручную. В Windows Server 2016 представлен новый стандартный тип использования ("Резервная копия"), обеспечивающий непрерывное развертывание дедупликации данных для виртуализированных приложений резервного копирования. |
| Поддержка последовательного обновления ОС кластера | Новый | Дедупликация данных полностью поддерживает новую функцию последовательного обновления кластерной ОС в Windows Server 2016. |
Поддержка больших томов
Какой эффект дает это изменение?
Чтобы обеспечить оптимальную производительность дедупликации данных в Windows Server 2012 R2, тома должны быть правильно размером, чтобы убедиться, что задание оптимизации может соответствовать скорости изменений данных или оттоку данных. На практике это обычно означает, что дедупликация данных выполняется в томах с размером до 10 ТБ в зависимости от особенностей операций записи рабочей нагрузки.
Начиная с Windows Server 2016 дедупликация данных высокопроизводительна на томах до 64 ТБ.
Что работает иначе?
В Windows Server 2012 R2 конвейер заданий дедупликации данных использует однопотоковые очереди и очереди ввода-вывода для каждого тома. Чтобы задания оптимизации выполнялись своевременно, обеспечивая высокую производительность томов, большие наборы данных нужно разбивать на тома меньшего размера. Допустимый размер тома зависит от ожидаемого масштаба обработки. В среднем это 6–7 ТБ для томов с большим масштабом обработки и 9–10 ТБ для томов с малым масштабом.
Начиная с Windows Server 2016 конвейер задания дедупликации данных был изменен для параллельного выполнения нескольких потоков с использованием нескольких очередей ввода-вывода для каждого тома. В результате производительность повышается до уровня, который ранее был возможен только при разбивке данных на несколько небольших томов. Это изменение представлено на рисунке ниже.
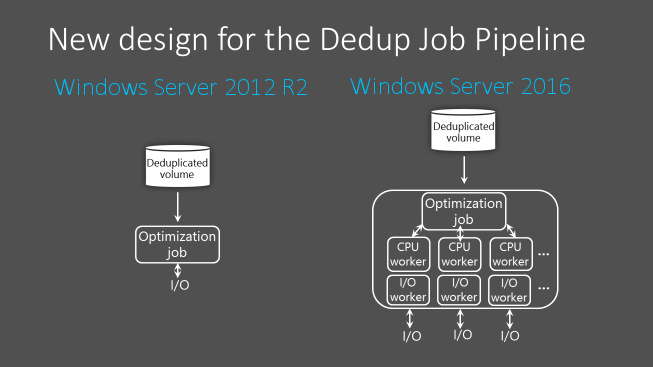
Эти улучшения относятся ко всем заданиям дедупликации данных, а не только к заданию оптимизации.
Поддержка больших файлов
Какой эффект дает это изменение?
В Windows Server 2012 R2 очень большие файлы не используются для дедупликации данных, так как производительность их дедупликации в конвейере обработки дедупликации является низкой. В Windows Server 2016 производительность дедупликации файлов с размером до 1 ТБ является очень высокой. Это позволяет администраторам рационально применять дедупликацию к большему количеству рабочих нагрузок. Например, дедупликацию можно выполнять для очень больших файлов, обычно связанных с рабочими нагрузками резервного копирования.
Что работает иначе?
Начиная с Windows Server 2016 дедупликация данных использует новые структуры карты потоков и другие улучшения "под капотом", чтобы повысить пропускную способность оптимизации и производительность доступа. Кроме того, после отработки отказа конвейер обработки дедупликации теперь может возобновить оптимизацию, вместо того чтобы перезапускать ее. Эти изменения привели к значительному повышению производительности дедупликации файлов с размером до 1 ТБ.
Поддержка Nano Server
Какой эффект дает это изменение?
Nano Server — это новая функция развертывания без монитора в Windows Server 2016, которая быстрее запускается, а также требует меньше системных ресурсов, обновлений и перезапусков, чем развертывание Windows Server Core. Nano Server полностью поддерживает дедупликацию данных. Дополнительные сведения о Nano Server см. в статье Getting Started with Nano Server (Приступая к работе с Nano Server).
Упрощенная конфигурация для виртуализированных приложений резервного копирования
Какой эффект дает это изменение?
Дедупликация данных виртуализированных приложений резервного копирования поддерживается в Windows Server 2012 R2, но параметры дедупликации для нее нужно настраивать вручную. Начиная с Windows Server 2016 настройка дедупликации для виртуализированных приложений резервного копирования значительно упрощается. Теперь включить дедупликацию для тома можно с помощью предварительно заданного параметра "Тип использования" (подобно тому, как это можно сделать для файловых серверов общего назначения и инфраструктуры VDI).
Поддержка последовательного обновления кластерной ОС
Какой эффект дает это изменение?
В отказоустойчивых кластерах Windows Server на одних узлах может выполняться дедупликация данных Windows Server 2012 R2, а на других узлах (параллельно) — дедупликация данных Windows Server 2016. Это улучшение обеспечивает полный доступ ко всем дедуплицированным томам во время последовательного обновления кластера. А это, в свою очередь, позволяет выгружать новую версию дедупликации данных в существующий кластер Windows Server 2012 R2 постепенно и без простоев.
Что работает иначе?
В отказоустойчивых кластерах под управлением предыдущих версий Windows Server узлы могли использовать только одну и ту же версию Windows Server. Начиная с выпуска Windows Server 2016 функция последовательного обновления позволяет кластеру работать в смешанном режиме. Функция дедупликации данных поддерживает этот смешанный режим, обеспечивая полный доступ к данным во время последовательного обновления.