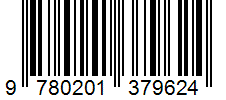Versioner av den offentliga förhandsversionen av Document Intelligence ger tidig åtkomst till funktioner som är i aktiv utveckling. Funktioner, metoder och processer kan ändras, före allmän tillgänglighet (GA), baserat på användarfeedback.
Den offentliga förhandsversionen av Dokumentinformationsklientbiblioteken är som standard REST API version 2024-07-31-preview.
Den offentliga förhandsversionen 2024-07-31-preview är för närvarande endast tillgänglig i följande Azure-regioner. Observera att modellen för anpassad generativ (extrahering av dokumentfält) i AI Studio endast är tillgänglig i regionen USA, norra centrala:
USA, östra
USA, västra 2
Europa, västra
USA, norra centrala
Det här innehållet gäller för:v4.0 (förhandsversion) | Tidigare versioner:v3.1 (GA)
Tilläggsfunktioner är tillgängliga i alla modeller förutom visitkortsmodellen.
Funktioner
Dokumentinformation stöder mer avancerade och modulära analysfunktioner. Använd tilläggsfunktionerna för att utöka resultatet till att omfatta fler funktioner som extraherats från dina dokument. Vissa tilläggsfunktioner medför en extra kostnad. Dessa valfria funktioner kan aktiveras och inaktiveras beroende på scenariot med extrahering av dokument. Om du vill aktivera en funktion lägger du till det associerade funktionsnamnet i frågesträngsegenskapen features . Du kan aktivera fler än en tilläggsfunktion på en begäran genom att tillhandahålla en kommaavgränsad lista över funktioner. Följande tilläggsfunktioner är tillgängliga för 2023-07-31 (GA) och senare versioner.
Alla tilläggsfunktioner stöds inte av alla modeller. Mer information finns iextrahering av modelldata.
Tilläggsfunktioner stöds för närvarande inte för Microsoft kancelarija filtyper.
Dokumentinformation stöder valfria funktioner som kan aktiveras och inaktiveras beroende på scenariot för dokumentextrahering. Följande tilläggsfunktioner är tillgängliga för 2023-10-31-preview, och senare versioner:
Implementeringen av frågefälten i API:et 2023-10-30-preview skiljer sig från den senaste förhandsversionen. Den nya implementeringen är billigare och fungerar bra med strukturerade dokument.
✱ Tillägg – Frågefält prissätts på ett annat sätt än de andra tilläggsfunktionerna. Mer information finns i priser .
Filformat som stöds
PDF
Bilder: JPEG/JPG, PNG, BMP, , TIFFHEIF
✱ Microsoft kancelarija filer stöds för närvarande inte.
Högupplösningsextrahering
Uppgiften att känna igen liten text från stora dokument, till exempel tekniska ritningar, är en utmaning. Ofta blandas texten med andra grafiska element och har olika teckensnitt, storlekar och orienteringar. Dessutom kan texten delas upp i separata delar eller kopplas till andra symboler. Dokumentinformation har nu stöd för att extrahera innehåll från dessa typer av dokument med funktionen ocr.highResolution . Du får bättre kvalitet på extrahering av innehåll från A1/A2/A3-dokument genom att aktivera den här tilläggsfunktionen.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.OCR_HIGH_RESOLUTION], # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_with_highres]
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
# Analyze a document at a URL:
url = "(https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.OCR_HIGH_RESOLUTION] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_with_highres]
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
Funktionen ocr.formula extraherar alla identifierade formler, till exempel matematiska ekvationer, i formulas samlingen som ett objekt på toppnivå under content. Inuti contentrepresenteras identifierade formler som :formula:. Varje post i den här samlingen representerar en formel som innehåller formeltypen som inline eller display, och dess LaTeX-representation tillsammans value med dess polygon koordinater. Inledningsvis visas formler i slutet av varje sida.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.FORMULAS], # Specify which add-on capabilities to enable
)
result: AnalyzeResult = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
if page.formulas:
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
# To learn the detailed concept of "polygon" in the following content, visit: https://aka.ms/bounding-region
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.FORMULAS] # Specify which add-on capabilities to enable
)
result = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
"content": ":formula:",
"pages": [
{
"pageNumber": 1,
"formulas": [
{
"kind": "inline",
"value": "\\frac { \\partial a } { \\partial b }",
"polygon": [...],
"span": {...},
"confidence": 0.99
},
{
"kind": "display",
"value": "y = a \\times b + a \\times c",
"polygon": [...],
"span": {...},
"confidence": 0.99
}
]
}
]
Extrahering av teckensnittsegenskap
Funktionen ocr.font extraherar alla teckensnittsegenskaper för text som extraheras i styles samlingen som ett objekt på översta nivån under content. Varje formatobjekt anger en enskild teckensnittsegenskap, det textintervall som det gäller för och dess motsvarande konfidenspoäng. Den befintliga formategenskapen utökas med fler teckensnittsegenskaper, till exempel similarFontFamily för textens teckensnitt, fontStyle för format som kursiv och normal, för fetstil eller normal, fontWeightcolor för textfärg och backgroundColor för textavgränsningsrutans färg.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
return
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
Funktionen ocr.barcode extraherar alla identifierade streckkoder i barcodes samlingen som ett objekt på översta nivån under content. I , contentrepresenteras identifierade streckkoder som :barcode:. Varje post i den här samlingen representerar en streckkod och innehåller streckkodstypen som kind och det inbäddade streckkodsinnehållet samt value dess polygon koordinater. Inledningsvis visas streckkoder i slutet av varje sida. confidence är hårdkodad för som 1.
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-barcodes.jpg?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.BARCODES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_barcodes]
# Iterate over extracted barcodes on each page.
for page in result.pages:
print(f"----Barcodes detected from page #{page.page_number}----")
print(f"Detected {len(page.barcodes)} barcodes:")
for barcode_idx, barcode in enumerate(page.barcodes):
print(f"- Barcode #{barcode_idx}: {barcode.value}")
print(f" Kind: {barcode.kind}")
print(f" Confidence: {barcode.confidence}")
print(f" Bounding regions: {format_polygon(barcode.polygon)}")
languages Om du lägger till funktionen i analyzeResult begäran förutsäger du det identifierade primära språket för varje textrad tillsammans med confidence i languages samlingen under analyzeResult.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
if result.languages:
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(
f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'"
)
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'")
Med den sökbara PDF-funktionen kan du konvertera en analog PDF, till exempel skannade PDF-filer, till en PDF med inbäddad text. Den inbäddade texten möjliggör djuptextsökning i PDF-filens extraherade innehåll genom att lägga över de identifierade textentiteterna ovanpå bildfilerna.
Viktigt!
För närvarande stöds den sökbara PDF-funktionen endast av Read OCR-modellen prebuilt-read. När du använder den här funktionen anger modelId du som prebuilt-read, eftersom andra modelltyper returnerar fel för den här förhandsversionen.
Sökbar PDF ingår i modellen 2024-07-31-preview prebuilt-read utan användningskostnad för allmän PDF-förbrukning.
Använda sökbar PDF
Om du vill använda sökbar PDF gör du en POST begäran med hjälp av Analyze åtgärden och anger utdataformatet som pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
När åtgärden Analyze är klar gör du en GET begäran om att hämta åtgärdsresultatet Analyze .
När pdf-filen har slutförts kan den hämtas och laddas ned som application/pdf. Den här åtgärden möjliggör direkt nedladdning av den inbäddade textformen pdf i stället för Base64-kodad JSON.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Nyckel/värde-par
I tidigare API-versioner extraherade den fördefinierade dokumentmodellen nyckel/värde-par från formulär och dokument. Med tillägg av keyValuePairs funktionen i den fördefinierade layouten ger layoutmodellen nu samma resultat.
Nyckel/värde-par är specifika intervall i dokumentet som identifierar en etikett eller nyckel och dess associerade svar eller värde. I ett strukturerat formulär kan dessa par vara etiketten och värdet som användaren angav för fältet. I ett ostrukturerat dokument kan det vara det datum då ett kontrakt utfördes baserat på texten i ett stycke. AI-modellen tränas för att extrahera identifierbara nycklar och värden baserat på en mängd olika dokumenttyper, format och strukturer.
Nycklar kan också finnas isolerat när modellen upptäcker att en nyckel finns, utan associerat värde eller när valfria fält bearbetas. Ett mellannamnsfält kan till exempel lämnas tomt i ett formulär i vissa fall. Nyckel/värde-par är textintervall som finns i dokumentet. För dokument där samma värde beskrivs på olika sätt, till exempel kund/användare, är den associerade nyckeln antingen kund eller användare (baserat på kontext).
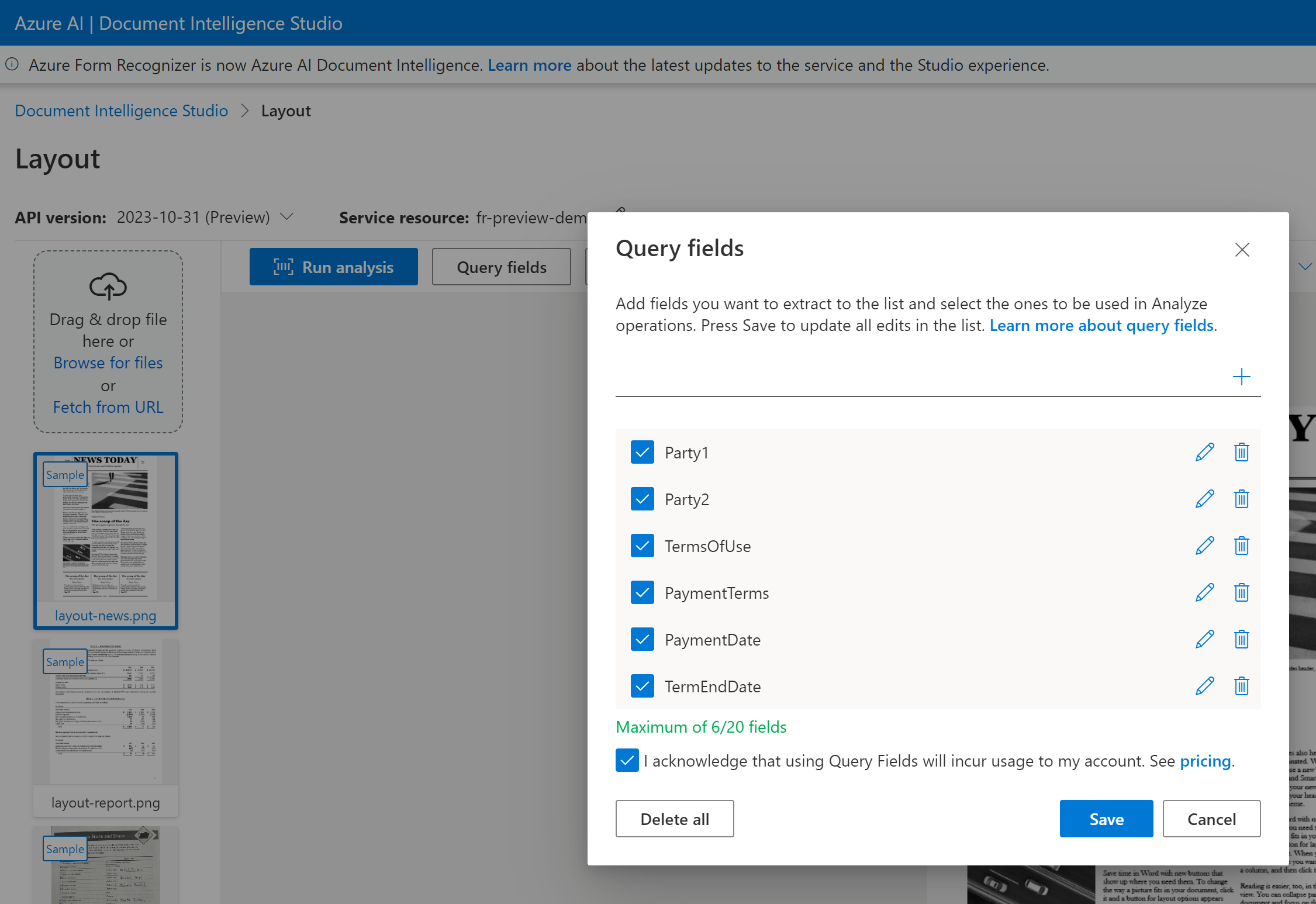
Frågefält är en tilläggsfunktion för att utöka schemat som extraherats från en fördefinierad modell eller definiera ett specifikt nyckelnamn när nyckelnamnet är variabel. Om du vill använda frågefält anger du funktionerna till queryFields och anger en kommaavgränsad lista med fältnamn i queryFields egenskapen.
Dokumentinformation stöder nu extrahering av frågefält. Med extrahering av frågefält kan du lägga till fält i extraheringsprocessen med hjälp av en frågebegäran utan att behöva lägga till utbildning.
Använd frågefält när du behöver utöka schemat för en fördefinierad eller anpassad modell eller behöver extrahera några fält med utdata från layouten.
Frågefält är en premium-tilläggsfunktion. För bästa resultat definierar du de fält som du vill extrahera med hjälp av kamelfall eller Pascal-skiftlägesfältnamn för fältnamn med flera ord.
Frågefält stöder högst 20 fält per begäran. Om dokumentet innehåller ett värde för fältet returneras fältet och värdet.
Den här versionen har en ny implementering av frågefältsfunktionen som är lägre än den tidigare implementeringen och bör valideras.
Kommentar
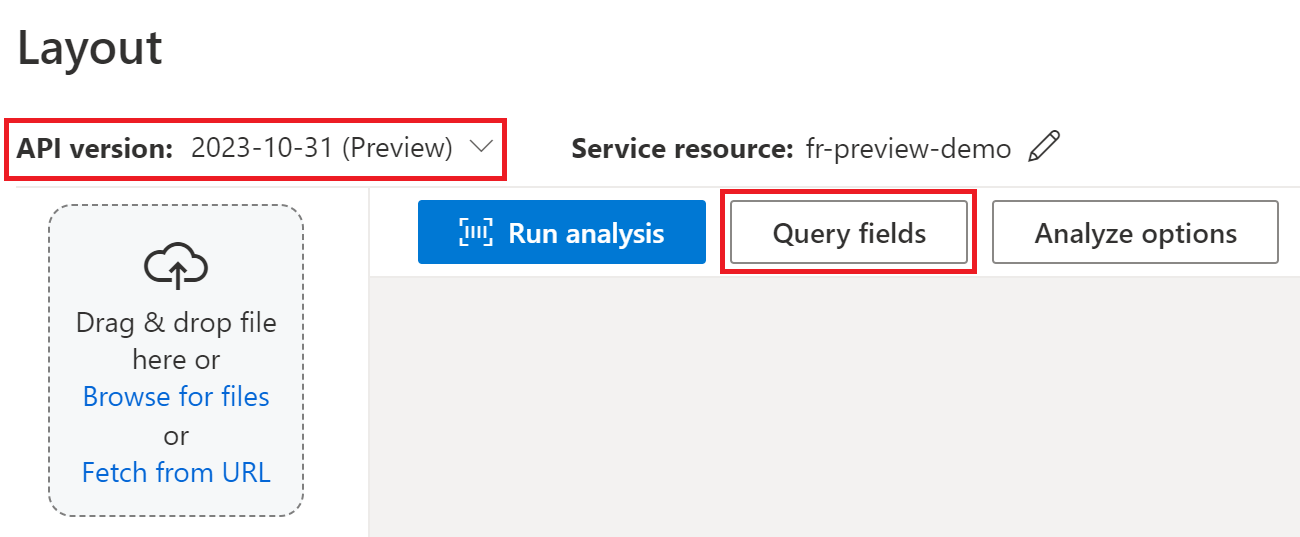
Extrahering av frågefält i Document Intelligence Studio är för närvarande tillgängligt med API:US taxet layout och fördefinierade modeller 2024-02-29-preview2023-10-31-preview och senare versioner förutom modellerna (W2, 1098s och 1099s-modeller).
Extrahering av frågefält
För extrahering av frågefält anger du de fält som du vill extrahera och Dokumentinformation analyserar dokumentet därefter. Här är ett exempel:
Om du bearbetar ett kontrakt i Document Intelligence Studio använder du versionerna 2024-02-29-preview eller 2023-10-31-preview :
Du kan skicka en lista med fältetiketter som Party1, Party2, TermsOfUse, PaymentTerms, PaymentDateoch TermEndDate som en del av analyze document begäran.
Dokumentinformation kan analysera och extrahera fältdata och returnera värdena i en strukturerad JSON-utdata.
Förutom frågefälten innehåller svaret text, tabeller, markeringsmarkeringar och andra relevanta data.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/invoice/simple-invoice.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.QUERY_FIELDS], # Specify which add-on capabilities to enable.
query_fields=["Address", "InvoiceNumber"], # Set the features and provide a comma-separated list of field names.
)
result: AnalyzeResult = poller.result()
print("Here are extra fields in result:\n")
if result.documents:
for doc in result.documents:
if doc.fields and doc.fields["Address"]:
print(f"Address: {doc.fields['Address'].value_string}")
if doc.fields and doc.fields["InvoiceNumber"]:
print(f"Invoice number: {doc.fields['InvoiceNumber'].value_string}")