Layoutmodell för dokumentinformation
Viktigt!
- Versioner av den offentliga förhandsversionen av Document Intelligence ger tidig åtkomst till funktioner som är i aktiv utveckling.
- Funktioner, metoder och processer kan ändras, före allmän tillgänglighet (GA), baserat på användarfeedback.
- Den offentliga förhandsversionen av Dokumentinformationsklientbiblioteken är som standard REST API version 2024-02-29-preview.
- Förhandsversion 2024-02-29-preview är för närvarande endast tillgänglig i följande Azure-regioner:
- USA, östra
- USA, västra 2
- Europa, västra
Det här innehållet gäller för:![]() v4.0 (förhandsversion) | Tidigare versioner:
v4.0 (förhandsversion) | Tidigare versioner:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Det här innehållet gäller för:![]() v3.1 (GA) | Senaste version:
v3.1 (GA) | Senaste version:![]() v4.0 (förhandsversion) | Tidigare versioner:
v4.0 (förhandsversion) | Tidigare versioner:![]() v3.0
v3.0![]() v2.1
v2.1
Det här innehållet gäller för:![]() v3.0 (GA) | Senaste versionerna:
v3.0 (GA) | Senaste versionerna:![]() v4.0 (förhandsversion)
v4.0 (förhandsversion)![]() v3.1 | Tidigare version:
v3.1 | Tidigare version:![]() v2.1
v2.1
Det här innehållet gäller för:![]() v2.1 | Senaste version:
v2.1 | Senaste version:![]() v4.0 (förhandsversion)
v4.0 (förhandsversion)
Layoutmodellen för dokumentinformation är ett avancerat maskininlärningsbaserat dokumentanalys-API som är tillgängligt i document intelligence-molnet. Det gör att du kan ta dokument i olika format och returnera strukturerade datarepresentationer av dokumenten. Den kombinerar en förbättrad version av våra kraftfulla OCR-funktioner (Optisk teckenigenkänning) med djupinlärningsmodeller för att extrahera text, tabeller, urvalsmarkeringar och dokumentstruktur.
Analys av dokumentlayout
Layoutanalys av dokumentstruktur är en process för att analysera ett dokument för att extrahera intressanta regioner och deras relationer. Målet är att extrahera text och strukturella element från sidan för att skapa bättre semantiska förståelsemodeller. Det finns två typer av roller i en dokumentlayout:
- Geometriska roller: Text, tabeller, siffror och urvalsmarkeringar är exempel på geometriska roller.
- Logiska roller: Rubriker, rubriker och sidfötter är exempel på logiska roller i texter.
Följande bild visar de typiska komponenterna i en bild av en exempelsida.

Utvecklingsalternativ
Document Intelligence v4.0 (2024-02-29-preview, 2023-10-31-preview) stöder följande verktyg, program och bibliotek:
| Funktion | Resurser | Model ID |
|---|---|---|
| Layoutmodell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
fördefinierad layout |
Document Intelligence v3.1 stöder följande verktyg, program och bibliotek:
| Funktion | Resurser | Model ID |
|---|---|---|
| Layoutmodell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
fördefinierad layout |
Document Intelligence v3.0 stöder följande verktyg, program och bibliotek:
| Funktion | Resurser | Model ID |
|---|---|---|
| Layoutmodell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
fördefinierad layout |
Document Intelligence v2.1 stöder följande verktyg, program och bibliotek:
| Funktion | Resurser |
|---|---|
| Layoutmodell | • Etikettverktyg för dokumentinformation• REST API • Klientbiblioteks-SDK • Docker-container för dokumentinformation |
Indatakrav
För bästa resultat anger du ett tydligt foto eller en genomsökning av hög kvalitet per dokument.
Filformat som stöds:
Modell PDF Bild:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) och HTMLLäsa ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Allmänt dokument ✔ ✔ Inbyggda ✔ ✔ Anpassad extrahering ✔ ✔ Anpassad klassificering ✔ ✔ ✔ (2024-02-29-preview) För PDF och TIFF kan upp till 2 000 sidor bearbetas (med en kostnadsfri nivåprenumeration bearbetas endast de två första sidorna).
Filstorleken för att analysera dokument är 500 MB för den betalda nivån (S0) och 4 MB för den kostnadsfria nivån (F0).
Bilddimensionerna måste vara mellan 50 x 50 bildpunkter och 10 000 px x 10 000 bildpunkter.
Om dina PDF-filer är låsta med lösenord måste du ta bort låset innan du skickar filerna.
Den minsta höjden på texten som ska extraheras är 12 bildpunkter för en bild på 1 024 x 768 bildpunkter. Den här dimensionen motsvarar ungefär
8-punkttext vid 150 punkter per tum (DPI).För anpassad modellträning är det maximala antalet sidor för träningsdata 500 för den anpassade mallmodellen och 50 000 för den anpassade neurala modellen.
För anpassad extraheringsmodellträning är den totala storleken på träningsdata 50 MB för mallmodellen och 1G-MB för den neurala modellen.
För anpassad klassificeringsmodellträning är
1GBden totala storleken på träningsdata med högst 10 000 sidor.
- Filformat som stöds: JPEG, PNG, PDF och TIFF.
- Antal sidor som stöds: För PDF och TIFF bearbetas upp till 2 000 sidor. För prenumeranter på den kostnadsfria nivån bearbetas endast de två första sidorna.
- Filstorlek som stöds: filstorleken måste vara mindre än 50 MB och dimensionerna minst 50 x 50 bildpunkter och högst 10 000 x 10 000 bildpunkter.
Kom igång med layoutmodellen
Se hur data, inklusive text, tabeller, tabellrubriker, markeringsmarkeringar och strukturinformation extraheras från dokument med hjälp av dokumentinformation. Du behöver följande resurser:
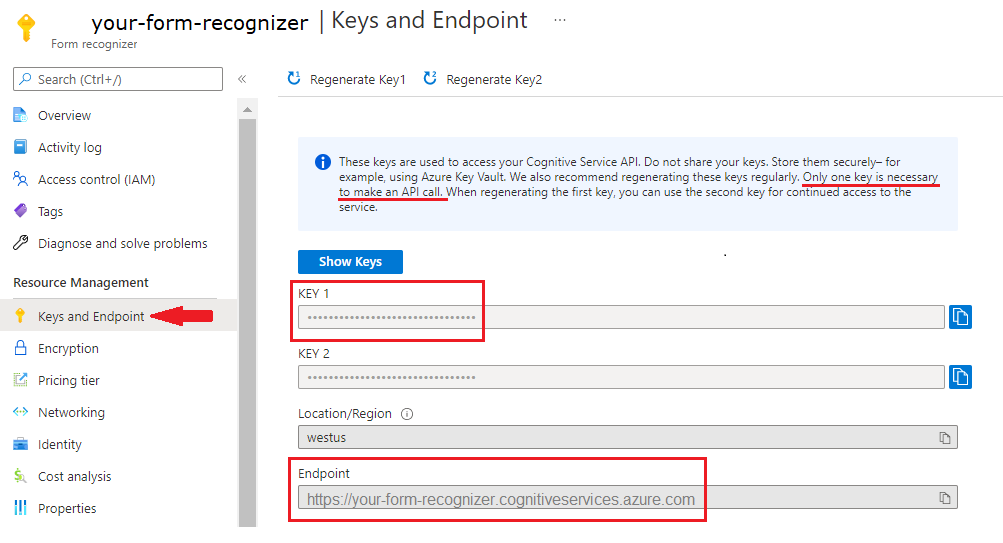
En Azure-prenumeration – du kan skapa en kostnadsfritt.
En instans av dokumentinformation i Azure-portalen. Du kan använda den kostnadsfria prisnivån (
F0) för att prova tjänsten. När resursen har distribuerats väljer du Gå till resurs för att hämta din nyckel och slutpunkt.
Kommentar
Document Intelligence Studio är tillgängligt med v3.0 API:er och senare versioner.
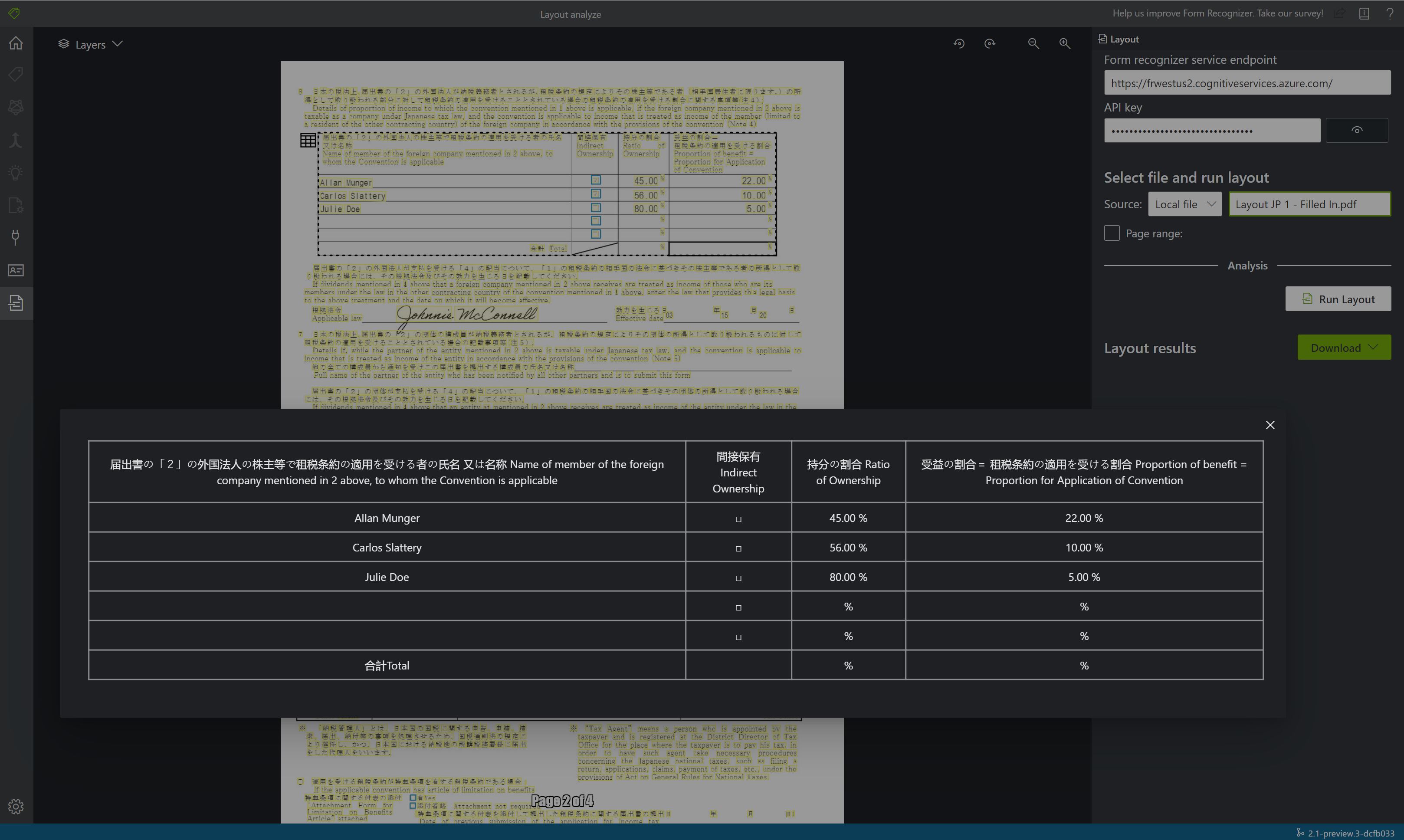
Exempeldokument som bearbetas med Document Intelligence Studio
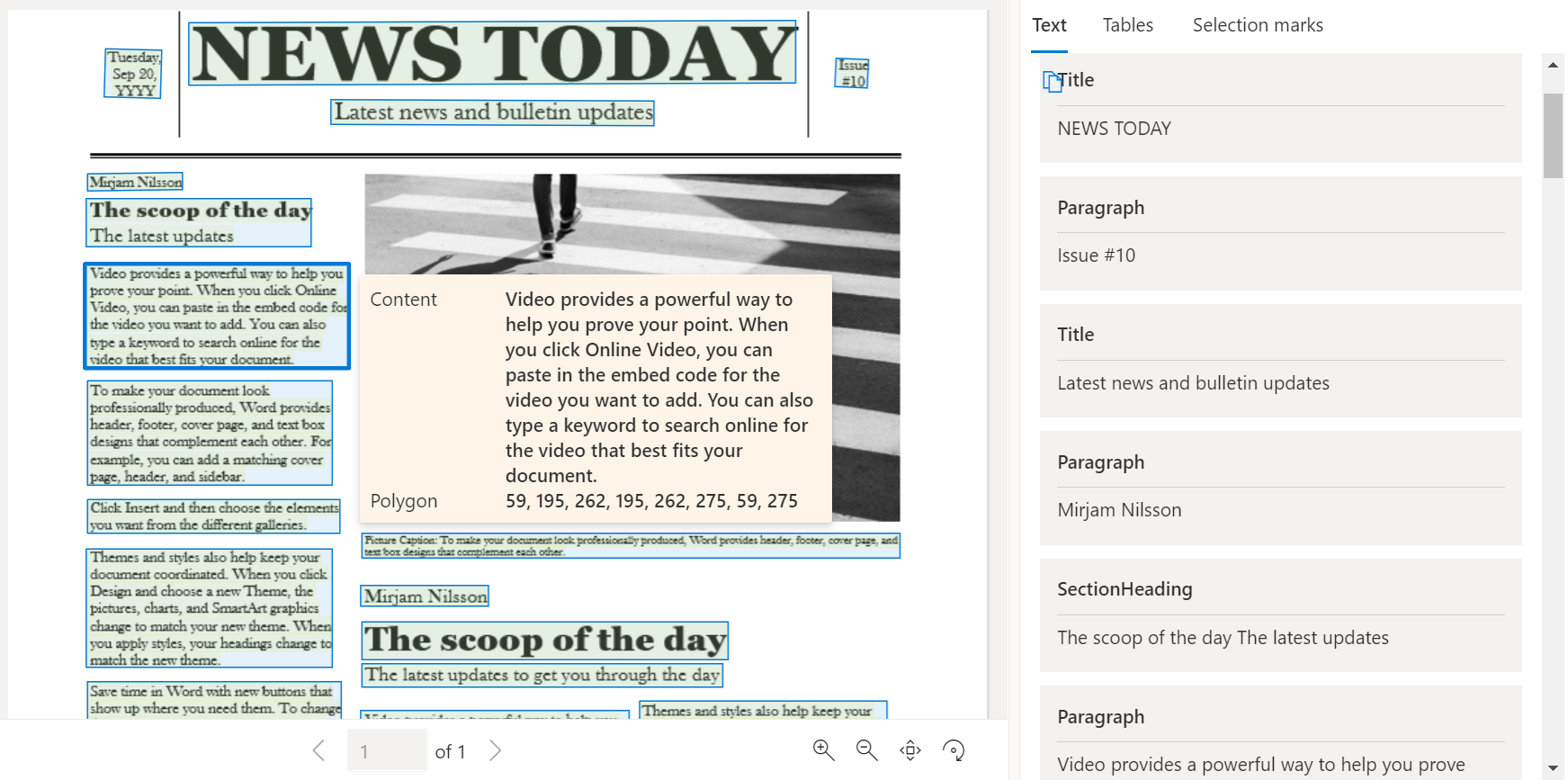
På startsidan för Document Intelligence Studio väljer du Layout.
Du kan analysera exempeldokumentet eller ladda upp dina egna filer.
Välj knappen Kör analys och konfigurera vid behov alternativen Analysera:

Exempeletikettverktyg för dokumentinformation
Gå till exempelverktyget för dokumentinformation.
På exempelverktygets startsida väljer du Använd layout för att hämta text, tabeller och markeringsmarkeringar.
I fältet För dokumentinformationstjänstens slutpunkt klistrar du in slutpunkten som du fick med din Document Intelligence-prenumeration.
I nyckelfältet klistrar du in den nyckel som du fick från dokumentinformationsresursen.
I fältet Källa väljer du URL på den nedrullningsbara menyn Du kan använda vårt exempeldokument:
Välj knappen Hämta.
Välj Kör layout. Verktyget Exempeletiketter för dokumentinformation anropar API:et
Analyze Layoutför att analysera dokumentet.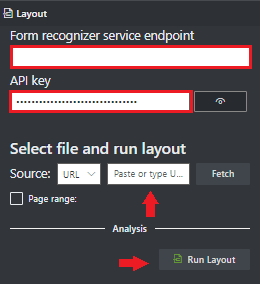
Visa resultatet – se den markerade extraherade texten, identifierade markeringsmarkeringar och identifierade tabeller.
{kind=link}
Språk och nationella inställningar som stöds
Se sidan Språkstöd – modeller för dokumentanalys för en fullständig lista över språk som stöds.
Document Intelligence v2.1 stöder följande verktyg, program och bibliotek:
| Funktion | Resurser |
|---|---|
| Layout-API |
Extrahering av data
Layoutmodellen extraherar text, markeringsmarkeringar, tabeller, stycken och stycketyper (roles) från dina dokument.
Kommentar
Versioner 2024-02-29-preview, 2023-10-31-previewoch senare stöder Microsoft Office (DOCX-, XLSX-, PPTX- och HTML-filer). Följande funktioner stöds inte:
- Det finns ingen vinkel, bredd/höjd och enhet för varje sidobjekt.
- För varje objekt som identifieras finns det ingen avgränsande polygon eller avgränsningsregion.
- Sidintervall (
pages) stöds inte som en parameter. - Inget
linesobjekt.
Sidor
Sidsamlingen är en lista över sidor i dokumentet. Varje sida representeras sekventiellt i dokumentet och innehåller orienteringsvinkeln som anger om sidan roteras och bredden och höjden (dimensioner i bildpunkter). Sidenheterna i modellutdata beräknas enligt följande:
| Filformat | Beräknad sidenhet | Totalt antal sidor |
|---|---|---|
| Bilder (JPEG/JPG, PNG, BMP, HEIF) | Varje bild = 1 sidenhet | Totalt antal bilder |
| Varje sida i PDF = 1 sidenhet | Totalt antal sidor i PDF-filen | |
| TIFF | Varje bild i enheten TIFF = 1 sida | Totalt antal bilder i TIFF |
| Word (DOCX) | Upp till 3 000 tecken = en sidenhet, inbäddade eller länkade bilder stöds inte | Totalt antal sidor på upp till 3 000 tecken vardera |
| Excel (XLSX) | Varje kalkylblad = 1 sidenhet, inbäddade eller länkade bilder stöds inte | Totalt antal kalkylblad |
| PowerPoint (PPTX) | Varje bild = 1 sidenhet, inbäddade eller länkade bilder stöds inte | Totalt antal bilder |
| HTML | Upp till 3 000 tecken = en sidenhet, inbäddade eller länkade bilder stöds inte | Totalt antal sidor på upp till 3 000 tecken vardera |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
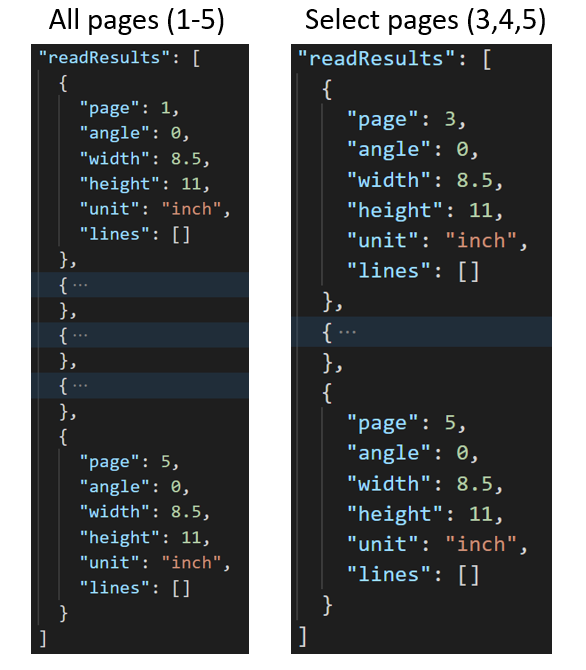
Extrahera markerade sidor från dokument
För stora dokument med flera sidor använder du pages frågeparametern för att ange specifika sidnummer eller sidintervall för textextrahering.
Punkterna
Layoutmodellen extraherar alla identifierade textblock i paragraphs samlingen som ett objekt på översta nivån under analyzeResults. Varje post i den här samlingen representerar ett textblock och innehåller den extraherade texten somcontentoch avgränsningskoordinaterna polygon . Informationen span pekar på textfragmentet i den översta egenskapen content som innehåller den fullständiga texten från dokumentet.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Styckeroller
Den nya maskininlärningsbaserade identifieringen av sidobjekt extraherar logiska roller som rubriker, avsnittsrubriker, sidhuvuden, sidfötter med mera. Layoutmodellen för dokumentinformation tilldelar vissa textblock i paragraphs samlingen med sin särskilda roll eller typ som förutsägs av modellen. De används bäst med ostrukturerade dokument för att förstå layouten för det extraherade innehållet för en mer omfattande semantisk analys. Följande styckeroller stöds:
| Förutsagd roll | Beskrivning | Filtyper som stöds |
|---|---|---|
title |
Huvudrubrikerna på sidan | pdf, image, docx, pptx, xlsx, html |
sectionHeading |
Ett eller flera underrubriker på sidan | pdf, image, docx, xlsx, html |
footnote |
Text längst ned på sidan | pdf, bild |
pageHeader |
Text nära sidans övre kant | pdf, image, docx |
pageFooter |
Text nära sidans nederkant | pdf, image, docx, pptx, html |
pageNumber |
Sidnummer | pdf, bild |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Text, rader och ord
Dokumentlayoutmodellen i Dokumentinformation extraherar utskrifts- och handskriven formatmallstext som lines och words. Samlingen styles innehåller alla handskrivna formatmallar för rader om de identifieras tillsammans med de intervall som pekar på den associerade texten. Den här funktionen gäller för handskrivna språk som stöds.
För Microsoft Word, Excel, PowerPoint och HTML extraherar dokumentinformationsversionerna 2024-02-29-preview och 2023-10-31-preview layoutmodellen all inbäddad text som den är. Texter extraheras som ord och stycken. Inbäddade bilder stöds inte.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
Handskriven stil för textrader
Svaret innehåller klassificering av om varje textrad har handskriftsstil eller inte, tillsammans med en konfidenspoäng. Mer information. Se Stöd för handskrivna språk. I följande exempel visas ett exempel på JSON-kodfragment.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Om du aktiverar funktionen för teckensnitt/formattillägg får du även teckensnitts-/formatmallsresultatet styles som en del av objektet.
Markeringsmarkeringar
Layoutmodellen extraherar också markeringsmarkeringar från dokument. Extraherade markeringsmarkeringar visas i pages samlingen för varje sida. De inkluderar avgränsningen polygon, confidenceoch markeringen state (selected/unselected). Textrepresentationen (d.v.s :selected: . och :unselected) ingår också som startindex (offset) och length som refererar till egenskapen på den översta nivån content som innehåller den fullständiga texten från dokumentet.
{
"selectionMarks": [
{
"state": "unselected",
"polygon": [],
"confidence": 0.995,
"span": {
"offset": 1421,
"length": 12
}
}
]
}
Tabeller
Att extrahera tabeller är ett viktigt krav för att bearbeta dokument som innehåller stora mängder data som vanligtvis formateras som tabeller. Layoutmodellen extraherar tabeller i pageResults avsnittet i JSON-utdata. Extraherad tabellinformation innehåller antalet kolumner och rader, radintervall och kolumnintervall. Varje cell med sin avgränsningspolygon matas ut tillsammans med information om området identifieras som en columnHeader eller inte. Modellen stöder extrahering av tabeller som roteras. Varje tabellcell innehåller rad- och kolumnindex och avgränsningspolygonkoordinater. För celltexten matar modellen ut informationen span som innehåller startindexet (offset). Modellen matar också ut length innehållet på den översta nivån som innehåller den fullständiga texten från dokumentet.
Kommentar
Tabellen stöds inte om indatafilen är XLSX.
{
"tables": [
{
"rowCount": 9,
"columnCount": 4,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"columnSpan": 4,
"content": "(In millions, except earnings per share)",
"boundingRegions": [],
"spans": []
},
]
}
]
}
Anteckningar (endast tillgängliga i 2023-02-28-preview API.)
Layoutmodellen extraherar anteckningar i dokument, till exempel kontroller och korsningar. Svaret innehåller den typ av anteckning, tillsammans med en konfidenspoäng och avgränsningspolygon.
{
"pages": [
{
"annotations": [
{
"kind": "cross",
"polygon": [...],
"confidence": 1
}
]
}
]
}
Utdata till markdown-format
Layout-API:et kan mata ut den extraherade texten i markdown-format. outputContentFormat=markdown Använd för att ange utdataformatet i markdown. Markdown-innehållet är utdata som en del av avsnittet content .
"analyzeResult": {
"apiVersion": "2024-02-29-preview",
"modelId": "prebuilt-layout",
"contentFormat": "markdown",
"content": "# CONTOSO LTD...",
}
Siffror
Siffror (diagram, bilder) i dokument spelar en avgörande roll när det gäller att komplettera och förbättra textinnehållet, vilket ger visuella representationer som underlättar förståelsen av komplex information. Figurobjektet som identifieras av layoutmodellen har nyckelegenskaper som boundingRegions (figurens rumsliga platser på dokumentsidorna, inklusive sidnumret och polygonkoordinaterna som beskriver figurens gräns), spans (beskriver textintervallen som är relaterade till figuren och anger deras förskjutningar och längder i dokumentets text. Den här anslutningen hjälper till att associera figuren med dess relevanta textkontext), elements (identifierarna för textelement eller stycken i dokumentet som är relaterade till eller beskriver figuren) och caption om det finns några.
{
"figures": [
{
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15",
...
],
"caption": {
"content": "Here is a figure with some text",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15"
]
}
}
]
}
Avsnitt
Hierarkisk dokumentstrukturanalys är avgörande för att organisera, förstå och bearbeta omfattande dokument. Den här metoden är viktig för att semantiskt segmentera långa dokument för att öka förståelsen, underlätta navigeringen och förbättra informationshämtningen. Tillkomsten av RAG (Retrieval Augmented Generation) i dokumentgenerativ AI understryker betydelsen av hierarkisk dokumentstrukturanalys. Layoutmodellen stöder avsnitt och underavsnitt i utdata, som identifierar relationen mellan avsnitt och objekt i varje avsnitt. Den hierarkiska strukturen underhålls i elements varje avsnitt. Du kan använda utdata till markdown-format för att enkelt hämta avsnitten och underavsnitten i markdown.
{
"sections": [
{
"spans": [],
"elements": [
"/paragraphs/0",
"/sections/1",
"/sections/2",
"/sections/5"
]
},
...
}
Naturliga avläsningsordningsutdata (endast latinsk)
Du kan ange i vilken ordning textraderna ska matas ut med frågeparametern readingOrder . Använd natural för ett mer människovänligt läsordningsutdata som visas i följande exempel. Den här funktionen stöds endast för latinska språk.

Välj sidnummer eller intervall för textextrahering
För stora dokument med flera sidor använder du pages frågeparametern för att ange specifika sidnummer eller sidintervall för textextrahering. I följande exempel visas ett dokument med 10 sidor, med text extraherad för båda fallen – alla sidor (1–10) och valda sidor (3–6).
Åtgärden Hämta analyslayoutresultat
Det andra steget är att anropa åtgärden Hämta analysera layoutresultat . Den här åtgärden tar som indata det resultat-ID som Analyze Layout åtgärden skapade. Det returnerar ett JSON-svar som innehåller ett statusfält med följande möjliga värden.
| Fält | Typ | Möjliga värden |
|---|---|---|
| status | sträng | notStarted: Analysåtgärden har inte startats.running: Analysåtgärden pågår. failed: Analysåtgärden misslyckades.succeeded: Analysåtgärden lyckades. |
Anropa den här åtgärden iterativt tills den succeeded returnerar värdet. Om du vill undvika att överskrida antalet förfrågningar per sekund (RPS) använder du ett intervall på 3 till 5 sekunder.
När statusfältet har succeeded värdet innehåller JSON-svaret den extraherade layouten, texten, tabellerna och markeringsmarkeringarna. Extraherade data innehåller extraherade textrader och ord, avgränsningsrutor, textutseende med handskriven indikation, tabeller och markeringsmarkeringar med markerade/omarkerade angivna.
Handskriven klassificering för textrader (endast latinsk)
Svaret innehåller klassificering av om varje textrad har handskriftsstil eller inte, tillsammans med en konfidenspoäng. Den här funktionen stöds endast för latinska språk. I följande exempel visas den handskrivna klassificeringen för texten i bilden.

Exempel på JSON-utdata
Svaret på åtgärden Hämta analysera layoutresultat är en strukturerad representation av dokumentet med all information som extraheras. Här finns en exempeldokumentfil och dess strukturerade utdataexempellayoututdata.
JSON-utdata har två delar:
readResultsnoden innehåller all igenkänd text och markeringsmarkering. Textpresentationshierarkin är sida, rad och sedan enskilda ord.pageResultsnoden innehåller tabeller och celler som extraherats med sina avgränsningsrutor, konfidens och en referens till raderna och orden i fältet "readResults".
Exempel på utdata
Text
Layout-API extraherar text från dokument och bilder med flera textvinklar och färger. Den accepterar foton av dokument, fax, tryckt och/eller handskriven text (endast engelska) och blandade lägen. Text extraheras med information om rader, ord, avgränsningsrutor, konfidenspoäng och format (handskriven eller annan). All textinformation ingår i readResults avsnittet i JSON-utdata.
Tabeller med rubriker
Layout-API extraherar tabeller i pageResults avsnittet i JSON-utdata. Dokument kan skannas, fotograferas eller digitaliseras. Tabeller kan vara komplexa med sammanfogade celler eller kolumner, med eller utan kantlinjer och med udda vinklar. Extraherad tabellinformation innehåller antalet kolumner och rader, radintervall och kolumnintervall. Varje cell med sin avgränsningsruta matas ut tillsammans med om området känns igen som en del av en rubrik eller inte. Modellen förutsagda rubrikceller kan sträcka sig över flera rader och är inte nödvändigtvis de första raderna i en tabell. De fungerar också med roterade tabeller. Varje tabellcell innehåller också den fullständiga texten med referenser till de enskilda orden i readResults avsnittet.
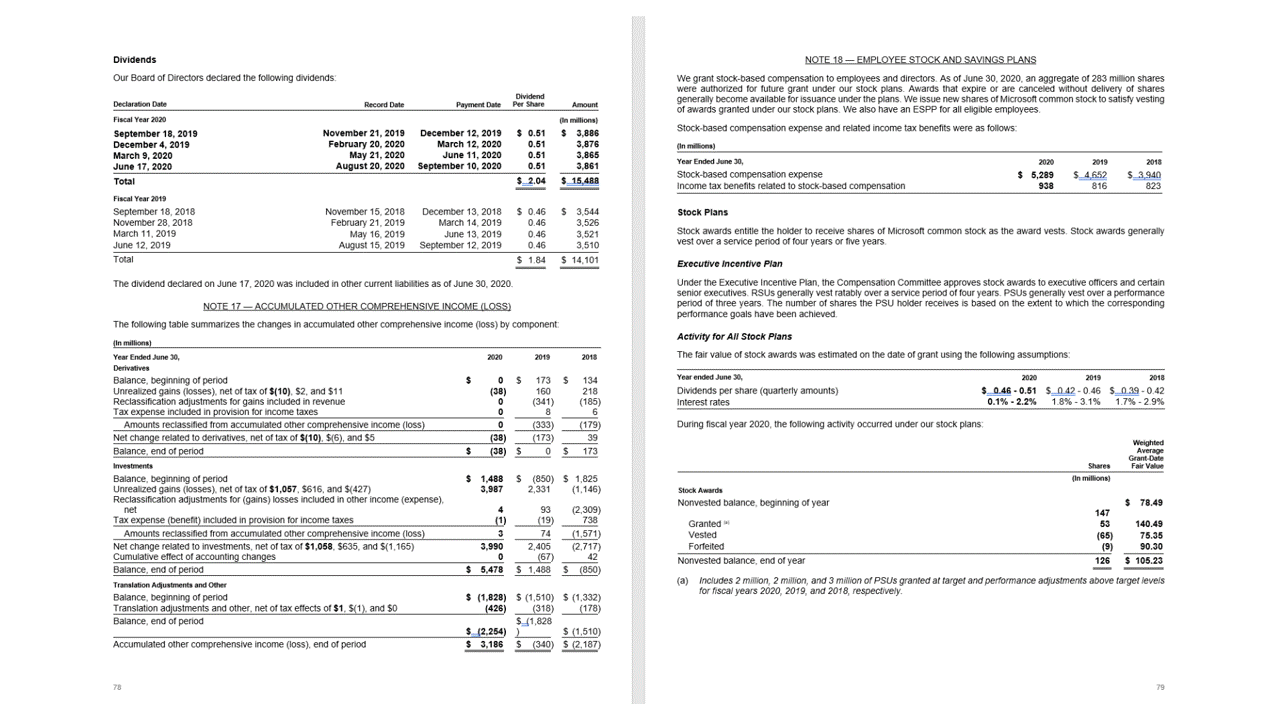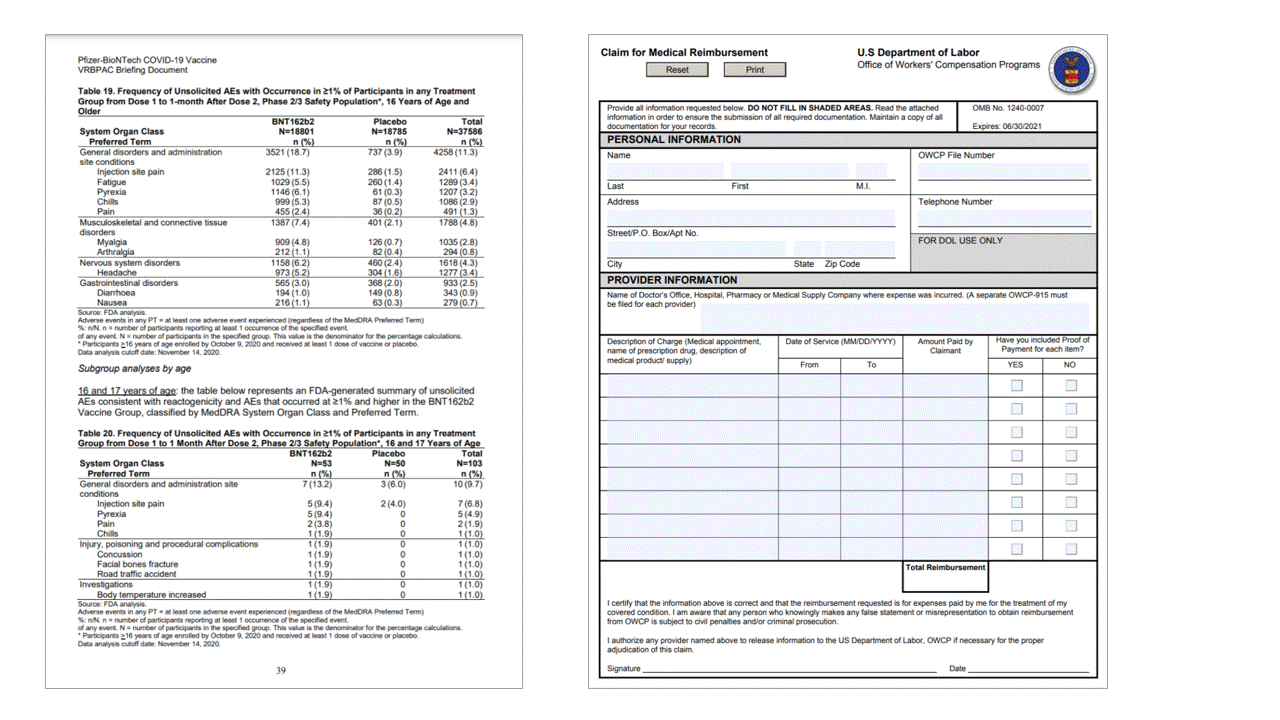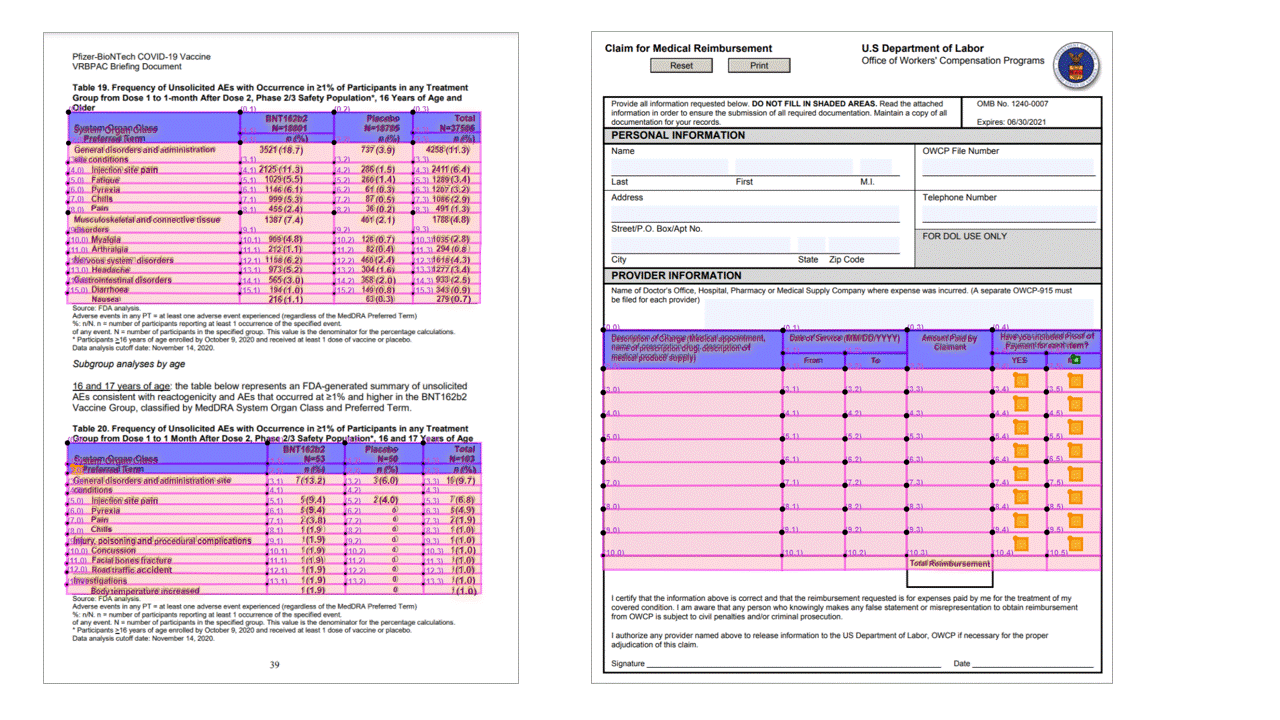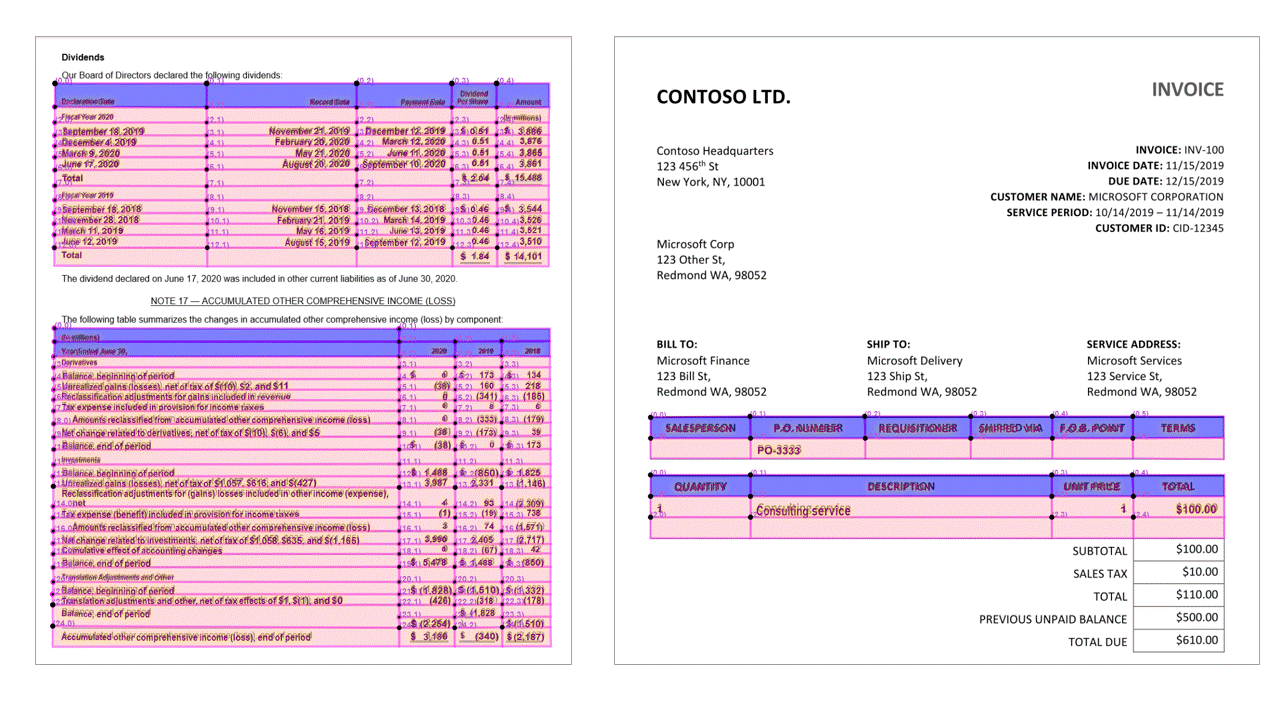
Markeringsmarkeringar
Layout-API extraherar också urvalsmarkeringar från dokument. Extraherade markeringsmarkeringar inkluderar avgränsningsrutan, konfidens och tillstånd (markerad/avmarkerad). Markeringsmarkeringsinformation extraheras i readResults avsnittet i JSON-utdata.
Migreringsguide
Nästa steg
Lär dig hur du bearbetar dina egna formulär och dokument med Document Intelligence Studio.
Slutför en snabbstart för dokumentinformation och kom igång med att skapa en app för dokumentbearbetning på valfritt utvecklingsspråk.
Lär dig hur du bearbetar dina egna formulär och dokument med verktyget Exempeletiketter för dokumentinformation.
Slutför en snabbstart för dokumentinformation och kom igång med att skapa en app för dokumentbearbetning på valfritt utvecklingsspråk.