Träna en anpassad modell med hjälp av verktyget Exempeletiketter
Det här innehållet gäller för:![]() v2.1.
v2.1.
Dricks
- För en förbättrad upplevelse och avancerad modellkvalitet kan du prova Document Intelligence v3.0 Studio.
- v3.0 Studio stöder alla modeller som tränats med v2.1-märkta data.
- Du kan läsa api-migreringsguiden för detaljerad information om migrering från v2.1 till v3.0.
- Se våra REST API- eller C#-, Java-, JavaScript- eller Python SDK-snabbstarter för att komma igång med V3.0.
I den här artikeln använder du REST-API:et för dokumentinformation med verktyget Exempeletiketter för att träna en anpassad modell med manuellt märkta data.
Förutsättningar
Du behöver följande resurser för att slutföra projektet:
- Azure-prenumeration – Skapa en kostnadsfritt
- När du har din Azure-prenumeration skapar du en dokumentinformationsresurs i Azure-portalen för att hämta din nyckel och slutpunkt. När den har distribuerats väljer du Gå till resurs.
- Du behöver nyckeln och slutpunkten från resursen som du skapar för att ansluta ditt program till API:et för dokumentinformation. Du klistrar in nyckeln och slutpunkten i koden senare i snabbstarten.
- Du kan använda den kostnadsfria prisnivån (
F0) för att prova tjänsten och uppgradera senare till en betald nivå för produktion.
- En uppsättning med minst sex former av samma typ. Du använder dessa data för att träna modellen och testa ett formulär. Du kan använda en exempeldatauppsättning (ladda ned och extrahera sample_data.zip) för den här snabbstarten. Ladda upp träningsfilerna till roten för en bloblagringscontainer i ett Azure Storage-konto på standardnivå.
Skapa en dokumentinformationsresurs
Gå till Azure-portalen och skapa en ny dokumentinformationsresurs . Ange följande information i fönstret Skapa :
| Projektinformation | beskrivning |
|---|---|
| Abonnemang | Välj den Azure-prenumeration som har beviljats åtkomst. |
| Resursgrupp | Den Azure-resursgrupp som innehåller din resurs. Du kan skapa en ny grupp eller lägga till den i en befintlig grupp. |
| Region | Platsen för din Azure AI-tjänstresurs. Olika platser kan ge svarstid, men påverkar inte resursens körningstillgänglighet. |
| Name (Name) | Ett beskrivande namn för resursen. Vi rekommenderar att du använder ett beskrivande namn, till exempel MyNameFormRecognizer. |
| Prisnivå | Kostnaden för din resurs beror på vilken prisnivå du väljer och din användning. Mer information finns i information om API-priser. |
| Granska + skapa | Välj knappen Granska + skapa för att distribuera resursen på Azure-portalen. |
Hämta nyckeln och slutpunkten
När dokumentinformationsresursen är klar med distributionen letar du upp och väljer den i listan Alla resurser i portalen. Din nyckel och slutpunkt finns på resursens nyckel- och slutpunktssida under Resurshantering. Spara båda dessa på en tillfällig plats innan du går vidare.
Prova nu
Prova verktyget Exempeletiketter för dokumentinformation online:
Du behöver en Azure-prenumeration (skapa en kostnadsfritt) och en slutpunkt och nyckel för dokumentinformationsresurser för att testa tjänsten Dokumentinformation.
Konfigurera exempeletikettverktyget
Kommentar
Om dina lagringsdata finns bakom ett virtuellt nätverk eller en brandvägg måste du distribuera exempeletiketteringsverktyget för dokumentinformation bakom ditt virtuella nätverk eller brandvägg och bevilja åtkomst genom att skapa en systemtilldelad hanterad identitet.
Du använder Docker-motorn för att köra verktyget Exempeletikettering. Följ de här stegen för att konfigurera Docker-containern. En introduktion till grunderna för Docker och containrar finns i Docker-översikt.
Dricks
OCR-formuläretikettverktyget är också tillgängligt som ett öppen källkod projekt på GitHub. Verktyget är ett TypeScript-webbprogram som skapats med React + Redux. Mer information om eller bidrag finns i lagringsplatsen ocr-formuläretiketteringsverktyg . Om du vill testa verktyget online går du till webbplatsen för exempeletiketteringsverktyget för dokumentinformation.
Installera först Docker på en värddator. Den här guiden visar hur du använder den lokala datorn som värd. Om du vill använda en Docker-värdtjänst i Azure kan du läsa instruktionsguiden Distribuera exempeletiketteringsverktyget .
Värddatorn måste uppfylla följande maskinvarukrav:
Behållare Lägsta Rekommenderas Exempel på märkningsverktyg 2core, 4 GB minne4core, 8 GB minneInstallera Docker på datorn genom att följa lämpliga instruktioner för operativsystemet:
Hämta containern för exempeletiketteringsverktyget med
docker pullkommandot .docker pull mcr.microsoft.com/azure-cognitive-services/custom-form/labeltool:latest-2.1Nu är du redo att köra containern med
docker run.docker run -it -p 3000:80 mcr.microsoft.com/azure-cognitive-services/custom-form/labeltool:latest-2.1 eula=acceptMed det här kommandot blir exempeletikettverktyget tillgängligt via en webbläsare. Gå till
http://localhost:3000.
Kommentar
Du kan också märka dokument och träna modeller med hjälp av REST-API:et för dokumentinformation. Information om hur du tränar och analyserar med REST-API :et finns i Träna med etiketter med hjälp av REST API och Python.
Konfigurera indata
Kontrollera först att alla träningsdokument har samma format. Om du har formulär i flera format ordnar du dem i undermappar efter format. När du tränar måste du dirigera API:et till en undermapp.
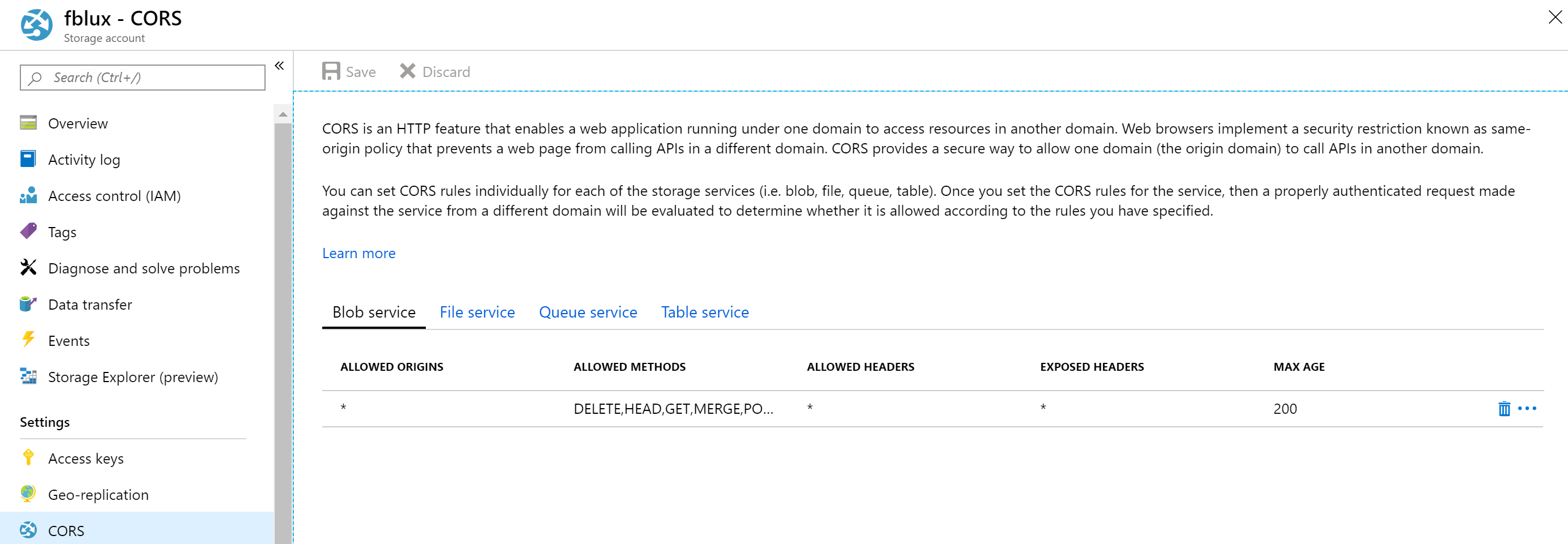
Konfigurera resursdelning mellan domäner (CORS)
Aktivera CORS på ditt lagringskonto. Välj ditt lagringskonto i Azure-portalen och välj sedan fliken CORS i det vänstra fönstret. Fyll i följande värden på den nedre raden. Välj Spara högst upp.
- Tillåtet ursprung = *
- Tillåtna metoder = [markera alla]
- Tillåtna rubriker = *
- Synliga rubriker = *
- Max ålder = 200
Anslut till exempeletiketteringsverktyget
Verktyget Exempeletiketter ansluter till en källa (dina ursprungliga uppladdade formulär) och ett mål (skapade etiketter och utdata).
Anslut ions kan konfigureras och delas mellan projekt. De använder en utökningsbar leverantörsmodell, så att du enkelt kan lägga till nya käll-/målproviders.
Om du vill skapa en ny anslutning väljer du ikonen Ny Anslut ions (plugin) i det vänstra navigeringsfältet.
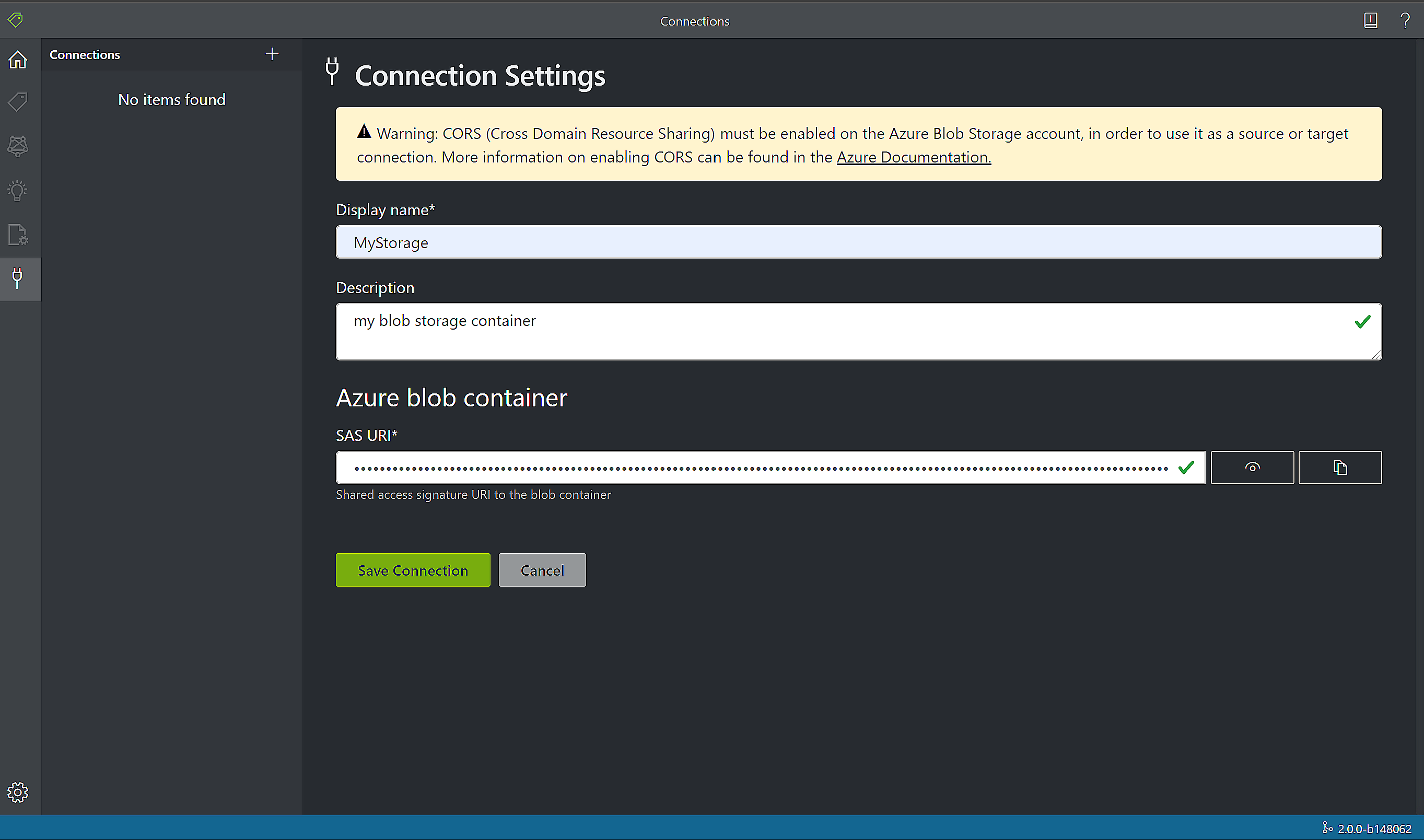
Fyll i fälten med följande värden:
Visningsnamn – anslutningsvisningsnamnet.
Beskrivning – Din projektbeskrivning.
SAS-URL – URL:en för signatur för delad åtkomst (SAS) för din Azure Blob Storage-container. Om du vill hämta SAS-URL:en för dina träningsdata för anpassade modeller går du till lagringsresursen i Azure-portalen och väljer fliken Storage Explorer . Navigera till containern, högerklicka och välj Hämta signatur för delad åtkomst. Det är viktigt att hämta SAS för din container, inte för själva lagringskontot. Kontrollera att behörigheterna Läsa, Skriva, Ta bort och Lista är markerade och klicka på Skapa. Kopiera sedan värdet i URL-avsnittet till en tillfällig plats. Det bör ha formatet:
https://<storage account>.blob.core.windows.net/<container name>?<SAS value>.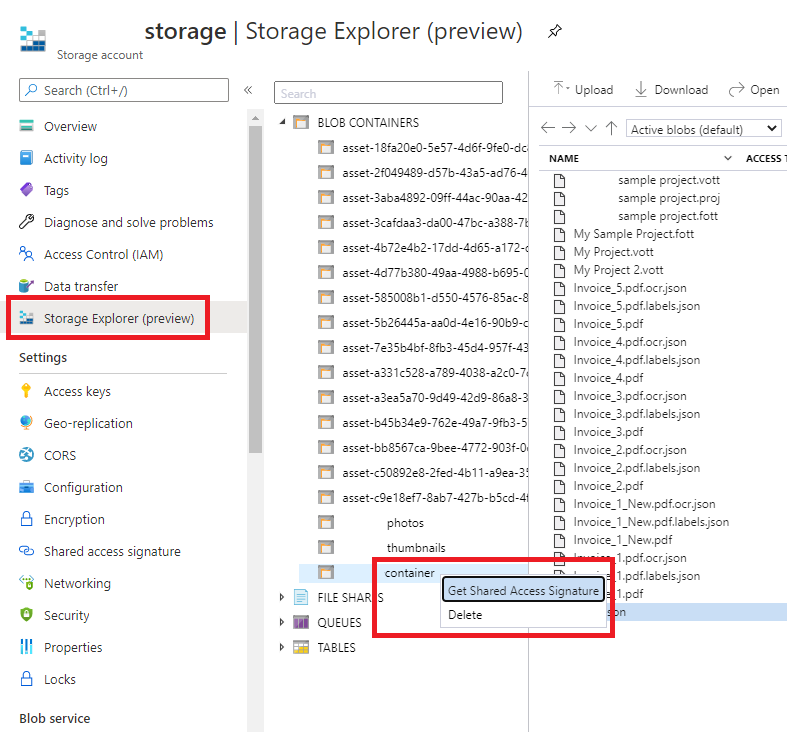
Skapa ett nytt projekt
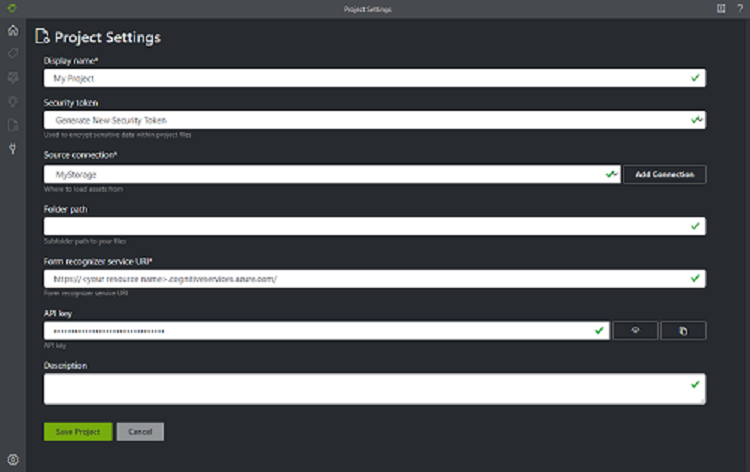
I exempeletikettverktyget lagrar projekten dina konfigurationer och inställningar. Skapa ett nytt projekt och fyll i fälten med följande värden:
- Visningsnamn – projektets visningsnamn
- Säkerhetstoken – Vissa projektinställningar kan innehålla känsliga värden, till exempel nycklar eller andra delade hemligheter. Varje projekt genererar en säkerhetstoken som kan användas för att kryptera/dekryptera känsliga projektinställningar. Du hittar säkerhetstoken i programmet Inställningar genom att välja kugghjulsikonen längst ned i det vänstra navigeringsfältet.
- Käll-Anslut ion – Den Azure Blob Storage-anslutning som du skapade i föregående steg som du vill använda för det här projektet.
- Mappsökväg – Valfritt – Om källformulären finns i en mapp i blobcontainern anger du mappnamnet här
- Uri för Document Intelligence Service – din slutpunkts-URL för dokumentinformation.
- Nyckel – din dokumentinformationsnyckel.
- Beskrivning – valfritt – Projektbeskrivning
Etikettera dina formulär
När du skapar eller öppnar ett projekt öppnas huvudfönstret för taggredigeraren. Taggredigeraren består av tre delar:
- Ett storleksbart v3.0-fönster som innehåller en rullningsbar lista över formulär från källanslutningen.
- Huvudredigerarens fönster där du kan använda taggar.
- Fönstret taggar redigerare som gör det möjligt för användare att ändra, låsa, ordna om och ta bort taggar.
Identifiera text och tabeller
Välj Kör layout i dokument som inte visas i det vänstra fönstret för att hämta text- och tabelllayoutinformationen för varje dokument. Märkningsverktyget ritar avgränsningsrutor runt varje textelement.
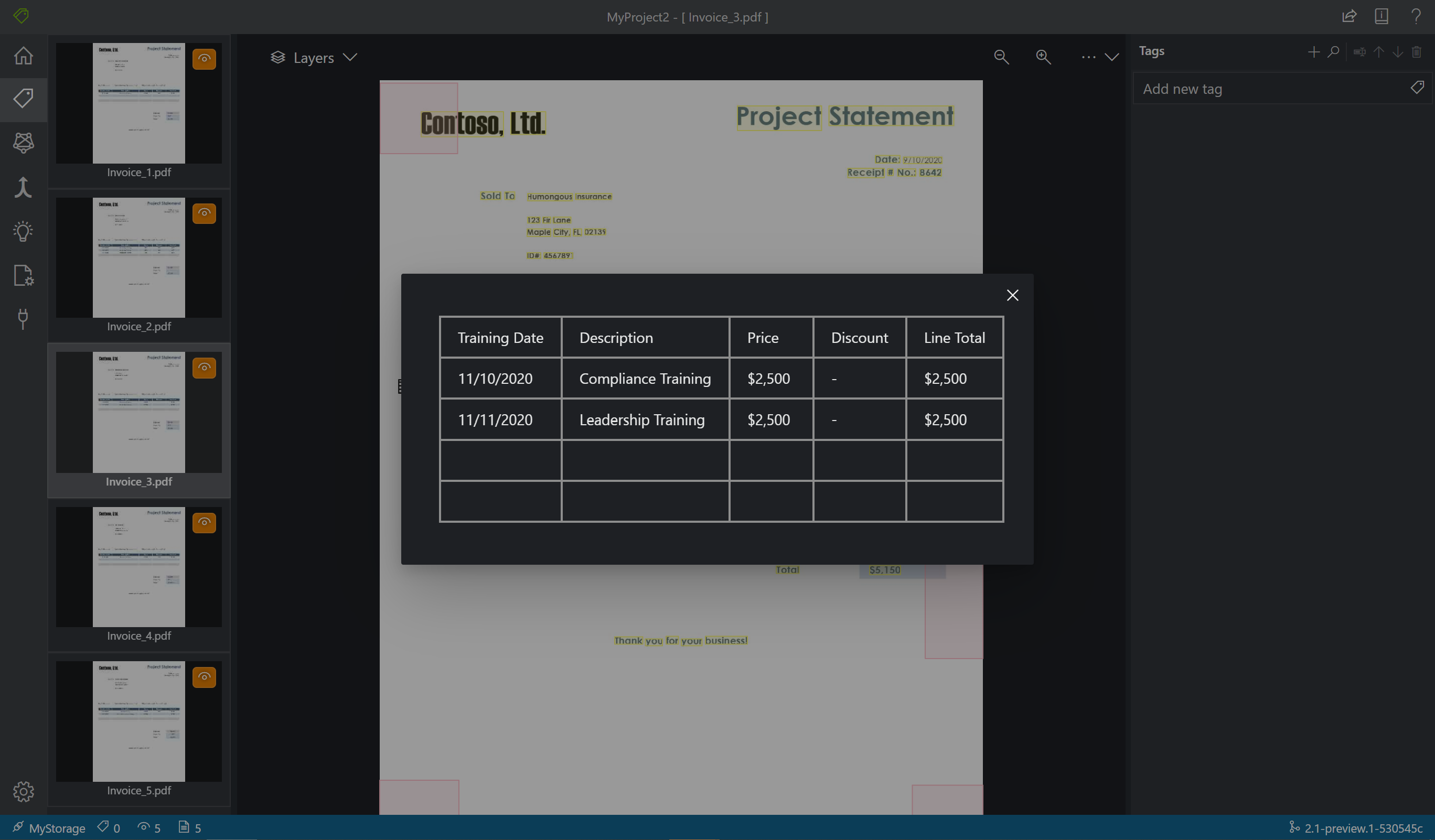
Märkningsverktyget visar också vilka tabeller som har extraherats automatiskt. Välj tabell-/rutnätsikonen till vänster i dokumentet för att se den extraherade tabellen. Eftersom tabellinnehållet extraheras automatiskt i den här snabbstarten etiketterar vi inte tabellinnehållet, utan förlitar oss i stället på automatisk extrahering.
Om träningsdokumentet inte har något ifyllt värde i v2.1 kan du rita en ruta där värdet ska vara. Använd Rita region i det övre vänstra hörnet i fönstret för att göra regionen taggbar.
Använd etiketter på text
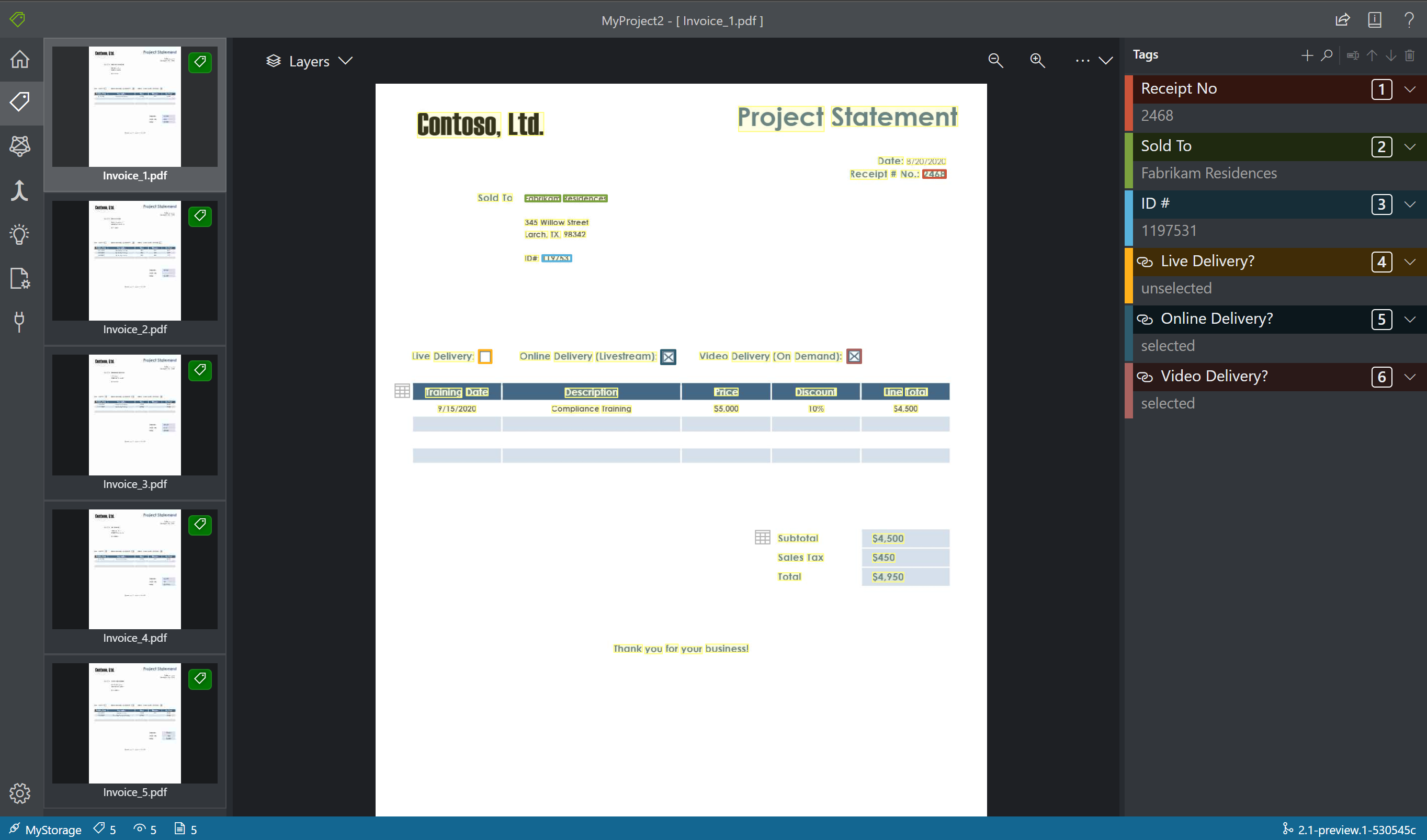
Därefter skapar du taggar (etiketter) och tillämpar dem på de textelement som du vill att modellen ska analysera.
- Börja med att använda fönstret taggar redigerare för att skapa de taggar som du vill identifiera.
- Välj + för att skapa en ny tagg.
- Ange taggnamnet.
- Spara taggen genom att trycka på Retur.
- I huvudredigeraren väljer du ord från de markerade textelementen eller en region som du ritade in.
- Välj den tagg som du vill använda eller tryck på motsvarande tangentbordstangent. Nummernycklarna tilldelas som snabbtangenter för de första 10 taggarna. Du kan ändra ordning på taggarna med hjälp av upp- och nedpilsikonerna i taggredigerarens fönster.
- Följ de här stegen för att märka minst fem av dina formulär.
Dricks
Tänk på följande tips när du etiketterar dina formulär:
- Du kan bara använda en tagg för varje markerat textelement.
- Varje tagg kan bara tillämpas en gång per sida. Om ett värde visas flera gånger i samma formulär skapar du olika taggar för varje instans. Till exempel: "invoice# 1", "invoice# 2" och så vidare.
- Taggar kan inte sträcka sig över flera sidor.
- Etikettvärden som de visas i formuläret. försök inte dela upp ett värde i två delar med två olika taggar. Ett adressfält bör till exempel märkas med en enda tagg även om det sträcker sig över flera rader.
- Inkludera inte nycklar i dina taggade fält – bara värdena.
- Tabelldata bör identifieras automatiskt och kommer att vara tillgängliga i den slutliga utdata-JSON-filen. Men om modellen inte kan identifiera alla dina tabelldata kan du även tagga dessa fält manuellt. Tagga varje cell i tabellen med en annan etikett. Om dina formulär har tabeller med olika antal rader måste du tagga minst ett formulär med den största möjliga tabellen.
- Använd knapparna till höger om + för att söka, byta namn på, ordna om och ta bort taggarna.
- Om du vill ta bort en tillämpad tagg utan att ta bort själva taggen markerar du den taggade rektangeln i dokumentvyn och trycker på borttagningsnyckeln.
Ange taggvärdetyper
Du kan ange den förväntade datatypen för varje tagg. Öppna snabbmenyn till höger om en tagg och välj en typ på menyn. Med den här funktionen kan identifieringsalgoritmen göra antaganden som förbättrar noggrannheten för textidentifiering. Det säkerställer också att de identifierade värdena returneras i ett standardiserat format i de slutliga JSON-utdata. Värdetypsinformation sparas i filen fields.json i samma sökväg som dina etikettfiler.
Följande värdetyper och varianter stöds för närvarande:
string- default,
no-whitespaces,alphanumeric
- default,
number- Standard
currency - Formaterat som ett flyttalvärde.
- Exempel: 1234.98 i dokumentet formateras till 1234,98 på utdata
- Standard
date- default,
dmy,mdy,ymd
- default,
timeinteger- Formaterat som ett heltalsvärde.
- Exempel: 1234.98 i dokumentet formateras till 123498 på utdata.
selectionMark
Kommentar
Se följande regler för datumformatering:
Du måste ange ett format (dmy, mdy, ymd) för att datumformateringen ska fungera.
Följande tecken kan användas som datumavgränsare: , - / . \. Det går inte att använda blanksteg som avgränsare. Till exempel:
- 01,01,2020
- 01-01-2020
- 01/01/2020
Dag och månad kan var och en skrivas som en eller två siffror, och året kan vara två eller fyra siffror:
- 1-1-2020
- 1-01-20
Om en datumsträng har åtta siffror är avgränsaren valfri:
- 01012020
- 01 01 2020
Månaden kan också skrivas som sitt fullständiga eller korta namn. Om namnet används är avgränsare valfria tecken. Formatet kanske känns igen på ett mindre korrekt sätt än andra.
- 01/Jan/2020
- 01Jan2020
- 01 Jan 2020
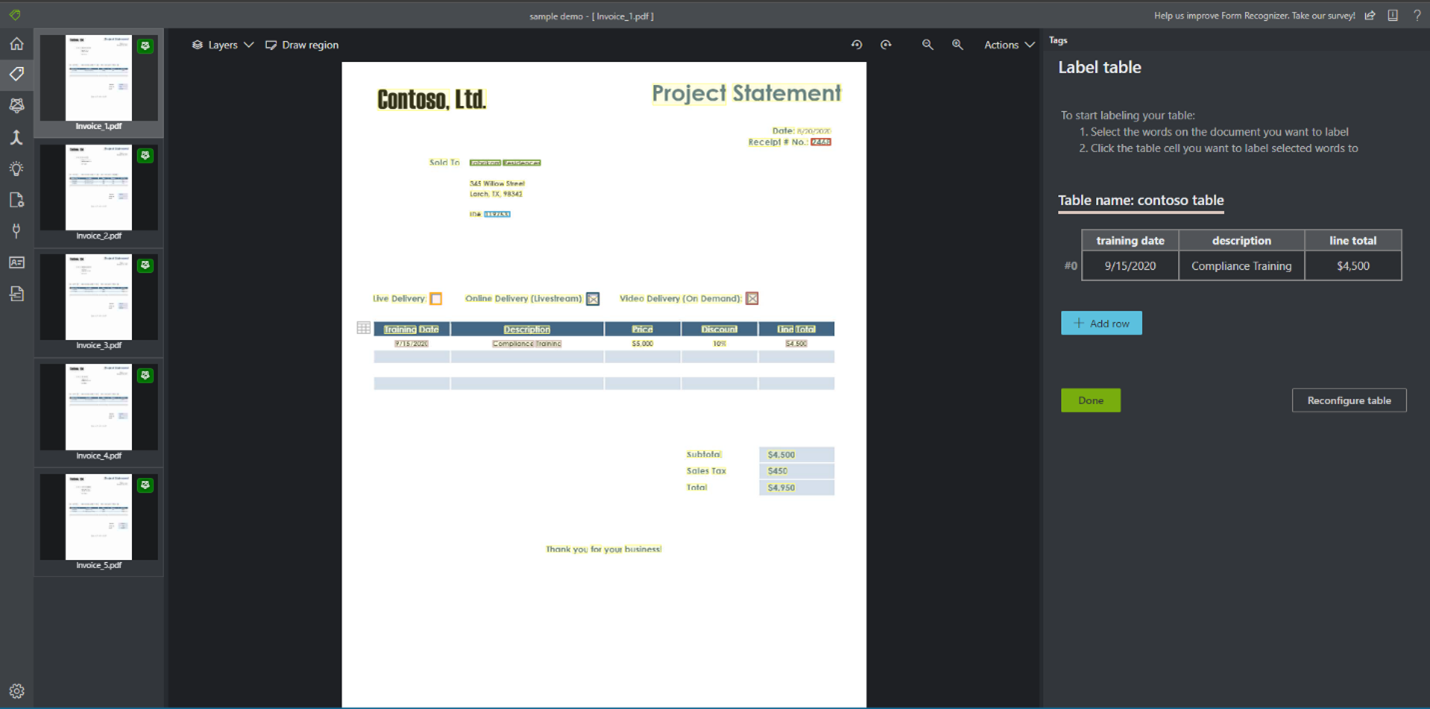
Etiketttabeller (endast v2.1)
Ibland kan dina data lämpar sig bättre för att märkas som en tabell i stället för nyckel/värde-par. I det här fallet kan du skapa en tabelltagg genom att välja Lägg till en ny tabelltagg. Ange om tabellen har ett fast antal rader eller ett variabelt antal rader beroende på dokumentet och definiera schemat.
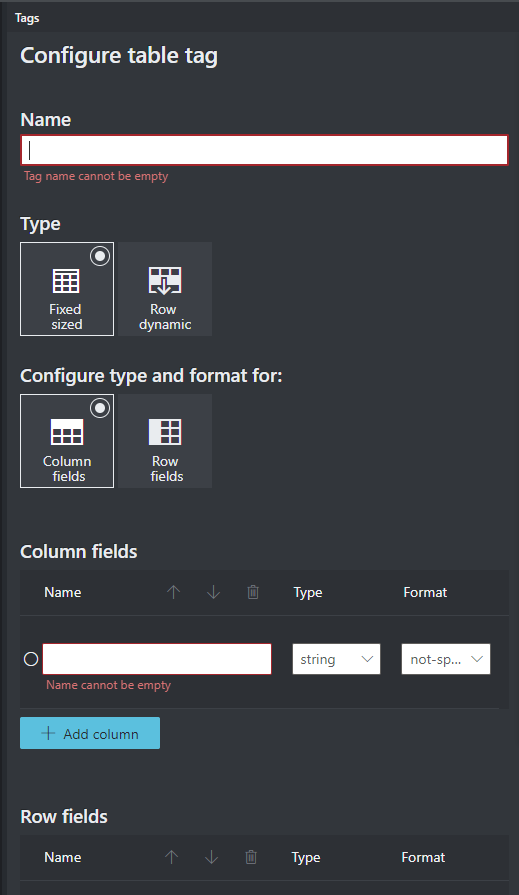
När du har definierat tabelltaggen taggar du cellvärdena.
Träna en anpassad modell
Välj ikonen Träna i det vänstra fönstret för att öppna sidan Träning. Välj sedan knappen Träna för att börja träna modellen. När träningsprocessen är klar visas följande information:
- Modell-ID – ID för modellen som skapades och tränades. Varje träningsanrop skapar en ny modell med sitt eget ID. Kopiera strängen till en säker plats. du behöver det om du vill göra förutsägelseanrop via REST-API:et eller klientbiblioteksguiden.
- Genomsnittlig noggrannhet – modellens genomsnittliga noggrannhet. Du kan förbättra modellens noggrannhet genom att lägga till och märka fler formulär och sedan träna om för att skapa en ny modell. Vi rekommenderar att du börjar med att märka fem formulär och lägga till fler formulär efter behov.
- Listan över taggar och den uppskattade noggrannheten per tagg.
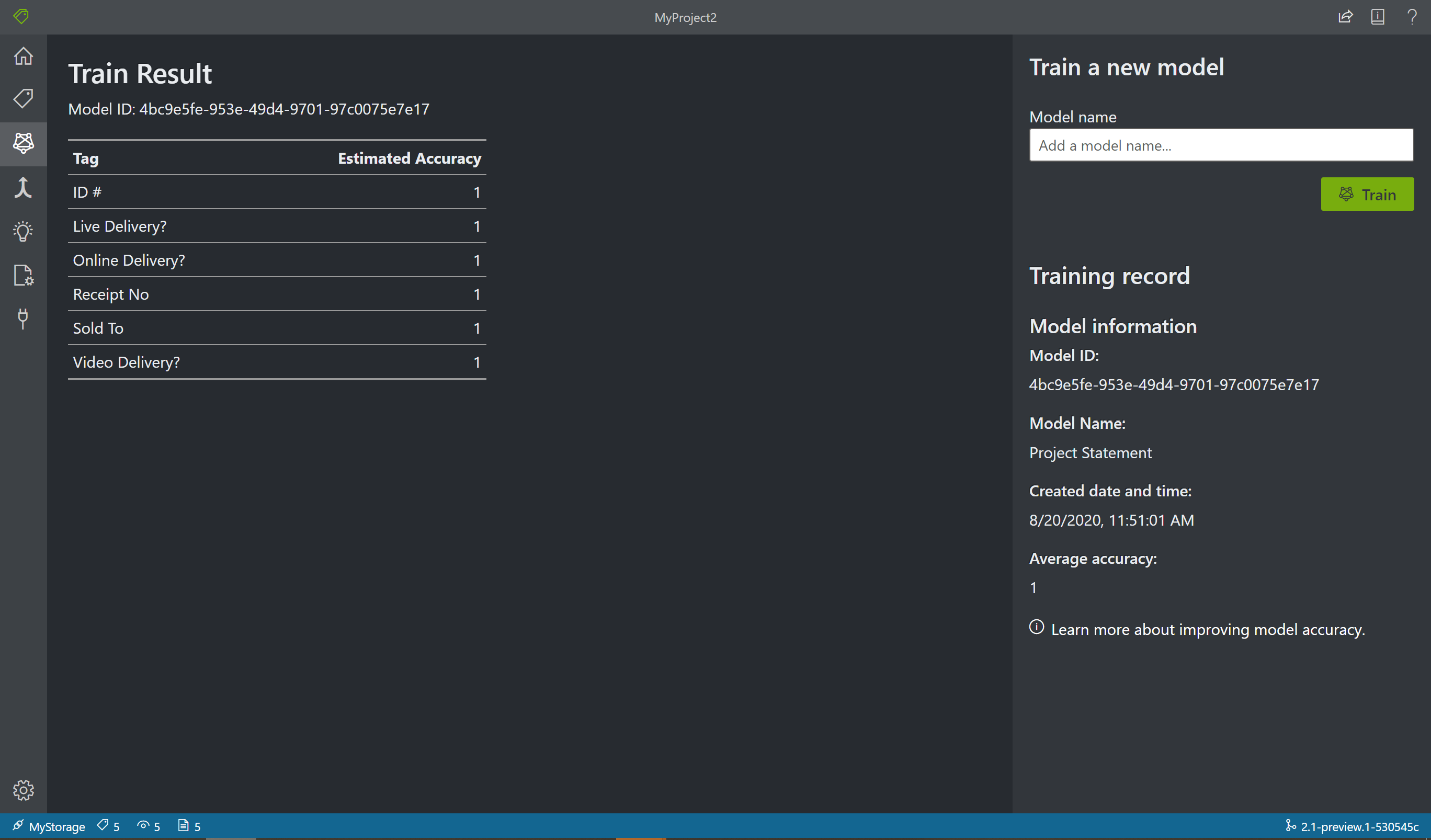
När träningen har slutförts undersöker du värdet Genomsnittlig noggrannhet . Om den är låg bör du lägga till fler indatadokument och upprepa etiketteringsstegen. Dokumenten som du redan har märkt finns kvar i projektindexet.
Dricks
Du kan också köra träningsprocessen med ett REST API-anrop. Mer information om hur du gör detta finns i Träna med etiketter med python.
Skapa tränade modeller
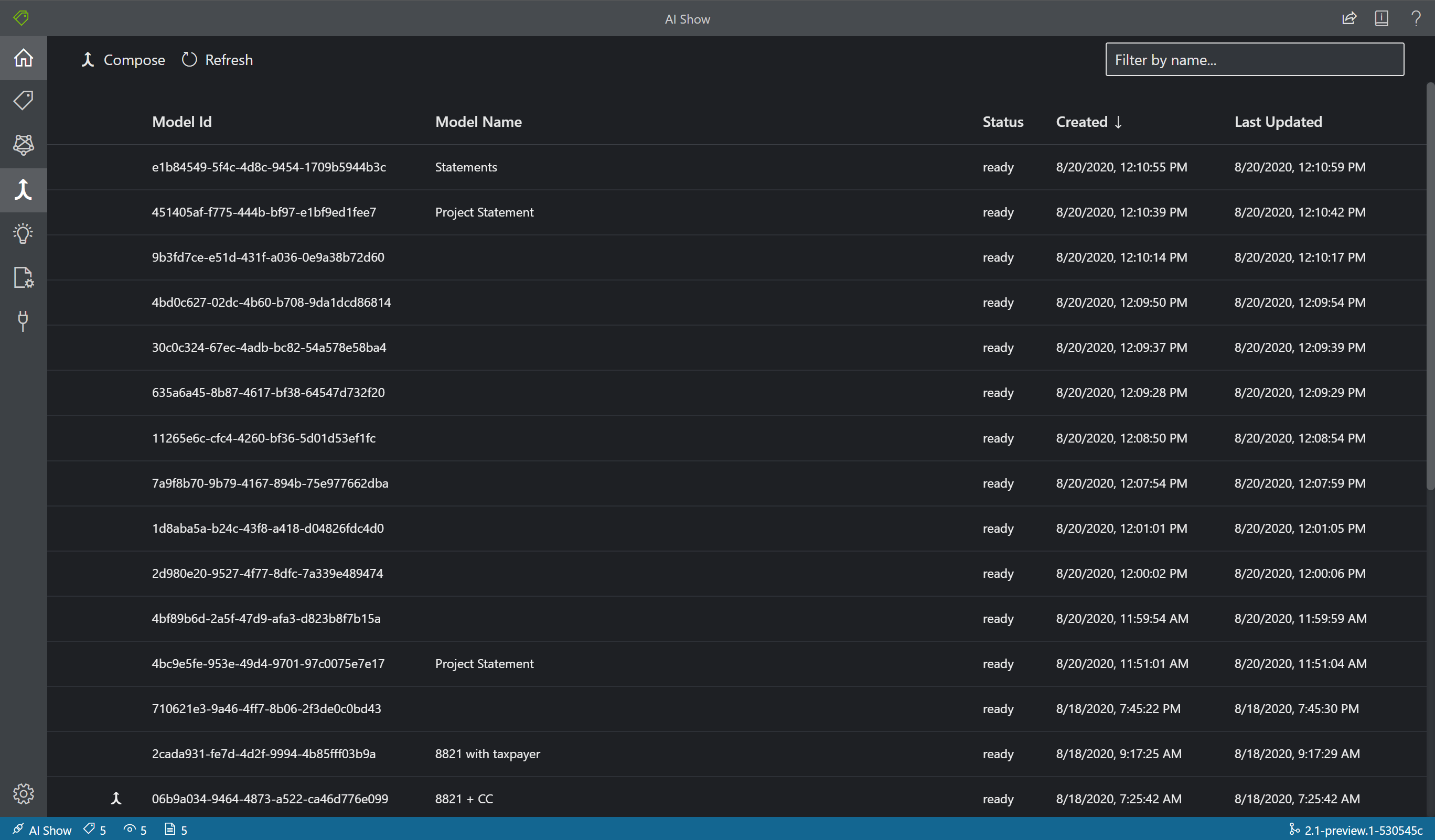
Med Model Compose kan du skapa upp till 200 modeller till ett enda modell-ID. När du anropar Analysera med den sammansatta modelIDklassificerar Dokumentinformation formuläret som du skickade, väljer den bästa matchande modellen och returnerar sedan resultat för den modellen. Den här åtgärden är användbar när inkommande formulär kan tillhöra en av flera mallar.
- Om du vill skapa modeller i verktyget Exempeletiketter väljer du ikonen Modellkompilering (sammanslagningspil) i navigeringsfältet.
- Välj de modeller som du vill skapa tillsammans. Modeller med pilikonen är redan sammansatta modeller.
- Välj knappen Skriv. I popup-fönstret namnger du din nya sammansatta modell och väljer Skriv.
- När åtgärden är klar bör din nyskapade modell visas i listan.
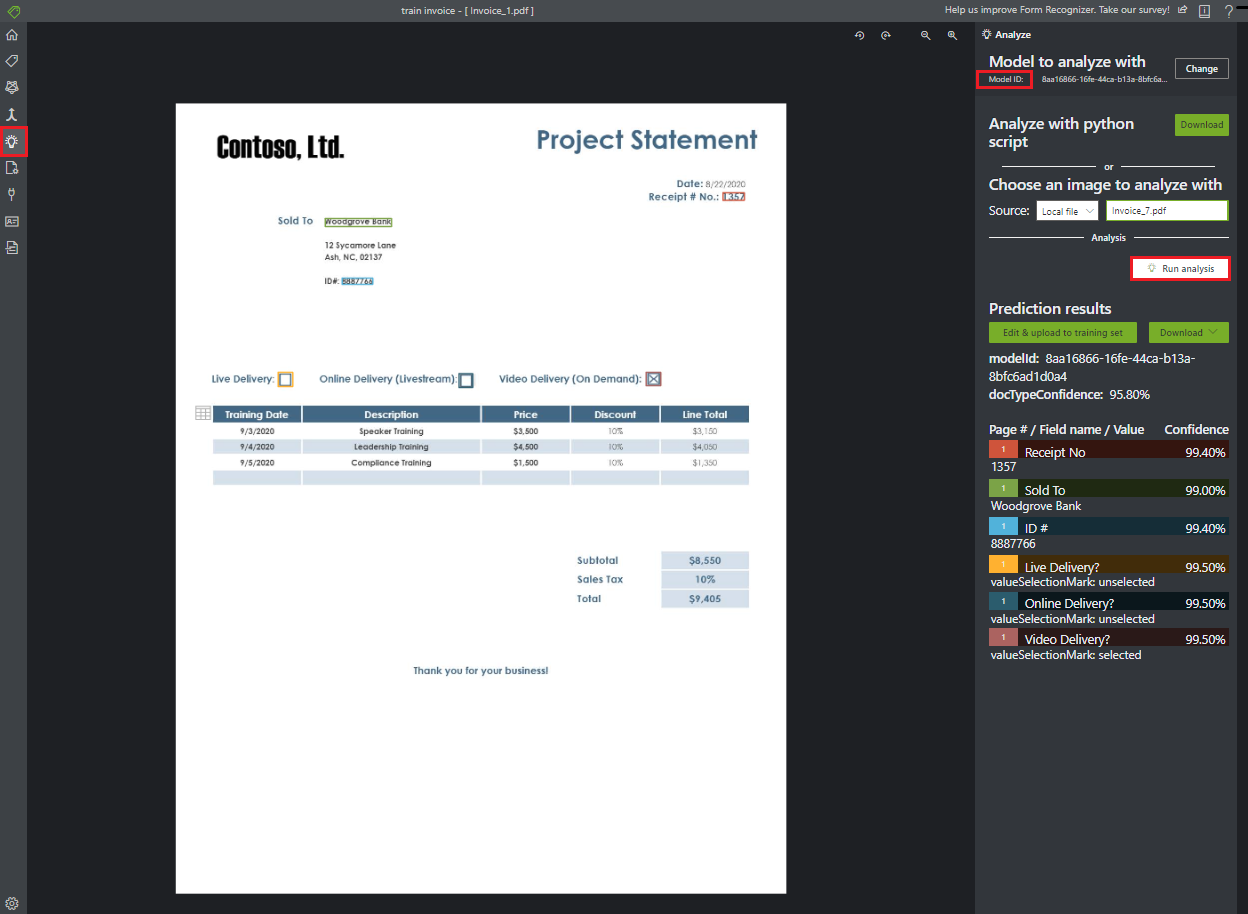
Analysera ett formulär
Välj ikonen Analysera i navigeringsfältet för att testa din modell. Välj lokal källfil. Bläddra efter en fil och välj en fil från exempeldatauppsättningen som du har packat upp i testmappen. Välj sedan knappen Kör analys för att hämta nyckel/värde-par, text- och tabellförutsägelser för formuläret. Verktyget använder taggar i avgränsningsrutor och rapporterar varje taggs förtroende.
Dricks
Du kan också köra Analys-API:et med ett REST-anrop. Mer information om hur du gör detta finns i Träna med etiketter med python.
Förbättra resultaten
Beroende på den rapporterade noggrannheten kanske du vill träna vidare för att förbättra modellen. När du har gjort en förutsägelse undersöker du konfidensvärdena för var och en av de tillämpade taggarna. Om det genomsnittliga noggrannhetsträningsvärdet är högt, men konfidenspoängen är låga (eller om resultaten är felaktiga), lägger du till förutsägelsefilen i träningsuppsättningen, märker den och tränar igen.
Den rapporterade genomsnittliga noggrannheten, konfidenspoängen och den faktiska noggrannheten kan vara inkonsekvent när de analyserade dokumenten skiljer sig från dokument som används i träning. Tänk på att vissa dokument ser likadana ut när de visas av personer men kan se distinkta ut för AI-modellen. Du kan till exempel träna med en formulärtyp som har två varianter, där träningsuppsättningen består av 20 % variant A och 80 % variant B. Under förutsägelsen kommer konfidenspoängen för dokument med variation A sannolikt att vara lägre.
Spara ett projekt och återuppta senare
Om du vill återuppta projektet vid en annan tidpunkt eller i en annan webbläsare måste du spara projektets säkerhetstoken och ange den igen senare.
Hämta autentiseringsuppgifter för projekt
Gå till sidan projektinställningar (skjutreglageikonen) och anteckna namnet på säkerhetstoken. Gå sedan till programinställningarna (kugghjulsikonen), som visar alla säkerhetstoken i din aktuella webbläsarinstans. Leta reda på projektets säkerhetstoken och kopiera dess namn och nyckelvärde till en säker plats.
Återställa autentiseringsuppgifter för projekt
När du vill återuppta projektet måste du först skapa en anslutning till samma bloblagringscontainer. Upprepa stegen för att göra det. Gå sedan till sidan programinställningar (kugghjulsikon) och se om projektets säkerhetstoken finns där. Om det inte är det lägger du till en ny säkerhetstoken och kopierar över ditt tokennamn och din nyckel från föregående steg. Välj Spara för att behålla inställningarna.
Återuppta ett projekt
Gå slutligen till huvudsidan (husikonen) och välj Öppna molnprojekt. Välj sedan bloblagringsanslutningen och välj projektets .fott fil. Programmet läser in alla projektets inställningar eftersom det har säkerhetstoken.
Nästa steg
I den här snabbstarten har du lärt dig hur du använder verktyget Exempeletiketter för dokumentinformation för att träna en modell med manuellt märkta data. Om du vill skapa ett eget verktyg för att märka träningsdata använder du REST-API:er som hanterar etiketterad dataträning.