Den här referensarkitekturen visar hur du använder överföring i neural stil till en video med hjälp av Azure Machine Learning. Formatöverföring är en djupinlärningsteknik som skapar en befintlig bild i stil med en annan bild. Du kan generalisera den här arkitekturen för alla scenarion som använder batchbedömning med djupinlärning.
Arkitektur
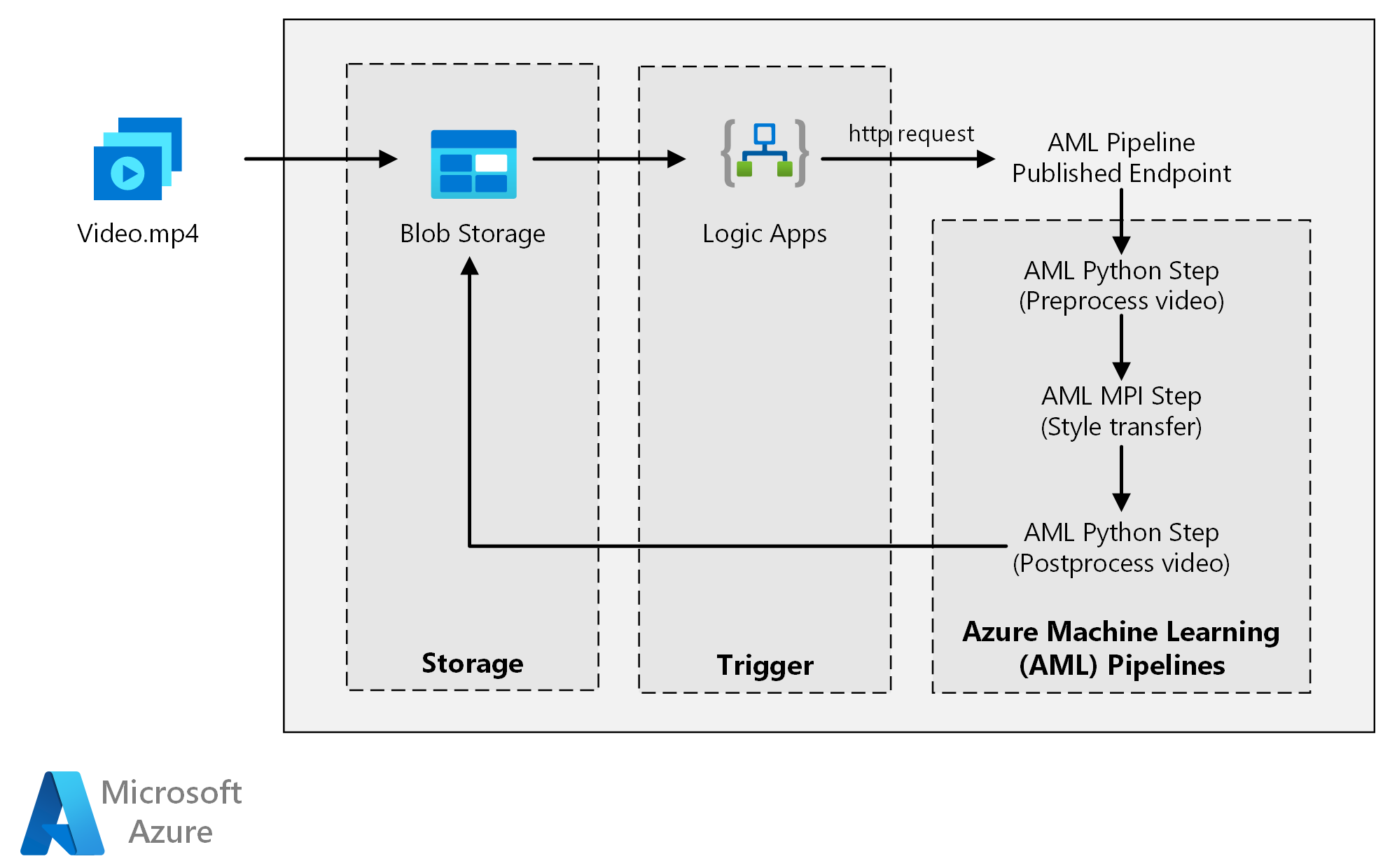
Ladda ned en Visio-fil med den här arkitekturen.
Arbetsflöde
Den här arkitekturen består av följande komponenter.
Compute
Azure Machine Learning använder pipelines för att skapa reproducerbara och lätthanterliga beräkningssekvenser. Det erbjuder också ett hanterat beräkningsmål (där en pipelineberäkning kan köras) som kallas Azure Machine Learning Compute för träning, distribution och bedömning av maskininlärningsmodeller.
Lagring
Azure Blob Storage lagrar alla bilder (indatabilder, formatbilder och utdatabilder). Azure Machine Learning integreras med Blob Storage så att användarna inte behöver flytta data manuellt mellan beräkningsplattformar och bloblagringar. Blob Storage är också kostnadseffektivt för den prestanda som krävs för den här arbetsbelastningen.
Utlösare
Azure Logic Apps utlöser arbetsflödet. När logikappen upptäcker att en blob har lagts till i containern utlöser den Azure Machine Learning-pipelinen. Logic Apps passar bra för den här referensarkitekturen eftersom det är ett enkelt sätt att identifiera ändringar i bloblagring, med en enkel process för att ändra utlösaren.
Förbearbeta och efterbearbeta data
Den här referensarkitekturen använder videofilmer av en orangutang i ett träd.
- Använd FFmpeg för att extrahera ljudfilen från videofilmerna, så att ljudfilen kan sys tillbaka till utdatavideon senare.
- Använd FFmpeg för att dela upp videon i enskilda bildrutor. Bildrutorna bearbetas separat, parallellt.
- Nu kan du använda överföring av neuralt format till varje enskild bildruta parallellt.
- När varje bildruta har bearbetats använder du FFmpeg för att återställa bildrutorna.
- Koppla slutligen tillbaka ljudfilen till de restitchade bilderna.
Komponenter
Lösningsdetaljer
Den här referensarkitekturen är utformad för arbetsbelastningar som utlöses av förekomsten av nya medier i Azure Storage.
Bearbetningen omfattar följande steg:
- Ladda upp en videofil till Azure Blob Storage.
- Videofilen utlöser Azure Logic Apps för att skicka en begäran till den publicerade slutpunkten för Azure Machine Learning-pipelinen.
- Pipelinen bearbetar videon, tillämpar formatöverföring med MPI och efterbearbetar videon.
- Utdata sparas tillbaka till Blob Storage när pipelinen har slutförts.
Potentiella användningsfall
En medieorganisation har en video vars stil de vill ändra för att se ut som en specifik målning. Organisationen vill tillämpa den här stilen på alla bildrutor i videon i tid och på ett automatiserat sätt. Mer bakgrund om överföringsalgoritmer för neurala format finns i Bildformatöverföring med hjälp av convolutional neurala nätverk (PDF).
Att tänka på
Dessa överväganden implementerar grundpelarna i Azure Well-Architected Framework, som är en uppsättning vägledande grundsatser som kan användas för att förbättra kvaliteten på en arbetsbelastning. Mer information finns i Microsoft Azure Well-Architected Framework.
Prestandaeffektivitet
Prestandaeffektivitet handlar om att effektivt skala arbetsbelastningen baserat på användarnas behov. Mer information finns i Översikt över grundpelare för prestandaeffektivitet.
GPU jämfört med CPU
För djupinlärningsarbetsbelastningar presterar GPU:er vanligtvis ut med en betydande mängd, i den utsträckning som ett stort kluster med processorer vanligtvis behövs för att få jämförbara prestanda. Även om du bara kan använda processorer i den här arkitekturen ger GPU:er en mycket bättre kostnads-/prestandaprofil. Vi rekommenderar att du använder den senaste NCv3-serien med GPU-optimerade virtuella datorer.
GPU:er är inte aktiverade som standard i alla regioner. Se till att välja en region med GPU:er aktiverade. Dessutom har prenumerationer en standardkvot på noll kärnor för GPU-optimerade virtuella datorer. Du kan höja den här kvoten genom att öppna en supportbegäran. Kontrollera att din prenumeration har tillräckligt med kvot för att köra din arbetsbelastning.
Parallellisera mellan virtuella datorer och kärnor
När du kör en formatöverföringsprocess som ett batchjobb måste jobben som främst körs på GPU:er parallelliseras mellan virtuella datorer. Två metoder är möjliga: Du kan skapa ett större kluster med virtuella datorer som har en enda GPU eller skapa ett mindre kluster med hjälp av virtuella datorer med många GPU:er.
För den här arbetsbelastningen har dessa två alternativ jämförbara prestanda. Om du använder färre virtuella datorer med fler GPU:er per virtuell dator kan du minska dataflytten. Datavolymen per jobb för den här arbetsbelastningen är dock inte stor, så du ser inte mycket begränsning av Blob Storage.
MPI-steg
När du skapar Azure Machine Learning-pipelinen är ett av de steg som används för att utföra parallell beräkning MPI-steget (gränssnitt för meddelandebearbetning). MPI-steget hjälper till att dela upp data jämnt mellan tillgängliga noder. MPI-steget körs inte förrän alla begärda noder är klara. Om en nod misslyckas eller blir förinstallerad (om det är en virtuell dator med låg prioritet) måste MPI-steget köras igen.
Säkerhet
Säkerhet ger garantier mot avsiktliga attacker och missbruk av dina värdefulla data och system. Mer information finns i Översikt över säkerhetspelare. Det här avsnittet innehåller överväganden för att skapa säkra lösningar.
Begränsa åtkomsten till Azure Blob Storage
I den här referensarkitekturen är Azure Blob Storage den viktigaste lagringskomponenten som måste skyddas. Baslinjedistributionen som visas på GitHub-lagringsplatsen använder lagringskontonycklar för att komma åt bloblagringen. Om du vill ha ytterligare kontroll och skydd bör du överväga att använda en signatur för delad åtkomst (SAS) i stället. Detta ger begränsad åtkomst till objekt i lagringen, utan att behöva hårdkoda kontonycklarna eller spara dem i klartext. Den här metoden är särskilt användbar eftersom kontonycklar visas i klartext i logikappens designergränssnitt. Att använda en SAS hjälper också till att säkerställa att lagringskontot har rätt styrning och att åtkomst endast beviljas till de personer som är avsedda att ha det.
För scenarier med känsligare data kontrollerar du att alla dina lagringsnycklar är skyddade, eftersom dessa nycklar ger fullständig åtkomst till alla indata och utdata från arbetsbelastningen.
Datakryptering och dataförflyttning
Den här referensarkitekturen använder formatöverföring som ett exempel på en batchbedömningsprocess. För mer datakänsliga scenarier bör data i lagringen krypteras i vila. Varje gång data flyttas från en plats till en annan använder du Transport Layer Security (TSL) för att skydda dataöverföringen. Mer information finns i Säkerhetsguide för Azure Storage.
Skydda beräkningen i ett virtuellt nätverk
När du distribuerar machine learning-beräkningsklustret kan du konfigurera klustret så att det etableras i ett undernät i ett virtuellt nätverk. Med det här undernätet kan beräkningsnoderna i klustret kommunicera säkert med andra virtuella datorer.
Skydda mot skadlig aktivitet
I scenarier där det finns flera användare kontrollerar du att känsliga data skyddas mot skadlig aktivitet. Observera följande försiktighetsåtgärder och överväganden om andra användare får åtkomst till den här distributionen för att anpassa indata:
- Använd rollbaserad åtkomstkontroll i Azure (RBAC) för att begränsa användarnas åtkomst till endast de resurser de behöver.
- Etablera två separata lagringskonton. Lagra indata och utdata i det första kontot. Externa användare kan få åtkomst till det här kontot. Lagra körbara skript och utdataloggfiler i det andra kontot. Externa användare bör inte ha åtkomst till det här kontot. Den här separationen säkerställer att externa användare inte kan ändra körbara filer (för att mata in skadlig kod) och inte har åtkomst till loggfiler som kan innehålla känslig information.
- Skadliga användare kan utföra en DDoS-attack på jobbkön eller mata in felaktiga giftmeddelanden i jobbkön, vilket gör att systemet låser sig eller orsakar borttagningsfel.
Kostnadsoptimering
Kostnadsoptimering handlar om att titta på sätt att minska onödiga utgifter och förbättra drifteffektiviteten. Mer information finns i Översikt över kostnadsoptimeringspelare.
Jämfört med komponenterna för lagring och schemaläggning dominerar de beräkningsresurser som används i den här referensarkitekturen överlägset vad gäller kostnader. En av de största utmaningarna är att effektivt parallellisera arbetet över ett kluster med GPU-aktiverade datorer.
Azure Machine Learning Compute-klusterstorleken kan automatiskt skalas upp och ned beroende på jobben i kön. Du kan aktivera autoskalning programmatiskt genom att ange de minsta och högsta noderna.
För arbete som inte kräver omedelbar bearbetning konfigurerar du autoskalning så att standardtillståndet (minimum) är ett kluster med noll noder. Med den här konfigurationen börjar klustret med noll noder och skalas bara upp när det identifierar jobb i kön. Om batchbedömningsprocessen bara sker några gånger om dagen eller mindre resulterar den här inställningen i betydande kostnadsbesparingar.
Automatisk skalning kanske inte är lämpligt för batchjobb som sker för nära varandra. Den tid det tar för ett kluster att starta och spinna ned medför också en kostnad, så om en batcharbetsbelastning börjar bara några minuter efter att det tidigare jobbet har avslutats kan det vara mer kostnadseffektivt att hålla klustret igång mellan jobben.
Azure Machine Learning Compute stöder också virtuella datorer med låg prioritet, vilket gör att du kan köra din beräkning på rabatterade virtuella datorer, med förbehållet att de kan föregripas när som helst. Virtuella datorer med låg prioritet är idealiska för icke-kritiska batchbedömningsarbetsbelastningar.
Övervaka batchjobb
När du kör jobbet är det viktigt att övervaka förloppet och se till att jobbet fungerar som förväntat. Det kan dock vara en utmaning att övervaka över ett kluster med aktiva noder.
Om du vill kontrollera klustrets övergripande tillstånd går du till Machine Learning-tjänsten i Azure-portalen för att kontrollera tillståndet för noderna i klustret. Om en nod är inaktiv eller om ett jobb har misslyckats sparas felloggarna i Blob Storage och är också tillgängliga i Azure-portalen.
Övervakning kan utökas ytterligare genom att ansluta loggar till Application Insights eller genom att köra separata processer för att söka efter tillståndet för klustret och dess jobb.
Logga med Azure Machine Learning
Azure Machine Learning loggar automatiskt alla stdout/stderr till det associerade Blob Storage-kontot. Om inget annat anges etablerar din Azure Machine Learning-arbetsyta automatiskt ett lagringskonto och dumpar dina loggar till det. Du kan också använda ett lagringsnavigeringsverktyg som Azure Storage Explorer, vilket är ett enklare sätt att navigera i loggfiler.
Distribuera det här scenariot
Om du vill distribuera den här referensarkitekturen följer du stegen som beskrivs i GitHub-lagringsplatsen.
Du kan också distribuera en batchbedömningsarkitektur för djupinlärningsmodeller med hjälp av Azure Kubernetes Service. Följ stegen som beskrivs i den här GitHub-lagringsplatsen.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudförfattare:
- Jian Tang | Programhanteraren II
Om du vill se icke-offentliga LinkedIn-profiler loggar du in på LinkedIn.
Nästa steg
- Batchbedömning av Spark-modeller på Azure Databricks
- Batchbedömning av Python-modeller i Azure
- Batchbedömning med R-modeller för prognostisering av försäljning