Vad är bildanalys?
Azure AI Vision Image Analysis-tjänsten kan extrahera en mängd olika visuella funktioner från dina bilder. Den kan till exempel avgöra om en bild innehåller vuxet innehåll, hitta specifika varumärken eller objekt eller hitta mänskliga ansikten.
Den senaste versionen av Image Analysis, 4.0, som nu är allmänt tillgänglig, har nya funktioner som synkron OCR och personidentifiering. Vi rekommenderar att du använder den här versionen framöver.
Du kan använda bildanalys via ett klientbiblioteks-SDK eller genom att anropa REST-API:et direkt. Följ snabbstarten för att komma igång.
Du kan också prova funktionerna i Bildanalys snabbt och enkelt i webbläsaren med hjälp av Vision Studio.
Den här dokumentationen innehåller följande typer av artiklar:
- Snabbstarterna är stegvisa instruktioner som gör att du kan göra anrop till tjänsten och få resultat på kort tid.
- Instruktionsguiderna innehåller instruktioner för att använda tjänsten på mer specifika eller anpassade sätt.
- De konceptuella artiklarna innehåller djupgående förklaringar av tjänstens funktioner och funktioner.
- Självstudierna är längre guider som visar hur du använder den här tjänsten som en komponent i bredare affärslösningar.
Om du vill ha en mer strukturerad metod följer du en utbildningsmodul för bildanalys.
Bildanalysversioner
Viktigt!
Välj den version av API:et för bildanalys som passar dina behov bäst.
| Version | Tillgängliga funktioner | Rekommendation |
|---|---|---|
| version 4.0 | Läs text, bildtexter, kompakta bildtext, taggar, objektidentifiering, anpassad bildklassificering/objektidentifiering, Personer, smart gröda | Bättre modeller; använd version 4.0 om den stöder ditt användningsfall. |
| version 3.2 | Taggar, Objekt, Beskrivningar, Varumärken, Ansikten, Bildtyp, Färgschema, Landmärken, Kändisar, Vuxet innehåll, Smart gröda | Bredare utbud av funktioner; använd version 3.2 om ditt användningsfall ännu inte stöds i version 4.0 |
Vi rekommenderar att du använder API:et bildanalys 4.0 om det stöder ditt användningsfall. Använd version 3.2 om ditt användningsfall ännu inte stöds av 4.0.
Du måste också använda version 3.2 om du vill göra bildtext och visionsresursen ligger utanför dessa Azure-regioner: USA, östra, Frankrike, centrala, Korea, centrala, Europa, norra, Sydostasien, Europa, västra och USA, östra, Asien, östra. Avbildningsfunktionen bildtext i Bildanalys 4.0 stöds bara i dessa Azure-regioner. Bild bildtext i version 3.2 är tillgänglig i alla Azure AI Vision-regioner.
Analyze Image (Analysera bild)
Du kan analysera bilder för att ge insikter om deras visuella funktioner och egenskaper. Alla funktioner i den här listan tillhandahålls av API:et Analysera bild. Följ en snabbstart för att komma igång.
| Name | beskrivning | Konceptsida |
|---|---|---|
| Modellanpassning (endast v4.0 förhandsversion) | Du kan skapa och träna anpassade modeller för att göra bildklassificering eller objektidentifiering. Ta med egna bilder, märk dem med anpassade taggar och Bildanalys tränar en modell som är anpassad för ditt användningsfall. | Modellanpassning |
| Läsa text från bilder (endast v4.0) | Version 4.0 förhandsgranskning av bildanalys ger möjlighet att extrahera läsbar text från bilder. Jämfört med asynkron Visuellt innehåll 3.2-läs-API erbjuder den nya versionen den välbekanta Read OCR-motorn i ett enhetligt synkront API som gör det enkelt att få OCR tillsammans med andra insikter i ett enda API-anrop. | OCR för bilder |
| Identifiera personer i bilder (endast v4.0) | Version 4.0 av bildanalys ger möjlighet att identifiera personer som visas i bilder. Koordinaterna för avgränsningsrutan för varje identifierad person returneras tillsammans med en konfidenspoäng. | Personer identifiering |
| Generera bildtext | Generera en bildtext av en bild på ett läsbart språk med hjälp av fullständiga meningar. Visuellt innehåll algoritmer genererar bildtext baserat på de objekt som identifieras i bilden. Avbildningsmodellen version 4.0 bildtext är en mer avancerad implementering och fungerar med ett bredare utbud av indatabilder. Den är endast tillgänglig i följande geografiska regioner: USA, östra, Frankrike, centrala, Korea, centrala, Europa, norra, Sydostasien, Europa, västra, USA, västra. Med version 4.0 kan du också använda kompakt bildtext, vilket genererar detaljerade bildtext för enskilda objekt som finns i bilden. API:et returnerar avgränsningsrutans koordinater (i bildpunkter) för varje objekt som finns i bilden, plus en bildtext. Du kan använda den här funktionen för att generera beskrivningar av separata delar av en bild. 
|
Generera bildtext (v3.2) (v4.0) |
| Upptäcka objekt | Objektidentifiering liknar taggar, men API:n returnerar avgränsningsfältets koordinater för varje tagg som tillämpas. Om en bild till exempel innehåller en hund, katt och person, visar åtgärden Identifiera dessa objekt tillsammans med deras koordinater i bilden. Du kan använda den här funktionen till att bearbeta ytterligare relationer mellan objekt i en bild. Du får även veta när det finns flera instanser av samma tagg i en bild. 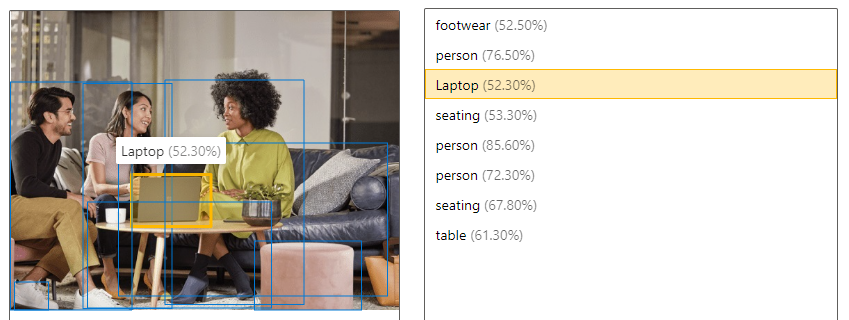
|
Identifiera objekt (v3.2) (v4.0) |
| Tagga visuella egenskaper | Identifiera och tagga visuella egenskaper i en bild, från tusentals identifierbara objekt, levande varelser, landskap och åtgärder. När taggarna är tvetydiga eller inte allmänt kända ger API-svaret tips för att klargöra taggens kontext. Taggar är inte begränsade till huvudföremålet på bilden, som till exempel en person i förgrunden, utan finns även för saker som bakgrund (inomhus eller utomhus), möbler, verktyg, växter, djur, accessoarer, saker och så vidare.
|
Tagga visuella funktioner (v3.2) (v4.0) |
| Få området av intresse / smart gröda | Analysera innehållet i en bild för att returnera koordinaterna för det intresseområde som matchar ett angivet proportioner. Visuellt innehåll returnerar avgränsningsrutans koordinater för regionen, så att det anropande programmet kan ändra den ursprungliga avbildningen efter behov. Den smarta beskärningsmodellen version 4.0 är en mer avancerad implementering och fungerar med ett bredare utbud av indatabilder. Den är endast tillgänglig i följande geografiska regioner: USA, östra, Frankrike, centrala, Korea, centrala, Europa, norra, Sydostasien, Europa, västra, USA, västra. |
Generera en miniatyrbild (v3.2) (v4.0 förhandsversion) |
| Identifiera varumärken (endast v3.2) | Identifiera varumärken i bilder och videor från en databas med tusentals olika globala logotyper. Du kan använda den här funktionen för att till exempel identifiera vilka varumärken som är mest populära på sociala medier eller förekommer oftast i medieproduktplacering. | Identifiera varumärken |
| Kategorisera en bild (endast v3.2) | Identifiera och kategorisera en hel bild med hjälp av en kategoritaxonomi med överordnade/underordnade ärftliga hierarkier. Kategorier kan användas fristående eller med våra nya taggningsmodeller. Engelska är för närvarande det enda språket som stöds för att tagga och kategorisera bilder. |
Kategorisera en bild |
| Identifiera ansikten (endast v3.2) | Identifiera ansikten i en bild och ange information om varje identifierat ansikte. Azure AI Vision returnerar koordinater, rektangel, kön och ålder för varje identifierat ansikte. Du kan också använda det dedikerade ansikts-API :et för dessa ändamål. Det ger mer detaljerad analys, till exempel ansiktsidentifiering och poseidentifiering. |
Identifiera ansikten |
| Identifiera avbildningstyper (endast v3.2) | Identifiera olika kännetecken om en bild som t. ex. om det är en teckning eller om den kan vara ClipArt. | Identifiera bildtyper |
| Identifiera domänspecifikt innehåll (endast v3.2) | Använd domänmodeller för att upptäcka och identifiera domänspecifikt innehåll i en bild, till exempel kändisar och landmärken. Om en bild till exempel innehåller personer kan Azure AI Vision använda en domänmodell för kändisar för att avgöra om de personer som identifieras i bilden är kända kändisar. | Identifiera domänspecifikt innehåll |
| Identifiera färgschemat (endast v3.2) | Analysera användningen av färg i en bild. Azure AI Vision kan avgöra om en bild är svartvit eller färg och, för färgbilder, identifiera de dominerande färgerna och dekorfärgerna. | Identifiera färgschema |
| Moderera innehåll i bilder (endast v3.2) | Du kan använda Azure AI Vision för att identifiera vuxet innehåll i en bild och returnera konfidenspoäng för olika klassificeringar. Tröskelvärdet för att flagga innehåll kan anges på en glidande skala för att passa dina inställningar. | Identifiera innehåll som är olämpligt för barn |
Dricks
Du kan använda funktionerna För att läsa text och objektidentifiering i bildanalys via Azure OpenAI-tjänsten . Med modellen GPT-4 Turbo with Vision kan du chatta med en AI-assistent som kan analysera de bilder du delar, och alternativet Vision Enhancement använder bildanalys för att ge AI-hjälpen mer information (läsbar text och objektplatser) om bilden. Mer information finns i snabbstarten GPT-4 Turbo med vision.
Produktigenkänning (endast v4.0 förhandsversion)
Med API:erna för produktigenkänning kan du analysera foton av hyllor i en butik. Du kan identifiera förekomsten eller frånvaron av produkter och få deras avgränsningsboxkoordinater. Använd den i kombination med modellanpassning för att träna en modell för att identifiera dina specifika produkter. Du kan också jämföra produktigenkänningsresultat med butikens planogramdokument.
Multimodala inbäddningar (endast v4.0)
API:erna för multimodala inbäddningar möjliggör vektorisering av bilder och textfrågor. De konverterar bilder till koordinater i ett flerdimensionellt vektorutrymme. Sedan kan inkommande textfrågor också konverteras till vektorer och bilder kan matchas med texten baserat på semantisk närhet. På så sätt kan användaren söka i en uppsättning bilder med hjälp av text, utan att behöva använda bildtaggar eller andra metadata. Semantisk närhet ger ofta bättre resultat i sökningen.
API:et 2024-02-01 innehåller en flerspråkig modell som stöder textsökning på 102 språk. Den ursprungliga modellen endast på engelska är fortfarande tillgänglig, men den kan inte kombineras med den nya modellen i samma sökindex. Om du har vektoriserat text och bilder med modellen endast på engelska är dessa vektorer inte kompatibla med flerspråkiga text- och bildvektorer.
Dessa API:er är endast tillgängliga i följande geografiska regioner: USA, östra, Frankrike, centrala, Korea, centrala, Europa, norra, Sydostasien, Europa, västra, USA, västra.
Bakgrundsborttagning (endast v4.0 förhandsversion)
Bildanalys 4.0 (förhandsversion) ger möjlighet att ta bort bakgrunden till en bild. Den här funktionen kan antingen mata ut en bild av det identifierade förgrundsobjektet med en transparent bakgrund eller en alfamatisk bild i gråskala som visar opaciteten för det identifierade förgrundsobjektet.
| Originalbild | Med bakgrund borttagen | Alfa-matt |
|---|---|---|

|

|

|
Bildkrav
Bildanalys fungerar endast på bilder som uppfyller följande krav:
- Bilden måste vara i formatet JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF eller MPO
- Filstorleken måste vara mindre än 20 megabyte (MB)
- Bildens dimensioner måste vara större än 50 x 50 bildpunkter och mindre än 16 000 x 16 000 bildpunkter
Dricks
Indatakraven för multimodala inbäddningar skiljer sig åt och visas i Multimodal-inbäddningar
Datasekretess och säkerhet
Precis som med alla Azure AI-tjänster bör utvecklare som använder Azure AI Vision-tjänsten vara medvetna om Microsofts principer för kunddata. Mer information finns på sidan Azure AI-tjänster i Microsoft Trust Center.
Nästa steg
Kom igång med bildanalys genom att följa snabbstartsguiden på önskat utvecklingsspråk: