Skapa och köra Azure Databricks-jobb
Den här artikeln beskriver hur du skapar och kör Azure Databricks-jobb med hjälp av användargränssnittet för jobb.
Mer information om konfigurationsalternativ för jobb och hur du redigerar dina befintliga jobb finns i Konfigurera inställningar för Azure Databricks-jobb.
Information om hur du hanterar och övervakar jobbkörningar finns i Visa och hantera jobbkörningar.
Information om hur du skapar ditt första arbetsflöde med ett Azure Databricks-jobb finns i snabbstarten.
Viktigt!
- En arbetsyta är begränsad till 1 000 samtidiga aktivitetskörningar. Ett
429 Too Many Requests-svar returneras när du begär en körning som inte kan starta omedelbart. - Antalet jobb som en arbetsyta kan skapa på en timme är begränsat till 1 0000 (inklusive "kör skicka"). Den här gränsen påverkar även jobb som skapas av REST API och notebook-flöden.
Skapa och köra jobb med hjälp av CLI, API eller notebook-filer
- Mer information om hur du använder Databricks CLI för att skapa och köra jobb finns i Vad är Databricks CLI?.
- Mer information om hur du använder jobb-API:et för att skapa och köra jobb finns i Jobb i REST API-referensen.
- Information om hur du kör och schemalägger jobb direkt i en Databricks-notebook-fil finns i Skapa och hantera schemalagda notebook-jobb.
Skapa ett jobb
Gör något av följande:
- Klicka på
 Arbetsflöden i sidofältet och klicka på .
Arbetsflöden i sidofältet och klicka på .
- I sidofältet klickar du på
 Nytt och väljer Jobb.
Nytt och väljer Jobb.
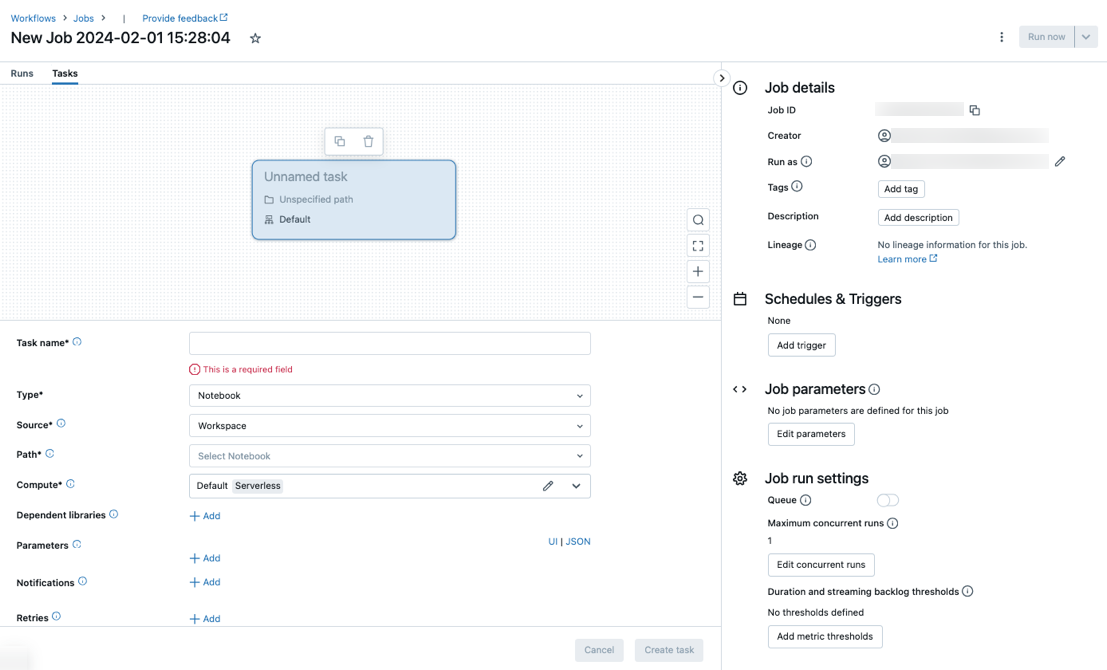
Fliken Uppgifter visas med dialogrutan Skapa aktivitet tillsammans med panelen Jobbinformation som innehåller inställningar på jobbnivå.
- Klicka på
Ersätt Nytt jobb... med ditt jobbnamn.
Ange ett namn på aktiviteten i fältet Aktivitetsnamn .
I listrutan Typ väljer du vilken typ av uppgift som ska köras. Se Alternativ för aktivitetstyp.
Konfigurera klustret där uppgiften körs. I den nedrullningsbara menyn Kluster väljer du antingen Nytt jobbkluster eller Befintliga all-Purpose-kluster.
- Nytt jobbkluster: Klicka på Redigera i den nedrullningsbara menyn Kluster och slutför klusterkonfigurationen.
- Befintligt all-purpose-kluster: Välj ett befintligt kluster i den nedrullningsbara menyn Kluster . Om du vill öppna klustret på en ny sida klickar du på
 ikonen till höger om klusternamnet och beskrivningen.
ikonen till höger om klusternamnet och beskrivningen.
Mer information om hur du väljer och konfigurerar kluster för att köra uppgifter finns i Använda Azure Databricks-beräkning med dina jobb.
Om du vill lägga till beroende bibliotek klickar du på + Lägg tillbredvid Beroende bibliotek. Se Konfigurera beroende bibliotek.
Du kan skicka parametrar för din uppgift. Information om kraven för formatering och överföring av parametrar finns i Skicka parametrar till en Azure Databricks-jobbaktivitet.
Om du vill ta emot meddelanden om aktivitetsstart, lyckad aktivitet eller fel klickar du på + Lägg tillbredvid E-postmeddelanden. Meddelanden om fel skickas vid inledande aktivitetsfel och eventuella efterföljande återförsök. Om du vill filtrera meddelanden och minska antalet e-postmeddelanden som skickas kontrollerar du Avaktivera meddelanden för överhoppade körningar, Stänga av meddelanden för avbrutna körningar eller Stäng av aviseringar tills det senaste återförsöket.
Om du vill konfigurera en återförsöksprincip för aktiviteten klickar du på + Lägg till bredvid Försök igen. Se Konfigurera en återförsöksprincip för en uppgift.
Om du vill konfigurera aktivitetens förväntade varaktighet eller tidsgräns klickar du på + Lägg till bredvid Tröskelvärde för varaktighet. Se Konfigurera en förväntad slutförandetid eller en tidsgräns för en aktivitet.
Klicka på Skapa.
Om du vill lägga till en annan aktivitet klickar du  i DAG-vyn. Ett alternativ för delat kluster tillhandahålls om du har konfigurerat ett nytt jobbkluster för en tidigare uppgift. Du kan också konfigurera ett kluster för varje uppgift när du skapar eller redigerar en uppgift. Mer information om hur du väljer och konfigurerar kluster för att köra uppgifter finns i Använda Azure Databricks-beräkning med dina jobb.
i DAG-vyn. Ett alternativ för delat kluster tillhandahålls om du har konfigurerat ett nytt jobbkluster för en tidigare uppgift. Du kan också konfigurera ett kluster för varje uppgift när du skapar eller redigerar en uppgift. Mer information om hur du väljer och konfigurerar kluster för att köra uppgifter finns i Använda Azure Databricks-beräkning med dina jobb.
Du kan också konfigurera inställningar på jobbnivå, till exempel meddelanden, jobbutlösare och behörigheter. Se Redigera ett jobb. Du kan också konfigurera parametrar på jobbnivå som delas med jobbets uppgifter. Se Lägg till parametrar för alla jobbaktiviteter.
Alternativ för aktivitetstyp
Följande är de aktivitetstyper som du kan lägga till i ditt Azure Databricks-jobb och tillgängliga alternativ för de olika aktivitetstyperna:
Notebook: I den nedrullningsbara menyn Källa väljer du Arbetsyta för att använda en notebook-fil i en Azure Databricks-arbetsytemapp eller Git-provider för en notebook-fil som finns på en fjärransluten Git-lagringsplats.
Arbetsyta: Använd filläsaren för att hitta anteckningsboken, klicka på anteckningsbokens namn och klicka på Bekräfta.
Git-provider: Klicka på Redigera eller Lägg till en git-referens och ange Git-lagringsplatsens information. Se Använda en notebook-fil från en fjärransluten Git-lagringsplats.
Kommentar
Totalt antal notebook-cellutdata (de kombinerade utdata från alla notebook-celler) omfattas av en storleksgräns på 20 MB. Dessutom omfattas enskilda cellutdata av en storleksgräns på 8 MB. Om den totala cellens utdata överskrider 20 MB i storlek, eller om utdata från en enskild cell är större än 8 MB, avbryts körningen och markeras som misslyckad.
Om du behöver hjälp med att hitta celler nära eller utanför gränsen kör du notebook-filen mot ett kluster för alla syften och använder den här tekniken för att spara filer automatiskt.
JAR: Ange klassen Main. Använd det fullständigt kvalificerade namnet på klassen som innehåller huvudmetoden, till exempel
org.apache.spark.examples.SparkPi. Klicka sedan på Lägg till under Beroende bibliotek för att lägga till bibliotek som krävs för att köra aktiviteten. Ett av dessa bibliotek måste innehålla huvudklassen.Mer information om JAR-uppgifter finns i Använda en JAR i ett Azure Databricks-jobb.
Spark-sändning: I textrutan Parametrar anger du huvudklassen, sökvägen till bibliotekets JAR och alla argument, formaterade som en JSON-matris med strängar. I följande exempel konfigureras en spark-submit-uppgift för att köra från Apache Spark-exemplen
DFSReadWriteTest:["--class","org.apache.spark.examples.DFSReadWriteTest","dbfs:/FileStore/libraries/spark_examples_2_12_3_1_1.jar","/discover/databricks-datasets/README.md","/FileStore/examples/output/"]Viktigt!
Det finns flera begränsningar för spark-submit-uppgifter :
- Du kan endast köra spark-submit-uppgifter i nya kluster.
- Spark-submit stöder inte automatisk skalning av kluster. Mer information om automatisk skalning finns i Autoskalning av kluster.
- Spark-submit stöder inte databricks Utilities-referens (dbutils). Om du vill använda Databricks Utilities använder du JAR-uppgifter i stället.
- Om du använder ett Unity Catalog-aktiverat kluster stöds spark-submit endast om klustret använder det tilldelade åtkomstläget. Läget för delad åtkomst stöds inte.
- Spark Streaming-jobb bör aldrig ha maximalt antal samtidiga körningar som är större än 1. Direktuppspelningsjobb ska vara inställda på att köras med cron-uttrycket
"* * * * * ?"(varje minut). Eftersom en direktuppspelningsaktivitet körs kontinuerligt bör den alltid vara den sista uppgiften i ett jobb.
Python-skript: I listrutan Källa väljer du en plats för Python-skriptet, antingen Arbetsyta för ett skript på den lokala arbetsytan, DBFS för ett skript som finns på DBFS eller Git-providern för ett skript som finns på en Git-lagringsplats. I textrutan Sökväg anger du sökvägen till Python-skriptet:
Arbetsyta: I dialogrutan Välj Python-fil bläddrar du till Python-skriptet och klickar på Bekräfta.
DBFS: Ange URI för ett Python-skript på DBFS eller molnlagring,
dbfs:/FileStore/myscript.pytill exempel .Git-provider: Klicka på Redigera och ange information om Git-lagringsplatsen. Se Använda Python-kod från en fjärransluten Git-lagringsplats.
Delta Live Tables Pipeline: I den nedrullningsbara menyn Pipeline väljer du en befintlig Delta Live Tables-pipeline .
Viktigt!
Du kan bara använda utlösta pipelines med pipelineaktiviteten. Kontinuerliga pipelines stöds inte som en jobbaktivitet. Mer information om utlösta och kontinuerliga pipelines finns i Kontinuerlig eller utlöst pipelinekörning.
Python Wheel: I textrutan Paketnamn anger du paketet som ska importeras,
myWheel-1.0-py2.py3-none-any.whltill exempel . I textrutan Startpunkt anger du funktionen som ska anropas när du startar Python-hjulet. Klicka på Lägg till under Beroende bibliotek för att lägga till bibliotek som krävs för att köra uppgiften.SQL: I listrutan SQL-uppgift väljer du Fråga, Instrumentpanel, Avisering eller Fil.
Kommentar
- SQL-uppgiften kräver Databricks SQL och ett serverlöst eller pro SQL-lager.
Fråga: I listrutan SQL-fråga väljer du den fråga som ska köras när aktiviteten körs.
Instrumentpanel: I den nedrullningsbara menyn för SQL-instrumentpanelen väljer du en instrumentpanel som ska uppdateras när aktiviteten körs.
Avisering: I listrutan SQL-avisering väljer du en avisering som ska utlösas för utvärdering.
Fil: Om du vill använda en SQL-fil som finns i en Azure Databricks-arbetsytemapp går du till listrutan Källa , väljer Arbetsyta, använder filläsaren för att hitta SQL-filen, klickar på filnamnet och klickar på Bekräfta. Om du vill använda en SQL-fil som finns på en fjärransluten Git-lagringsplats väljer du Git-provider, klickar på Redigera eller Lägg till en git-referens och anger information för Git-lagringsplatsen. Se Använda SQL-frågor från en fjärransluten Git-lagringsplats.
I listrutan SQL Warehouse väljer du ett serverlöst eller pro SQL-lager för att köra uppgiften.
dbt: Se Använda dbt-transformeringar i ett Azure Databricks-jobb för ett detaljerat exempel på hur du konfigurerar en dbt-uppgift.
Kör jobb: I den nedrullningsbara menyn Jobb väljer du ett jobb som ska köras av aktiviteten. Om du vill söka efter jobbet som ska köras börjar du skriva jobbnamnet på jobbmenyn .
Viktigt!
Du bör inte skapa jobb med cirkulära beroenden när du använder uppgiften eller jobben
Run Jobsom kapslar fler än treRun Jobaktiviteter. Cirkulära beroenden ärRun Jobuppgifter som direkt eller indirekt utlöser varandra. Jobb A utlöser till exempel jobb B och jobb B utlöser jobb A. Databricks stöder inte jobb med cirkulära beroenden eller som kapslar fler än treRun Jobaktiviteter och kanske inte tillåter körning av dessa jobb i framtida versioner.Om/annars: Mer information om hur du använder
If/else conditionuppgiften finns i Lägga till förgreningslogik i ditt jobb med villkorsaktiviteten If/else.
Skicka parametrar till en Azure Databricks-jobbaktivitet
Du kan skicka parametrar till många av jobbaktivitetstyperna. Varje aktivitetstyp har olika krav för formatering och överföring av parametrarna.
Om du vill komma åt information om den aktuella aktiviteten, till exempel aktivitetsnamnet eller skicka kontext om den aktuella körningen mellan jobbaktiviteter, till exempel starttiden för jobbet eller identifieraren för den aktuella jobbkörningen, använder du referenser för dynamiskt värde. Om du vill visa en lista över tillgängliga referenser för dynamiskt värde klickar du på Bläddra bland dynamiska värden.
Om jobbparametrar har konfigurerats för jobbet som en uppgift tillhör visas dessa parametrar när du lägger till uppgiftsparametrar. Om jobb- och uppgiftsparametrarna delar en nyckel har jobbparametern företräde. En varning visas i användargränssnittet om du försöker lägga till en aktivitetsparameter med samma nyckel som en jobbparameter. Om du vill skicka jobbparametrar till aktiviteter som inte har konfigurerats med nyckelvärdesparametrar, till exempel JAR eller Spark Submit uppgifter, formaterar du argument som {{job.parameters.[name]}}, ersätter [name] med key som identifierar parametern.
Notebook: Klicka på Lägg till och ange nyckeln och värdet för varje parameter som ska skickas till aktiviteten. Du kan åsidosätta eller lägga till ytterligare parametrar när du manuellt kör en uppgift med alternativet Kör ett jobb med olika parametrar . Parametrar anger värdet för notebook-widgeten som anges av nyckeln för parametern.
JAR: Använd en JSON-formaterad matris med strängar för att ange parametrar. Dessa strängar skickas som argument till huvudmetoden för huvudklassen. Se Konfigurera JAR-jobbparametrar.
Spark-sändning: Parametrar anges som en JSON-formaterad matris med strängar. Enligt Apache Spark spark-submit-konventionen skickas parametrar efter att JAR-sökvägen har skickats till huvudmetoden för huvudklassen.
Python Wheel: I den nedrullningsbara menyn Parametrar väljer du Positionella argument för att ange parametrar som en JSON-formaterad matris med strängar eller väljer Nyckelordsargument > Lägg till för att ange nyckeln och värdet för varje parameter. Både positions- och nyckelordsargument skickas till Python-hjulaktiviteten som kommandoradsargument. Ett exempel på hur du läser argument i ett Python-skript som paketeras i ett Python-hjul finns i Använda ett Python-hjul i ett Azure Databricks-jobb.
Kör jobb: Ange nyckeln och värdet för varje jobbparameter som ska skickas till jobbet.
Python-skript: Använd en JSON-formaterad matris med strängar för att ange parametrar. Dessa strängar skickas som argument och kan läsas som positionsargument eller parsas med hjälp av argparse-modulen i Python. Ett exempel på hur du läser positionsargument i ett Python-skript finns i Steg 2: Skapa ett skript för att hämta GitHub-data.
SQL: Om din uppgift kör en parameteriserad fråga eller en parameteriserad instrumentpanel anger du värden för parametrarna i de angivna textrutorna.
Kopiera en aktivitetssökväg
Med vissa aktivitetstyper, till exempel notebook-uppgifter, kan du kopiera sökvägen till aktivitetens källkod:
- Klicka på fliken Uppgifter .
- Välj den uppgift som innehåller sökvägen som ska kopieras.
- Klicka
 bredvid aktivitetssökvägen för att kopiera sökvägen till Urklipp.
bredvid aktivitetssökvägen för att kopiera sökvägen till Urklipp.
Skapa ett jobb från ett befintligt jobb
Du kan snabbt skapa ett nytt jobb genom att klona ett befintligt jobb. Kloning av ett jobb skapar en identisk kopia av jobbet, förutom jobb-ID:t. På jobbets sida klickar du på Mer ... bredvid jobbets namn och väljer Klona på den nedrullningsbara menyn.
Skapa en aktivitet från en befintlig aktivitet
Du kan snabbt skapa en ny uppgift genom att klona en befintlig uppgift:
- På jobbets sida klickar du på fliken Uppgifter .
- Välj den uppgift som ska klonas.
- Klicka
 på och välj Klona aktivitet.
på och välj Klona aktivitet.
Ta bort ett jobb
Om du vill ta bort ett jobb klickar du på Mer på jobbets sida... bredvid jobbets namn och väljer Ta bort på den nedrullningsbara menyn.
Ta bort en uppgift
Så här tar du bort en uppgift:
- Klicka på fliken Uppgifter .
- Välj den uppgift som ska tas bort.
- Klicka och välj Ta bort aktivitet.
Köra ett jobb
- Klicka på Arbetsflöden i sidofältet.
- Välj ett jobb och klicka på fliken Körningar . Du kan köra ett jobb direkt eller schemalägga jobbet så att det körs senare.
Om en eller flera aktiviteter i ett jobb med flera aktiviteter misslyckas kan du köra om delmängden av misslyckade aktiviteter. Se Kör om misslyckade och överhoppade uppgifter.
Kör ett jobb omedelbart
Om du vill köra jobbet direkt klickar du på  .
.
Dricks
Du kan utföra en testkörning av ett jobb med en notebook-uppgift genom att klicka på Kör nu. Om du behöver göra ändringar i anteckningsboken körs den nya versionen av notebook-filen automatiskt genom att klicka på Kör nu igen efter redigering av anteckningsboken.
Köra ett jobb med olika parametrar
Du kan använda Kör nu med olika parametrar för att köra ett jobb igen med olika parametrar eller olika värden för befintliga parametrar.
Kommentar
Du kan inte åsidosätta jobbparametrar om ett jobb som kördes före introduktionen av jobbparametrar överskrör aktivitetsparametrar med samma nyckel.
- Klicka
 bredvid Kör nu och välj Kör nu med olika parametrar, eller klicka på Kör nu med olika parametrar i tabellen Aktiva körningar. Ange de nya parametrarna beroende på typen av aktivitet. Se Skicka parametrar till en Azure Databricks-jobbaktivitet.
bredvid Kör nu och välj Kör nu med olika parametrar, eller klicka på Kör nu med olika parametrar i tabellen Aktiva körningar. Ange de nya parametrarna beroende på typen av aktivitet. Se Skicka parametrar till en Azure Databricks-jobbaktivitet. - Klicka på Kör.
Kör ett jobb som tjänstens huvudnamn
Kommentar
Om ditt jobb kör SQL-frågor med sql-uppgiften bestäms identiteten som används för att köra frågorna av delningsinställningarna för varje fråga, även om jobbet körs som tjänstens huvudnamn. Om en fråga har konfigurerats till Run as ownerkörs frågan alltid med ägarens identitet och inte tjänstens huvudnamns identitet. Om frågan är konfigurerad för Run as viewerkörs frågan med tjänstens huvudnamns identitet. Mer information om inställningar för frågedelning finns i Frågebehörigheter och delningsinställningar.
Som standard körs jobben som jobbägarens identitet. Det innebär att jobbet förutsätter jobbägarens behörigheter. Jobbet kan bara komma åt data och Azure Databricks-objekt som jobbägaren har behörighet att komma åt. Du kan ändra identiteten som jobbet körs som till tjänstens huvudnamn. Sedan förutsätter jobbet behörigheterna för tjänstens huvudnamn i stället för ägaren.
Om du vill ändra inställningen Kör som måste du ha behörigheten CAN MANAGE eller IS OWNER för jobbet. Du kan ange inställningen Kör som till dig själv eller till ett huvudnamn för tjänsten på arbetsytan där du har rollen Tjänstens huvudnamn. Mer information finns i Roller för att hantera tjänstens huvudnamn och Åtkomstkontroll för jobb.
Kommentar
RestrictWorkspaceAdmins När inställningen på en arbetsyta är inställd ALLOW ALLpå kan arbetsyteadministratörer också ändra inställningen Kör som till alla användare på arbetsytan. Information om hur du begränsar arbetsyteadministratörer till att endast ändra inställningen Kör som till sig själva eller tjänstens huvudnamn som de har användarrollen Tjänsthuvudnamn på finns i Begränsa administratörer för arbetsytan.
Gör följande för att ändra kör som-fältet:
- I sidofältet klickar du på Arbetsflöden.
- Klicka på jobbnamnet i kolumnen Namn.
- I panelen Jobbinformation klickar du på pennikonen bredvid fältet Kör som .
- Sök efter och välj tjänstens huvudnamn.
- Klicka på Spara.
Du kan också lista de tjänsthuvudnamn som du har användarrollen på med hjälp av API:et För arbetsytetjänstens huvudnamn. Mer information finns i Lista de tjänsthuvudnamn som du kan använda.
Köra ett jobb enligt ett schema
Du kan använda ett schema för att automatiskt köra ditt Azure Databricks-jobb vid angivna tider och perioder. Se Lägg till ett jobbschema.
Köra ett kontinuerligt jobb
Du kan se till att det alltid finns en aktiv körning av jobbet. Se Köra ett kontinuerligt jobb.
Kör ett jobb när nya filer tas emot
Om du vill utlösa en jobbkörning när nya filer kommer till en extern plats eller volym i Unity Catalog använder du en utlösare för filinkomst.
Vad händer om mitt jobb inte kan köras på grund av samtidighetsgränser?
Om du vill förhindra att körningar av ett jobb hoppas över på grund av samtidighetsgränser kan du aktivera köning för jobbet. Om resurser inte är tillgängliga för en jobbkörning när köning är aktiverat placeras körningen i kö i upp till 48 timmar. När kapaciteten är tillgänglig tas jobbkörningen bort och körs. Köade körningar visas i körningslistan för jobbet och den senaste listan över jobbkörningar.
En körning placeras i kö när någon av följande gränser har nåtts:
- Maximalt antal samtidiga aktiva körningar på arbetsytan.
- Den maximala samtidiga
Run Jobaktiviteten körs på arbetsytan. - Maximalt antal samtidiga körningar av jobbet.
Köning är en egenskap på jobbnivå som köer endast körs för det jobbet.
Om du vill aktivera köning klickar du på växlingsknappen Kö på sidan Jobbinformation .