Förbearbeta data med en lagrad procedur innan de läses in i Lakehouse
I den här självstudien visar vi hur du använder en pipelineskriptaktivitet för att köra en lagrad procedur för att skapa en tabell och förbearbeta data i ett Synapse Data Warehouse. Därefter läser vi in den förbearbetade tabellen i Lakehouse.
Förutsättningar
En Microsoft Fabric-aktiverad arbetsyta. Om du inte redan har en kan du läsa artikeln Skapa en arbetsyta.
Förbered en lagrad procedur i Azure Synapse Data Warehouse. Skapa följande lagrade procedur i förväg:
CREATE PROCEDURE spM_add_names AS --Create initial table IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[names]') AND TYPE IN (N'U')) BEGIN DROP TABLE names END; CREATE TABLE names (id INT,fullname VARCHAR(50)); --Populate data INSERT INTO names VALUES (1,'John Smith'); INSERT INTO names VALUES (2,'James Dean'); --Alter table for new columns ALTER TABLE names ADD first_name VARCHAR(50) NULL; ALTER TABLE names ADD last_name VARCHAR(50) NULL; --Update table UPDATE names SET first_name = SUBSTRING(fullname, 1, CHARINDEX(' ', fullname)-1); UPDATE names SET last_name = SUBSTRING(fullname, CHARINDEX(' ', fullname)+1, LEN(fullname)-CHARINDEX(' ', fullname)); --View Result SELECT * FROM names;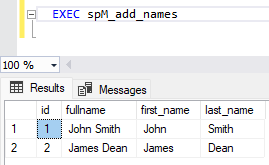
Skapa en pipelineskriptaktivitet för att köra den lagrade proceduren
I det här avsnittet använder vi en skriptaktivitet för att köra den lagrade proceduren som skapats i förutsättningarna.
Välj Skriptaktivitet och välj sedan Ny för att ansluta till ditt Azure Synapse Data Warehouse.
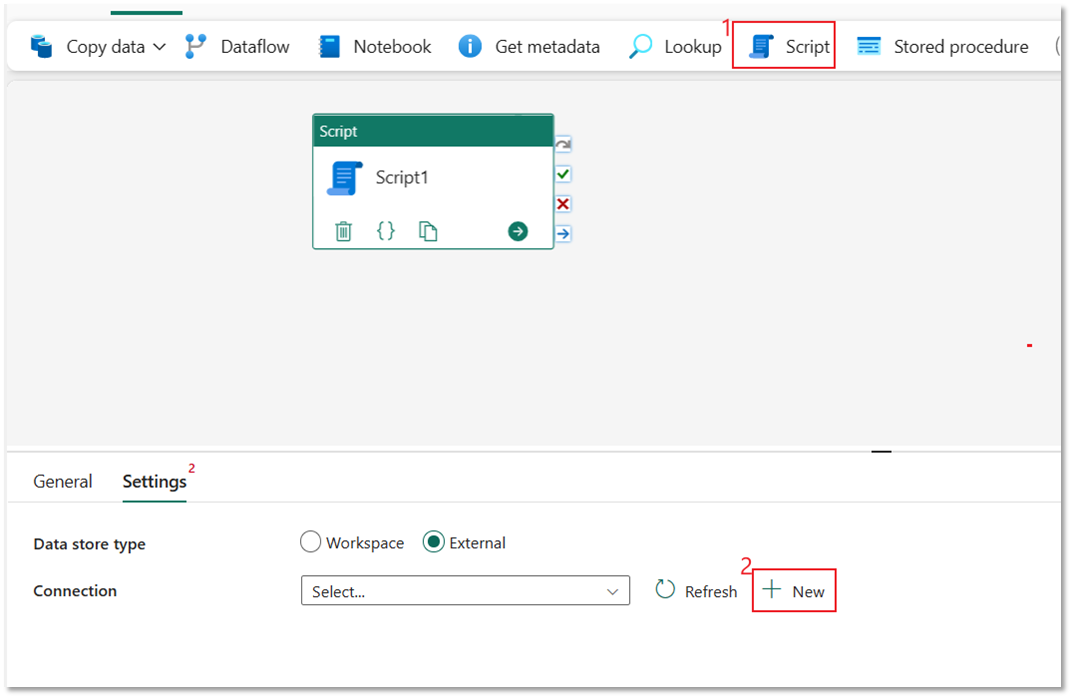
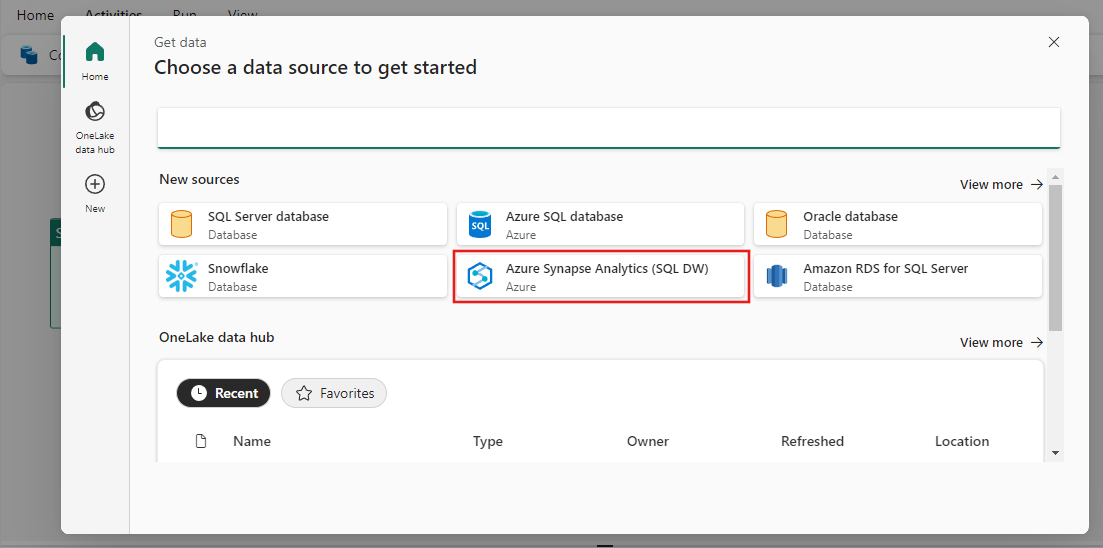
Välj Azure Synapse Analytics och sedan Fortsätt.
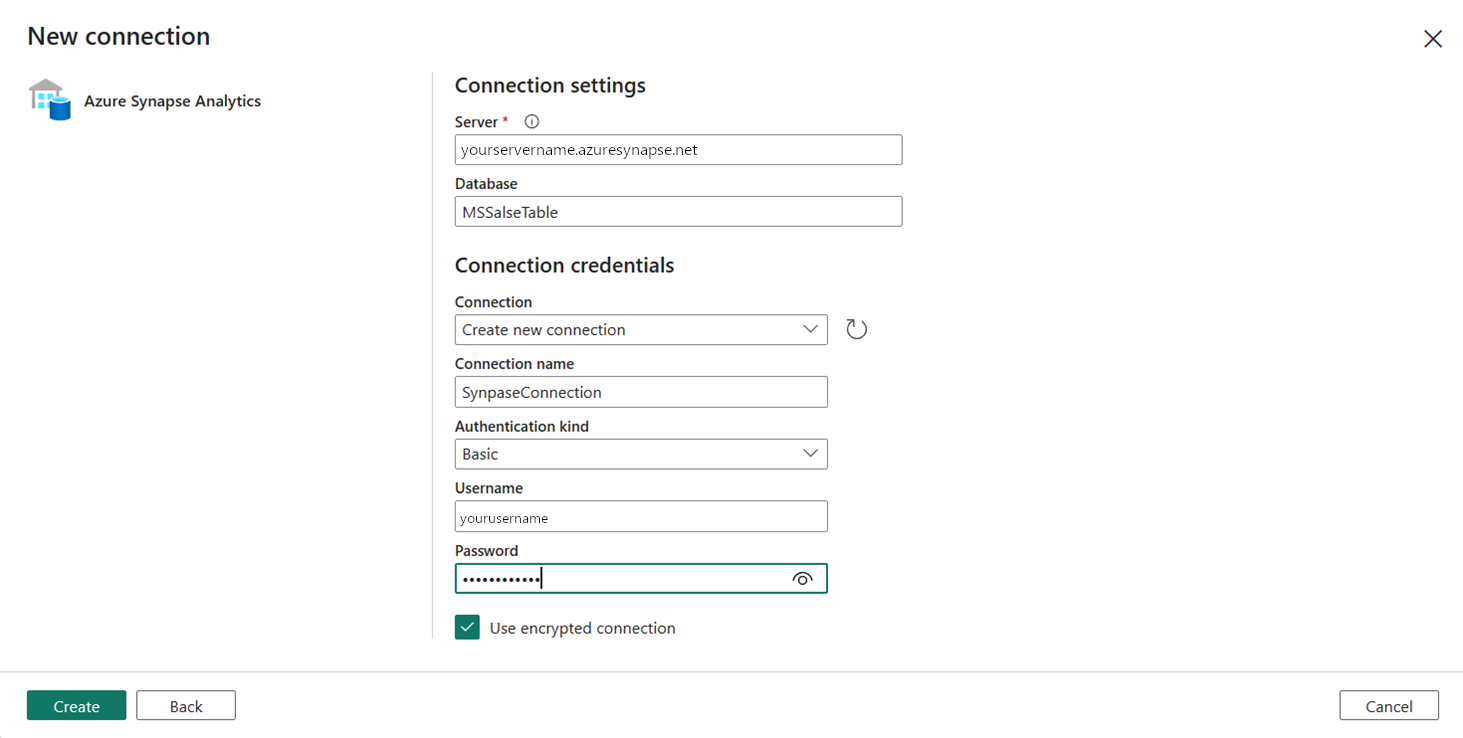
Ange fälten Server, Databas och Användarnamn och Lösenord för Grundläggande autentisering och ange Synapse Anslut ion som namn på Anslut ion. Välj sedan Skapa för att skapa den nya anslutningen.
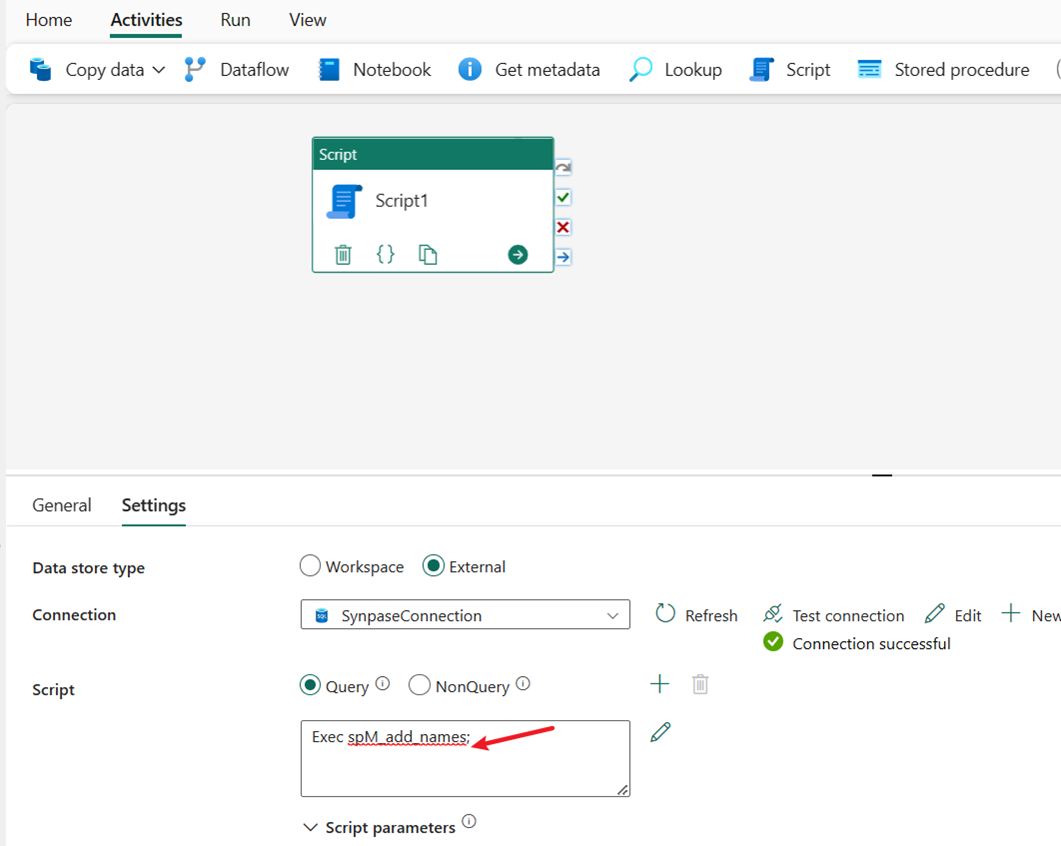
Indata-EXEC-spM_add_names för att köra den lagrade proceduren. Den skapar en ny tabell dbo.name och förbearbetar data med en enkel transformering för att ändra fältet fullname till två fält, first_name och last_name.


Använda en pipelineaktivitet för att läsa in förbearbetade tabelldata i Lakehouse
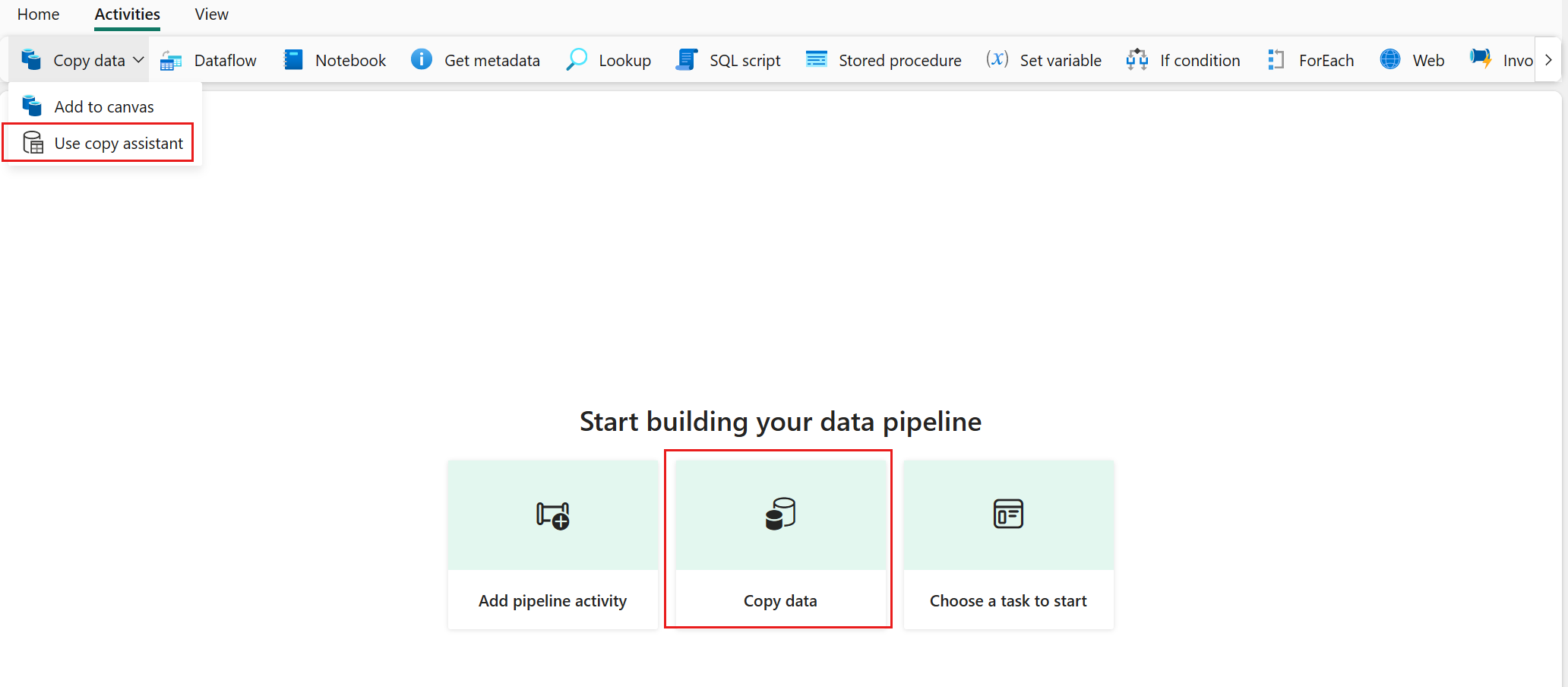
Välj Kopiera data och välj sedan Använd kopieringsassistent.
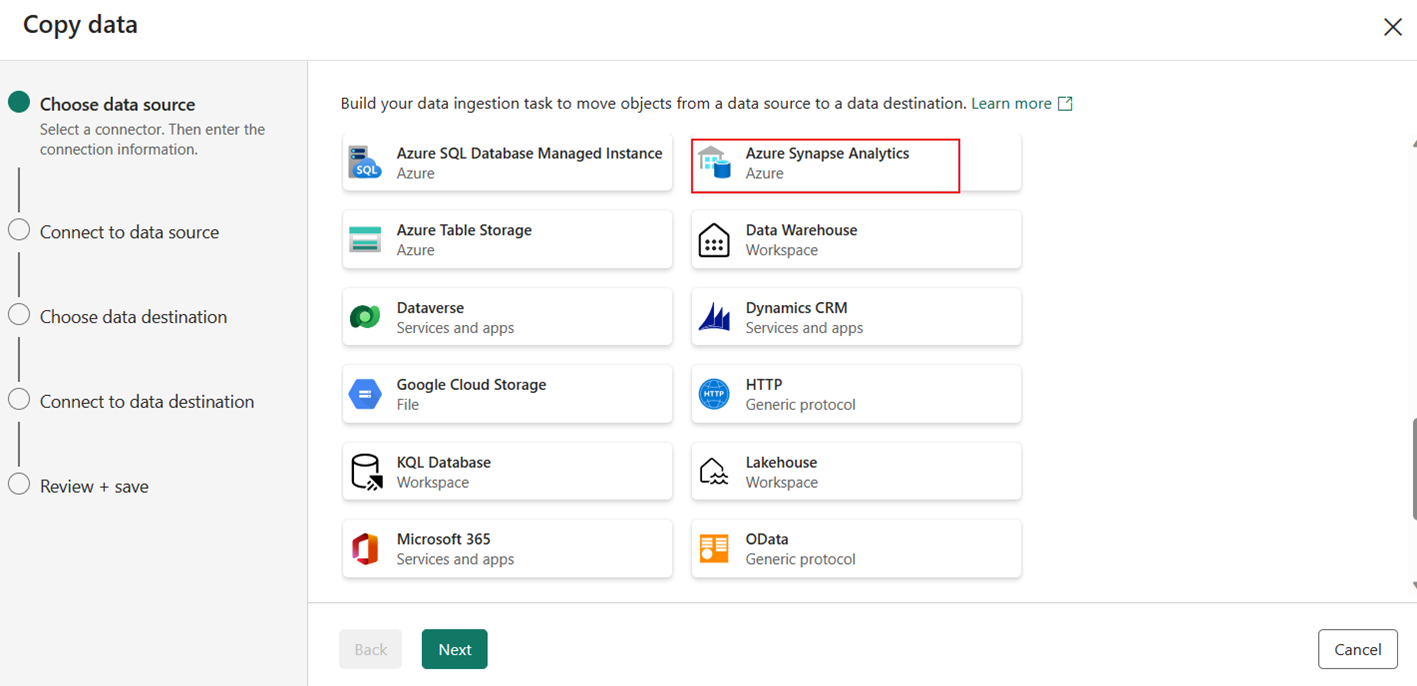
Välj Azure Synapse Analytics för datakällan och välj sedan Nästa.
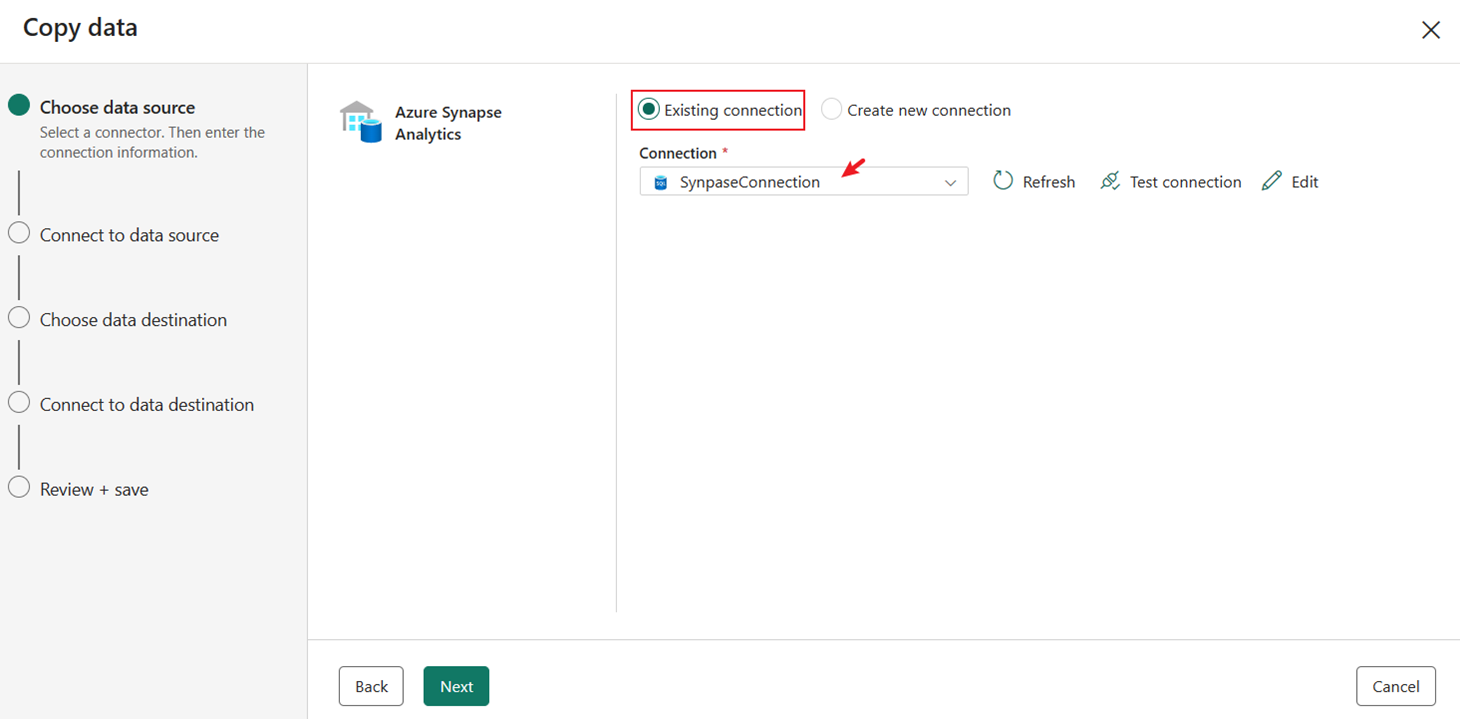
Välj den befintliga anslutningen Synapse Anslut ion som du skapade tidigare.
Välj tabellen dbo.names som skapades och förbearbetades av den lagrade proceduren. Välj sedan Nästa.
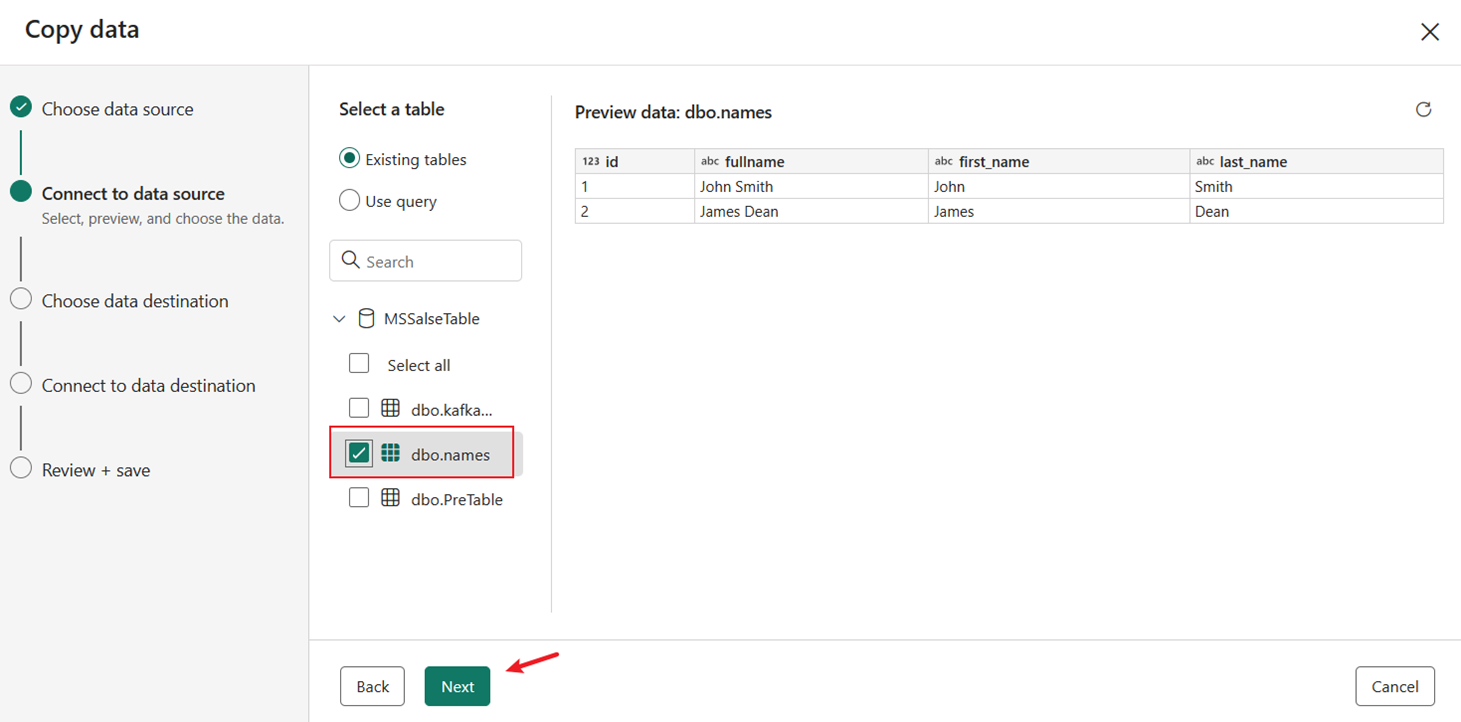
Välj Lakehouse under fliken Arbetsyta som mål och välj sedan Nästa igen.
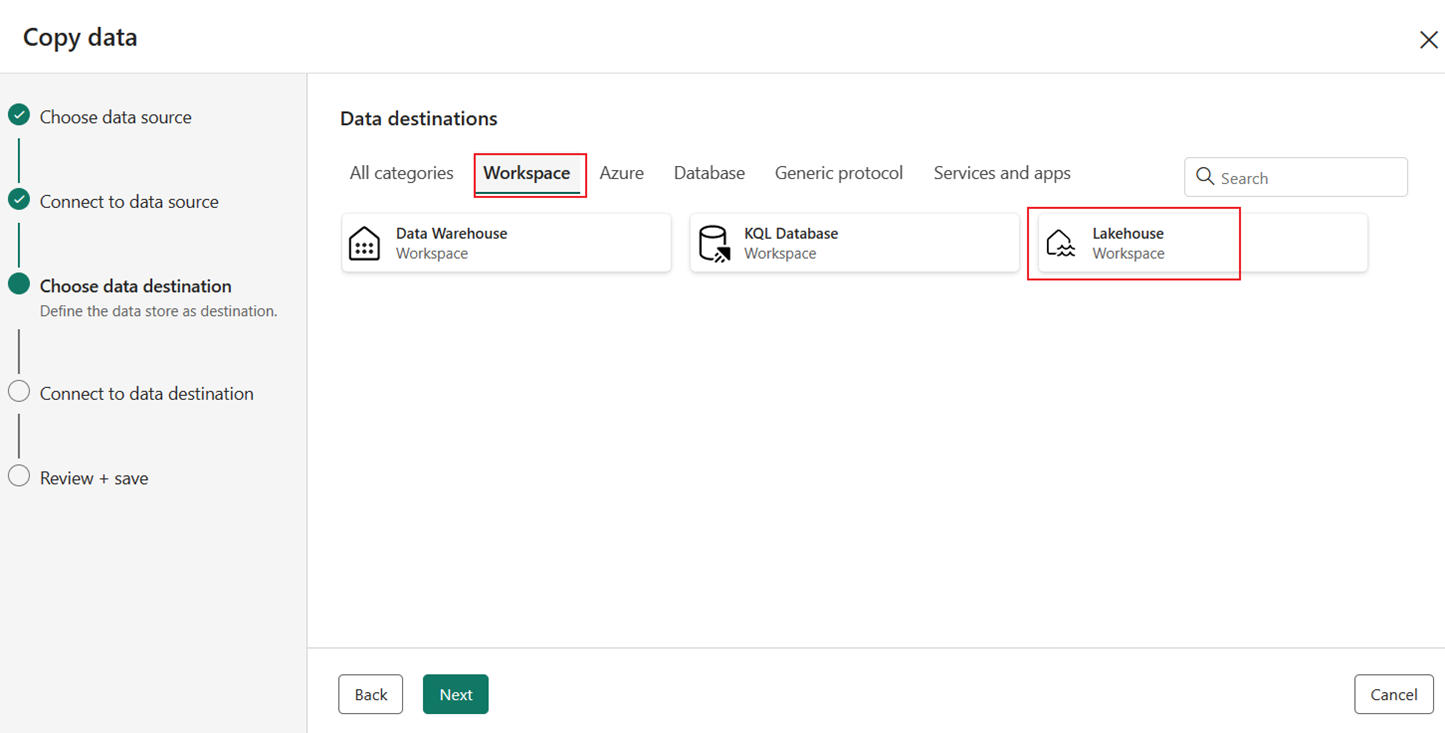
Välj en befintlig eller skapa ett nytt Lakehouse och välj sedan Nästa.
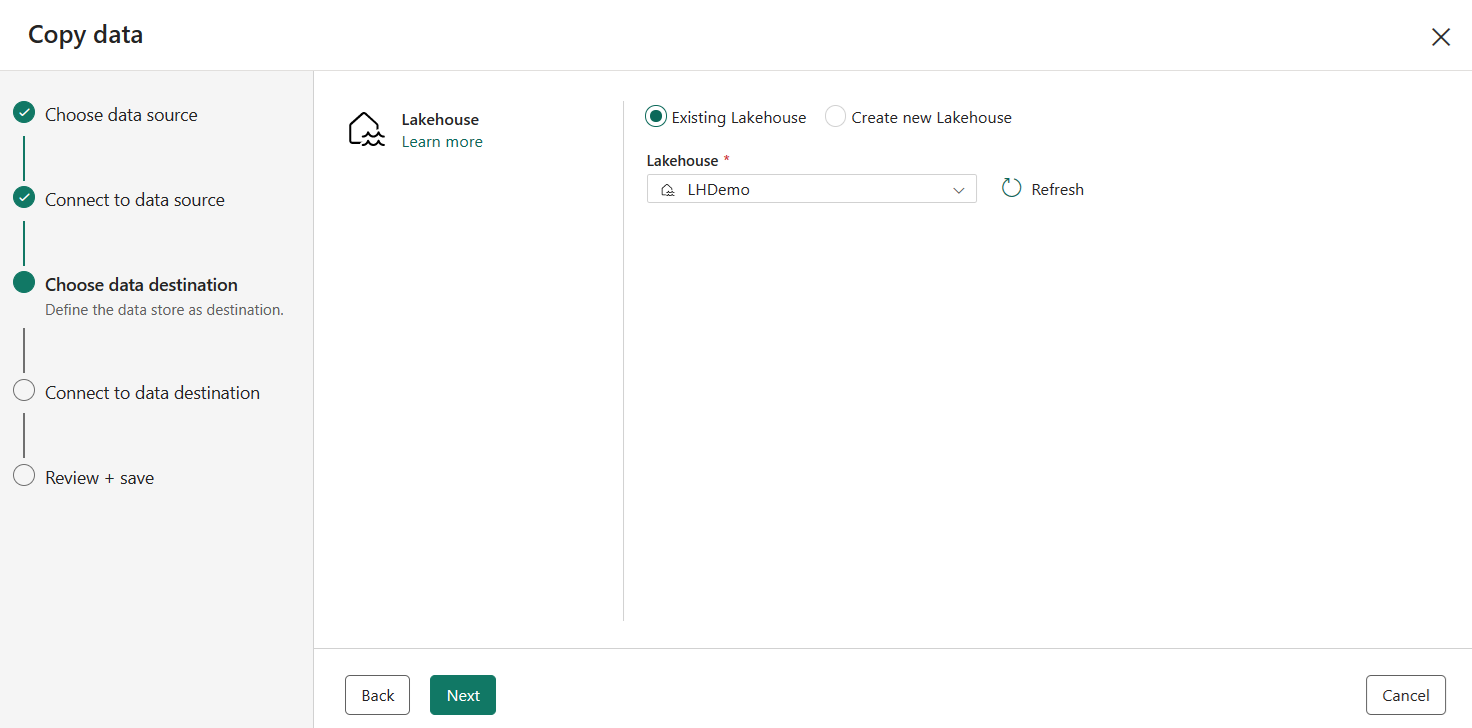
Ange ett måltabellnamn för de data som ska kopieras till för Lakehouse-målet och välj Nästa.
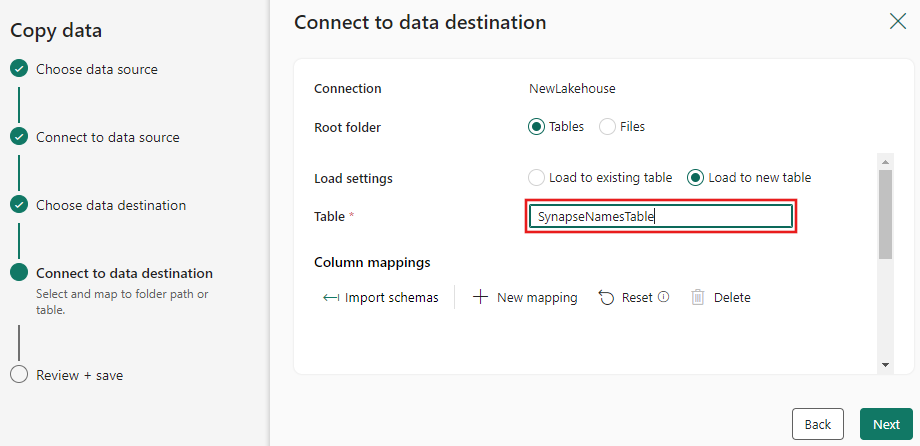
Granska sammanfattningen på den sista sidan i kopieringsassistenten och välj sedan OK.
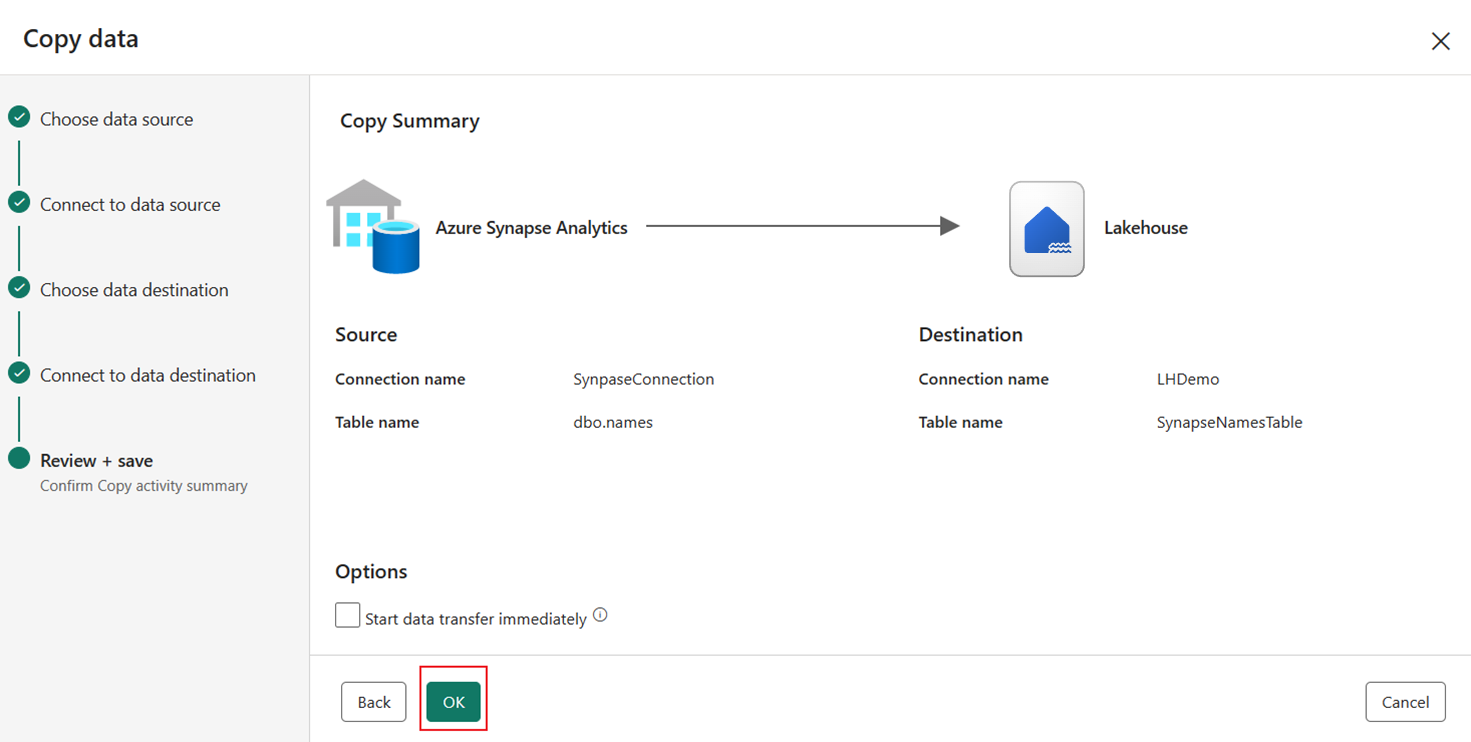
När du har valt OK läggs den nya aktiviteten Kopiera till på pipelinearbetsytan.
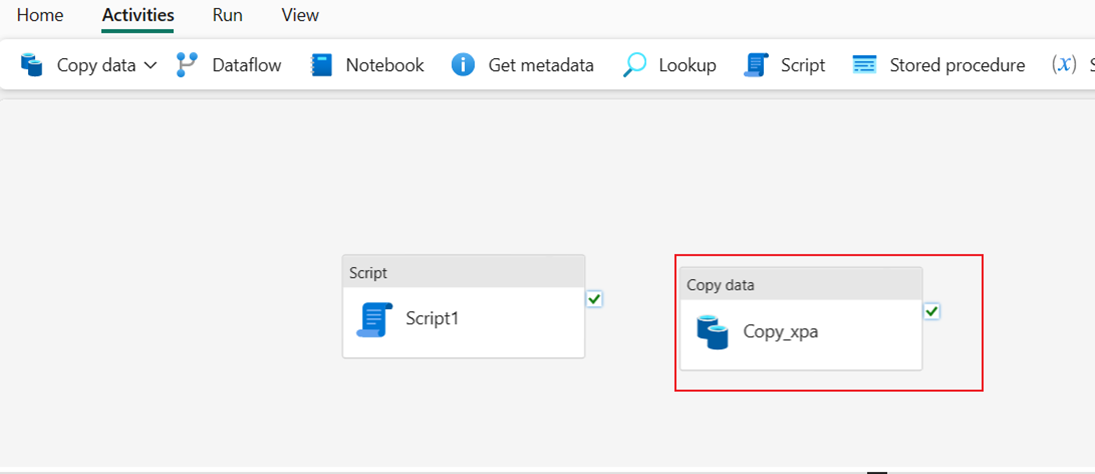



Kör de två pipelineaktiviteterna för att läsa in data
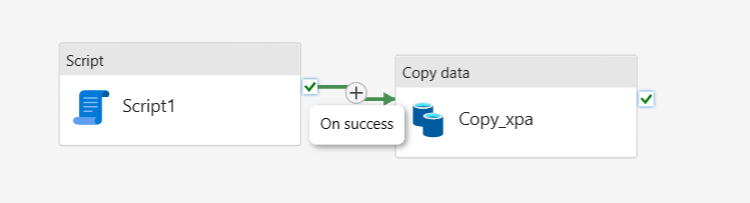
Anslut dataaktiviteterna Skript och Kopiera efter Vid framgång från skriptaktiviteten.
Välj Kör och sedan Spara och kör för att köra de två aktiviteterna i pipelinen.
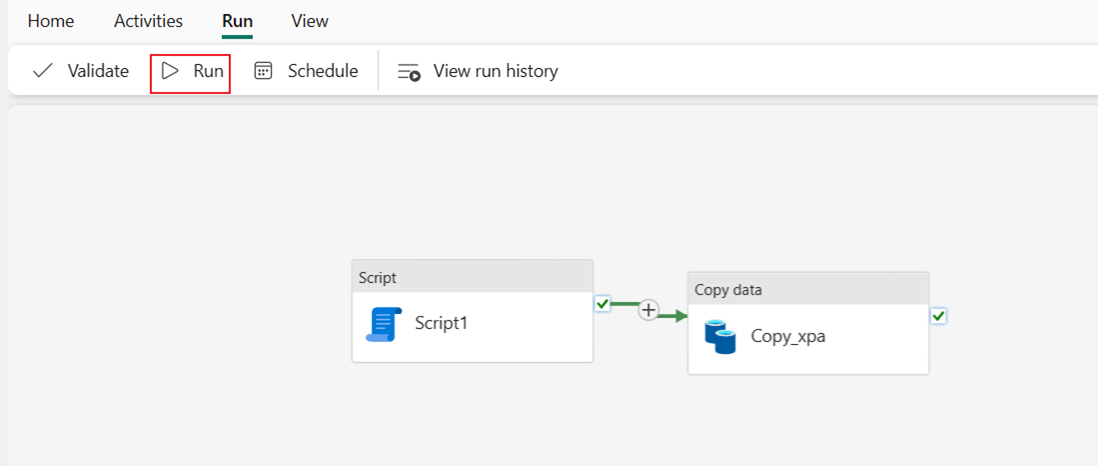
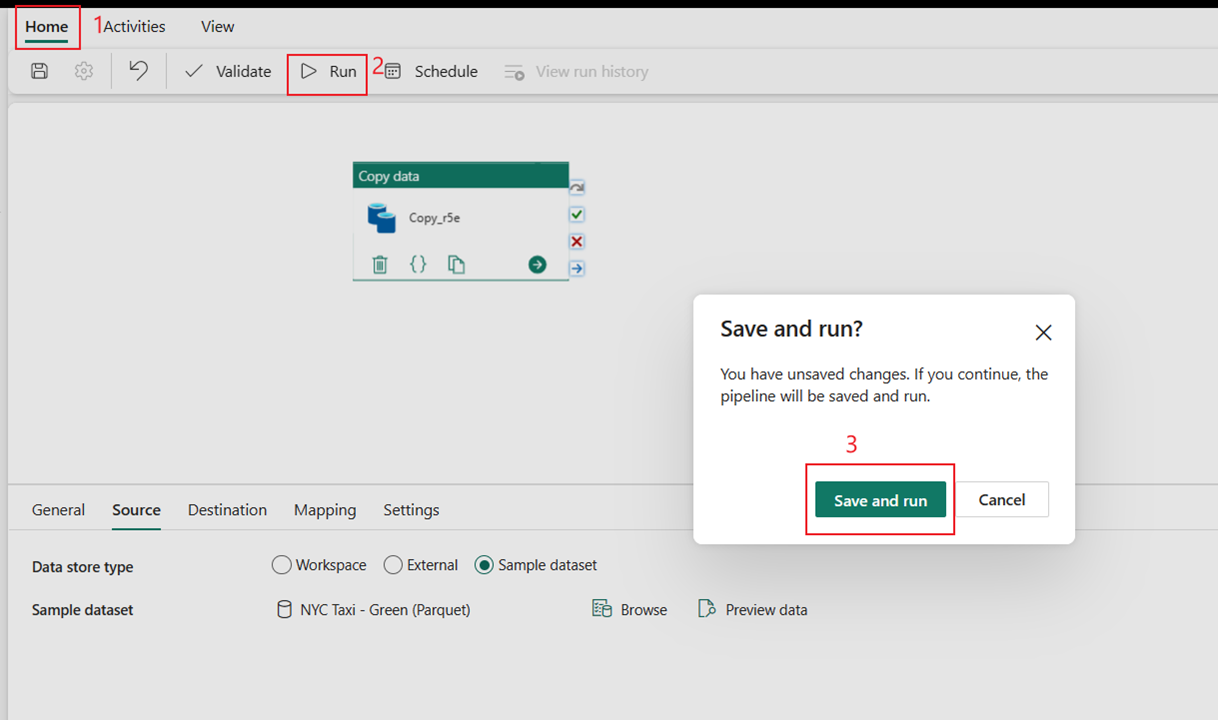
När pipelinen har körts kan du visa informationen för mer information.
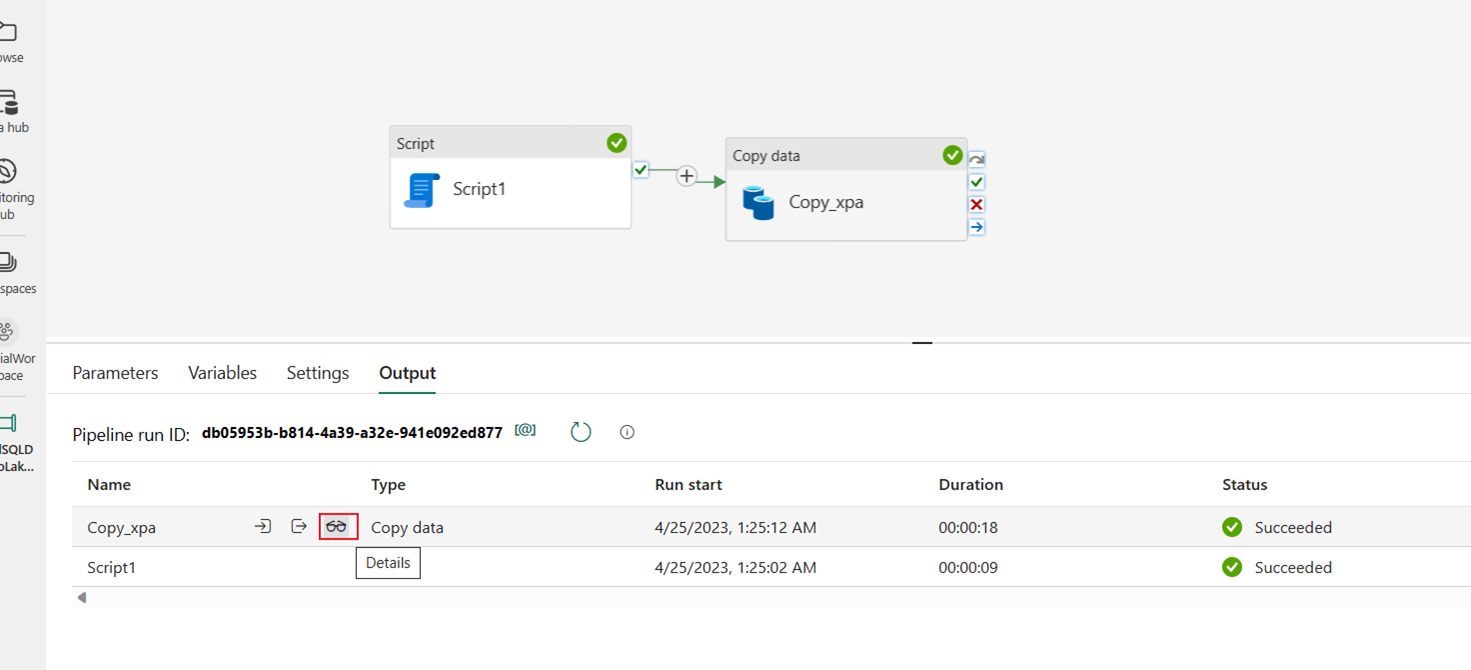
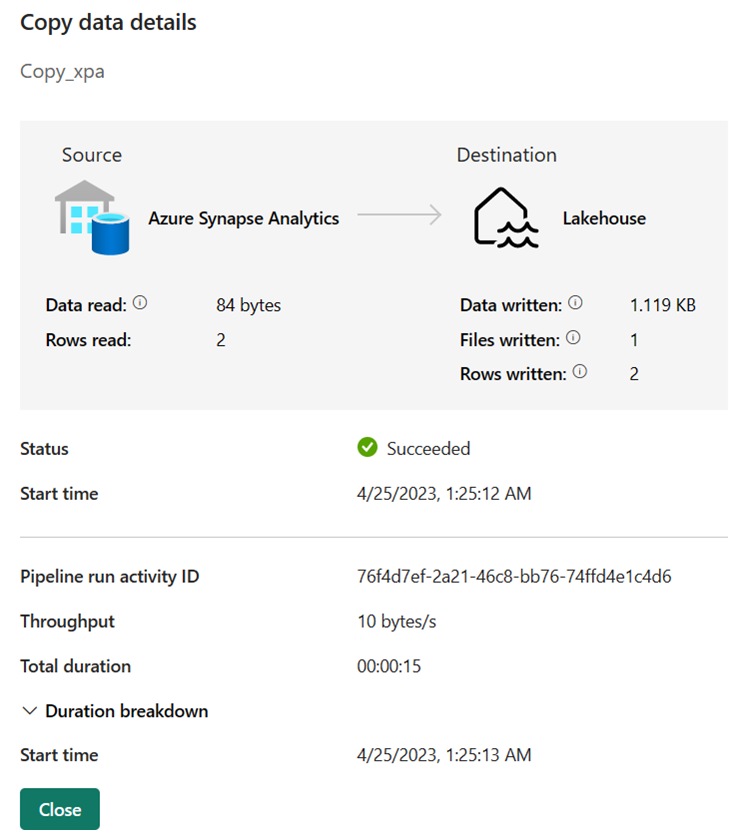
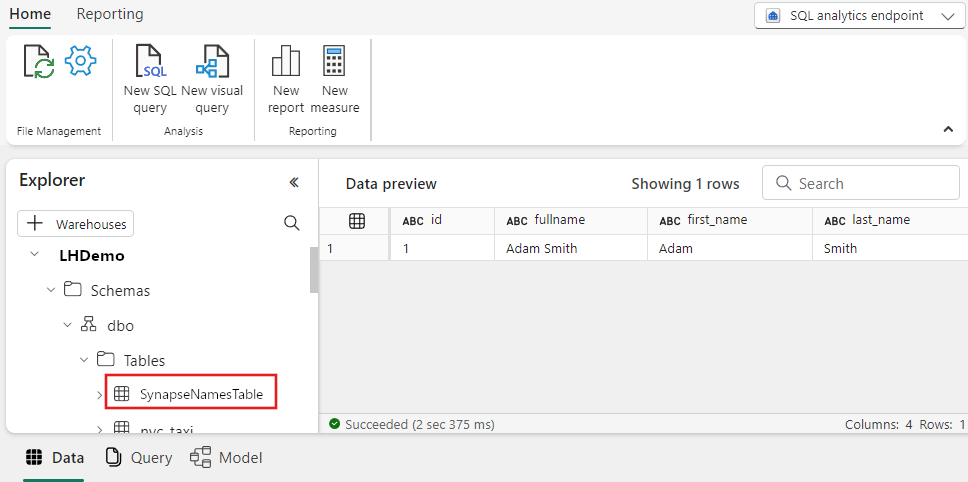
Växla till arbetsytan och välj Lakehouse för att kontrollera resultatet.
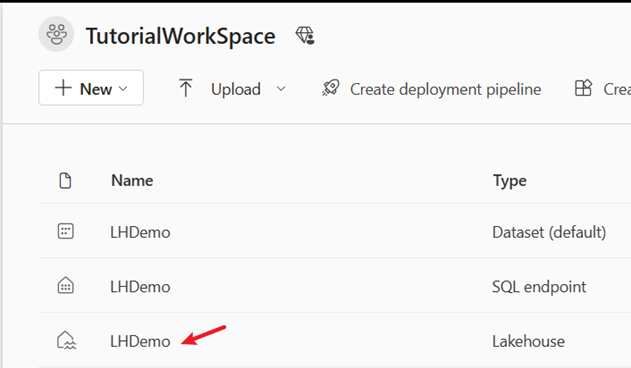
Välj tabellen SynapseNamesTable för att visa dat som lästs in i Lakehouse.
Relaterat innehåll
Det här exemplet visar hur du förbearbetar data med en lagrad procedur innan du läser in resultaten i Lakehouse. Du har lärt dig att:
- Skapa en datapipeline med en skriptaktivitet för att köra en lagrad procedur.
- Använd en pipelineaktivitet för att läsa in förbearbetade tabelldata till Lakehouse.
- Kör pipelineaktiviteterna för att läsa in data.
Gå sedan vidare för att lära dig mer om att övervaka dina pipelinekörningar.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för