Capabilities and limitations
In this section, we'll review what accuracy means for OCR and how to assess it for your context.
Word-level accuracy measure
Text is composed of lines, words, and characters. A popular measure of accuracy for OCR is word error rate (WER), or how many words were incorrectly output in the extracted results. The lower the WER, the higher the accuracy.
WER is defined as:
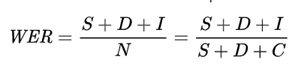
Where:
| Term | Definition | Example |
|---|---|---|
| S | Count of incorrect words ("substituted") in the output. | "Velvet" gets extracted as "Veivet" because "l" is detected as "i." |
| D | Count of missing (“deleted”) words in the output. | For the text "Company Name: Microsoft," Microsoft isn't extracted because it's handwritten or hard to read. |
| I | Count of nonexistent ("inserted") words in the output. | "Department" gets incorrectly segmented into three words as "Dep artm ent." In this case, the result is one deleted word and three inserted words. |
| C | Count of correctly extracted words in the output. | All words that are correctly extracted. |
| N | Count of total words in the reference (N=S+D+C) excluding I because those words were missing from the original reference and were incorrectly predicted as present. | Consider an image with the sentence, "Microsoft, headquartered in Redmond, WA announced a new product called Velvet for finance departments." Assume the OCR output is " , headquartered in Redmond, WA announced a new product called Veivet for finance dep artm ents." In this case, S (Velvet) = 1, D (Microsoft) = 1, I (dep artm ents) = 3, C (11), and N = S + D + C = 13. Therefore, WER = (S + D + I) / N = 5 / 13 = 0.38 or 38% (out of 100). |
Using a confidence value
As covered in an earlier section, the service provides a confidence value for each predicted word in the OCR output. Customers use this value to calibrate custom thresholds for their content and scenarios to route the content for straight-through processing or forwarding to the human-in-the-loop process. The resulting measurements determine the scenario-specific accuracy.
OCR system performance implications can vary by scenarios where the OCR technology is applied. We'll review a few examples to illustrate that concept.
Medical device compliance: In this first example, a multinational pharmaceutical company with a diverse product portfolio of patents, devices, medications, and treatments needs to analyze FDA-compliant product label information and analysis results documents. The company might prefer a low confidence value threshold for applying human-in-the-loop because the cost of incorrectly extracted data can have significant impact for consumers and fines from regulatory agencies.
Image and documents processing: In this second example, a company performs insurance and loan application processing. The customer using OCR might prefer a medium confidence value threshold because the automated text extraction is combined downstream with other information inputs and human-in-the-loop steps for a holistic review of applications.
Content moderation: For a large volume of e-commerce catalog data imported from suppliers at scale, the customer might prefer a high confidence value threshold with high accuracy because even a small percentage of falsely flagged content can generate a lot of overhead for their human review teams and suppliers.
System limitations and best practices to improve system performance
The service supports images (JPEG, PNG, and BMP) and documents (PDF and TIFF). The allowable limits for number of pages, image sizes, paper sizes, and file sizes are listed on the OCR overview page.
Document scan quality, resolution, contrast, light conditions, rotation, and text attributes such as size, color, and density can all affect the accuracy of OCR results. For example, we recommend the image be at least 50 X 50 pixels. Customers should refer to the product specifications and test the service on their documents to validate the fit for their situation.
The following example shows a few difficult cases for OCR where you see missed and incorrect text extractions.

The current version supports handwriting or cursive-style text only for English. This limitation also affects any related features such as print vs. handwriting-style classification (preview) for each text line.
OCR's performance will vary depending on the real-world uses that customers implement. In order to ensure optimal performance in their scenarios, customers should conduct their own evaluations of the solutions they implement using OCR. The service provides a confidence value in the range between 0 and 1 for each detected word included in the OCR output. Customers should scan a sample dataset representing their content to get a sense of the range of confidence scores and the resulting extraction quality. They can then decide on the confidence value thresholds to determine whether the results should be sent for straight-through-processing (STP) or reviewed by a human. For example, the customer may submit results with confidence value greater than or equal to .80 for straight through processing, and apply human review to results with confidence value less than .80.