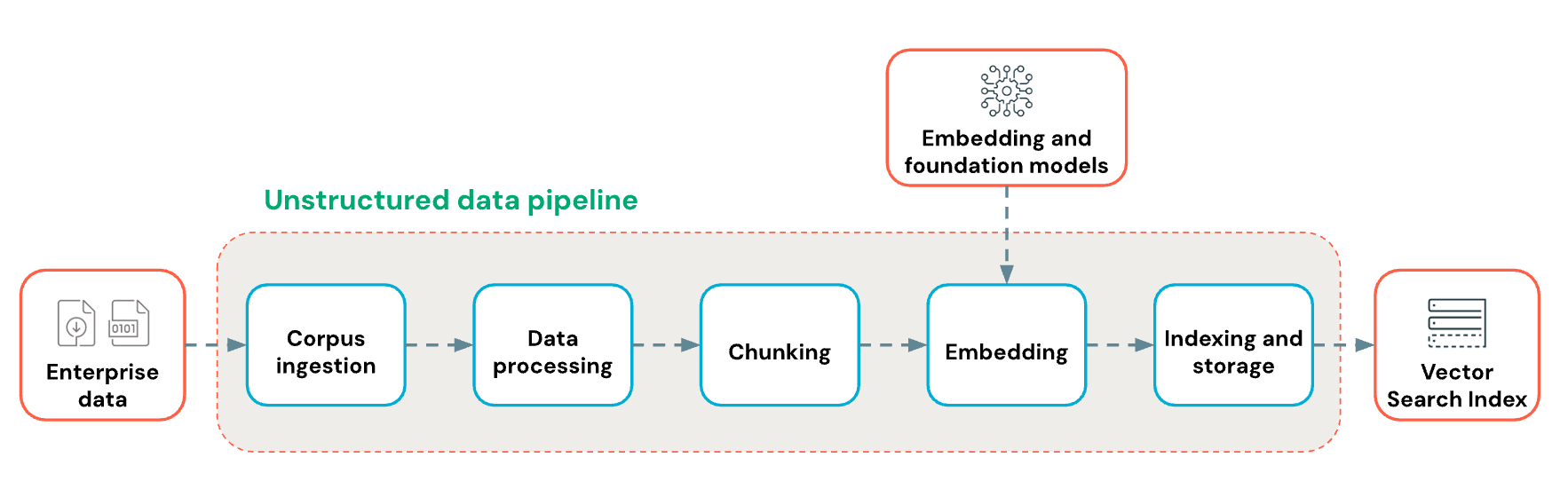
This article describes how to build an unstructured data pipeline for gen AI applications. Unstructured pipelines are particularly useful for Retrieval-Augmented Generation (RAG) applications.
Learn how to convert unstructured content like text files and PDFs into a vector index that AI agents or other retrievers can query. You also learn how to experiment and tune your pipeline to optimize chunking, indexing, and parsing data, allowing you to troubleshoot and experiment with the pipeline to achieve better results.
Unstructured data pipeline notebook
The following notebook shows you how to implement the information in this article to create an unstructured data pipeline.
The foundation of any RAG application with unstructured data is the data pipeline. This pipeline is responsible for curating and preparing the unstructured data in a format the RAG application can use effectively. While this data pipeline can become complex depending on the use case, the following are the key components you need to think about when first building your RAG application:
Data preprocessing: Transform raw data into a clean, consistent format suitable for embedding and retrieval.
Parsing: Extract relevant information from the raw data using appropriate parsing techniques.
Enrichment: Enrich data with additional metadata and remove noise.
Metadata extraction: Extract helpful metadata to implement faster and more efficient data retrieval.
Deduplication: Analyze the documents to identify and eliminate duplicates or near-duplicate documents.
Filtering: Eliminate irrelevant or unwanted documents from the collection.
Chunking: Break down the parsed data into smaller, manageable chunks for efficient retrieval.
Embedding: Convert the chunked text data into a numerical vector representation that captures its semantic meaning.
Indexing and storage: Create efficient vector indices for optimized search performance.
Corpus composition and ingestion
Your RAG application can’t retrieve the information required to answer a user query without the right data corpus. The correct data depends entirely on your application's specific requirements and goals, making it crucial to dedicate time to understanding the nuances of the available data (see the requirements gathering section for guidance).
For example, when building a customer support bot, you might consider including the following:
Knowledge base documents
Frequently Asked Questions (FAQs)
Product manuals and specifications
Troubleshooting guides
Engage domain experts and stakeholders from the beginning of any project to help identify and curate relevant content that could improve the quality and coverage of your data corpus. They can provide insights into the types of queries that users are likely to submit and help prioritize the most critical information to include.
Databricks recommends you ingest data in a scalable and incremental manner. Azure Databricks offers various methods for data ingestion, including fully managed connectors for SaaS applications and API integrations. As a best practice, raw source data should be ingested and stored in a target table. This approach ensures data preservation, traceability, and auditing. See Ingest data into an Azure Databricks lakehouse.
Data preprocessing
After the data has been ingested, it is essential to clean and format the raw data into a consistent format suitable for embedding and retrieval.
Parsing
After identifying the appropriate data sources for your retriever application, the next step is extracting the required information from the raw data. This process, known as parsing, involves transforming the unstructured data into a format that the RAG application can effectively use.
The specific parsing techniques and tools you use depend on the type of data you are working with. For example:
Text documents (PDFs, Word docs): Off-the-shelf libraries like unstructured and PyPDF2 can handle various file formats and provide options for customizing the parsing process.
HTML documents: HTML parsing libraries like BeautifulSoup and lxml can be used to extract relevant content from web pages. These libraries can help navigate the HTML structure, select specific elements, and extract the desired text or attributes.
Images and scanned documents: Optical Character Recognition (OCR) techniques are typically required to extract text from images. Popular OCR libraries include open source libraries such as Tesseract or SaaS versions like Amazon Textract, Azure AI Vision OCR, and Google Cloud Vision API.
Best practices for parsing data
Parsing ensures data is clean, structured, and ready for embedding generation and Vector Search. When parsing your data, consider the following best practices:
Data cleaning: Preprocess the extracted text to remove irrelevant or noisy information, such as headers, footers, or special characters. Reduce the amount of unnecessary or malformed information your RAG chain needs to process.
Handling errors and exceptions: Implement error handling and logging mechanisms to identify and resolve any issues encountered during the parsing process. This helps you to identify and fix problems quickly. Doing so often points to upstream issues with the quality of the source data.
Customizing parsing logic: Depending on the structure and format of your data, you may need to customize the parsing logic to extract the most relevant information. While it may require additional effort upfront, invest the time to do this if necessary, as it often prevents many downstream quality issues.
Evaluating parsing quality: Regularly assess the quality of the parsed data by manually reviewing a sample of the output. This can help you identify any issues or areas for improvement in the parsing process.
Enrichment
Enrich data with additional metadata and remove noise. Although enrichment is optional, it can drastically improve your application’s overall performance.
Metadata extraction
Generating and extracting metadata that captures essential information about the document's content, context, and structure can significantly improve a RAG application’s retrieval quality and performance. Metadata provides additional signals that improve relevance, enable advanced filtering, and support domain-specific search requirements.
While libraries such as LangChain and LlamaIndex provide built-in parsers capable of automatically extracting associated standard metadata, it is often helpful to supplement this with custom metadata tailored to your specific use case. This approach ensures that critical domain-specific information is captured, improving downstream retrieval and generation. You can also use large language models (LLMs) to automate metadata enhancement.
Types of metadata include:
Document-level metadata: File name, URLs, author information, creation and modification timestamps, GPS coordinates, and document versioning.
Content-based metadata: Extracted keywords, summaries, topics, named entities, and domain-specific tags (product names and categories like PII or HIPAA).
Structural metadata: Section headers, table of contents, page numbers, and semantic content boundaries (chapters or subsections).
Contextual metadata: Source system, ingestion date, data sensitivity level, original language, or transnational instructions.
Storing metadata alongside chunked documents or their corresponding embeddings is essential for optimal performance. It will also help narrow down the retrieved information and improve the accuracy and scalability of your application. Additionally, integrating metadata into hybrid search pipelines, which means combining vector similarity search with keyword-based filtering, can enhance relevance, especially in large datasets or specific search criteria scenarios.
Deduplication
Depending on your sources, you can end up with duplicate documents or near duplicates. For instance, if you pull from one or more shared drives, multiple copies of the same document could exist in multiple locations. Some of those copies may have subtle modifications. Similarly, your knowledge base may have copies of your product documentation or draft copies of blog posts. If these duplicates remain in your corpus, you can end up with highly redundant chunks in your final index that can decrease the performance of your application.
You can eliminate some duplicates using metadata alone. For instance, if an item has the same title and creation date but multiple entries from different sources or locations, you can filter those based on the metadata.
However, this may not be enough. To help identify and eliminate duplicates based on the content of the documents, you can use a technique known as locality-sensitive hashing. Specifically, a technique called MinHash works well here, and a Spark implementation is already available in Spark ML. It works by creating a hash for the document based on the words it contains and can then efficiently identify duplicates or near duplicates by joining on those hashes. At a very high level, this is a four-step process:
Create a feature vector for each document. If needed, consider applying techniques like stop word removal, stemming, and lemmatization to improve the results, and then tokenize into n-grams.
Run a similarity join using those hashes to produce a result set for each duplicate or a near duplicate document.
Filter out the duplicates you don't want to keep.
A baseline deduplication step can select the documents to keep arbitrarily (such as the first one in the results of each duplicate or a random choice among the duplicates). A potential improvement would be to select the “best” version of the duplicate using other logic (such as most recently updated, publication status, or most authoritative source). Also, note that you may need to experiment with the featurization step and the number of hash tables used in the MinHash model to improve the matching results.
Some of the documents you ingest into your corpus may not be useful for your agent, either because they are irrelevant to its purpose, too old or unreliable, or because they contain problematic content such as harmful language. Still, other documents may contain sensitive information you do not want to expose through your agent.
Therefore, consider including a step in your pipeline to filter out these documents by using any metadata, such as applying a toxicity classifier to the document to produce a prediction you can use as a filter. Another example would be applying a personally identifiable information (PII) detection algorithm to the documents to filter documents.
Finally, any document sources you feed into your agent are potential attack vectors for bad actors to launch data poisoning attacks. You can also consider adding detection and filtering mechanisms to help identify and eliminate those.
Chunking
After parsing the raw data into a more structured format, removing duplicates, and filtering out unwanted information, the next step is to break it down into smaller, manageable units called chunks. Segmenting large documents into smaller, semantically concentrated chunks ensures that retrieved data fits in the LLM’s context while minimizing the inclusion of distracting or irrelevant information. The choices made on chunking will directly affect the retrieved data the LLM provides, making it one of the first layers of optimization in an RAG application.
When chunking your data, consider the following factors:
Chunking strategy: The method you use to divide the original text into chunks. This can involve basic techniques such as splitting by sentences, paragraphs, specific character/token counts, and more advanced document-specific splitting strategies.
Chunk size: Smaller chunks may focus on specific details but lose some surrounding contextual information. Larger chunks may capture more context but can include irrelevant information or be computationally expensive.
Overlap between chunks: To ensure that important information is not lost when splitting the data into chunks, consider including some overlap between adjacent chunks. Overlapping can ensure continuity and context preservation across chunks and improve the retrieval results.
Semantic coherence: When possible, aim to create semantically coherent chunks that contain related information but can stand independently as a meaningful unit of text. This can be achieved by considering the structure of the original data, such as paragraphs, sections, or topic boundaries.
Metadata:Relevant metadata, such as the source document name, section heading, or product names, can improve retrieval. This additional information can help match retrieval queries to chunks.
Data chunking strategies
Finding the proper chunking method is both iterative and context-dependent. There is no one-size-fits-all approach. The optimal chunk size and method depends on the specific use case and the nature of the data being processed. Broadly, chunking strategies can be viewed as the following:
Fixed-size chunking: Split the text into chunks of a predetermined size, such as a fixed number of characters or tokens (for example, LangChain CharacterTextSplitter). While splitting by an arbitrary number of characters/tokens is quick and easy to set up, it will typically not result in consistent semantically coherent chunks. This approach rarely works for production-grade applications.
Paragraph-based chunking: Use the natural paragraph boundaries in the text to define chunks. This method can help preserve the chunks’ semantic coherence, as paragraphs often contain related information (for example, LangChain RecursiveCharacterTextSplitter).
Format-specific chunking: Formats such as Markdown or HTML have an inherent structure that can define chunk boundaries (for example, markdown headers). Tools like LangChain’s MarkdownHeaderTextSplitter or HTML header/section-based splitters can be used for this purpose.
Semantic chunking: Techniques such as topic modeling can be applied to identify semantically coherent sections in the text. These approaches analyze the content or structure of each document to determine the most appropriate chunk boundaries based on topic shifts. Although more involved than basic approaches, semantic chunking can help create chunks that are more aligned with the natural semantic divisions in the text (see LangChain SemanticChunker, for example).
Example: Fix-sized chunking
Fixed-size chunking example using LangChain’s RecursiveCharacterTextSplitter with chunk_size=100 and chunk_overlap=20. ChunkViz provides an interactive way to visualize how different chunk sizes and chunk overlap values with Langchain’s character splitters affect resulting chunks.
Embedding
After chunking your data, the next step is to convert the text chunks into a vector representation using an embedding model. An embedding model converts each text chunk into a vector representation that captures its semantic meaning. By representing chunks as dense vectors, embeddings allow fast and accurate retrieval of the most relevant chunks based on their semantic similarity to a retrieval query. The retrieval query will be transformed at query time using the same embedding model used to embed chunks in the data pipeline.
When selecting an embedding model, consider the following factors:
Model choice: Each embedding model has nuances, and the available benchmarks may not capture the specific characteristics of your data. It’s crucial to select a model that has been trained on similar data. It may also be beneficial to explore any available embedding models that are designed for specific tasks. Experiment with different off-the-shelf embedding models, even those that may be lower-ranked on standard leaderboards like MTEB. Some examples to consider:
Max tokens: Know the maximum token limit for your chosen embedding model. If you pass chunks that exceed this limit, they will be truncated, potentially losing important information. For example, bge-large-en-v1.5 has a maximum token limit of 512.
Model size: Larger embedding models generally perform better but require more computational resources. Based on your specific use case and available resources, you will need to balance performance and efficiency.
Fine-tuning: If your RAG application deals with domain-specific language (such as internal company acronyms or terminology), consider fine-tuning the embedding model on domain-specific data. This can help the model better capture the nuances and terminology of your particular domain and can often lead to improved retrieval performance.
Indexing and storage
The next step in the pipeline is to create indexes on the embeddings and the metadata generated in the previous steps. This stage involves organizing high-dimensional vector embeddings into efficient data structures that enable fast and accurate similarity searches.
Mosaic AI Vector Search uses the newest indexing techniques when you deploy a vector search endpoint and index to ensure fast and efficient lookups for your vector search queries. You don’t need to worry about testing and choosing the best indexing techniques.
After your index is built and deployed, it's ready to store in a system that supports scalable, low-latency queries. For production RAG pipelines with large datasets, use a vector database or scalable search service to ensure low latency and high throughput. Store additional metadata alongside embeddings to enable efficient filtering during retrieval.