สร้างการแสดงภาพข้อมูลผู้มีอิทธิพลหลัก
นําไปใช้กับ:![]() บริการของ Power BI Power BI Desktop
บริการของ Power BI Power BI Desktop ![]()
ภาพวิชวลของผู้มีอิทธิพลหลักช่วยให้คุณเข้าใจปัจจัยที่ขับเคลื่อนเมตริกที่คุณสนใจ ซึ่งวิเคราะห์ข้อมูลของคุณ จัดอันดับปัจจัยที่มีความสําคัญ และแสดงพวกเขาในฐานะผู้มีอิทธิพลหลัก ตัวอย่างเช่น สมมติว่าคุณต้องการค้นหาว่าอะไรมีผลต่อการหมุนเวียนพนักงาน ซึ่งเรียกอีกอย่างว่าการเลิกใช้บริการ ปัจจัยหนึ่งอาจเป็นระยะเวลาของสัญญาจ้างงาน และอีกปัจจัยหนึ่งอาจเป็นเวลาในการเดินทาง
เมื่อต้องใช้ผู้มีอิทธิพลหลัก
ภาพวิชวลของผู้มีอิทธิพลหลักเป็นตัวเลือกที่ยอดเยี่ยมหากคุณต้องการ:
- ดูว่าปัจจัยใดที่ส่งผลกระทบต่อเมตริกที่กําลังวิเคราะห์
- เปรียบเทียบความสําคัญที่เกี่ยวข้องของปัจจัยเหล่านี้ ตัวอย่างเช่น สัญญาระยะสั้นมีผลต่อการเลิกใช้บริการมากกว่าสัญญาระยะยาวหรือไม่?
คุณลักษณะภาพวิชวลของผู้มีอิทธิพลหลัก
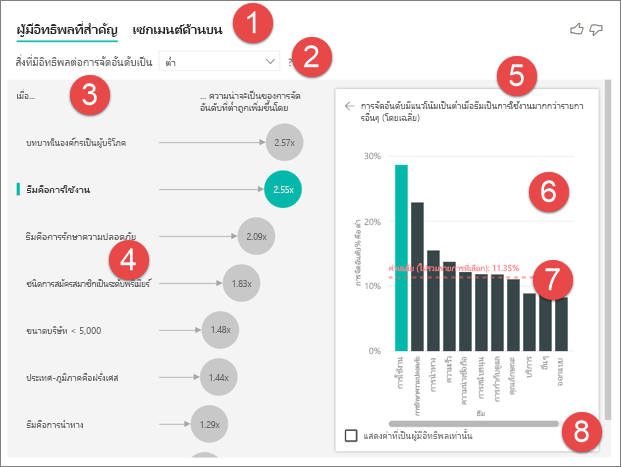
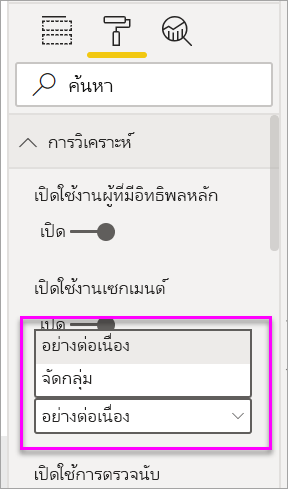
แท็บ: เลือกแท็บเพื่อสลับระหว่างมุมมอง ผู้ มีอิทธิพลหลักจะแสดงปัจจัยสนับสนุนสูงสุดต่อค่าเมตริกที่เลือก กลุ่มยอดนิยม จะแสดงกลุ่มที่มีส่วนร่วมสูงสุดต่อค่าเมตริกที่เลือก เซ กเมนต์ สร้างขึ้นจากชุดของค่า ตัวอย่างเช่น กลุ่มหนึ่งอาจเป็นผู้บริโภคที่เคยเป็นลูกค้ามาแล้วอย่างน้อย 20 ปีและอาศัยอยู่ในภาคตะวันตก
กล่องดรอปดาวน์: ค่าของเมตริกภายใต้การตรวจสอบ ในตัวอย่างนี้ ดูการให้คะแนนเมตริก ค่าที่เลือกคือ ต่ํา
การกล่าวใหม่: ช่วยเราตีความภาพวิชวลในบานหน้าต่างด้านซ้าย
บานหน้าต่างด้านซ้าย: บานหน้าต่างด้านซ้ายประกอบด้วยภาพวิชวลหนึ่งภาพ ในกรณีนี้ บานหน้าต่างด้านซ้ายจะแสดงรายชื่อของผู้มีอิทธิพลมากที่สุด
การกล่าวใหม่: ช่วยเราตีความภาพวิชวลในบานหน้าต่างด้านขวา
บานหน้าต่างด้านขวา: บานหน้าต่างด้านขวาประกอบด้วยภาพวิชวลหนึ่งภาพ ในกรณีนี้ แผนภูมิคอลัมน์แสดงค่าทั้งหมดสําหรับผู้ มีอิทธิพลหลัก, ธีม ที่เลือกไว้ในบานหน้าต่างด้านซ้าย ค่าเฉพาะของ ความสามารถในการ ใช้งานจากบานหน้าต่างด้านซ้ายจะแสดงเป็นสีเขียว ค่าอื่น ๆ ทั้งหมดสําหรับ ธีม จะแสดงเป็นสีดํา
เส้นเฉลี่ย: ค่าเฉลี่ยถูกคํานวณสําหรับค่าที่เป็นไปได้ทั้งหมดสําหรับ ธีม ยกเว้น ความสามารถในการ ใช้งาน (ซึ่งเป็นผู้มีอิทธิพลที่เลือก) ดังนั้นการคํานวณจึงนําไปใช้กับค่าทั้งหมดเป็นสีดํา ซึ่งบอกคุณว่าเปอร์เซ็นต์ของ ธีม อื่นมีคะแนนต่ําเท่าไหร่ ในกรณีนี้ 11.35% มีการให้คะแนนต่ํา (แสดงตามเส้นประ)
กล่องกาเครื่องหมาย: กรองภาพวิชวลออกในบานหน้าต่างด้านขวาเพื่อแสดงเฉพาะค่าที่เป็นผู้มีอิทธิพลสําหรับเขตข้อมูลนั้น ในตัวอย่างนี้ วิชวลจะถูกกรองให้แสดงความสามารถในการใช้งาน ความปลอดภัย และการนําทาง
วิเคราะห์เมตริกที่เป็นแบบจัดกลุ่ม
ดูวิดีโอนี้เพื่อเรียนรู้วิธีการสร้างภาพวิชวลของผู้มีอิทธิพลหลักด้วยเมตริกแบบจัดกลุ่ม จากนั้นทําตามขั้นตอนเพื่อสร้างหนึ่งรายการ
หมายเหตุ
วิดีโอนี้อาจใช้ Power BI Desktop หรือบริการของ Power BI เวอร์ชันก่อนหน้า
- ผู้จัดการผลิตภัณฑ์ของคุณต้องการให้คุณทราบว่าปัจจัยใดที่ทําให้ลูกค้าต้องแสดงความคิดเห็นเชิงลบเกี่ยวกับบริการคลาวด์ของคุณ หากต้องการทําตามใน Power BI Desktop ให้ เปิดไฟล์ PBIX คําติชมของลูกค้า
หมายเหตุ
ชุดข้อมูลคําติชมของลูกค้าขึ้นอยู่กับ [Moro et al., 2014] S. Moro, P. Cortez และ P. Rita "วิธีการที่ขับเคลื่อนด้วยข้อมูลเพื่อคาดการณ์ความสําเร็จของตลาดทางไกลของธนาคาร" ระบบสนับสนุนการตัดสินใจ, Elsevier, 62:22-31, มิถุนายน 2014
ภายใต้ สร้างวิชวล ในบานหน้าต่าง การแสดงภาพข้อมูล เลือกไอคอน ผู้ทรงอิทธิพลหลัก
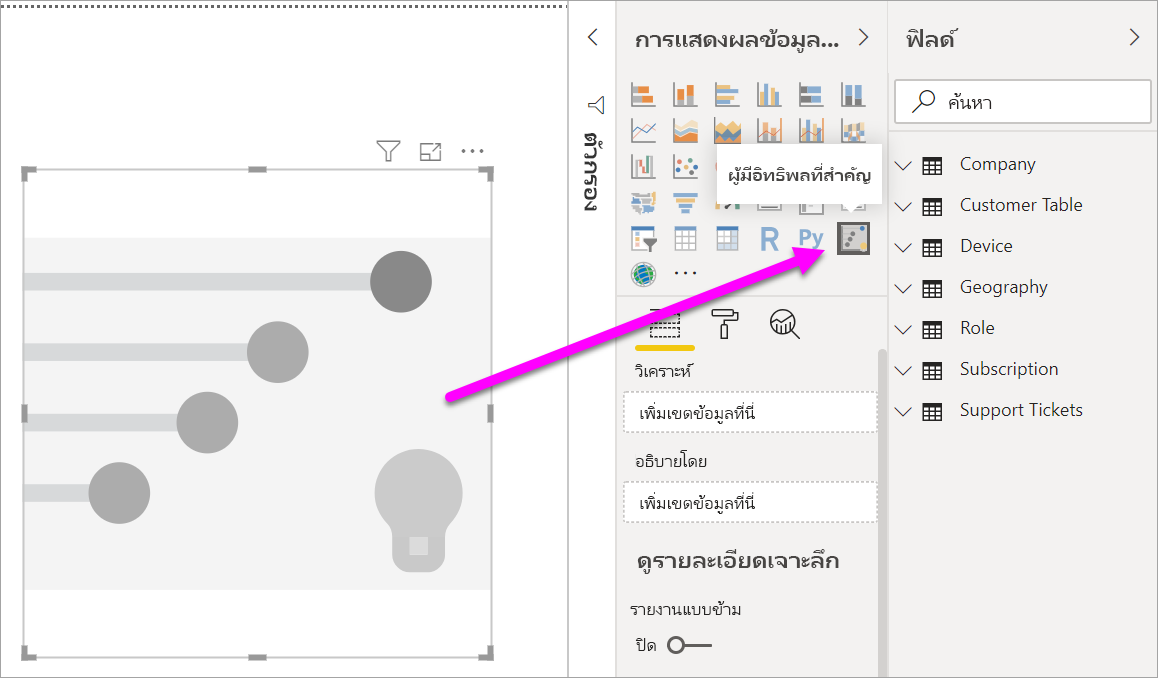
ย้ายเมตริกที่คุณต้องการตรวจสอบลงในเขตข้อมูล การวิเคราะห์ เมื่อต้องการดูสิ่งที่ขับเคลื่อนการให้คะแนนการบริการของลูกค้าต่ํา เลือกการจัดอันดับตาราง>ลูกค้า
ย้ายเขตข้อมูลที่คุณคิดว่ามีผลต่อ การจัดอันดับ ลงในเขตข้อมูล อธิบายโดย คุณสามารถย้ายเขตข้อมูลได้มากเท่าที่คุณต้องการ ในกรณีนี้ เริ่มต้นด้วย:
- ประเทศ-ภูมิภาค
- บทบาทในองค์กร
- ชนิดการสมัครใช้งาน
- ขนาดบริษัท
- Theme
ปล่อย เขตข้อมูลขยายโดย ว่างไว้ เขตข้อมูลนี้จะใช้เฉพาะเมื่อทําการวิเคราะห์เขตข้อมูลหน่วยวัดหรือเขตข้อมูลสรุป
เมื่อต้องการเน้นการให้คะแนนติดลบ ให้เลือก ต่ําในกล่องดรอปดาวน์ สิ่งที่มีผลต่อการให้คะแนนที่จะเป็น
การวิเคราะห์จะทํางานในระดับตารางของเขตข้อมูลที่กําลังวิเคราะห์ ในกรณีนี้ เป็นเมตริกการให้คะแนน เมตริกนี้ถูกกําหนดขึ้นในระดับลูกค้า ลูกค้าแต่ละรายได้รับคะแนนสูงหรือคะแนนต่ํา ปัจจัยการอธิบายทั้งหมดจะต้องกําหนดไว้ในระดับลูกค้าสําหรับภาพวิชวลเพื่อใช้ประโยชน์จากปัจจัยเหล่านั้น
ในตัวอย่างก่อนหน้านี้ ปัจจัยการอธิบายทั้งหมดมีความสัมพันธ์แบบหนึ่งต่อหนึ่งหรือกลุ่มต่อหนึ่งกับเมตริก ในกรณีนี้ ลูกค้าแต่ละรายกําหนดธีมเดียวให้กับการให้คะแนนของพวกเขา ในทํานองเดียวกัน ลูกค้ามาจากประเทศหรือภูมิภาคหนึ่ง มีประเภทสมาชิกหนึ่งประเภท และถือบทบาทหนึ่งในองค์กรของพวกเขา ปัจจัยการอธิบายนั้นเป็นแอตทริบิวต์ของลูกค้าอยู่แล้วและไม่จําเป็นต้องมีการแปลง วิชวลทําให้ใช้งานวิชวลเหล่านั้นได้ทันที
ต่อมาในบทช่วยสอน คุณจะได้ดูตัวอย่างที่ซับซ้อนมากขึ้นซึ่งมีความสัมพันธ์แบบหนึ่งต่อกลุ่ม ในกรณีดังกล่าว คอลัมน์จะต้องถูกรวมเข้ากับระดับลูกค้าก่อนจึงจะสามารถทําการวิเคราะห์ได้
หน่วยวัดและผลรวมที่ใช้เป็นปัจจัยการอธิบายจะถูกประเมินที่ระดับตารางของ เมตริกการวิเคราะห์ ด้วย ตัวอย่างบางส่วนจะแสดงในภายหลังในบทความนี้
ตีความผู้มีอิทธิพลหลักตามประเภท
ลองมาดูที่ผู้มีอิทธิพลหลักสําหรับการให้คะแนนต่ํา
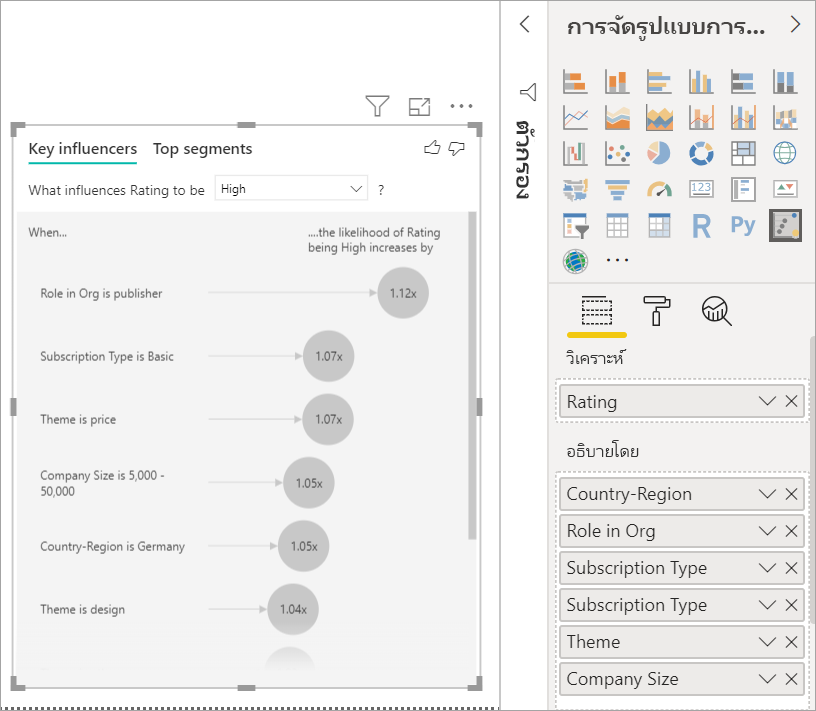
ปัจจัยเดียวอันดับแรกที่มีผลต่อความน่าจะเป็นของการให้คะแนนต่ํา
ลูกค้าในตัวอย่างนี้สามารถมีสามบทบาทได้แก่ ลูกค้า ผู้ดูแลระบบ และผู้เผยแพร่ การเป็นผู้บริโภคเป็นปัจจัยอันดับต้น ๆ ที่ส่งผลให้เกิดการให้คะแนนต่ํา
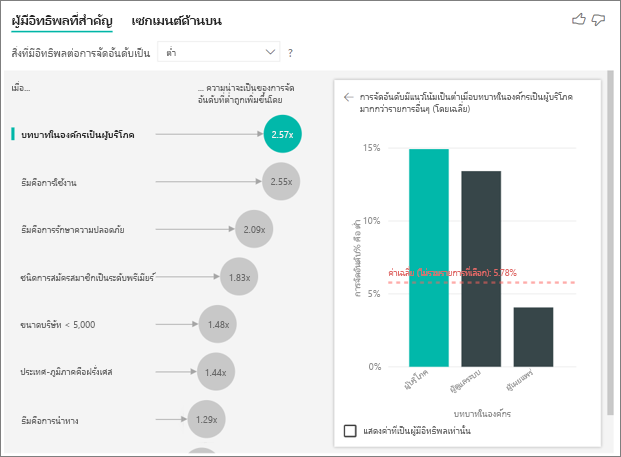
แม่นยํายิ่งขึ้น ผู้บริโภคของคุณมีแนวโน้มที่จะให้คะแนนการบริการติดลบ 2.57 เท่า แผนภูมิผู้มีอิทธิพลหลักแสดง บทบาทในองค์กรเป็นผู้บริโภค ก่อนในรายการด้านซ้าย โดยการเลือก บทบาทในองค์กรเป็นผู้บริโภค Power BI แสดงรายละเอียดเพิ่มเติมในบานหน้าต่างด้านขวา แสดงผลการเปรียบเทียบของแต่ละบทบาทเกี่ยวกับความน่าจะเป็นของการให้คะแนนต่ํา
- ลูกค้า 14.93% ให้คะแนนต่ํา
- โดยเฉลี่ยบทบาทอื่น ๆ ทั้งหมดให้คะแนนของเวลาต่ํา 5.78%
- ลูกค้ามีแนวโน้มที่จะให้คะแนนต่ํา 2.57 เท่าเมื่อเปรียบเทียบกับบทบาทอื่น ๆ ทั้งหมด คุณสามารถตรวจสอบคะแนนนี้ได้โดยการแบ่งแถบสีเขียวด้วยเส้นประสีแดง
ปัจจัยเดียวอันดับที่สองที่มีผลต่อความน่าจะเป็นของการให้คะแนนต่ํา
ภาพวิชวลของผู้มีอิทธิพลหลักจะเปรียบเทียบและจัดลําดับปัจจัยจากตัวแปรที่แตกต่างกันมากมาย ผู้มีอิทธิพลคนที่สองไม่มีส่วนเกี่ยวข้องกับ บทบาทในองค์กร เลือกผู้มีอิทธิพลลําดับที่สองในรายการ ซึ่งก็คือ ธีมเป็นความสามารถในการใช้งาน
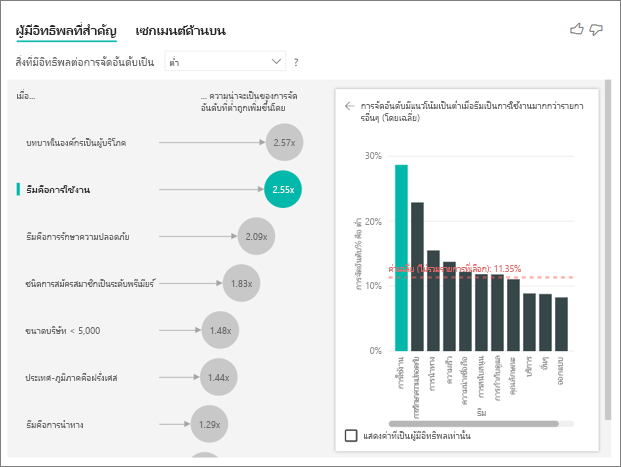
ปัจจัยที่สําคัญที่สุดอันดับสองเกี่ยวข้องกับธีมการรีวิวของลูกค้า ลูกค้าที่แสดงความคิดเห็นเกี่ยวกับความสามารถในการใช้งานของผลิตภัณฑ์มีแนวโน้มที่จะให้คะแนนต่ํา 2.55 เท่าเมื่อเปรียบเทียบกับลูกค้าที่แสดงความคิดเห็นในหัวข้ออื่น ๆ เช่น ความน่าเชื่อถือ การออกแบบ หรือความเร็ว
ระหว่างภาพวิชวล ค่าเฉลี่ยซึ่งแสดงด้วยเส้นประสีแดง จะเปลี่ยนจาก 5.78% เป็น 11.35% ค่าเฉลี่ยเป็นแบบไดนามิกเนื่องจากเป็นไปตามค่าเฉลี่ยของค่าอื่นทั้งหมด สําหรับผู้มีอิทธิพลคนแรก ค่าเฉลี่ยไม่รวมบทบาทของลูกค้า สําหรับผู้มีอิทธิพลที่สอง จะแยกออกจากธีมความสามารถในการใช้งาน
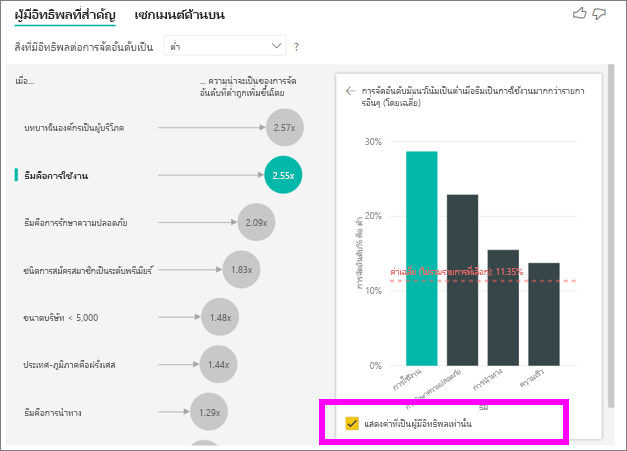
เลือกกล่องกา เครื่องหมาย แสดงเฉพาะค่าที่เป็นผู้ มีอิทธิพลเท่านั้น เพื่อกรองโดยใช้เฉพาะค่าที่มีอิทธิพลเท่านั้น ในกรณีนี้ พวกเขามีบทบาทที่มีผลทําให้คะแนนต่ํา ธีม 12 แบบจะลดลงเหลือสี่แบบที่ Power BI ระบุว่าเป็นธีมที่ขับเคลื่อนการจัดอันดับต่ํา
โต้ตอบกับวิชวลอื่น ๆ
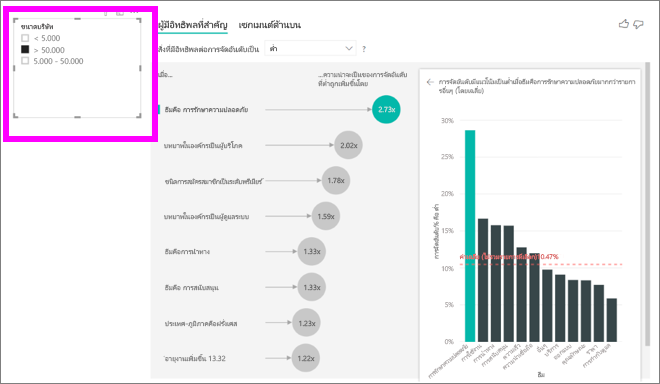
ทุกครั้งที่คุณเลือกตัวแบ่งส่วนข้อมูล ตัวกรอง หรือวิชวลอื่น ๆ บนพื้นที่ทํางาน ผู้มีอิทธิพลหลักจะรันการวิเคราะห์ซ้ําในส่วนของข้อมูลใหม่ ตัวอย่างเช่น คุณสามารถย้าย ขนาด บริษัทลงในรายงานและใช้เป็นตัวแบ่งส่วนข้อมูลได้ ใช้เพื่อดูว่าผู้มีอิทธิพลหลักสําหรับลูกค้าองค์กรของคุณแตกต่างจากประชากรทั่วไปหรือไม่ บริษัทขนาดใหญ่มีพนักงานมากกว่า 50,000 คน
เลือก >50,000 เพื่อรีรันการวิเคราะห์อีกครั้ง และคุณจะเห็นว่าผู้มีอิทธิพลมีการเปลี่ยนแปลง สําหรับลูกค้าระดับองค์กรขนาดใหญ่ ผู้มีอิทธิพลสูงสุดสําหรับการให้คะแนนต่ํามีธีมที่เกี่ยวข้องกับความปลอดภัย คุณอาจต้องการตรวจสอบเพิ่มเติมเพื่อดูว่ามีคุณลักษณะด้านความปลอดภัยที่เฉพาะเจาะจงที่ลูกค้ารายใหญ่ของคุณไม่พึงพอใจหรือไม่
ตีความผู้มีอิทธิพลหลักอย่างต่อเนื่อง
จนถึงตอนนี้ คุณได้เห็นวิธีการใช้วิชวลเพื่อสํารวจว่าเขตข้อมูลตามประเภทที่แตกต่างกันส่งผลต่อการให้คะแนนต่ําอย่างไร นอกจากนี้ยังเป็นไปได้ที่จะมีปัจจัยต่อเนื่องเช่นอายุ ความสูง และราคาในเขตข้อมูล อธิบายโดย มาดูกันว่าเกิดอะไรขึ้นเมื่อย้ายระยะเวลาการครอบครองจากตารางลูกค้าไปยังอธิบายโดย ระยะเวลาการครอบครองแสดงถึงระยะเวลาที่ลูกค้าใช้บริการ
เมื่อระยะเวลาการครอบครองเพิ่มขึ้น โอกาสที่จะได้รับการจัดอันดับต่ํากว่าก็เพิ่มขึ้นเช่นกัน แนวโน้มนี้แสดงให้เห็นว่าลูกค้าระยะยาวมากขึ้นมีแนวโน้มที่จะให้คะแนนติดลบ ข้อมูลเชิงลึกนี้น่าสนใจ และข้อมูลที่คุณอาจต้องการติดตามในภายหลัง
การแสดงภาพข้อมูลแสดงให้เห็นว่าทุกครั้งที่ระยะเวลาการครอบครองเพิ่มขึ้น 13.44 เดือน โดยเฉลี่ยความน่าจะเป็นของการให้คะแนนต่ําเพิ่มขึ้น 1.23 เท่า ในกรณีนี้ 13.44 เดือนแสดงถึงค่าเบี่ยงเบนมาตรฐานของระยะเวลาการครอบครอง ดังนั้นข้อมูลเชิงลึกที่คุณได้รับจะดูว่าการเพิ่มระยะเวลาการครอบครองตามปริมาณมาตรฐานซึ่งเป็นค่าเบี่ยงเบนมาตรฐานของระยะเวลาการครอบครองส่งผลกระทบต่อโอกาสที่จะได้รับการให้คะแนนต่ําอย่างไร
แผนภูมิกระจายในบานหน้าต่างด้านขวาจะกําหนดเปอร์เซ็นต์เฉลี่ยของการให้คะแนนต่ําสําหรับแต่ละค่าของระยะเวลาการครอบครอง ซึ่งจะเน้นความลาดชันด้วยเส้นแนวโน้ม
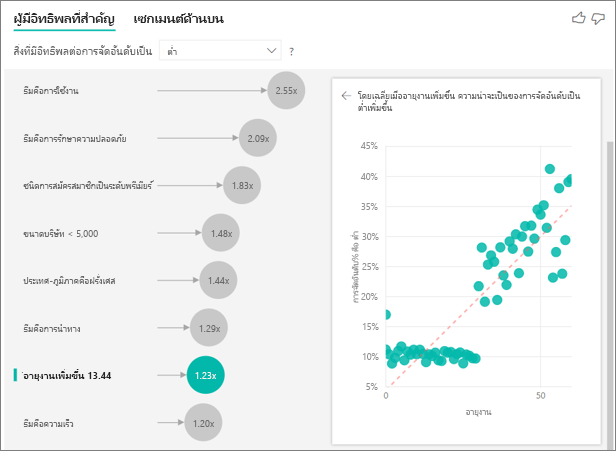
ผู้มีอิทธิพลหลักอย่างต่อเนื่องที่ผูกไว้
ในบางกรณี คุณอาจพบว่าปัจจัยแบบต่อเนื่องจะถูกเปลี่ยนเป็นปัจจัยตามประเภทโดยอัตโนมัติ ถ้าความสัมพันธ์ระหว่างตัวแปรไม่ใช่เชิงเส้น เราไม่สามารถอธิบายความสัมพันธ์ได้ว่าเป็นการเพิ่มหรือลดลง (อย่างที่เราทําในตัวอย่างด้านบน)
เราดําเนินการทดสอบความสัมพันธ์เพื่อกําหนดวิธีการเชิงเส้นที่ผู้มีอิทธิพลที่เกี่ยวข้องกับเป้าหมาย ถ้าเป้าหมายเป็นแบบต่อเนื่อง เราจะเรียกใช้ความสัมพันธ์แบบ Pearson และถ้าเป้าหมายเป็นแบบจัดกลุ่ม เราจะดําเนินการทดสอบความสัมพันธ์แบบ Biserial Point ถ้าเราตรวจพบว่าความสัมพันธ์ไม่เป็นเชิงเส้นพอ เราจะดําเนินการจัดช่องเก็บแบบควบคุมและสร้างช่องเก็บได้สูงสุดห้าช่อง หากต้องการทราบว่าช่องเก็บใดที่เหมาะสมมากที่สุด เราใช้วิธีการจัดช่องเก็บแบบควบคุมที่ดูความสัมพันธ์ระหว่างปัจจัยการอธิบายและเป้าหมายที่กําลังวิเคราะห์
ตีความหน่วยวัดและผลรวมเป็นผู้มีอิทธิพลหลัก
คุณสามารถใช้หน่วยวัดและผลรวมเป็นปัจจัยการอธิบายในการวิเคราะห์ของคุณได้ ตัวอย่างเช่น คุณอาจต้องการดูว่าอะไรส่งผลกระทบต่อจํานวนตั๋วการสนับสนุนของลูกค้าหรือระยะเวลาเฉลี่ยของตั๋วเปิดที่มีต่อคะแนนที่คุณได้รับ
ในกรณีนี้ คุณต้องการดูว่าจํานวนตั๋วการสนับสนุนที่ลูกค้ามีอิทธิพลต่อคะแนนที่พวกเขาให้หรือไม่ ในตอนนี้ คุณนํา ID ตั๋วการสนับสนุนมาจากตารางตั๋วการสนับสนุน เนื่องจากลูกค้าสามารถมีตั๋วการสนับสนุนได้หลายใบ คุณจึงต้องรวม ID กับระดับลูกค้า การรวมมีความสําคัญเนื่องจากการวิเคราะห์ทํางานในระดับลูกค้า ดังนั้นจําเป็นต้องกําหนดตัวขับเคลื่อนทั้งหมดที่ระดับความละเอียดนั้น
มาดูที่จํานวนของรหัส ลูกค้าแต่ละแถวมีจํานวนตั๋วการสนับสนุนที่เกี่ยวข้องกัน ในกรณีนี้ เมื่อจํานวนตั๋วการสนับสนุนเพิ่มขึ้น โอกาสในการจัดอันดับต่ําจะเพิ่มขึ้น 4.08 เท่า ภาพวิชวลด้านขวาแสดงจํานวนตั๋วสนับสนุนโดยเฉลี่ยตามค่าการจัดอันดับที่ต่างกันโดยประเมินที่ระดับลูกค้า
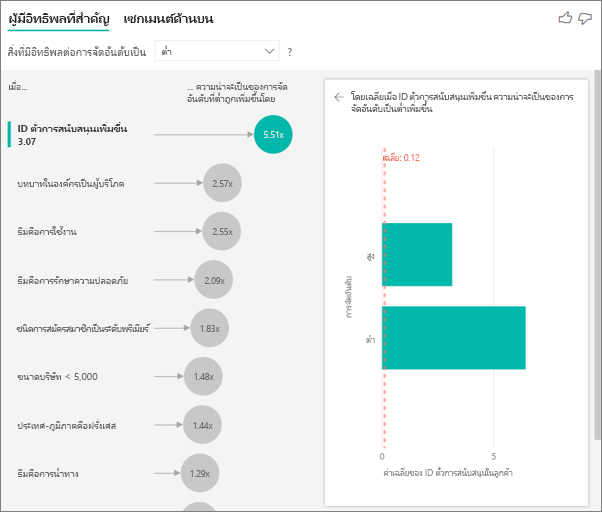
ตีความผลลัพธ์: เซกเมนต์ด้านบน
คุณสามารถใช้ แท็บ ผู้ มีอิทธิพลหลัก เพื่อประเมินปัจจัยแต่ละรายการได้ คุณยังสามารถใช้ แท็บ เซก เมนต์ด้านบน เพื่อดูวิธีชุดปัจจัยมีผลต่อเมตริกที่คุณกําลังวิเคราะห์อยู่นั้นได้
เซกเมนต์ด้านบนเริ่มแสดงภาพรวมของเซกเมนต์ทั้งหมดที่ Power BI ค้นพบ ตัวอย่างต่อไปนี้แสดงหกเซกเมนต์ที่ค้นพบ เซกเมนต์เหล่านี้จะถูกจัดอันดับตามเปอร์เซ็นต์ของการให้คะแนนต่ําภายในเซกเมนต์ ตัวอย่างเช่น เซกเมนต์ 1 มีลูกค้าให้คะแนน 74.3% ซึ่งเป็นค่าที่ต่ํา ยิ่งฟองสบู่สูงขึ้น สัดส่วนการจัดอันดับต่ําก็จะสูงขึ้นตาม ขนาดของฟองสบู่แสดงถึงจํานวนลูกค้าที่อยู่ในเซกเมนต์
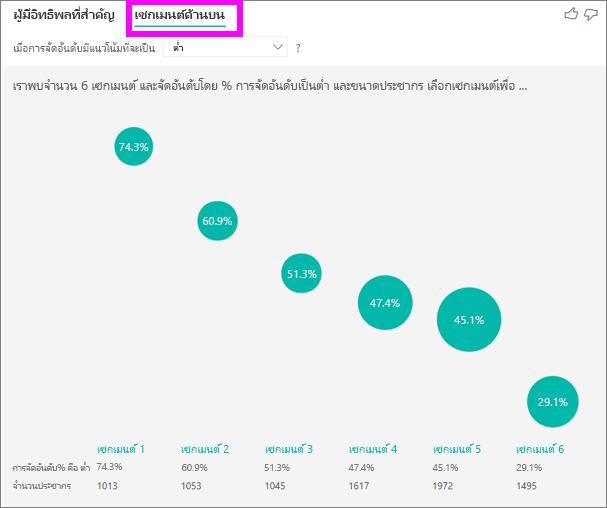
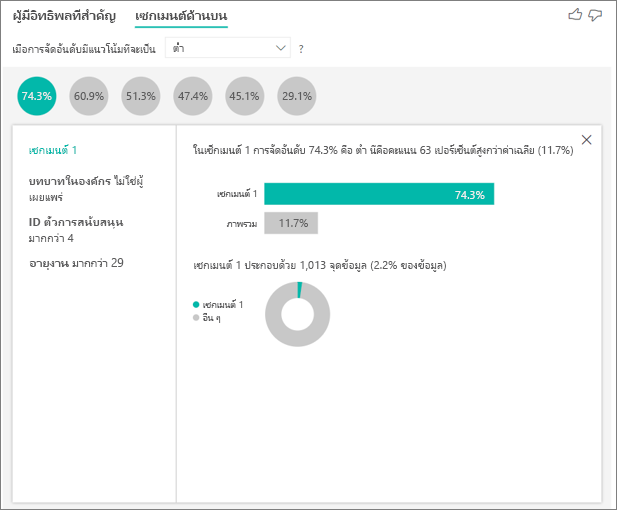
การเลือกฟองสบู่จะแสดงรายละเอียดของเซกเมนต์นั้น ตัวอย่างเช่น ถ้าคุณเลือกเซกเมนต์ 1 คุณจะพบว่าเป็นเซกเมนต์ของลูกค้าที่มีชื่อเสียง พวกเขาเป็นลูกค้ามาแล้วกว่า 29 เดือนและมีตั๋วการสนับสนุนมากกว่าสี่ใบ ท้ายที่สุด พวกเขาไม่ใช่ผู้เผยแพร่ ดังนั้นพวกเขาจึงเป็นได้ทั้งลูกค้าหรือผู้ดูแลระบบ
ในกลุ่มนี้ 74.3% ของลูกค้าให้คะแนนต่ํา ลูกค้าโดยเฉลี่ยให้คะแนนต่ํา 11.7% ของเวลา ดังนั้นเซกเมนต์นี้มีสัดส่วนการให้คะแนนต่ํามากขึ้น ซึ่งมีคะแนนร้อยละ 63 สูงขึ้น นอกจากนี้เซกเมนต์ 1 ยังประกอบด้วยข้อมูลประมาณ 2.2% ของข้อมูลดังนั้นจึงเป็นส่วนที่สามารถระบุตําแหน่งของประชากรได้
การเพิ่มจํานวน
ในบางครั้งผู้มีอิทธิพลอาจมีผลกระทบที่สําคัญ แต่แสดงข้อมูลเพียงเล็กน้อย ตัวอย่างเช่น ธีม คือ ความสามารถในการ ใช้งานเป็นผู้มีอิทธิพลใหญ่ที่สุดอันดับสามสําหรับการให้คะแนนต่ํา อย่างไรก็ตามอาจมีลูกค้าจํานวนเล็กน้อยเท่านั้นที่บ่นเกี่ยวกับความสามารถในการใช้งาน การนับจํานวนสามารถช่วยให้คุณจัดลําดับความสําคัญของผู้มีอิทธิพลที่คุณต้องการมุ่งเน้นได้
คุณสามารถเปิดใช้งานจํานวนผ่าน การ์ด การวิเคราะห์ของบานหน้าต่างการจัดรูปแบบได้
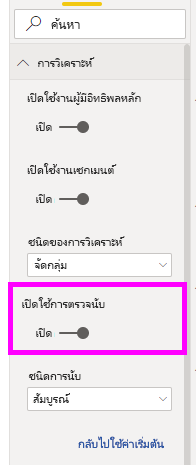
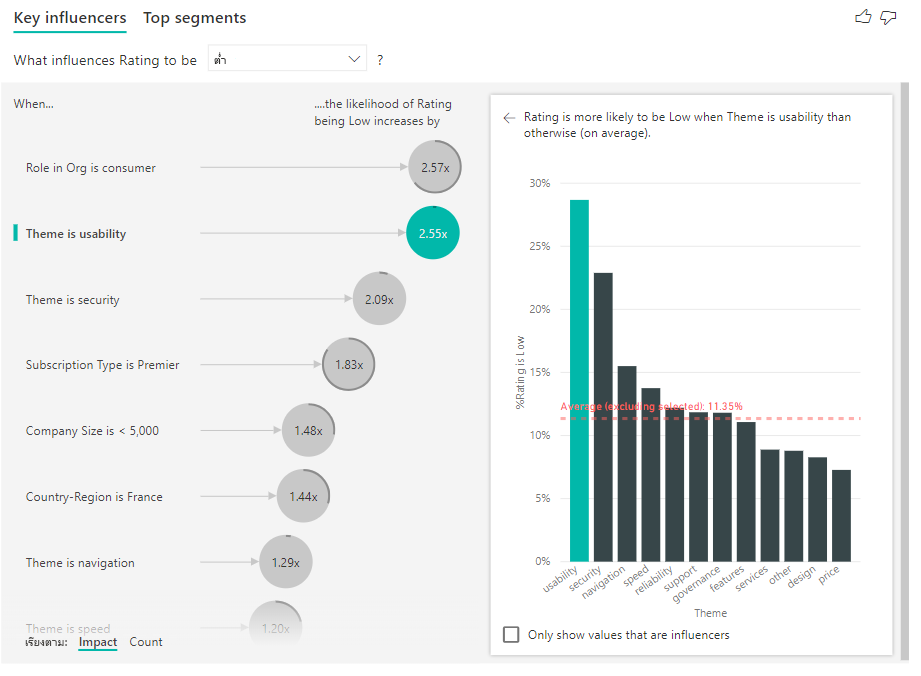
หลังจากเปิดใช้งานจํานวนแล้ว คุณจะเห็นวงแหวนรอบ ๆ ฟองของผู้มีอิทธิพลแต่ละราย ซึ่งแสดงถึงเปอร์เซ็นต์ของข้อมูลโดยประมาณที่ผู้มีอิทธิพลประกอบด้วย ยิ่งฟองของวงแหวนกลมมากขึ้นเท่าไหร่ ก็ยิ่งมีข้อมูลประกอบในนั้นมากขึ้นเท่านั้น เราสามารถเห็นได้ว่า ธีม มี ความสามารถในการ ใช้งานประกอบด้วยสัดส่วนข้อมูลขนาดเล็ก
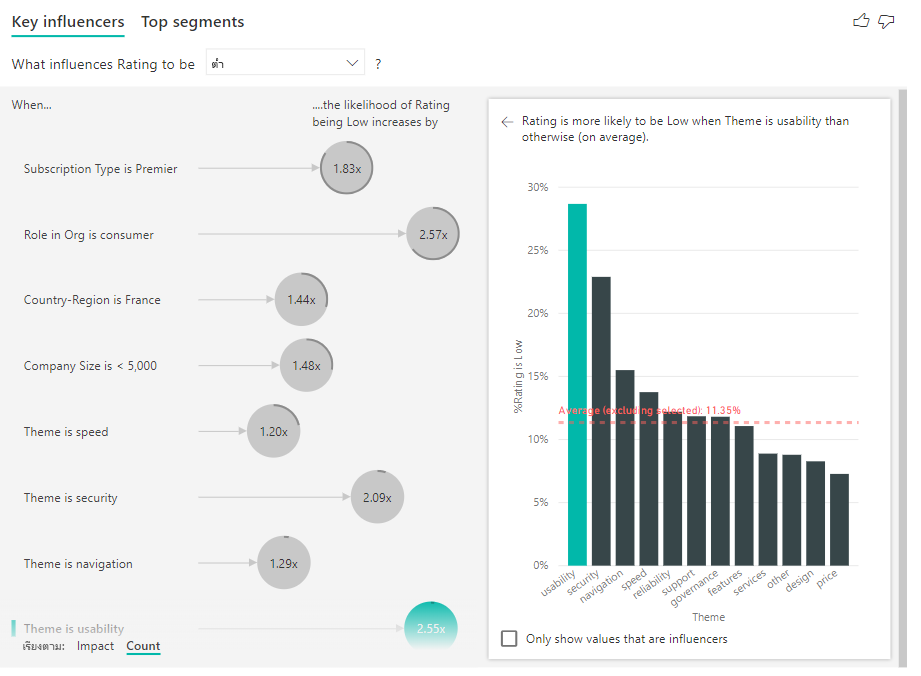
คุณยังสามารถใช้การเรียงลําดับโดยการสลับที่ด้านล่างซ้ายของวิชวลเพื่อเรียงลําดับฟองตามจํานวนครั้งแรกแทนผลกระทบ ชนิด การสมัครสมาชิกคือ Premier คือ ผู้มีอิทธิพลสูงสุดยึดตามจํานวน
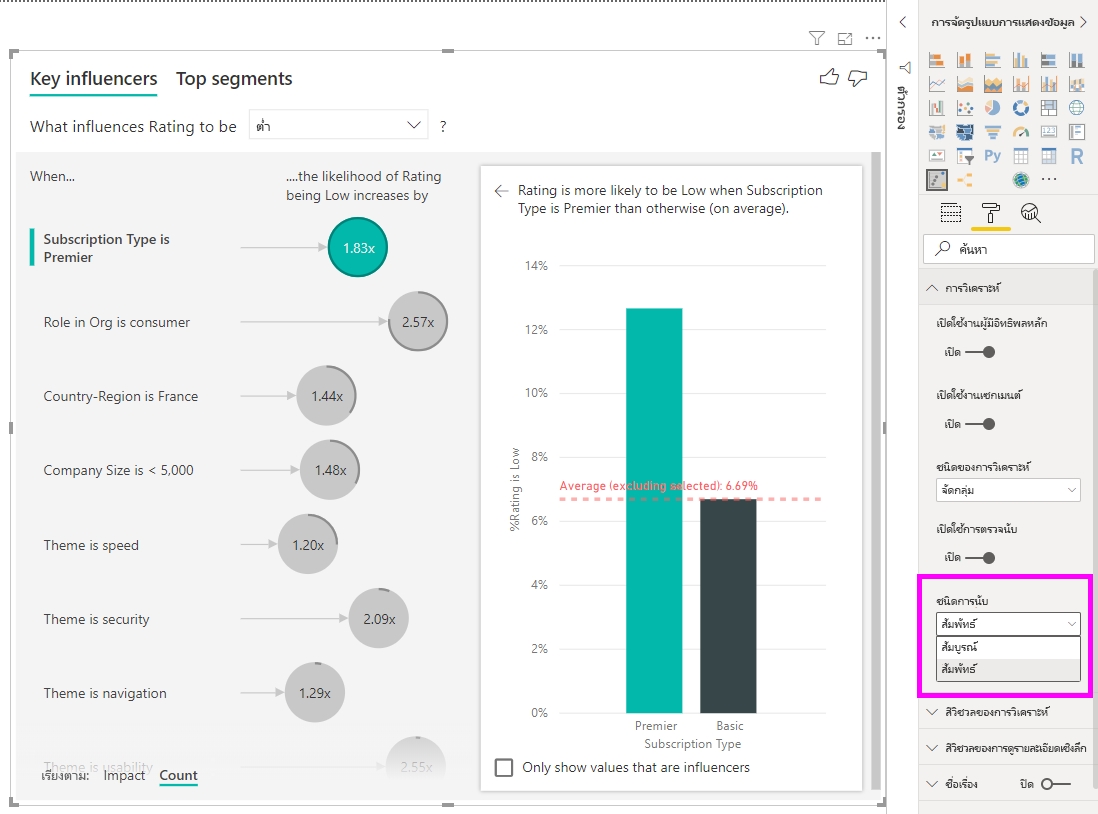
การมีวงแหวนแบบเต็มรอบวงกลมหมายความว่าผู้มีอิทธิพลนั้นประกอบด้วยข้อมูล 100% คุณสามารถเปลี่ยนชนิดจํานวนให้สัมพันธ์กับผู้มีอิทธิพลสูงสุดได้โดยใช้รายการ แบบเลื่อนลงชนิด จํานวนใน การ์ด การวิเคราะห์ของบานหน้าต่างการจัดรูปแบบ ตอนนี้ผู้มีอิทธิพลที่มีจํานวนข้อมูลมากที่สุดจะถูกแสดงด้วยวงแหวนแบบเต็มและจํานวนอื่น ๆ ทั้งหมดจะสัมพันธ์กับมัน
วิเคราะห์เมตริกที่เป็นตัวเลข
หากคุณย้ายเขตข้อมูลตัวเลขที่ไม่ได้สรุปไปยัง เขตข้อมูล การวิเคราะห์ คุณสามารถเลือกวิธีการจัดการสถานการณ์นั้น คุณสามารถเปลี่ยนลักษณะการทํางานของวิชวลโดยการเข้าไปที่ บานหน้าต่าง การจัดรูปแบบและการสลับไปมาระหว่าง ประเภท การวิเคราะห์ตามประเภทและ ประเภทการวิเคราะห์แบบต่อเนื่องได้
ประเภทการวิเคราะห์ตามประเภทจะมีลักษณะการทํางานตามที่อธิบายไว้ข้างต้น ตัวอย่างเช่น ถ้าคุณกําลังดูคะแนนการสํารวจตั้งแต่ 1 ถึง 10 คุณสามารถถามว่า "สิ่งใดที่มีผลทําให้คะแนนการสํารวจได้ 1 คะแนน"
ประเภทการวิเคราะห์แบบต่อเนื่องจะเปลี่ยนคําถามเป็นคําถามแบบต่อเนื่อง ในตัวอย่างข้างต้น คําถามใหม่ของเราจะเป็น "สิ่งใดที่มีผลทําให้คะแนนการสํารวจเพิ่มขึ้น/ลดลง"
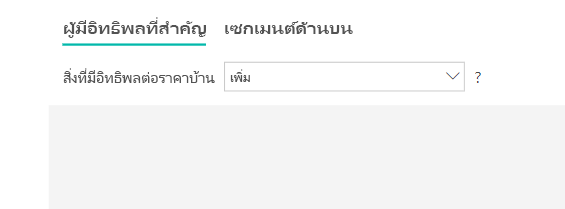
ความแตกต่างนี้จะมีประโยชน์เมื่อคุณมีค่าที่ไม่ซ้ํากันจํานวนมากในเขตข้อมูลที่คุณกําลังวิเคราะห์อยู่ ในตัวอย่างด้านล่าง เราจะดูราคาบ้าน การถามว่า "สิ่งใดที่มีผลทําให้ราคาบ้านเท่ากับ 156,214" เนื่องจากข้อมูลนั้นเจาะจงมากและเราไม่มีข้อมูลเพียงพอที่จะอนุมานรูปแบบได้
แต่เราอาจต้องการถามว่า "สิ่งใดที่มีผลทําให้ราคาบ้านเพิ่มขึ้น" ซึ่งช่วยให้เราสามารถกําหนดราคาบ้านเป็นช่วง ๆ แทนที่จะเป็นค่าเฉพาะ
ตีความผลลัพธ์: ผู้มีอิทธิพลหลัก
หมายเหตุ
ตัวอย่างในส่วนนี้ใช้ข้อมูลราคาบ้านของโดเมนสาธารณะ คุณสามารถ ดาวน์โหลดชุดข้อมูล ตัวอย่างได้ถ้าคุณต้องการทําตาม
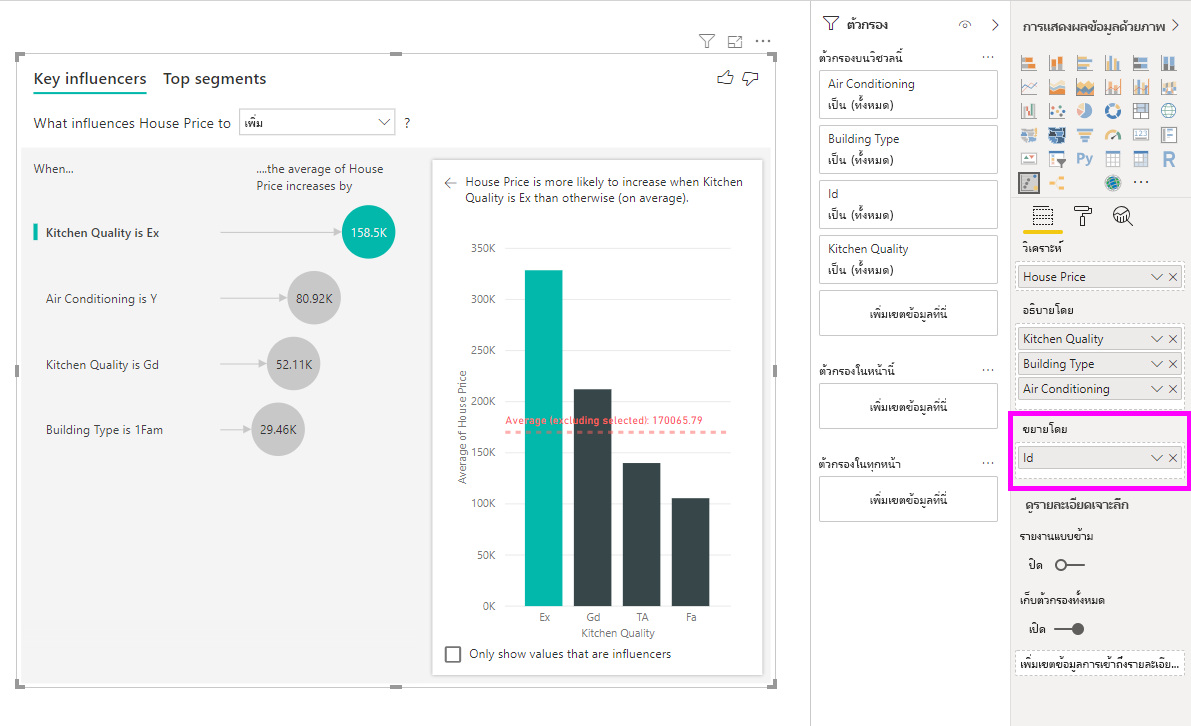
ในสถานการณ์นี้ เราจะมาดูว่า "สิ่งใดที่มีผลทําให้ราคาบ้านเพิ่มขึ้น" ปัจจัยการอธิบายจํานวนหนึ่งอาจส่งผลกระทบต่อราคาบ้าน เช่น ปีที่สร้าง (ปีที่สร้างบ้าน), KitchenQual (คุณภาพห้องครัว) และ YearRemodAdd (ปีที่ปรับปรุงบ้าน)
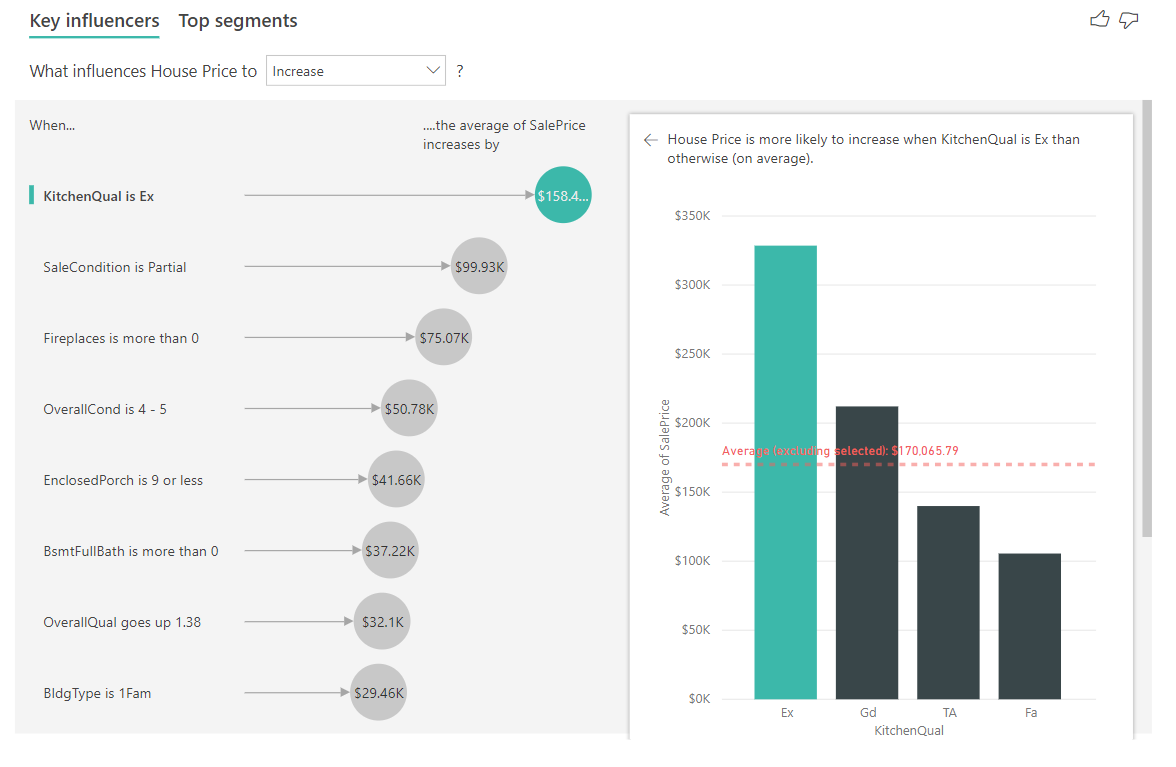
ในตัวอย่างด้านล่าง เราจะดูที่ผู้มีอิทธิพลสูงสุดของเราซึ่งห้องครัวมีคุณภาพดีเยี่ยม ผลลัพธ์จะคล้ายกับที่เราเห็นเมื่อเราวิเคราะห์เมตริกตามประเภทด้วยความแตกต่างที่สําคัญสองสามประการ:
- แผนภูมิคอลัมน์ทางด้านขวาแสดงค่าเฉลี่ยแทนที่จะเป็นเปอร์เซ็นต์ ดังนั้นจึงแสดงให้เราเห็นราคาบ้านโดยเฉลี่ยของบ้านพร้อมห้องครัวที่คุณภาพดี (แถบสีเขียว) เทียบกับราคาบ้านโดยเฉลี่ยของบ้านที่ไม่มีห้องครัวที่คุณภาพดี (เส้นประ)
- ตัวเลขในแผนภูมิฟองยังคงความแตกต่างระหว่างเส้นประสีแดงและแถบสีเขียว แต่จะแสดงเป็นตัวเลข ($158.49K) แทนที่จะเป็นความน่าเป็น (1.93x) ดังนั้นโดยเฉลี่ยแล้วบ้านพร้อมห้องครัวที่คุณภาพดีจะมีราคาเกือบ $160K แพงกว่าบ้านที่ไม่มีห้องครัวที่คุณภาพดี
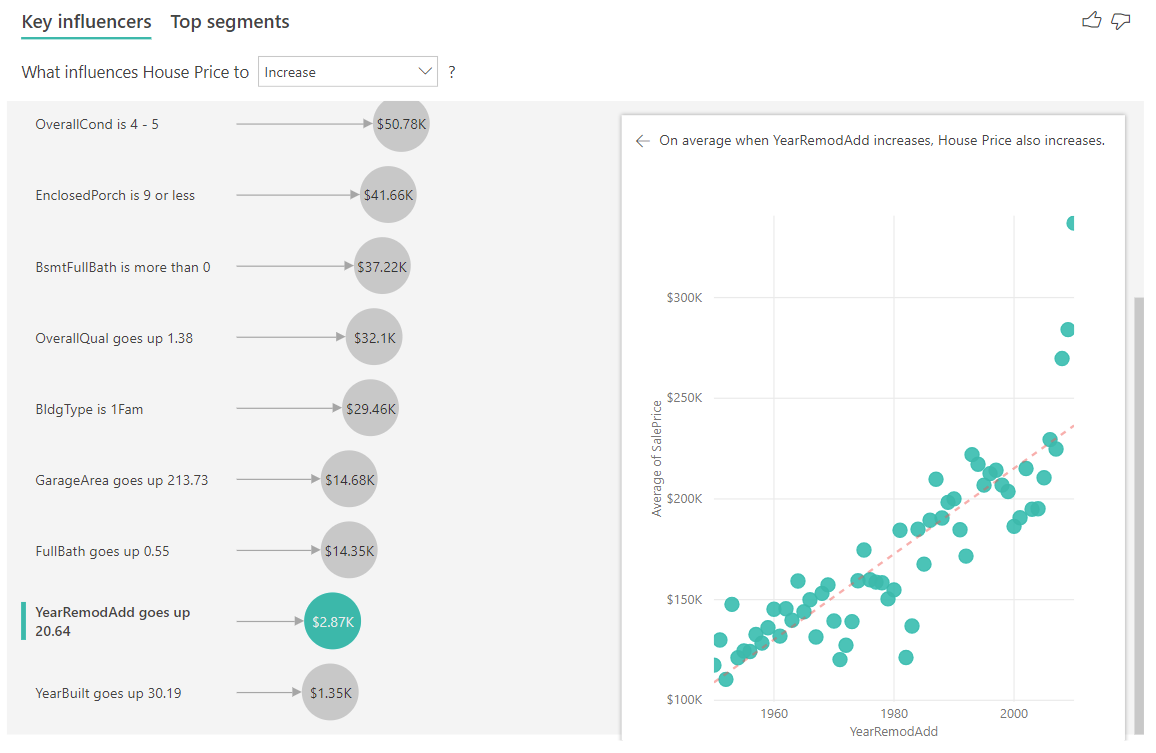
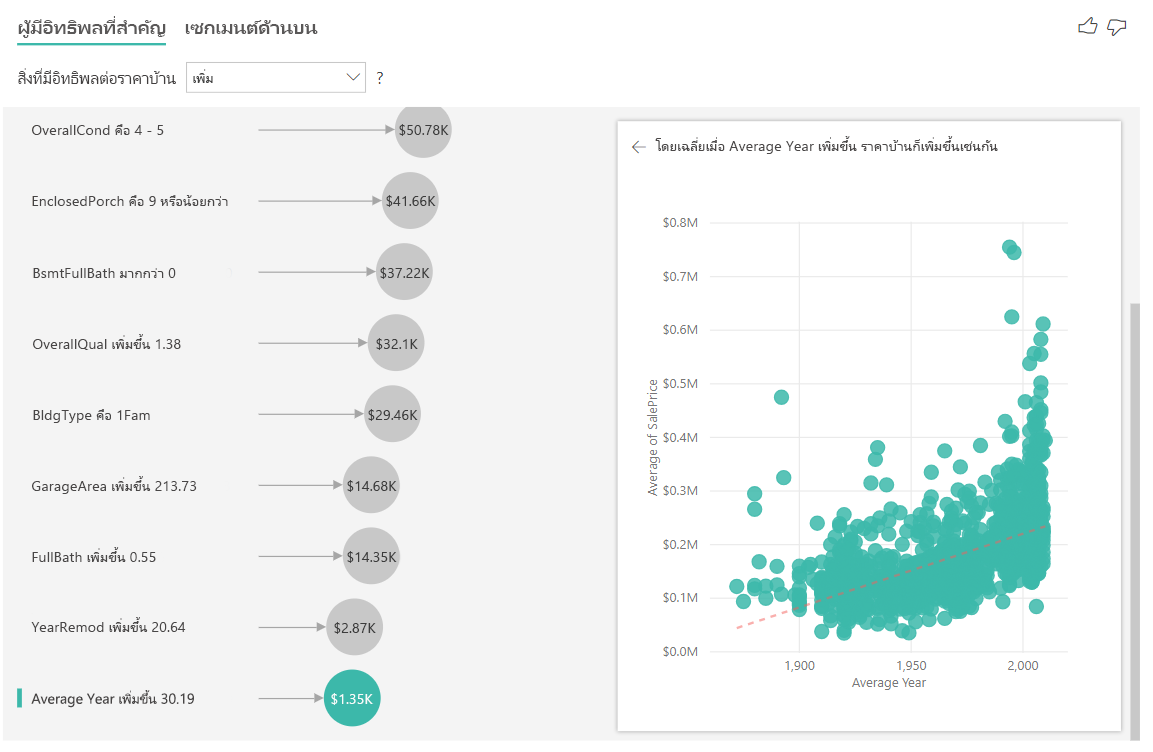
ในตัวอย่างด้านล่าง เราจะดูผลกระทบที่ปัจจัยแบบต่อเนื่อง (ปีที่ปรับปรุงบ้าน) มีต่อราคาบ้าน ความแตกต่างเมื่อเทียบกับวิธีที่เราวิเคราะห์ผู้มีอิทธิพลแบบต่อเนื่องสําหรับเมตริกตามประเภทมีดังนี้:
- แผนภูมิกระจายในบานหน้าต่างด้านขวาจะกําหนดราคาบ้านโดยเฉลี่ยสําหรับค่าเฉพาะแต่ละค่าของปีที่ปรับปรุง
- ค่าในแผนภูมิฟองจะแสดงตามจํานวนราคาบ้านโดยเฉลี่ยที่เพิ่มขึ้น (ในกรณีนี้คือ $2.87k) เมื่อจํานวนปีที่ปรับปรุงบ้านเพิ่มขึ้นตามค่าเบี่ยงเบนมาตรฐาน (ในกรณีนี้คือ 20 ปี)
สุดท้าย ในกรณีของการวัด เราจะดูปีที่สร้างบ้านโดยเฉลี่ย การวิเคราะห์มีดังนี้:
- แผนภูมิกระจายในบานหน้าต่างด้านขวาจะกําหนดราคาบ้านโดยเฉลี่ยสําหรับค่าเฉพาะแต่ละค่าในตาราง
- ค่าในแผนภูมิฟองจะแสดงตามจํานวนราคาบ้านโดยเฉลี่ยที่เพิ่มขึ้น (ในกรณีนี้คือ $1.35K) เมื่อจํานวนปีโดยเฉลี่ยเพิ่มขึ้นตามค่าเบี่ยงเบนมาตรฐาน (ในกรณีนี้คือ 30 ปี)
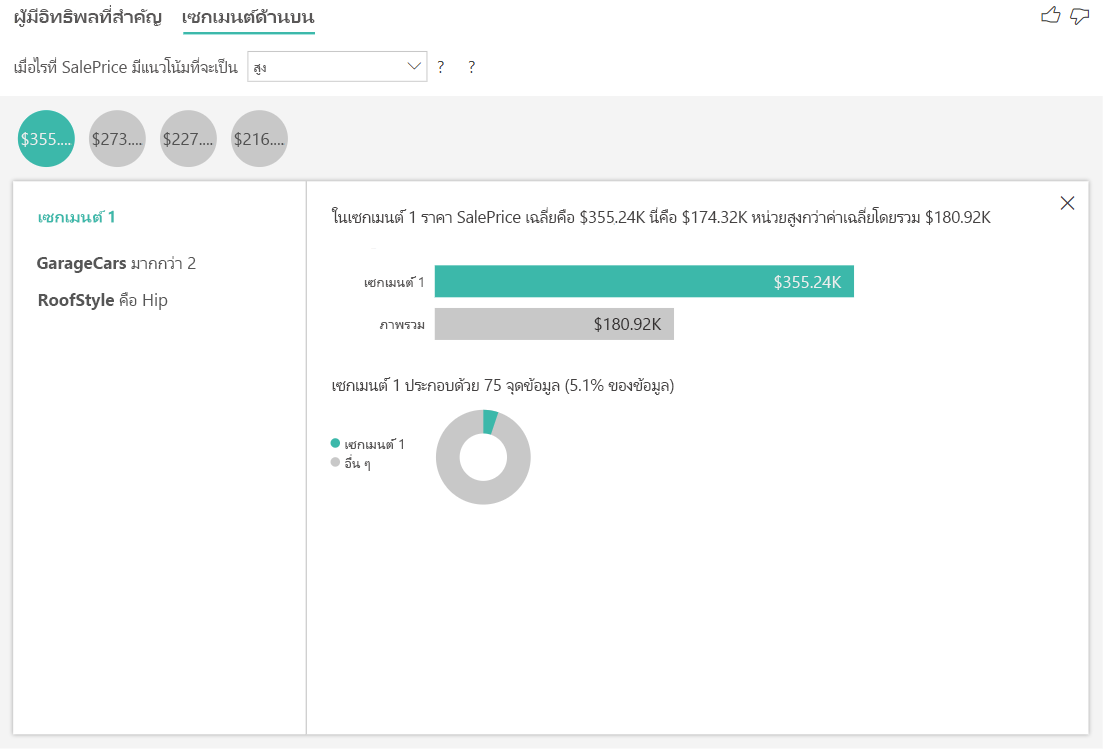
ตีความผลลัพธ์: เซกเมนต์ด้านบน
เซกเมนต์ด้านบนสําหรับเป้าหมายที่เป็นตัวเลขแสดงกลุ่มที่มีราคาบ้านโดยเฉลี่ยสูงกว่าราคาบ้านในชุดข้อมูลโดยรวม ตัวอย่างเช่น ด้านล่างเราจะเห็นว่า เซกเมนต์ 1 ถูกสร้างขึ้นจากบ้านซึ่ง GarageCars (จํานวนรถยนต์พอดีกับที่จอด) มีค่ามากกว่า 2 และ RoofStyle คือ Hip บ้านที่มีลักษณะดังกล่าวมีราคาเฉลี่ย $355K เมื่อเทียบกับค่าเฉลี่ยโดยรวมในข้อมูลซึ่งเป็น $180K
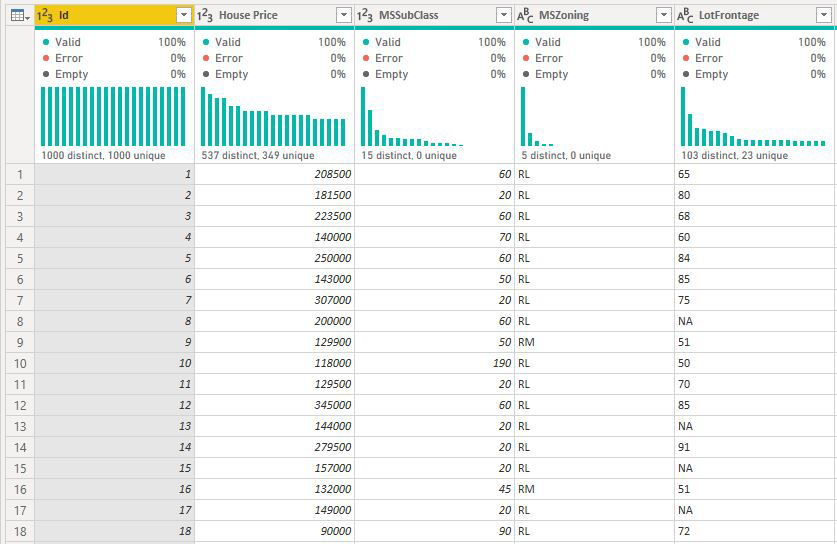
วิเคราะห์เมตริกที่เป็นคอลัมน์หน่วยวัดหรือคอลัมน์สรุป
ในกรณีของคอลัมน์หน่วยวัดหรือคอลัมน์สรุปการวิเคราะห์ที่เป็นค่าเริ่มต้นเป็นชนิดการวิเคราะห์แบบต่อเนื่องที่อธิบายไว้ข้างต้น ซึ่งไม่สามารถเปลี่ยนแปลงได้ ความแตกต่างที่สําคัญที่สุดระหว่างการวิเคราะห์คอลัมน์หน่วยวัด/สรุปและคอลัมน์ตัวเลขที่ไม่ได้สรุปคือระดับที่การวิเคราะห์รันอยู่
ในกรณีของคอลัมน์ที่ไม่ได้สรุป การวิเคราะห์จะเรียกใช้ในระดับตารางเสมอ ในตัวอย่างราคาบ้านด้านบน เราวิเคราะห์ เมตริกราคา บ้านเพื่อดูว่าสิ่งใดที่มีอิทธิพลต่อการเพิ่มขึ้น/ลดลงของราคาบ้าน การวิเคราะห์จะเรียกใช้ในระดับตารางโดยอัตโนมัติ ตารางของเรามี ID ที่ไม่ซ้ํากันสําหรับบ้านแต่ละหลังเพื่อให้การวิเคราะห์เรียกใช้ณ ระดับบ้าน
สําหรับคอลัมน์หน่วยวัดและคอลัมน์สรุป เรายังไม่ทราบโดยทันทีว่าจะวิเคราะห์คอลัมน์เหล่านี้ในระดับใด หาก ราคา บ้านได้รับการสรุปเป็น ค่าเฉลี่ย เราจะต้องพิจารณาว่าเราต้องการคํานวณราคาบ้านเฉลี่ยนี้ที่ระดับใด เป็นราคาบ้านเฉลี่ยในระดับใกล้เคียงหรือไม่ หรืออาจเป็นระดับภูมิภาคหรือไม่
คอลัมน์หน่วยวัดและคอลัมน์สรุปจะได้รับการวิเคราะห์โดยอัตโนมัติที่ระดับของ อธิบายโดย เขตข้อมูลที่ใช้ ลองจินตนาการว่าเรามีสามเขตข้อมูลในอธิบายโดยที่เราสนใจ: คุณภาพห้องครัว ชนิดอาคาร และเครื่องปรับอากาศ จะมีการคํานวณราคา บ้านเฉลี่ยสําหรับการรวมที่ไม่ซ้ํากันของเขตข้อมูลทั้งสามเหล่านั้น ซึ่งมักจะเป็นประโยชน์ในการสลับไปยังมุมมองตารางเพื่อดูว่าข้อมูลที่ทําการประเมินมีลักษณะอย่างไร
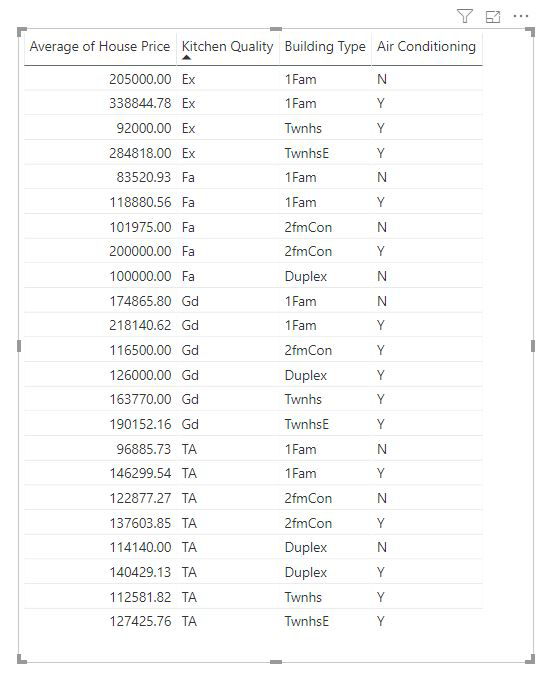
การวิเคราะห์นี้ได้รับการสรุปมากและดังนั้นจึงเป็นเรื่องยากสําหรับแบบจําลองการถดถอยเพื่อค้นหารูปแบบใด ๆ ในข้อมูลที่แบบจําลองสามารถเรียนรู้ได้ เราควรเรียกใช้การวิเคราะห์ที่ระดับที่มีรายละเอียดมากขึ้นเพื่อให้ได้ผลลัพธ์ที่ดีขึ้น หากเราต้องการวิเคราะห์ราคาบ้านในระดับบ้าน เราจําเป็นต้องเพิ่ม เขตข้อมูล ID ลงในการวิเคราะห์อย่างชัดเจน อย่างไรก็ตาม เราไม่ต้องการพิจารณาให้ ID ของบ้านเป็นผู้มีอิทธิพล ซึ่งไม่มีประโยชน์ที่จะเรียนรู้ว่าเมื่อ ID ของบ้านเพิ่มขึ้น ราคาของบ้านก็เพิ่มขึ้น ตัวเลือกพื้นที่ของเขตข้อมูลขยายโดย จะมีประโยชน์ที่นี่ คุณสามารถใช้ ขยายโดย เพื่อเพิ่มเขตข้อมูลที่คุณต้องการใช้สําหรับการตั้งค่าระดับของการวิเคราะห์โดยไม่ต้องค้นหาผู้มีอิทธิพลใหม่
ลองดูที่การแสดงผลข้อมูลด้วยภาพที่มีลักษณะเหมือนเมื่อเราเพิ่ม ID ไปยังขยายโดย เมื่อคุณได้กําหนดระดับที่คุณต้องการให้มีการประเมินหน่วยวัดของคุณ การแปลคําสั่งผู้มีอิทธิพลจะเหมือนกับ คอลัมน์ตัวเลขที่ไม่ได้สรุปอย่างชัดเจน
หากคุณต้องการเรียนรู้เพิ่มเติมเกี่ยวกับวิธีการที่คุณสามารถวิเคราะห์หน่วยวัดด้วยการแสดงภาพข้อมูลผู้มีอิทธิพลหลัก โปรดดูวิดีโอต่อไปนี้ หากต้องการเรียนรู้วิธีที่ Power BI ใช้ ML.NET เบื้องหลังเพื่อเหตุผลในข้อมูลเชิงลึกและพื้นผิวในลักษณะที่เป็นธรรมชาติ โปรดดู Power BI ระบุอิทธิพลที่สําคัญโดยใช้ ML.NET
หมายเหตุ
วิดีโอนี้อาจใช้ Power BI Desktop หรือบริการของ Power BI เวอร์ชันก่อนหน้า
ข้อควรพิจารณาและการแก้ไขปัญหา
ข้อจํากัดสําหรับวิชวลคืออะไร
วิชวลของผู้มีอิทธิพลหลักมีข้อจํากัดบางอย่าง:
- ไม่สนับสนุน Direct Query
- ไม่รองรับเชื่อมต่อสดไปยัง Azure Analysis Services และ SQL Server Analysis Services
- ไม่รองรับการเผยแพร่ไปยังเว็บ
- จําเป็นต้องมี .NET Framework 4.6 หรือสูงกว่า
- การฝัง SharePoint Online ไม่ได้รับการสนับสนุน
ฉันเห็นข้อผิดพลาดที่ไม่พบผู้มีอิทธิพลหรือเซกเมนต์ ทำไมจึงเป็นเช่นนั้น
ข้อผิดพลาดนี้เกิดขึ้นเมื่อคุณรวมเขตข้อมูลใน อธิบายโดย แต่ไม่พบผู้มีอิทธิพล
- คุณได้รวมเมตริกที่คุณกําลังวิเคราะห์ทั้งในการวิเคราะห์และอธิบายโดย เอาออกจาก อธิบายโดย
- เขตข้อมูลการอธิบายของคุณมีหมวดหมู่มากเกินไปโดยมีข้อสังเกตเพียงเล็กน้อย สถานการณ์นี้ทําให้ยากสําหรับการแสดงภาพข้อมูลเพื่อกําหนดปัจจัยที่เป็นผู้มีอิทธิพล เป็นเรื่องยากที่จะลงตัวตามข้อสังเกตเพียงสองสามข้อ ถ้าคุณกําลังวิเคราะห์เขตข้อมูลตัวเลข คุณอาจต้องการสลับจาก การวิเคราะห์ตามประเภท เป็น การวิเคราะห์แบบต่อเนื่อง ใน บานหน้าต่างการจัดรูปแบบ ภายใต้การ์ด การวิเคราะห์
- ปัจจัยการอธิบายของคุณมีข้อสังเกตเพียงพอที่จะลงรายละเอียด แต่การสร้างภาพข้อมูลไม่พบความสัมพันธ์ที่มีความหมายใด ๆ ต่อรายงาน
ฉันเห็นข้อผิดพลาดซึ่งเมตริกที่ฉันกําลังวิเคราะห์มีข้อมูลไม่เพียงพอที่จะทําการวิเคราะห์ ทำไมจึงเป็นเช่นนั้น

การแสดงภาพข้อมูลจะทํางานโดยดูที่รูปแบบในข้อมูลสําหรับกลุ่มหนึ่งเปรียบเทียบกับกลุ่มอื่น ตัวอย่างเช่น จะค้นหาลูกค้าที่ให้คะแนนต่ําเมื่อเปรียบเทียบกับลูกค้าที่ให้คะแนนสูง หากข้อมูลในแบบจําลองของคุณมีข้อสังเกตสองสามข้อ จึงเป็นเรื่องยากที่จะค้นหา หากการแสดงภาพข้อมูลไม่มีข้อมูลเพียงพอที่จะค้นหาผู้มีอิทธิพลที่มีความหมาย แสดงว่าจําเป็นต้องใช้ข้อมูลเพิ่มเติมเพื่อทําการวิเคราะห์
เราขอแนะนําให้คุณมีข้อสังเกตอย่างน้อย 100 ข้อสําหรับสถานะที่เลือก ในกรณีนี้ สถานะคือลูกค้าที่เลิกใช้บริการ คุณยังต้องมีข้อสังเกตอย่างน้อย 10 ข้อสําหรับสถานะที่คุณใช้สําหรับการเปรียบเทียบ ในกรณีนี้ สถานะการเปรียบเทียบคือลูกค้าที่ไม่เลิกใช้บริการ
ถ้าคุณกําลังวิเคราะห์เขตข้อมูลตัวเลข คุณอาจต้องการสลับจาก การวิเคราะห์ตามประเภท เป็น การวิเคราะห์แบบต่อเนื่อง ใน บานหน้าต่างการจัดรูปแบบ ภายใต้การ์ด การวิเคราะห์
ฉันเห็นข้อผิดพลาดที่เมื่อ 'วิเคราะห์' ไม่ได้รับการสรุป การวิเคราะห์จะเรียกใช้ที่ระดับแถวของตารางหลักเสมอ ไม่อนุญาตให้เปลี่ยนระดับนี้ผ่านเขตข้อมูล 'ขยายโดย' ทำไมจึงเป็นเช่นนั้น
เมื่อทําการวิเคราะห์คอลัมน์ตัวเลขหรือคอลัมน์จัดกลุ่ม การวิเคราะห์จะเรียกใช้ในระดับตารางเสมอ ตัวอย่างเช่น ถ้าคุณกําลังวิเคราะห์ราคาบ้านและตารางของคุณประกอบด้วยคอลัมน์ ID การวิเคราะห์จะเรียกใช้โดยอัตโนมัติที่ระดับ ID บ้าน
เมื่อคุณกําลังวิเคราะห์คอลัมน์หน่วยวัดหรือคอลัมน์สรุป คุณต้องระบุว่าคุณต้องการให้การวิเคราะห์เรียกใช้ที่ระดับใด คุณสามารถใช้ ขยายโดย เพื่อเปลี่ยนระดับของการวิเคราะห์สําหรับคอลัมน์หน่วยวัดและคอลัมน์สรุปโดยไม่ต้องเพิ่มผู้มีอิทธิพลใหม่ หาก ราคา บ้านได้รับการกําหนดเป็นหน่วยวัด คุณสามารถเพิ่มคอลัมน์ ID บ้านไปยัง ขยายโดย เพื่อเปลี่ยนระดับการวิเคราะห์ได้
ฉันเห็นข้อผิดพลาดว่าเขตข้อมูลใน อธิบายโดย ไม่เกี่ยวข้องกับตารางที่มีเมตริกที่ฉันกําลังวิเคราะห์โดยเฉพาะ ทำไมจึงเป็นเช่นนั้น
การวิเคราะห์จะทํางานในระดับตารางของเขตข้อมูลที่กําลังวิเคราะห์ ตัวอย่างเช่น หากคุณวิเคราะห์ความคิดเห็นของลูกค้าสําหรับบริการของคุณ คุณอาจมีตารางที่บอกคุณว่าลูกค้าให้คะแนนสูงหรือต่ํา ในกรณีนี้ การวิเคราะห์ของคุณจะทํางานที่ระดับตารางลูกค้า
หากคุณมีตารางที่เกี่ยวข้องซึ่งกําหนดไว้ในระดับที่ละเอียดมากกว่าตารางที่มีเมตริกของคุณ คุณจะเห็นข้อผิดพลาดนี้ ตัวอย่างมีดังนี้:
- คุณวิเคราะห์สิ่งที่ผลักดันให้ลูกค้าให้คะแนนการบริการของคุณต่ํา
- คุณต้องการดูว่าอุปกรณ์ที่ลูกค้าใช้บริการมีผลต่อการรีวิวที่พวกเขาให้หรือไม่
- ลูกค้าสามารถใช้บริการได้หลายวิธีที่แตกต่างกัน
- ในตัวอย่างต่อไปนี้ ลูกค้า 10000000 รายใช้ทั้งเบราว์เซอร์และแท็บเล็ตเพื่อโต้ตอบกับบริการ
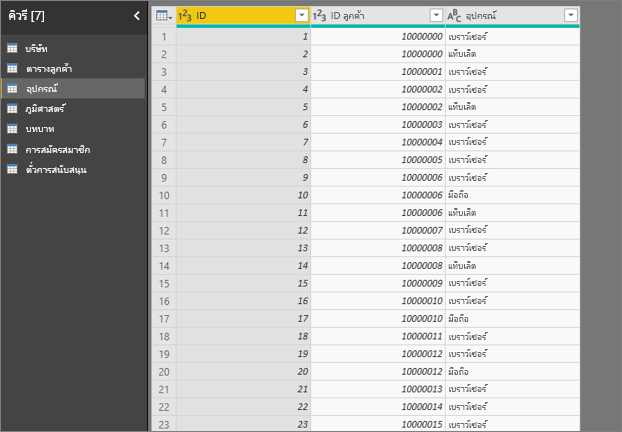
หากคุณพยายามใช้คอลัมน์อุปกรณ์เป็นปัจจัยการอธิบาย คุณจะเห็นข้อผิดพลาดต่อไปนี้:

ข้อผิดพลาดนี้ปรากฏขึ้นเนื่องจากอุปกรณ์ไม่ได้ถูกกําหนดไว้ในระดับลูกค้า ลูกค้าหนึ่งรายสามารถใช้บริการได้บนหลายอุปกรณ์ สําหรับการแสดงภาพข้อมูลเพื่อหารูปแบบ อุปกรณ์ต้องเป็นแอตทริบิวต์ของลูกค้า มีวิธีแก้ไขปัญหาหลากหลายทั้งนี้ขึ้นอยู่กับความเข้าใจเกี่ยวกับธุรกิจของคุณ:
- คุณสามารถเปลี่ยนการสรุปอุปกรณ์เพื่อนับ ตัวอย่างเช่น ใช้การนับถ้าจํานวนอุปกรณ์อาจส่งผลกระทบต่อคะแนนที่ลูกค้าให้
- คุณสามารถหมุนคอลัมน์อุปกรณ์เพื่อดูว่าการใช้บริการบนอุปกรณ์เฉพาะนั้นมีผลต่อการให้คะแนนของลูกค้าหรือไม่
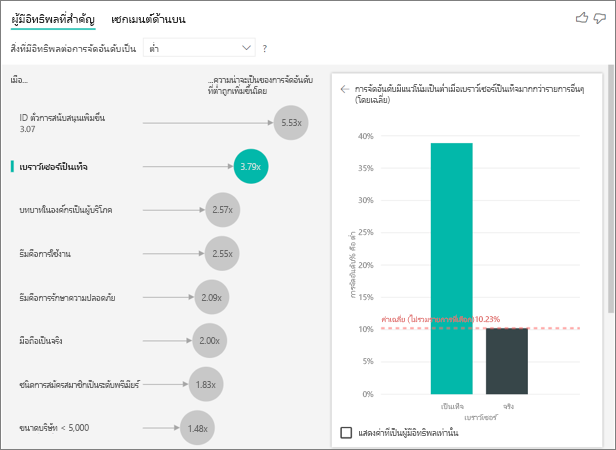
ในตัวอย่างนี้ ข้อมูลจะถูกหมุนเพื่อสร้างคอลัมน์ใหม่สําหรับเบราว์เซอร์ อุปกรณ์เคลื่อนที่ และแท็บเล็ต (ตรวจสอบให้แน่ใจว่าคุณได้ลบและสร้างความสัมพันธ์ของคุณในมุมมองการสร้างแบบจําลองใหม่หลังจาก pivot ข้อมูลของคุณ) ตอนนี้คุณสามารถใช้อุปกรณ์เฉพาะเหล่านี้ใน อธิบายโดยได้ อุปกรณ์ทั้งหมดกลายเป็นผู้มีอิทธิพลและเบราว์เซอร์มีผลกระทบต่อคะแนนของลูกค้ามากที่สุด
แม่นยํายิ่งขึ้น ลูกค้าที่ไม่ได้ใช้เบราว์เซอร์เพื่อใช้บริการมีแนวโน้มที่จะให้คะแนนต่ํากว่าลูกค้าที่ใช้ 3.79 เท่า เมื่อลดรายการสําหรับมือถือลง การผกผันจะเป็นจริง ลูกค้าที่ใช้แอปมือถือมีแนวโน้มที่จะให้คะแนนต่ํากว่าลูกค้าที่ไม่ได้ใช้
ฉันเห็นคําเตือนว่าการวัดไม่ได้รวมอยู่ในการวิเคราะห์ของฉัน ทำไมจึงเป็นเช่นนั้น
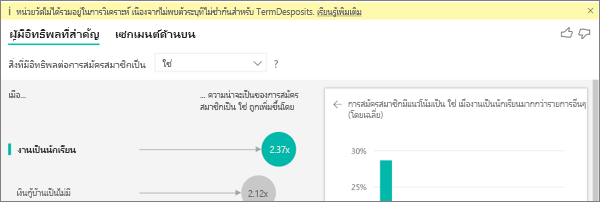
การวิเคราะห์จะทํางานในระดับตารางของเขตข้อมูลที่กําลังวิเคราะห์ หากคุณวิเคราะห์การเลิกใช้บริการของลูกค้า คุณอาจมีตารางที่บอกคุณว่าลูกค้าเลิกใช้บริการหรือไม่ ในกรณีนี้ การวิเคราะห์ของคุณจะทํางานที่ระดับตารางลูกค้า
การวัดและผลรวมจะถูกวิเคราะห์ตามค่าเริ่มต้นที่ระดับตาราง หากมีหน่วยวัดสําหรับค่าใช้จ่ายรายเดือนเฉลี่ย จะมีการวิเคราะห์ในระดับตารางลูกค้า
หากตารางลูกค้าไม่มีตัวระบุที่ไม่ซ้ํากัน คุณจะไม่สามารถประเมินหน่วยวัดได้และจะถูกละเว้นโดยการวิเคราะห์ เพื่อหลีกเลี่ยงไม่ให้เกิดสถานการณ์เช่นนี้ ตรวจสอบให้แน่ใจว่าตารางที่มีเมตริกของคุณมีตัวระบุที่ไม่ซ้ํากัน ในกรณีนี้ ตารางลูกค้าและตัวระบุที่ไม่ซ้ํากันคือ ID ลูกค้า นอกจากนี้ยังง่ายต่อการเพิ่มคอลัมน์ดัชนีโดยใช้ Power Query
ฉันเห็นคําเตือนว่าเมตริกที่ฉันกําลังวิเคราะห์มีค่ามากกว่า 10 ค่าที่ไม่ซ้ํากันและจํานวนนี้อาจส่งผลกระทบต่อคุณภาพการวิเคราะห์ของฉัน ทำไมจึงเป็นเช่นนั้น
การแสดงภาพข้อมูล AI สามารถวิเคราะห์เขตข้อมูลตามประเภทและเขตข้อมูลตัวเลขได้ ในกรณีของเขตข้อมูลตามประเภท ตัวอย่างอาจเป็น Churn ใช่หรือไม่ และความพึงพอใจของลูกค้าสูง ปานกลาง หรือต่ํา การเพิ่มจํานวนหมวดหมู่เพื่อวิเคราะห์หมายความว่ามีข้อสังเกตน้อยลงสําหรับแต่ละหมวดหมู่ สถานการณ์นี้ทําให้ยากขึ้นสําหรับการแสดงภาพข้อมูลเพื่อค้นหารูปแบบในข้อมูล
เมื่อทําการวิเคราะห์เขตข้อมูลตัวเลข คุณมีตัวเลือกระหว่างการจัดการเขตข้อมูลตัวเลข เช่น ข้อความ ในกรณีที่คุณจะเรียกใช้การวิเคราะห์เดียวกันกับที่คุณดําเนินการสําหรับข้อมูลตามประเภท (การวิเคราะห์ตามประเภท) ถ้าคุณมีค่าที่แตกต่างกันจํานวนมาก เราขอแนะนําให้คุณสลับการวิเคราะห์เป็น การวิเคราะห์ แบบต่อเนื่อง ซึ่งหมายความว่าเราสามารถอนุมานรูปแบบจากเมื่อตัวเลขเพิ่มขึ้นหรือลดลงแทนการจัดการตัวเลขเหล่านั้นเป็นค่าที่แตกต่างกัน คุณสามารถสลับจาก การวิเคราะห์ตามประเภท เป็น การวิเคราะห์แบบต่อเนื่อง ใน บานหน้าต่างการจัดรูปแบบ ภายใต้การ์ด การวิเคราะห์
หากต้องการค้นหาผู้มีอิทธิพลที่แข็งแกร่ง เราขอแนะนําให้จัดกลุ่มค่าที่คล้ายกันไว้ในหน่วยเดียว ตัวอย่างเช่น หากคุณมีเมตริกสําหรับราคา คุณจะได้ผลลัพธ์ที่ดีขึ้นโดยการจัดกลุ่มราคาที่คล้ายกัน เช่น กลุ่มราคาสูง กลุ่มราคาปานกลาง และกลุ่มราคาต่ําเทียบกับการเลือกใช้จุดราคาแต่ละจุด
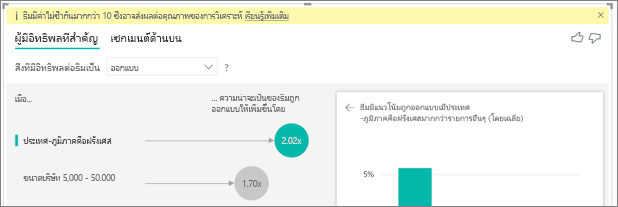
มีปัจจัยในข้อมูลของฉันที่ดูเหมือนว่าปัจจัยดังกล่าวควรเป็นผู้มีอิทธิพลหลัก แต่ว่าไม่ใช่ มันเกิดขึ้นได้อย่างไร
ในตัวอย่างต่อไปนี้ ลูกค้าที่เป็นผู้บริโภคให้คะแนนต่ํา โดยให้คะแนน 14.93% ซึ่งต่ํา บทบาทของผู้ดูแลระบบยังมีสัดส่วนสูงในการให้คะแนนต่ํา 13.42% แต่ไม่ถือว่าเป็นผู้มีอิทธิพล
เหตุผลในการพิจารณานี้คือการแสดงภาพข้อมูลพิจารณาจํานวนของจุดข้อมูลด้วยเมื่อค้นหาผู้มีอิทธิพล ตัวอย่างต่อไปนี้มีผู้บริโภคมากกว่า 29,000 คนและมีผู้ดูแลระบบน้อยกว่า 10 เท่า ประมาณ 2,900 คน มีเพียง 390 คนเท่านั้นที่ให้คะแนนต่ํา วิชวลไม่มีข้อมูลเพียงพอที่จะพิจารณาว่าพบรูปแบบที่มีการให้คะแนนโดยผู้ดูแลระบบหรือเป็นเพียงการค้นหาโอกาส
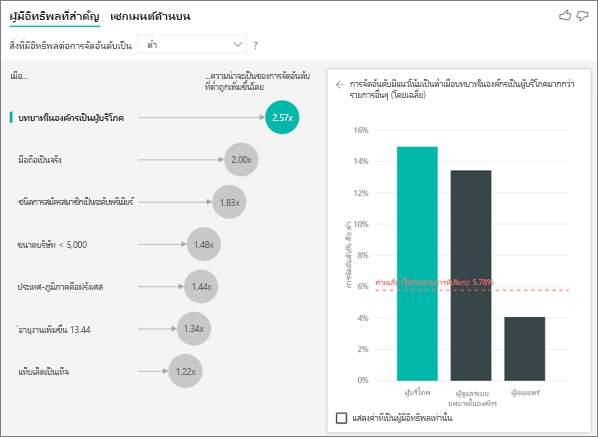
ข้อจํากัดของจุดข้อมูลสําหรับผู้มีอิทธิพลหลักคืออะไร เราเรียกใช้การวิเคราะห์เกี่ยวกับตัวอย่างของจุดข้อมูล 10,000 รายการ ฟองอากาศด้านหนึ่งแสดงถึงผู้มีอิทธิพลทั้งหมดที่พบ แผนภูมิคอลัมน์และ scatterplots ในอีกด้านหนึ่งจะปฏิบัติตามกลยุทธ์การสุ่มตัวอย่างสําหรับวิชวลหลักเหล่านั้น
คุณจะคํานวณผู้มีอิทธิพลหลักสําหรับการวิเคราะห์ตามประเภทได้อย่างไร
การสร้างภาพข้อมูลด้วย AI จะใช้ ML.NET เพื่อดําเนินการถดถอยโลจิสติกส์อยู่เบื้องหลังเพื่อคํานวณผู้มีอิทธิพลหลัก การถดถอยโลจิสติกเป็นแบบจําลองทางสถิติที่เปรียบเทียบกลุ่มที่แตกต่างกัน
หากคุณต้องการดูว่าอะไรเป็นตัวผลักดันให้คะแนนจัดอันดับต่ํา การถดถอยโลจิสติกส์จะดูว่าลูกค้าที่ให้คะแนนต่ําแตกต่างจากลูกค้าที่ให้คะแนนสูงอย่างไร หากคุณมีหลายหมวดหมู่ เช่น คะแนนสูง คะแนนปานกลาง และคะแนนต่ํา คุณจะต้องพิจารณาว่าลูกค้าที่ให้คะแนนต่ําแตกต่างจากลูกค้าที่ไม่ได้ให้คะแนนต่ําอย่างไร ในกรณีนี้ลูกค้าที่ให้คะแนนต่ําแตกต่างจากลูกค้าที่ให้คะแนนสูงหรือคะแนนกลางอย่างไร
การถดถอยโลจิสติกส์จะค้นหารูปแบบในข้อมูลและค้นหาว่าลูกค้าที่ให้คะแนนต่ําอาจแตกต่างจากลูกค้าที่ให้คะแนนสูงอย่างไร ตัวอย่างเช่น อาจพบว่าลูกค้าที่มีตั๋วการสนับสนุนมากกว่าให้คะแนนการจัดอันดับต่ํากว่าลูกค้าที่มีตั๋วสนับสนุนน้อยหรือไม่มีเลย
การถดถอยโลจิสติกส์ยังพิจารณาจํานวนจุดข้อมูลที่มีอยู่ด้วย ตัวอย่างเช่น หากลูกค้าที่มีบทบาทผู้ดูแลระบบให้คะแนนเชิงลบมากกว่าตามสัดส่วน แต่มีผู้ดูแลระบบเพียงไม่กี่คน ปัจจัยนี้ไม่ถือว่ามีอิทธิพล การกําหนดนี้เกิดขึ้นเนื่องจากมีจุดข้อมูลไม่เพียงพอที่จะอนุมานรูปแบบ การทดสอบทางสถิติหรือที่เรียกว่าการทดสอบ Wald นั้นใช้เพื่อพิจารณาว่าปัจจัยใดที่ถือว่าเป็นผู้มีอิทธิพล วิชวลใช้ค่า p เป็น 0.05 เพื่อกําหนดค่าเกณฑ์
คุณจะคํานวณผู้มีอิทธิพลหลักสําหรับการวิเคราะห์ตัวเลขได้อย่างไร
ในเบื้องหลัง การแสดงภาพข้อมูล AI จะใช้ ML.NET เพื่อดําเนินการถดถอยเชิงเส้นเพื่อคํานวณผู้มีอิทธิพลหลัก การถดถอยเชิงเส้นเป็นแบบจําลองทางสถิติที่พิจารณาว่าผลลัพธ์ของเขตข้อมูลที่คุณกําลังวิเคราะห์มีการเปลี่ยนแปลงตามปัจจัยการอธิบายของคุณอย่างไร
ตัวอย่างเช่น หากเรากําลังวิเคราะห์ราคาบ้าน การถดถอยเชิงเส้นจะพิจารณาถึงผลกระทบที่การมีห้องครัวที่ดีเยี่ยมจะมีต่อราคาบ้าน บ้านที่มีห้องครัวที่ดีเยี่ยมมักมีราคาบ้านที่ต่ํากว่าหรือสูงกว่าเมื่อเทียบกับบ้านที่ไม่มีห้องครัวที่ดีเยี่ยมหรือไม่
การถดถอยเชิงเส้นยังพิจารณาจํานวนของจุดข้อมูลด้วย ตัวอย่างเช่น หากบ้านที่มีสนามเทนนิสมีราคาสูงกว่า แต่เรามีบ้านไม่กี่หลังที่มีสนามเทนนิส ปัจจัยนี้จะไม่ถือว่ามีอิทธิพล การกําหนดนี้เกิดขึ้นเนื่องจากมีจุดข้อมูลไม่เพียงพอที่จะอนุมานรูปแบบ การทดสอบทางสถิติหรือที่เรียกว่าการทดสอบ Wald นั้นใช้เพื่อพิจารณาว่าปัจจัยใดที่ถือว่าเป็นผู้มีอิทธิพล วิชวลใช้ค่า p เป็น 0.05 เพื่อกําหนดค่าเกณฑ์
คุณคํานวณเซกเมนต์ได้อย่างไร
ในเบื้องหลัง การแสดงภาพข้อมูล AI ใช้ ML.NET เพื่อเรียกใช้แผนภูมิการตัดสินใจเพื่อค้นหากลุ่มย่อยที่น่าสนใจ วัตถุประสงค์ของแผนภูมิการตัดสินใจคือการจบด้วยกลุ่มย่อยของจุดข้อมูลที่ค่อนข้างสูงในเมตริกที่คุณสนใจ ซึ่งอาจเป็นลูกค้าที่มีการจัดอันดับต่ําหรือบ้านที่มีราคาสูง
ต้นไม้แห่งการตัดสินใจใช้ปัจจัยอธิบายแต่ละตัวและพยายามหาเหตุผลว่าปัจจัยใดที่มีการแยกที่ดีที่สุด ตัวอย่างเช่น หากคุณกรองข้อมูลเพื่อรวมเฉพาะลูกค้าองค์กรขนาดใหญ่จะแยกลูกค้าที่ให้คะแนนสูงกับคะแนนต่ําหรือไม่ หรืออาจจะดีกว่าถ้ากรองข้อมูลเพื่อรวมเฉพาะลูกค้าที่แสดงความคิดเห็นเกี่ยวกับความปลอดภัยเท่านั้นใช่หรือไม่
หลังจากทําการแยกแผนภูมิการตัดสินแล้ว ระบบจะใช้กลุ่มย่อยของข้อมูลและกําหนดการแยกที่ดีที่สุดถัดไปสําหรับข้อมูลนั้น ในกรณีนี้ กลุ่มย่อยคือลูกค้าที่แสดงข้อคิดเห็นเกี่ยวกับความปลอดภัย หลังจากการแยกแต่ละครั้ง แผนภูมิการตัดสินใจยังพิจารณาว่ามีจุดข้อมูลเพียงพอหรือไม่สําหรับกลุ่มนี้ที่จะเป็นตัวแทนซึ่งเพียงพอที่จะอนุมานรูปแบบหรืออาจเป็นความผิดปกติของข้อมูลและไม่ใช่เซกเมนต์จริงหรือไม่ ใช้การทดสอบทางสถิติอื่นเพื่อตรวจสอบนัยสําคัญทางสถิติของเงื่อนไขการแยกด้วยค่า p เท่ากับ 0.05
หลังจากแผนภูมิการตัดสินใจทํางานเสร็จสิ้น ระบบจะใช้การแยกทั้งหมด เช่น ความคิดเห็นด้านความปลอดภัยและองค์กรขนาดใหญ่ และสร้างตัวกรอง Power BI การรวมกันของตัวกรองนี้จะรวมเป็นกลุ่มในวิชวล
เหตุใดปัจจัยบางอย่างจึงกลายเป็นผู้มีอิทธิพลหรือหยุดการเป็นผู้มีอิทธิพลเมื่อฉันย้ายเขตข้อมูลไปที่ อธิบายโดย
การแสดงภาพข้อมูลประเมินปัจจัยการอธิบายทั้งหมดเข้าด้วยกัน ปัจจัยอาจเป็นผู้มีอิทธิพลด้วยตัวเอง แต่เมื่อพิจารณาด้วยปัจจัยอื่น ๆ อาจไม่เป็น สมมติว่าคุณต้องการวิเคราะห์สิ่งที่ทําให้ราคาบ้านสูงด้วยห้องนอนและขนาดบ้านเป็นปัจจัยการอธิบาย:
- โดยตัวเองแล้ว การมีห้องนอนมากขึ้นอาจเป็นตัวขับเคลื่อนให้ราคาบ้านสูงขึ้น
- การรวมขนาดบ้านในการวิเคราะห์หมายความว่าตอนนี้คุณจะดูว่าเกิดอะไรขึ้นกับห้องนอนในขณะที่ขนาดบ้านยังคงคงที่
- หากบ้านมีขนาดคงที่ 1,500 ตารางฟุต ไม่น่าเป็นไปได้ที่การเพิ่มจํานวนห้องนอนมากขึ้นอย่างต่อเนื่องจะเพิ่มราคาบ้านอย่างมาก
- ห้องนอนอาจไม่สําคัญเท่าปัจจัยก่อนที่จะพิจารณาขนาดบ้าน
การแชร์รายงานของคุณกับผู้ร่วมงาน Power BI กําหนดให้คุณต้องมีสิทธิ์การใช้งาน Power BI Pro แต่ละรายการ หรือรายงานจะถูกบันทึกในความจุแบบพรีเมียม ดูการแชร์รายงาน
เนื้อหาที่เกี่ยวข้อง
คำติชม
เร็วๆ นี้: ตลอดปี 2024 เราจะขจัดปัญหา GitHub เพื่อเป็นกลไกคำติชมสำหรับเนื้อหา และแทนที่ด้วยระบบคำติชมใหม่ สำหรับข้อมูลเพิ่มเติม ให้ดู: https://aka.ms/ContentUserFeedback
ส่งและดูข้อคิดเห็นสำหรับ