Bu içerik şunlar için geçerlidir:v4.0 (GA) | Önceki sürümler: v3.1 (GA)v3.0 (GA)
Not
Etiketler, sokak işaretleri ve posterler gibi dış görüntülerden metin ayıklamak için, performans açısından geliştirilmiş zaman uyumlu API'ye sahip genel (belge değil) görüntüler için iyileştirilmiş Azure AI Görüntü Analizi v4.0 Okuma özelliğini kullanın. Bu özellik, gerçek zamanlı kullanıcı deneyimi senaryolarına OCR eklemeyi kolaylaştırır.
Belge Zekası Okuma Optik Karakter Tanıma (OCR) modeli, Azure AI Görüntü İşleme Okuma'dan daha yüksek çözünürlükte çalışır ve PDF belgelerinden ve taranmış görüntülerden yazdırma ve el yazısı metinleri ayıklar. Ayrıca Microsoft Word, Excel, PowerPoint ve HTML belgelerinden metin ayıklama desteği de içerir. Paragrafları, metin satırlarını, sözcükleri, konumları ve dilleri algılar. Okuma modeli, özel modellere ek olarak Düzen, Genel Belge, Fatura, Makbuz, Kimlik (Kimlik) belgesi, Sağlık sigortası kartı, W2 gibi önceden oluşturulmuş diğer Belge Zekası modelleri için temel alınan OCR altyapısıdır.
Optik Karakter Tanıma nedir?
Belgeler için Optik Karakter Tanıma (OCR), birden çok dosya biçiminde ve genel dilde büyük metin ağırlıklı belgeler için iyileştirilmiştir. Daha küçük ve yoğun metinlerin daha iyi işlenmesi için belge görüntülerinin daha yüksek çözünürlüklü taranmış olması gibi özellikler içerir; paragraf algılama; ve doldurulabilir form yönetimi. OCR özellikleri, tek karakterli kutular gibi gelişmiş senaryoları ve faturalarda, makbuzlarda ve diğer önceden oluşturulmuş senaryolarda yaygın olarak bulunan anahtar alanlarının doğru ayıklarını içerir.
Geliştirme seçenekleri (v4)
Belge Yönetim Bilgileri v4.0: 2024-11-30 (GA) aşağıdaki araçları, uygulamaları ve kitaplıkları destekler:
Microsoft Office: Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTML
Okundu
✔
✔
✔
Düzen
✔
✔
✔
Genel Belge
✔
✔
Önceden oluşturulmuş
✔
✔
Özel ayıklama
✔
✔
Özel sınıflandırma
✔
✔
✔
En iyi sonuçları elde için belge başına tek bir net fotoğraf veya yüksek kaliteli tarama sağlayın.
PDF ve TIFF için en fazla 2.000 sayfa işlenebilir (ücretsiz katman aboneliğiyle yalnızca ilk iki sayfa işlenir).
Belgeleri analiz etmek için dosya boyutu ücretli (S0) katman için 500 MB ve 4 ücretsiz (F0) katman için MB'tır.
Görüntü boyutları 50 piksel x 50 piksel ile 10.000 piksel x 10.000 piksel arasında olmalıdır.
PDF’leriniz parola korumalıysa göndermeden önce kilidi kaldırmanız gerekir.
Ayıklanacak metnin en düşük yüksekliği 1024 x 768 piksel görüntü için 12 pikseldir. Bu boyut, yaklaşık 150 nokta/inç (DPI) nokta metnine karşılık gelir 8 .
Özel model eğitimi için eğitim verileri için en fazla sayfa sayısı özel şablon modeli için 500, özel sinir modeli için 50.000'dir.
Özel ayıklama modeli eğitimi için eğitim verilerinin toplam boyutu şablon modeli için 50 MB ve 1 sinir modeli için GB'tır.
Özel sınıflandırma modeli eğitimi için eğitim verilerinin toplam boyutu en fazla 10.000 sayfa ile GB'tır 1 . 2024-11-30 (GA) için eğitim verilerinin toplam boyutu gb ve en fazla 10.000 sayfadır 2 .
Okuma modelini kullanmaya başlama (v4)
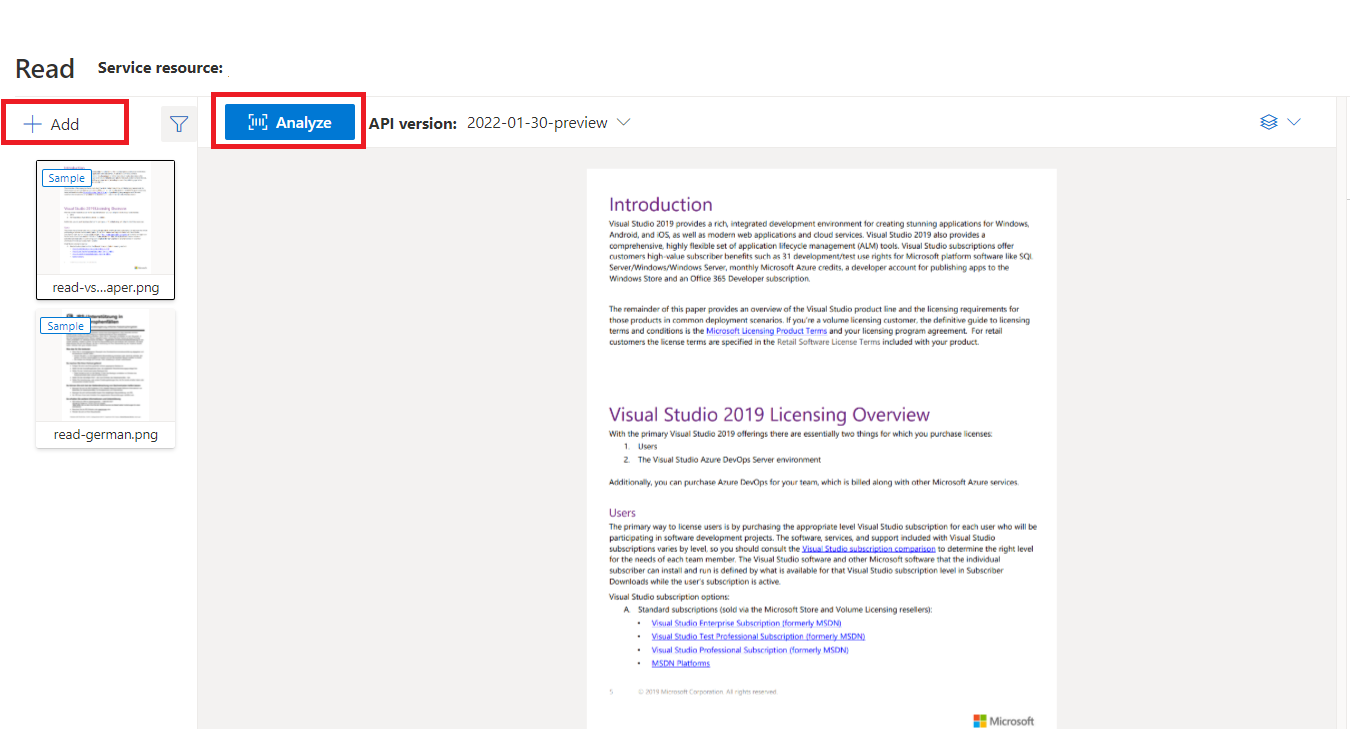
Document Intelligence Studio'yu kullanarak formlardan ve belgelerden metin ayıklamayı deneyin. Aşağıdaki varlıklara ihtiyacınız vardır:
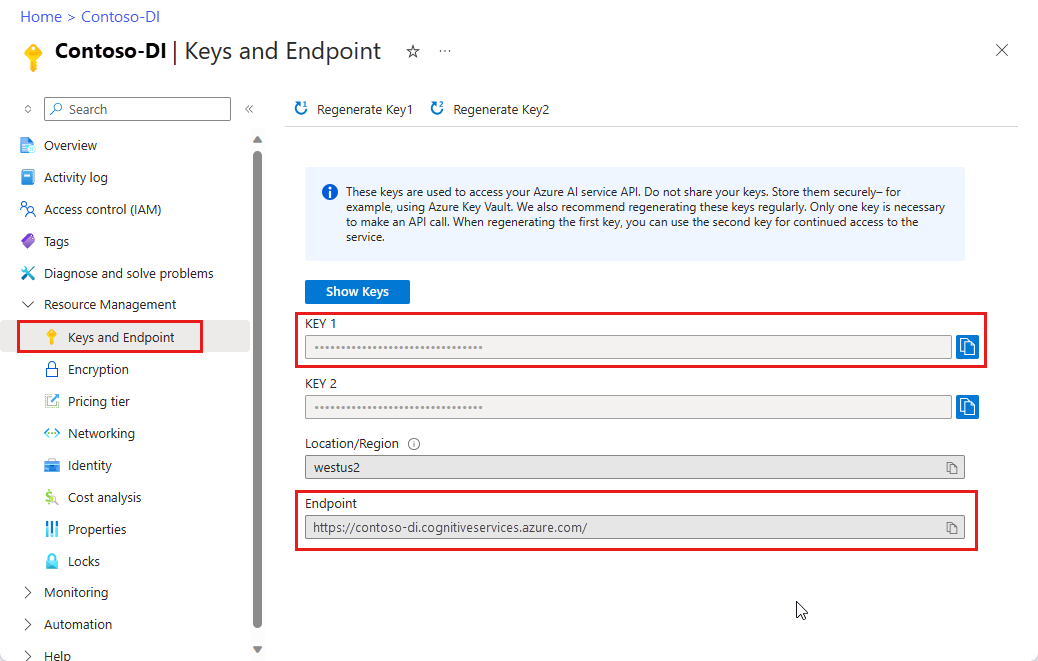
Azure portalında bir Belge Zekası örneği. Hizmeti denemek için ücretsiz fiyatlandırma katmanını (F0) kullanabilirsiniz. Kaynağınız dağıtıldıktan sonra anahtarınızı ve uç noktanızı almak için Kaynağa git'i seçin.
Not
Document Intelligence Studio şu anda Microsoft Word, Excel, PowerPoint ve HTML dosya biçimlerini desteklememektedir.
Desteklenen dillerin tam listesi için Dil Desteği— belge çözümleme modelleri sayfamıza bakın.
Veri ayıklama (v4)
Not
Microsoft Word ve HTML dosyası v4.0'da desteklenir. Şu anda aşağıdaki özellikler desteklenmemektedir:
Her sayfa nesnesiyle açı, genişlik/yükseklik ve birim döndürülmedi.
Algılanan her nesne için sınırlayıcı çokgen veya sınırlayıcı bölge yok.
Parametre olarak sayfa aralığı (pages) döndürülmedi.
Nesne yok lines .
Aranabilir PDF'ler
Aranabilir PDF özelliği, taranmış resim PDF dosyaları gibi bir analog PDF'yi eklenmiş metin içeren bir PDF'ye dönüştürmenizi sağlar. Ekli metin, algılanan metin varlıklarını görüntü dosyalarının üzerine katmanlayarak PDF'nin ayıklanan içeriğinde derin metin araması sağlar.
Önemli
Şu anda yalnızca Read OCR modeli prebuilt-read aranabilir PDF özelliğini destekler. Bu özelliği kullanırken olarak prebuilt-readbelirtinmodelId. Diğer model türleri bu önizleme sürümü için bir hata döndürür.
Aranabilir PDF, aranabilir PDF çıktısı 2024-11-30 oluşturmak için ek maliyet olmadan GA prebuilt-read modeline dahil edilir.
Aranabilir PDF'leri kullanma
Aranabilir PDF'yi kullanmak için işlemi kullanarak bir POST istekte bulunup Analyze çıkış biçimini olarak pdfbelirtin:
Bash
POST {endpoint}/documentintelligence/documentModels/prebuilt-read:analyze?_overload=analyzeDocument&api-version=2024-11-30&output=pdf
{...}
202
İşlemin tamamlanmasını yoklama Analyze . İşlem tamamlandıktan sonra, işlem sonuçlarının PDF biçimini almak için bir GET istekte bulunun Analyze .
Başarıyla tamamlandıktan sonra PDF olarak alınabilir ve indirilebilir application/pdf. Bu işlem, Base64 ile kodlanmış JSON yerine PDF'nin eklenmiş metin biçiminin doğrudan indirilmesini sağlar.
Bash
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET {endpoint}/documentintelligence/documentModels/prebuilt-read/analyzeResults/{resultId}/pdf?api-version=2024-11-30
URI Parameters
Name In Required Type Description
endpoint path True
string
uri
The Document Intelligence service endpoint.
modelId path True
string
Unique document model name.
Regex pattern: ^[a-zA-Z0-9][a-zA-Z0-9._~-]{1,63}$
resultId path True
string
uuid
Analyze operation result ID.
api-version query True
string
The API version to use for this operation.
Responses
Name Type Description
200 OK
file
The request has succeeded.
Media Types: "application/pdf", "application/json"
Other Status Codes
DocumentIntelligenceErrorResponse
An unexpected error response.
Media Types: "application/pdf", "application/json"
Security
Ocp-Apim-Subscription-Key
Type: apiKey
In: header
OAuth2Auth
Type: oauth2
Flow: accessCode
Authorization URL: https://login.microsoftonline.com/common/oauth2/authorize
Token URL: https://login.microsoftonline.com/common/oauth2/token
Scopes
Name Description
https://cognitiveservices.azure.com/.default
Examples
Get Analyze Document Result PDF
Sample request
HTTP
HTTP
Copy
GET https://myendpoint.cognitiveservices.azure.com/documentintelligence/documentModels/prebuilt-invoice/analyzeResults/3b31320d-8bab-4f88-b19c-2322a7f11034/pdf?api-version=2024-11-30
Sample response
Status code:
200
JSON
Copy
"{pdfBinary}"
Definitions
Name Description
DocumentIntelligenceError
The error object.
DocumentIntelligenceErrorResponse
Error response object.
DocumentIntelligenceInnerError
An object containing more specific information about the error.
DocumentIntelligenceError
The error object.
Name Type Description
code
string
One of a server-defined set of error codes.
details
DocumentIntelligenceError[]
An array of details about specific errors that led to this reported error.
innererror
DocumentIntelligenceInnerError
An object containing more specific information than the current object about the error.
message
string
A human-readable representation of the error.
target
string
The target of the error.
DocumentIntelligenceErrorResponse
Error response object.
Name Type Description
error
DocumentIntelligenceError
Error info.
DocumentIntelligenceInnerError
An object containing more specific information about the error.
Name Type Description
code
string
One of a server-defined set of error codes.
innererror
DocumentIntelligenceInnerError
Inner error.
message
string
A human-readable representation of the error.
In this article
URI Parameters
Responses
Security
Examples
200 OK
Content-Type: application/pdf
Pages parametresi
Sayfalar koleksiyonu, belgedeki sayfaların listesidir. Her sayfa belge içinde sıralı olarak temsil edilir ve sayfanın döndürülmüş olup olmadığını ve genişlik ile yüksekliği (piksel cinsinden boyutlar) gösteren yönlendirme açısını içerir. Model çıkışındaki sayfa birimleri gösterildiği gibi hesaplanır:
Dosya biçimi
Hesaplanan sayfa birimi
Toplam sayfa sayısı
Görüntüler (JPEG/JPG, PNG, BMP, HEIF)
Her resim = 1 sayfa birimi
Toplam resim sayısı
PDF
PDF ' deki her sayfa = 1 sayfa birimi
PDF'deki toplam sayfa sayısı
TIFF
TIFF = 1 sayfa birimindeki her resim
TIFF'deki toplam görüntü sayısı
Word (DOCX)
En fazla 3.000 karakter = 1 sayfa birimi, eklenmiş veya bağlantılı görüntüler desteklenmez
Her biri en fazla 3.000 karakterden oluşan toplam sayfa sayısı
Excel (XLSX)
Her çalışma sayfası = 1 sayfa birimi, eklenmiş veya bağlı görüntüler desteklenmez
Toplam çalışma sayfası
PowerPoint (PPTX)
Her slayt = 1 sayfalık birim, eklenmiş veya bağlı görüntüler desteklenmez
Toplam slayt sayısı
HTML
En fazla 3.000 karakter = 1 sayfa birimi, eklenmiş veya bağlantılı görüntüler desteklenmez
Her biri en fazla 3.000 karakterden oluşan toplam sayfa sayısı
# Analyze pages.for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Çok sayfalı büyük PDF belgeleri için, metin ayıklama için belirli sayfa numaralarını veya sayfa aralıklarını belirtmek üzere sorgu parametresini kullanın pages .
Paragraf ayıklama
Belge Zekası'ndaki Okuma OCR modeli, koleksiyondaki paragraphs tanımlanan tüm metin bloklarını altında analyzeResultsen üst düzey nesne olarak ayıklar. Bu koleksiyondaki her girdi bir metin bloğunu temsil eder ve ayıklanan metni ve sınırlayıcı polygon koordinatları içerircontent. Bilgiler, span belgenin tam metnini içeren üst düzey content özellik içindeki metin parçasını gösterir.
JSON
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Metin, satır ve sözcük ayıklama
Okuma OCR modeli, yazdırma ve el yazısı stil metinlerini ve wordsolarak lines ayıklar. Model, sınırlayıcı polygon koordinatlar ve confidence ayıklanan sözcükler için çıkış oluşturur. Koleksiyon, styles algılanırsa satırlar için el yazısı stilini ve ilişkili metne işaret eden aralıkları içerir. Bu özellik desteklenen el yazısı diller için geçerlidir.
Microsoft Word, Excel, PowerPoint ve HTML için, Belge Zekası Okuma modeli v3.1 ve sonraki sürümler tüm eklenmiş metni olduğu gibi ayıklar. Metinler sözcük ve paragraf olarak eklenir. Eklenmiş görüntüler desteklenmez.
# Analyze lines.if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{line.polygon}'"
)
# Analyze words.for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
El yazısı stil ayıklama
Yanıt, her metin satırının el yazısı stilinde olup olmadığını ve güvenilirlik puanını sınıflandırmayı içerir. Daha fazla bilgi için bkz. El yazısı dil desteği. Aşağıdaki örnekte örnek bir JSON kod parçacığı gösterilmektedir.
Bu içerik şunlar için geçerlidir:v3.1 (GA) | En son sürüm: v4.0 (GA) | Önceki sürümler:v3.0
Bu içerik şunlar için geçerlidir:v3.0 (GA) | En son sürümler: v4.0 (GA)v3.1
Not
Etiketler, sokak işaretleri ve posterler gibi dış görüntülerden metin ayıklamak için, performans açısından geliştirilmiş zaman uyumlu API'ye sahip genel (belge değil) görüntüler için iyileştirilmiş Azure AI Görüntü Analizi v4.0 Okuma özelliğini kullanın. Bu özellik, gerçek zamanlı kullanıcı deneyimi senaryolarına OCR eklemeyi kolaylaştırır.
Belge Zekası Okuma Optik Karakter Tanıma (OCR) modeli, Azure AI Görüntü İşleme Okuma'dan daha yüksek çözünürlükte çalışır ve PDF belgelerinden ve taranmış görüntülerden yazdırma ve el yazısı metinleri ayıklar. Ayrıca Microsoft Word, Excel, PowerPoint ve HTML belgelerinden metin ayıklama desteği de içerir. Paragrafları, metin satırlarını, sözcükleri, konumları ve dilleri algılar. Okuma modeli, özel modellere ek olarak Düzen, Genel Belge, Fatura, Makbuz, Kimlik (Kimlik) belgesi, Sağlık sigortası kartı, W2 gibi önceden oluşturulmuş diğer Belge Zekası modelleri için temel alınan OCR altyapısıdır.
Belgeler için OCR nedir?
Belgeler için Optik Karakter Tanıma (OCR), birden çok dosya biçiminde ve genel dilde büyük metin ağırlıklı belgeler için iyileştirilmiştir. Daha küçük ve yoğun metinlerin daha iyi işlenmesi için belge görüntülerinin daha yüksek çözünürlüklü taranmış olması gibi özellikler içerir; paragraf algılama; ve doldurulabilir form yönetimi. OCR özellikleri, tek karakterli kutular gibi gelişmiş senaryoları ve faturalarda, makbuzlarda ve diğer önceden oluşturulmuş senaryolarda yaygın olarak bulunan anahtar alanlarının doğru ayıklarını içerir.
Dağıtım seçenekleri
Document Intelligence v3.1 aşağıdaki araçları, uygulamaları ve kitaplıkları destekler:
Microsoft Office: Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTML
Okundu
✔
✔
✔
Düzen
✔
✔
✔
Genel Belge
✔
✔
Önceden oluşturulmuş
✔
✔
Özel ayıklama
✔
✔
Özel sınıflandırma
✔
✔
✔
En iyi sonuçları elde için belge başına tek bir net fotoğraf veya yüksek kaliteli tarama sağlayın.
PDF ve TIFF için en fazla 2.000 sayfa işlenebilir (ücretsiz katman aboneliğiyle yalnızca ilk iki sayfa işlenir).
Belgeleri analiz etmek için dosya boyutu ücretli (S0) katman için 500 MB ve 4 ücretsiz (F0) katman için MB'tır.
Görüntü boyutları 50 piksel x 50 piksel ile 10.000 piksel x 10.000 piksel arasında olmalıdır.
PDF’leriniz parola korumalıysa göndermeden önce kilidi kaldırmanız gerekir.
Ayıklanacak metnin en düşük yüksekliği 1024 x 768 piksel görüntü için 12 pikseldir. Bu boyut, yaklaşık 150 nokta/inç (DPI) nokta metnine karşılık gelir 8 .
Özel model eğitimi için eğitim verileri için en fazla sayfa sayısı özel şablon modeli için 500, özel sinir modeli için 50.000'dir.
Özel ayıklama modeli eğitimi için eğitim verilerinin toplam boyutu şablon modeli için 50 MB ve 1 sinir modeli için GB'tır.
Özel sınıflandırma modeli eğitimi için eğitim verilerinin toplam boyutu en fazla 10.000 sayfa ile GB'tır 1 . 2024-11-30 (GA) için eğitim verilerinin toplam boyutu gb ve en fazla 10.000 sayfadır 2 .
Okuma modelini kullanmaya başlama
Document Intelligence Studio'yu kullanarak formlardan ve belgelerden metin ayıklamayı deneyin. Aşağıdaki varlıklara ihtiyacınız vardır:
Azure portalında bir Belge Zekası örneği. Hizmeti denemek için ücretsiz fiyatlandırma katmanını (F0) kullanabilirsiniz. Kaynağınız dağıtıldıktan sonra anahtarınızı ve uç noktanızı almak için Kaynağa git'i seçin.
Not
Document Intelligence Studio şu anda Microsoft Word, Excel, PowerPoint ve HTML dosya biçimlerini desteklememektedir.
Desteklenen dillerin tam listesi için Dil Desteği— belge çözümleme modelleri sayfamıza bakın.
Veri ayıklama
Not
Microsoft Word ve HTML dosyası v4.0'da desteklenir. Şu anda aşağıdaki özellikler desteklenmemektedir:
Her sayfa nesnesiyle açı, genişlik/yükseklik ve birim döndürülmedi.
Algılanan her nesne için sınırlayıcı çokgen veya sınırlayıcı bölge yok.
Parametre olarak sayfa aralığı (pages) döndürülmedi.
Nesne yok lines .
Aranabilir PDF
Aranabilir PDF özelliği, taranmış resim PDF dosyaları gibi bir analog PDF'yi eklenmiş metin içeren bir PDF'ye dönüştürmenizi sağlar. Ekli metin, algılanan metin varlıklarını görüntü dosyalarının üzerine katmanlayarak PDF'nin ayıklanan içeriğinde derin metin araması sağlar.
Önemli
Şu anda yalnızca Read OCR modeli prebuilt-read aranabilir PDF özelliğini destekler. Bu özelliği kullanırken olarak prebuilt-readbelirtinmodelId. Diğer model türleri hata döndürür.
Aranabilir PDF, aranabilir BIR PDF çıktısı 2024-11-30prebuilt-read oluşturmak için ek maliyet olmadan modele dahil edilir.
Aranabilir PDF şu anda yalnızca GIRIŞ olarak PDF dosyalarını destekler.
Aranabilir PDF kullanma
Aranabilir PDF'yi kullanmak için işlemi kullanarak bir POST istekte bulunup Analyze çıkış biçimini olarak pdfbelirtin:
Bash
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
İşlemin tamamlanmasını yoklama Analyze . İşlem tamamlandıktan sonra, işlem sonuçlarının PDF biçimini almak için bir GET istekte bulunun Analyze .
Başarıyla tamamlandıktan sonra PDF olarak alınabilir ve indirilebilir application/pdf. Bu işlem, Base64 ile kodlanmış JSON yerine PDF'nin eklenmiş metin biçiminin doğrudan indirilmesini sağlar.
Bash
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Sayfalar
Sayfalar koleksiyonu, belgedeki sayfaların listesidir. Her sayfa belge içinde sıralı olarak temsil edilir ve sayfanın döndürülmüş olup olmadığını ve genişlik ile yüksekliği (piksel cinsinden boyutlar) gösteren yönlendirme açısını içerir. Model çıkışındaki sayfa birimleri gösterildiği gibi hesaplanır:
Dosya biçimi
Hesaplanan sayfa birimi
Toplam sayfa sayısı
Görüntüler (JPEG/JPG, PNG, BMP, HEIF)
Her resim = 1 sayfa birimi
Toplam resim sayısı
PDF
PDF ' deki her sayfa = 1 sayfa birimi
PDF'deki toplam sayfa sayısı
TIFF
TIFF = 1 sayfa birimindeki her resim
TIFF'deki toplam görüntü sayısı
Word (DOCX)
En fazla 3.000 karakter = 1 sayfa birimi, eklenmiş veya bağlantılı görüntüler desteklenmez
Her biri en fazla 3.000 karakterden oluşan toplam sayfa sayısı
Excel (XLSX)
Her çalışma sayfası = 1 sayfa birimi, eklenmiş veya bağlı görüntüler desteklenmez
Toplam çalışma sayfası
PowerPoint (PPTX)
Her slayt = 1 sayfalık birim, eklenmiş veya bağlı görüntüler desteklenmez
Toplam slayt sayısı
HTML
En fazla 3.000 karakter = 1 sayfa birimi, eklenmiş veya bağlantılı görüntüler desteklenmez
Her biri en fazla 3.000 karakterden oluşan toplam sayfa sayısı
# Analyze pages.for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Çok sayfalı büyük PDF belgeleri için, metin ayıklama için belirli sayfa numaralarını veya sayfa aralıklarını belirtmek üzere sorgu parametresini kullanın pages .
Paragraf
Belge Zekası'ndaki Okuma OCR modeli, koleksiyondaki paragraphs tanımlanan tüm metin bloklarını altında analyzeResultsen üst düzey nesne olarak ayıklar. Bu koleksiyondaki her girdi bir metin bloğunu temsil eder ve ayıklanan metni ve sınırlayıcı polygon koordinatları içerircontent. Bilgiler, span belgenin tam metnini içeren üst düzey content özellik içindeki metin parçasını gösterir.
JSON
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Metin, satır ve sözcükler
Okuma OCR modeli, yazdırma ve el yazısı stil metinlerini ve wordsolarak lines ayıklar. Model, sınırlayıcı polygon koordinatlar ve confidence ayıklanan sözcükler için çıkış oluşturur. Koleksiyon, styles algılanırsa satırlar için el yazısı stilini ve ilişkili metne işaret eden aralıkları içerir. Bu özellik desteklenen el yazısı diller için geçerlidir.
Microsoft Word, Excel, PowerPoint ve HTML için, Belge Zekası Okuma modeli v3.1 ve sonraki sürümler tüm eklenmiş metni olduğu gibi ayıklar. Metinler sözcük ve paragraf olarak eklenir. Eklenmiş görüntüler desteklenmez.
JSON
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
Metin satırları için el yazısı stili
Yanıt, her metin satırının el yazısı stilinde olup olmadığını ve güvenilirlik puanını sınıflandırmayı içerir. Daha fazla bilgi için bkz. El yazısı dil desteği. Aşağıdaki örnekte örnek bir JSON kod parçacığı gösterilmektedir.
Diğer geliştiriciler ve uzmanlarla gerçek dünyadaki kullanım örneklerini temel alan ölçeklenebilir yapay zeka çözümleri oluşturmak için toplantı serisine katılın.
Azure'ın Yapay Zeka Görüntü İşleme hizmeti, ilgilendiğiniz görsel özelliklere göre görüntüleri işlemek ve bilgi döndürmek için gelişmiş algoritmalar kullanır. Bu modülde Azure AI Vision'ın Görüntü Analizi OCR özelliğini nasıl kullanacağınız öğretildi.
Belge Yönetim Bilgileri istemci kitaplıklarını veya REST API'sini kullanmayı ve belgelerden önemli verileri ayıklamak için uygulamalar oluşturmayı öğrenin.
Belge Yönetim Bilgileri'nden düzen çözümleme modeliyle metin, tablo, seçim, başlık, bölüm başlığı, sayfa üst bilgisi, sayfa alt bilgisi ve daha fazlasını ayıklayın.
Belgelerinizden önemli verileri ve yapı öğelerini ayıklayan bir form işleme uygulaması oluşturmak için Belge Yönetim Bilgileri SDK'sını veya REST API'sini kullanın.
Azure AI Belge Zekası, formlardan ve belgelerden önemli verilerin ayıklanırken otomatik hale getirmek için makine öğrenmesi tabanlı bir OCR ve akıllı belge işleme hizmetidir.
Azure AI Belge Zekası, belgelerinizden anahtar-değer çiftlerini, metinleri ve tabloları ayıklamak için makine öğrenmesi modellerini kullanan bulut tabanlı bir Azure yapay zeka hizmetidir. Belge Yönetim Bilgileri formlarınızı ve belgelerinizi analiz eder, metin ve verileri ayıklar, alan ilişkilerini anahtar-değer çiftleri olarak eşler ve yapılandırılmış bir JSON çıktısı döndürür. Aşırı el ile müdahale veya kapsamlı veri bilimi uzmanlığı olmadan, özel içeriğinize göre uyarlanmış doğru sonuçları hızla alırsını