Bu başvuru mimarisi, Azure Databricks kullanarak bir öneri modelini eğitmeyi ve ardından Azure Cosmos DB, Azure Machine Learning ve Azure Kubernetes Service (AKS) kullanarak modeli API olarak dağıtmayı gösterir. Bu mimarinin başvuru uygulaması için bkz . GitHub'da Gerçek Zamanlı Öneri API'sini oluşturma.
Mimari
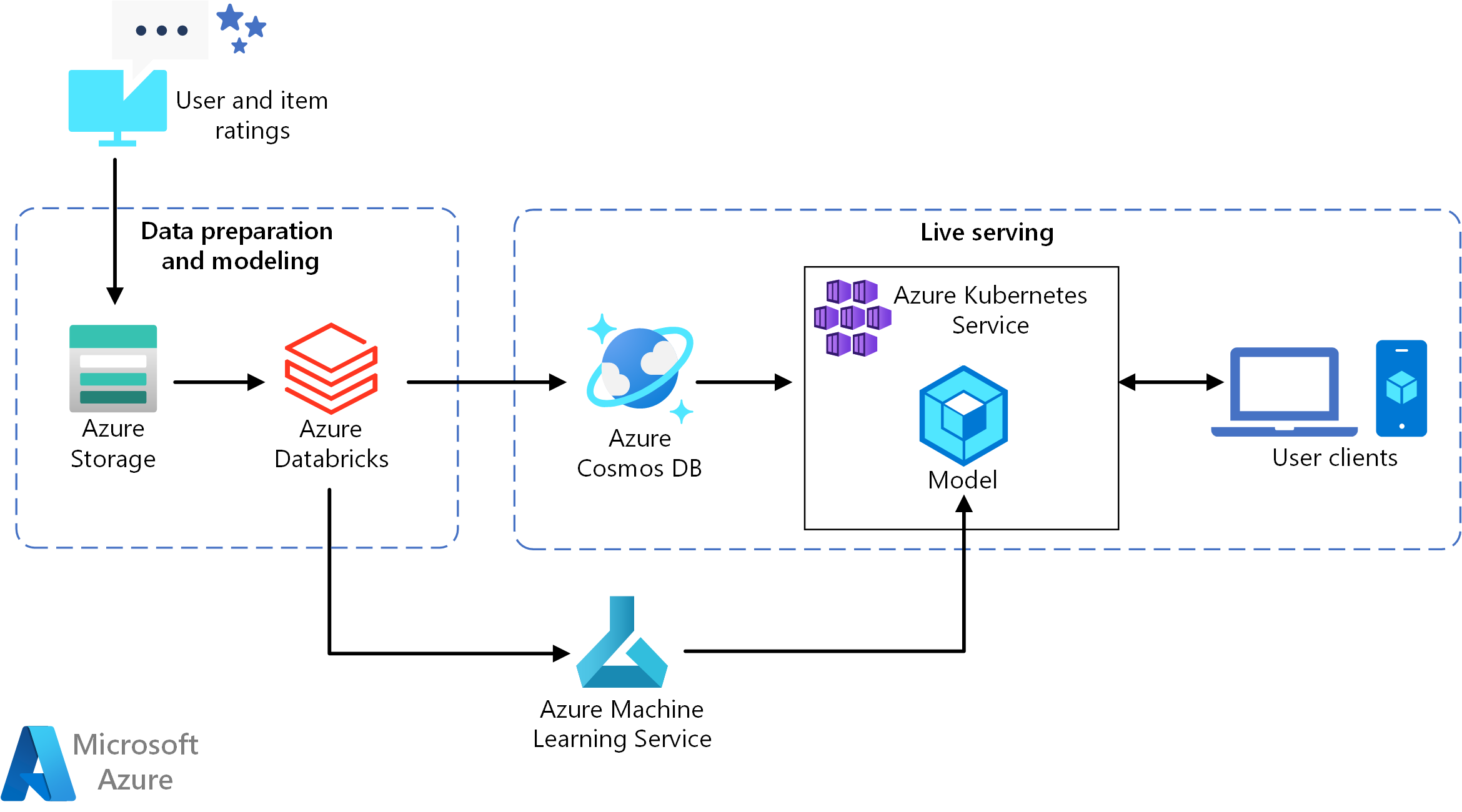
Bu mimarinin bir Visio dosyasını indirin.
Bu başvuru mimarisi, bir kullanıcıya en iyi 10 film önerisi sağlayabilen gerçek zamanlı bir önerilen hizmet API'sini eğitme ve dağıtmaya yöneliktir.
Veri akışı
- Kullanıcı davranışlarını izleme. Örneğin, bir arka uç hizmeti bir kullanıcı bir filmi fiyatladığında veya bir ürüne veya haber makalesine tıkladığında günlüğe kaydedilebilir.
- Verileri kullanılabilir bir veri kaynağından Azure Databricks'e yükleyin.
- Verileri hazırlayın ve modeli eğitmek için eğitim ve test kümelerine bölün. (Bu kılavuzda verileri bölme seçenekleri açıklanmaktadır.)
- Spark İşbirliğine Dayalı Filtreleme modelini verilere sığdırın.
- Derecelendirme ve derecelendirme ölçümlerini kullanarak modelin kalitesini değerlendirin. (Bu kılavuzda , önerinizi değerlendirmek için kullanabileceğiniz ölçümlerle ilgili ayrıntılar sağlanır.)
- Kullanıcı başına en iyi 10 öneriyi önceden derleyip Azure Cosmos DB'de önbellek olarak depolayın.
- API'yi kapsayıcıya almak ve dağıtmak için Machine Learning API'lerini kullanarak AKS'ye bir API hizmeti dağıtın.
- Arka uç hizmeti bir kullanıcıdan istek aldığında, ilk 10 öneriyi almak ve bunları kullanıcıya görüntülemek için AKS'de barındırılan öneriler API'sini çağırın.
Bileşenler
- Azure Databricks. Databricks, giriş verilerini hazırlamak ve spark kümesinde önerilen modeli eğitmek için kullanılan bir geliştirme ortamıdır. Azure Databricks ayrıca tüm veri işleme veya makine öğrenmesi görevleri için not defterlerini çalıştırmak ve üzerinde işbirliği yapmak için etkileşimli bir çalışma alanı sağlar.
- Azure Kubernetes Service (AKS). AKS, Kubernetes kümesinde makine öğrenmesi modeli hizmet API'sini dağıtmak ve kullanıma hazır hale getirmek için kullanılır. AKS kapsayıcılı modeli barındırarak aktarım hızı gereksinimlerinizi, kimlik ve erişim yönetiminizi ve günlüğe kaydetme ve sistem durumu izlemenizi karşılayan ölçeklenebilirlik sağlar.
- Azure Cosmos DB. Azure Cosmos DB, her kullanıcı için en çok önerilen 10 filmi depolamak için kullanılan genel olarak dağıtılmış bir veritabanı hizmetidir. Azure Cosmos DB, belirli bir kullanıcı için en çok önerilen öğeleri okumak için düşük gecikme süresi (99. yüzdebirlik dilimde 10 ms) sağladığından bu senaryo için uygundur.
- Makine Öğrenmesi. Bu hizmet, makine öğrenmesi modellerini izlemek ve yönetmek ve ardından bu modelleri paketleyip ölçeklenebilir bir AKS ortamına dağıtmak için kullanılır.
- Microsoft Recommenders. Bu açık kaynak deposu, kullanıcıların bir öneride bulunan sistemi oluşturmaya, değerlendirmeye ve kullanıma hazır hale getirmesine yardımcı olmak için yardımcı program kodu ve örnekler içerir.
Senaryo ayrıntıları
Bu mimari, ürünler, filmler ve haberler için öneriler de dahil olmak üzere çoğu öneri altyapısı senaryosu için genelleştirilebilir.
Olası kullanım örnekleri
Senaryo: Bir medya kuruluşu, kullanıcılarına film veya video önerileri sağlamak istiyor. Kişiselleştirilmiş öneriler sağlayarak kuruluş, artan tıklama oranları, web sitesinde daha fazla katılım ve daha yüksek kullanıcı memnuniyeti dahil olmak üzere çeşitli iş hedeflerini karşılar.
Bu çözüm perakende sektörü ve medya ve eğlence sektörleri için optimize edilmiştir.
Dikkat edilmesi gereken noktalar
Bu önemli noktalar, bir iş yükünün kalitesini artırmak için kullanılabilecek bir dizi yol gösteren ilke olan Azure İyi Tasarlanmış Çerçeve'nin yapı taşlarını uygular. Daha fazla bilgi için bkz . Microsoft Azure İyi Tasarlanmış Çerçeve.
Azure Databricks'te Spark modellerinin toplu puanlaması, zamanlanmış toplu puanlama işlemlerini yürütmek için Spark ve Azure Databricks kullanan bir başvuru mimarisini açıklar. Yeni öneriler oluşturmak için bu yaklaşımı öneririz.
Performans verimliliği
Performans verimliliği, kullanıcılar tarafından anlamlı bir şekilde yerleştirilen talepleri karşılamak amacıyla iş yükünüzü ölçeklendirme becerisidir. Daha fazla bilgi için bkz . Performans verimliliği sütununa genel bakış.
Öneriler genellikle web sitenizdeki bir kullanıcı isteğinin kritik yoluna düştüğünden, gerçek zamanlı öneriler için performans önemli bir noktadır.
AKS ve Azure Cosmos DB'nin birleşimi, bu mimarinin en düşük ek yüke sahip orta büyüklükte bir iş yüküne yönelik öneriler sağlamak için iyi bir başlangıç noktası sağlamasına olanak tanır. 200 eşzamanlı kullanıcının yük testi altında, bu mimari yaklaşık 60 ms ortanca gecikme süresiyle ilgili öneriler sağlar ve saniyede 180 istek aktarım hızıyla performans gösterir. Yük testi varsayılan dağıtım yapılandırmasına (Azure Cosmos DB için sağlanan saniyede 12 vCPU, 42 GB bellek ve 11.000 İstek Birimi (RU) ile 3x D3 v2 AKS kümesi) karşı çalıştırıldı.
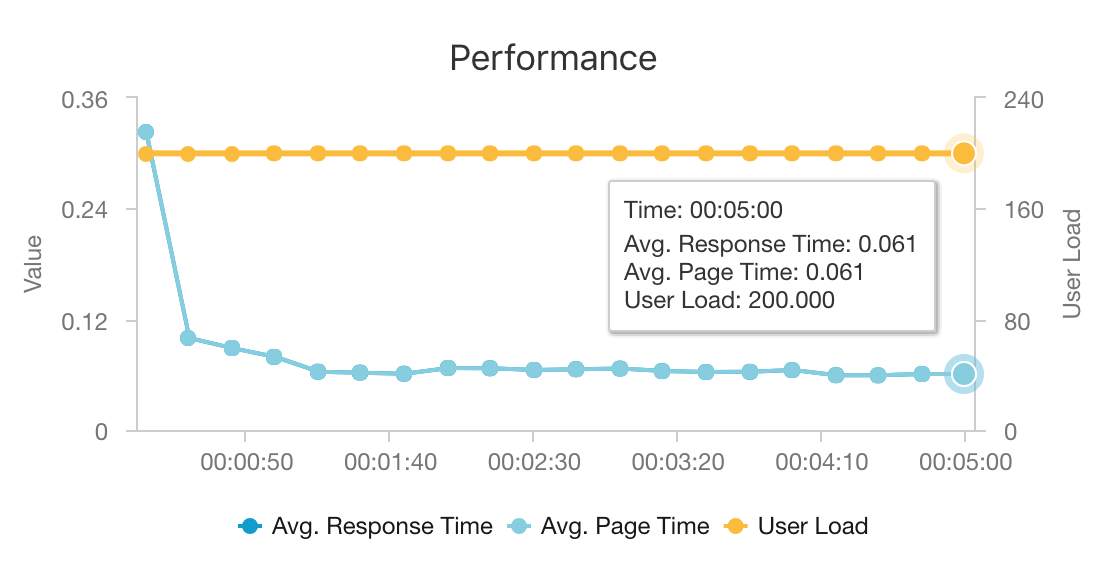
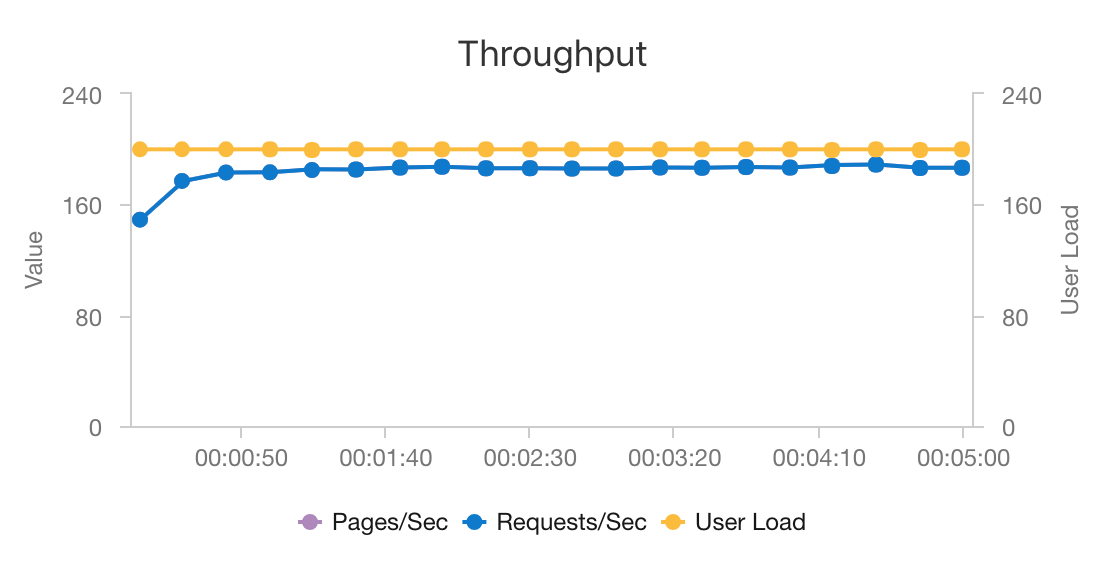
Azure Cosmos DB, anahtar teslimi genel dağıtımı ve uygulamanızın tüm veritabanı gereksinimlerini karşılamada yararlı olması için önerilir. Gecikme süresini biraz azaltmak için, aramalara hizmet vermek için Azure Cosmos DB yerine Redis için Azure Cache kullanmayı göz önünde bulundurun. Redis için Azure Cache, arka uç depolarındaki verilere yoğun bir şekilde bağımlı olan sistemlerin performansını artırabilir.
Ölçeklenebilirlik
Spark kullanmayı planlamıyorsanız veya dağıtım gerektirmeyen daha küçük bir iş yükünüz varsa Azure Databricks yerine bir Veri Bilimi Sanal Makinesi (DSVM) kullanmayı göz önünde bulundurun. DSVM, derin öğrenme çerçeveleri ve makine öğrenmesi ile veri bilimi için araçlar içeren bir Azure sanal makinesidir. Azure Databricks'te olduğu gibi, DSVM'de oluşturduğunuz tüm modeller Machine Learning aracılığıyla AKS'de hizmet olarak kullanıma hazır hale getirilebilir.
Eğitim sırasında Azure Databricks'te daha büyük bir sabit boyutlu Spark kümesi sağlayın veya otomatik ölçeklendirmeyi yapılandırın. Otomatik ölçeklendirme etkinleştirildiğinde Databricks kümenizdeki yükü izler ve gerektiğinde ölçeği büyütüp küçültür. Büyük bir veri boyutunuz varsa ve veri hazırlama veya modelleme görevleri için gereken süreyi azaltmak istiyorsanız, daha büyük bir kümeyi sağlayın veya ölçeklendirin.
PERFORMANS ve aktarım hızı gereksinimlerinizi karşılamak için AKS kümesini ölçeklendirin. Kümeyi tam olarak kullanmak için pod sayısını artırmaya ve hizmetinizin talebini karşılamak için küme düğümlerini ölçeklendirmeye dikkat edin. Aks kümesinde otomatik ölçeklendirme de ayarlayabilirsiniz. Daha fazla bilgi için bkz . Azure Kubernetes Service kümesine model dağıtma.
Azure Cosmos DB performansını yönetmek için saniye başına gereken okuma sayısını tahmin edin ve gereken saniye başına RU sayısını (aktarım hızı) sağlayın. Bölümleme ve yatay ölçeklendirme için en iyi yöntemleri kullanın.
Maliyet iyileştirme
Maliyet iyileştirmesi, gereksiz giderleri azaltmanın ve operasyonel verimlilikleri iyileştirmenin yollarını aramaktır. Daha fazla bilgi için bkz . Maliyet iyileştirme sütununa genel bakış.
Bu senaryoda maliyetin başlıca etmenleri şunlardır:
- Eğitim için gereken Azure Databricks küme boyutu.
- Performans gereksinimlerinizi karşılamak için gereken AKS kümesi boyutu.
- Performans gereksinimlerinizi karşılamak için sağlanan Azure Cosmos DB RU'ları.
Azure Databricks maliyetlerini daha az sıklıkta yeniden eğiterek ve kullanımda olmadığında Spark kümesini kapatarak yönetin. AKS ve Azure Cosmos DB maliyetleri, sitenizin gerektirdiği aktarım hızına ve performansa bağlıdır ve sitenize gelen trafik hacmine bağlı olarak ölçeği artırıp azaltacaktır.
Bu senaryoyu dağıtın
Bu mimariyi dağıtmak için kurulum belgesindeki Azure Databricks yönergelerini izleyin. Kısaca yönergeler şunları gerektirir:
- Azure Databricks çalışma alanı oluşturun.
- Azure Databricks'te aşağıdaki yapılandırmayla yeni bir küme oluşturun:
- Küme modu: Standart
- Databricks çalışma zamanı sürümü: 4.3 (Apache Spark 2.3.1, Scala 2.11 içerir)
- Python sürümü: 3
- Sürücü türü: Standard_DS3_v2
- Çalışan türü: Standard_DS3_v2 (gerektiği gibi en az ve en fazla)
- Otomatik sonlandırma: (gerektiği gibi)
- Spark yapılandırması: (gerektiği gibi)
- Ortam değişkenleri: (gerektiği gibi)
- Azure Databricks çalışma alanında kişisel erişim belirteci oluşturun. Ayrıntılar için Azure Databricks kimlik doğrulaması belgelerine bakın.
- Microsoft Recommenders deposunu betikleri (örneğin, yerel bilgisayarınız) yürütebileceğiniz bir ortama kopyalayın.
- Azure Databricks'e ilgili kitaplıkları yüklemek için Hızlı yükleme kurulum yönergelerini izleyin.
- Azure Databricks'i kullanıma hazır hale getirmek için Hızlı yükleme kurulum yönergelerini izleyin.
- ALS Movie Operationalization not defterini çalışma alanınıza aktarın. Azure Databricks çalışma alanınızda oturum açtıktan sonra aşağıdakileri yapın:
- Çalışma alanının sol tarafındaki Giriş'e tıklayın.
- Giriş dizininizdeki boşluklara sağ tıklayın. İçeri aktar'ı seçin.
- URL'yi seçin ve aşağıdakileri metin alanına yapıştırın:
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb - İçe aktar'a tıklayın.
- Azure Databricks'in içinde not defterini açın ve yapılandırılan kümeyi ekleyin.
- Not defterini çalıştırarak belirli bir kullanıcı için en iyi 10 film önerisi sağlayan bir öneri API'sini oluşturmak için gereken Azure kaynaklarını oluşturun.
Katkıda Bulunanlar
Bu makale Microsoft tarafından yönetilir. Başlangıçta aşağıdaki katkıda bulunanlar tarafından yazılmıştır.
Asıl yazarlar:
- Miguel Fierro | Sorumlu Veri Bilimci Yöneticisi
- Nikhil Joglekar | Product Manager, Azure algoritmaları ve veri bilimi
Genel olmayan LinkedIn profillerini görmek için LinkedIn'de oturum açın.
Sonraki adımlar
- Gerçek Zamanlı Öneri API'si oluşturma
- Azure Databricks nedir?
- Azure Kubernetes Service
- Azure Cosmos DB'ye hoş geldiniz
- Azure Machine Learning nedir?