Çift yazma ara sunucusu ve Apache Spark kullanarak Apache Cassandra'dan Apache Cassandra için Azure Cosmos DB'ye canlı veri geçirme
Azure Cosmos DB'de Cassandra API'si, Apache Cassandra üzerinde çalışan kurumsal iş yükleri için aşağıdakiler gibi çeşitli nedenlerle harika bir seçenek haline gelmiştir:
Yönetim ve izleme yükü yoktur: İşletim sistemi, JVM ve yaml dosyalarında ve bunların etkileşimlerinde çok sayıda ayarı yönetme ve izleme yükünü ortadan kaldırır.
Önemli maliyet tasarrufları: VM'nin, bant genişliğinin ve geçerli lisansların maliyetini içeren Azure Cosmos DB ile maliyet tasarrufu yapabilirsiniz. Ayrıca veri merkezlerini, sunucuları, SSD depolamayı, ağ ve elektrik maliyetlerini yönetmeniz gerekmez.
Mevcut kodu ve araçları kullanma olanağı: Azure Cosmos DB, mevcut Cassandra SDK'ları ve araçlarıyla kablo protokolü düzeyinde uyumluluk sağlar. Bu uyumluluk, mevcut kod tabanınızı Apache Cassandra için Azure Cosmos DB ile önemsiz değişikliklerle kullanabilmenizi sağlar.
Azure Cosmos DB, çoğaltma için yerel Apache Cassandra dedikodu protokollerini desteklemez. Bu nedenle, sıfır kapalı kalma süresinin geçiş için gerekli olduğu durumlarda farklı bir yaklaşım gerekir. Bu öğreticide, çift yazma ara sunucusu ve Apache Spark kullanarak yerel bir Apache Cassandra kümesinden Apache Cassandra için Azure Cosmos DB'ye canlı veri geçirme işlemi açıklanmaktadır.
Aşağıdaki görüntüde desen gösterilmektedir. Çift yazma ara sunucusu canlı değişiklikleri yakalamak için kullanılırken, geçmiş veriler Apache Spark kullanılarak toplu olarak kopyalanır. Ara sunucu, uygulama kodunuzdan yapılandırma değişikliği yapabilen veya olmayan bağlantıları kabul edebilir. Toplu kopyalama sırasında tüm istekleri kaynak veritabanınıza yönlendirir ve cassandra için API'ye zaman uyumsuz olarak yazmaları yönlendirir.

Önkoşullar
Apache Cassandra için Azure Cosmos DB'ye bağlanmanın temellerini gözden geçirin.
Uyumluluğu sağlamak için Apache Cassandra için Azure Cosmos DB'de desteklenen özellikleri gözden geçirin.
Cassandra uç noktası için kaynak kümenizle hedef API arasında ağ bağlantınız olduğundan emin olun.
Anahtar alanını/tablo düzenini kaynak Cassandra veritabanınızdan Cassandra hesabı için hedef API'nize zaten geçirdiğinizden emin olun.
Önemli
Geçiş sırasında Apache Cassandra'yı
writetimekoruma gereksiniminiz varsa, tablo oluştururken aşağıdaki bayrakların ayarlanması gerekir:with cosmosdb_cell_level_timestamp=true and cosmosdb_cell_level_timestamp_tombstones=true and cosmosdb_cell_level_timetolive=trueÖrnek:
CREATE KEYSPACE IF NOT EXISTS migrationkeyspace WITH REPLICATION= {'class': 'org.apache.> cassandra.locator.SimpleStrategy', 'replication_factor' : '1'};CREATE TABLE IF NOT EXISTS migrationkeyspace.users ( name text, userID int, address text, phone int, PRIMARY KEY ((name), userID)) with cosmosdb_cell_level_timestamp=true and > cosmosdb_cell_level_timestamp_tombstones=true and cosmosdb_cell_level_timetolive=true;
Spark kümesi sağlama
Azure Databricks'i öneririz. Spark 3.0 veya üzerini destekleyen bir çalışma zamanı kullanın.
Önemli
Azure Databricks hesabınızın kaynak Apache Cassandra kümenizle ağ bağlantısı olduğundan emin olmanız gerekir. Bu, sanal ağ eklemesi gerektirebilir. Daha fazla bilgi için buradaki makaleye bakın.
Spark bağımlılıkları ekleme
Hem yerel hem de Azure Cosmos DB Cassandra uç noktalarına bağlanmak için kümenize Apache Spark Cassandra Bağlayıcı kitaplığını eklemeniz gerekir. Kümenizde Kitaplıklar> YeniMavenYükle'yi> seçin ve ardından Maven koordinatlarını ekleyincom.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0.
Önemli
Geçiş sırasında her satır için Apache Cassandra'yı writetime koruma gereksiniminiz varsa bu örneği kullanmanızı öneririz. Bu örnekteki bağımlılık jar'ı spark bağlayıcısını da içerdiğinden yukarıdaki bağlayıcı derlemesi yerine bunu yüklemeniz gerekir. Bu örnek, geçmiş veri yükü tamamlandıktan sonra kaynak ve hedef arasında satır karşılaştırma doğrulaması gerçekleştirmek istediğinizde de yararlıdır. Daha fazla ayrıntı için aşağıdaki "geçmiş veri yükünü çalıştırma" ve "kaynağı ve hedefi doğrulama" bölümlerine bakın.
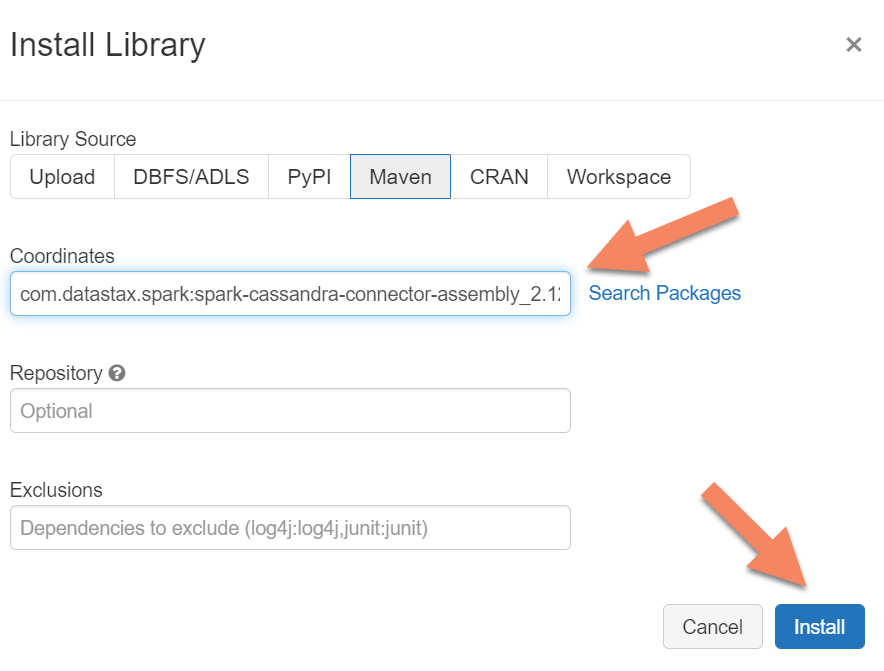
Yükle'yi seçin ve yükleme tamamlandığında kümeyi yeniden başlatın.
Not
Cassandra Bağlayıcı kitaplığı yüklendikten sonra Azure Databricks kümesini yeniden başlattığınızdan emin olun.
Çift yazma ara sunucusunu yükleme
İkili yazma sırasında en iyi performans için, ara sunucuyu kaynak Cassandra kümenizdeki tüm düğümlere yüklemenizi öneririz.
#assuming you do not have git already installed
sudo apt-get install git
#assuming you do not have maven already installed
sudo apt install maven
#clone repo for dual-write proxy
git clone https://github.com/Azure-Samples/cassandra-proxy.git
#change directory
cd cassandra-proxy
#compile the proxy
mvn package
Çift yazma ara sunucusunu başlatma
Proxy'yi kaynak Cassandra kümenizdeki tüm düğümlere yüklemenizi öneririz. Her düğümde ara sunucuyu başlatmak için en azından aşağıdaki komutu çalıştırın. değerini hedef kümedeki düğümlerden birinin IP veya sunucu adresiyle değiştirin <target-server> . yerine <path to JKS file> yerel .jks dosyasının yolunu yazın ve yerine karşılık gelen parolayı yazın <keystore password> .
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password>
Proxy'yi bu şekilde başlatmak için aşağıdakilerin doğru olduğu varsayılır:
- Kaynak ve hedef uç noktaları aynı kullanıcı adı ve parolaya sahiptir.
- Kaynak ve hedef uç noktalar Güvenli Yuva Katmanı (SSL) uygular.
Kaynak ve hedef uç noktalarınız bu ölçütleri karşılamıyorsa diğer yapılandırma seçenekleri için okumaya devam edin.
SSL yapılandırma
SSL için mevcut bir anahtar deposu (örneğin, kaynak kümenizin kullandığı) uygulayabilir veya kullanarak keytoolotomatik olarak imzalanan bir sertifika oluşturabilirsiniz:
keytool -genkey -keyalg RSA -alias selfsigned -keystore keystore.jks -storepass password -validity 360 -keysize 2048
Ayrıca, SSL uygulamazlarsa kaynak veya hedef uç noktalar için SSL'yi devre dışı bırakabilirsiniz. --disable-source-tls veya --disable-target-tls bayraklarını kullanın:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password> --disable-source-tls true --disable-target-tls true
Not
İstemci uygulamanızın, ara sunucu aracılığıyla veritabanına SSL bağlantıları oluştururken çift yazma ara sunucusu için kullanılanlarla aynı anahtar deposunu ve parolayı kullandığından emin olun.
Kimlik bilgilerini ve bağlantı noktasını yapılandırma
Varsayılan olarak, kaynak kimlik bilgileri istemci uygulamanızdan geçirilir. Proxy, kaynak ve hedef kümelere bağlantı oluşturmak için kimlik bilgilerini kullanır. Daha önce belirtildiği gibi, bu işlem kaynak ve hedef kimlik bilgilerinin aynı olduğunu varsayar. Ara sunucuyu başlatırken Cassandra uç noktası için hedef API için farklı bir kullanıcı adı ve parolanın ayrı olarak belirtilmesi gerekir:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
Belirtilmediğinde varsayılan kaynak ve hedef bağlantı noktaları 9042 olacaktır. Bu durumda, Cassandra API'si bağlantı noktası 10350üzerinde çalışır, bu nedenle bağlantı noktası numaralarını belirtmek için veya --target-port kullanmanız --source-port gerekir:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
Ara sunucuyu uzaktan dağıtma
Proxy'yi küme düğümlerine yüklemek istemediğiniz ve bunu ayrı bir makineye yüklemeyi tercih ettiğiniz durumlar olabilir. Bu senaryoda, ip adresini <source-server>belirtmeniz gerekir:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar <source-server> <destination-server>
Uyarı
Proxy'yi ayrı bir makinede uzaktan yükleyip çalıştırmak (kaynak Apache Cassandra kümenizdeki tüm düğümlerde çalıştırmak yerine), dinamik geçiş gerçekleşirken performansı etkiler. İşlevsel olarak çalışacak olsa da, istemci sürücüsü kümedeki tüm düğümlere bağlantıları açamaz ve bağlantı kurmak için tek bir koordinatlayıcı düğümüne (proxy'nin yüklendiği yer) güvenir.
Sıfır uygulama kodu değişikliğine izin ver
Varsayılan olarak, ara sunucu 29042 numaralı bağlantı noktasını dinler. Uygulama kodunun bu bağlantı noktasına işaret etmesi için değiştirilmesi gerekir. Ancak, proxy'nin dinleyebileceği bağlantı noktasını değiştirebilirsiniz. Uygulama düzeyi kod değişikliklerini ortadan kaldırmak için şunları yapabilirsiniz:
- Kaynak Cassandra sunucusunun farklı bir bağlantı noktasında çalıştırılması.
- Proxy'nin standart Cassandra bağlantı noktası 9042'de çalıştırılması.
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042
Not
Proxy'yi küme düğümlerine yüklemek için düğümlerin yeniden başlatılması gerekmez. Ancak, birçok uygulama istemciniz varsa ve uygulama düzeyindeki kod değişikliklerini ortadan kaldırmak için proxy'nin standart Cassandra bağlantı noktası 9042'de çalışmasını tercih ediyorsanız, Apache Cassandra varsayılan bağlantı noktasını değiştirmeniz gerekir. Ardından kümenizdeki düğümleri yeniden başlatmanız ve kaynak bağlantı noktasını kaynak Cassandra kümeniz için tanımladığınız yeni bağlantı noktası olacak şekilde yapılandırmanız gerekir.
Aşağıdaki örnekte kaynak Cassandra kümesini 3074 numaralı bağlantı noktasında çalışacak şekilde değiştiriyoruz ve kümeyi 9042 numaralı bağlantı noktasında başlatıyoruz:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042 --source-port 3074
Zorlama protokolleri
Ara sunucu, protokolleri zorlama işlevselliğine sahiptir. Bu, kaynak uç nokta hedeften daha gelişmişse veya başka bir şekilde desteklenmiyorsa gerekli olabilir. Bu durumda, protokolü hedefe uymaya zorlamak için ve --cql-version belirtebilirsiniz--protocol-version:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --protocol-version 4 --cql-version 3.11
Çift yazma ara sunucusu çalıştırıldıktan sonra, uygulama istemcinizde bağlantı noktasını değiştirmeniz ve yeniden başlatmanız gerekir. (Ya da Cassandra bağlantı noktasını değiştirin ve bu yaklaşımı seçtiyseniz kümeyi yeniden başlatın.) Ardından ara sunucu yazmaları hedef uç noktaya iletmeye başlar. İzleme ve ölçümler hakkında bilgi edinmek için ara sunucu aracını kullanabilirsiniz.
Geçmiş veri yükünü çalıştırma
Verileri yüklemek için Azure Databricks hesabınızda bir Scala not defteri oluşturun. Kaynak ve hedef Cassandra yapılandırmalarınızı karşılık gelen kimlik bilgileriyle değiştirin, kaynak ve hedef anahtar alanlarını ve tabloları değiştirin. Aşağıdaki örne gereken şekilde her tablo için daha fazla değişken ekleyin ve ardından komutunu çalıştırın. Uygulamanız çift yazma ara sunucusuna istek göndermeye başladıktan sonra geçmiş verileri geçirmeye hazırsınız demektir.
Önemli
Verileri geçirmeden önce kapsayıcı aktarım hızını uygulamanızın hızlı bir şekilde geçirilmesi için gereken miktara yükseltin. Geçişe başlamadan önce aktarım hızını ölçeklendirmek, verilerinizi daha kısa sürede geçirmenize yardımcı olur. Geçmiş veri yükü sırasında hız sınırlamaya karşı korumaya yardımcı olmak için Cassandra için API'de sunucu tarafı yeniden denemelerini (SSR) etkinleştirmek isteyebilirsiniz. SSR'yi etkinleştirme hakkında daha fazla bilgi ve yönergeler için buradaki makalemize bakın.
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "10350",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//set timestamp to ensure it is before read job starts
val timestamp: Long = System.currentTimeMillis / 1000
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.option("writetime", timestamp)
.mode(SaveMode.Append)
.save
Not
Önceki Scala örneğinde, kaynak tablodaki tüm verileri okumadan önce bunun geçerli saate ayarlandığını fark timestamp edeceksiniz. Ardından, writetime bu destekli zaman damgasına ayarlanıyor. Bu, geçmiş veri yükünden hedef uç noktaya yazılan kayıtların, geçmiş veriler okunurken çift yazma proxy'sinden daha sonra gelen güncelleştirmelerin üzerine yazamamasını sağlar.
Önemli
Herhangi bir nedenle tam zaman damgalarını korumanız gerekiyorsa, bu örnek gibi zaman damgalarını koruyan geçmişe dönük bir veri geçişi yaklaşımını benimsemeniz gerekir. Örnekteki bağımlılık jar'ı spark bağlayıcısını da içerir, bu nedenle önceki önkoşullarda bahsedilen Spark bağlayıcı derlemesini yüklemeniz gerekmez; her ikisinin de Spark kümenizde yüklü olması çakışmalara neden olur.
Kaynağı ve hedefi doğrulama
Geçmiş veri yükü tamamlandıktan sonra veritabanlarınız eşitlenmiş ve tam geçiş için hazır olmalıdır. Ancak, son olarak kesmeden önce eşleşmelerini sağlamak için kaynağı ve hedefi doğrulamanızı öneririz.
Not
korumak writetimeiçin yukarıda belirtilen cassandra geçişi örneğini kullandıysanız, bu, kaynak ve hedefteki satırları belirli toleranslara göre karşılaştırarakgeçişi doğrulama özelliğini içerir.