Apache Gremlin için Azure Cosmos DB ile graf veri modelleme
ŞUNLAR IÇIN GEÇERLIDIR:![]() Gremlin
Gremlin
Bu makalede graf veri modellerinin kullanımına yönelik öneriler sağlanır. Bu en iyi yöntemler, veriler geliştikçe graf veritabanı sisteminin ölçeklenebilirliğini ve performansını sağlamak için çok önemlidir. Verimli bir veri modeli özellikle büyük ölçekli grafikler için önemlidir.
Gereksinimler
Bu kılavuzda özetlenen işlem aşağıdaki varsayımları temel alır:
- Sorun alanı içindeki varlıklar tanımlanır. Bu varlıkların her istek için atomik olarak tüketilmesi amaçlanır. Başka bir deyişle, veritabanı sistemi birden çok sorgu isteğinde tek bir varlığın verilerini alacak şekilde tasarlanmamıştır.
- Veritabanı sistemi için okuma ve yazma gereksinimlerini anlayabilirsiniz. Bu gereksinimler graf veri modeli için gereken iyileştirmelere yol gösterir.
- Apache Tinkerpop özellik grafiği standardının ilkeleri iyi anlaşılmıştır.
Graf veritabanına ne zaman ihtiyacım var?
Bir veri etki alanındaki varlıklar ve ilişkiler aşağıdaki özelliklerden birine sahipse graf veritabanı çözümü en uygun şekilde kullanılabilir:
- Varlıklar, açıklayıcı ilişkiler aracılığıyla yüksek oranda bağlıdır . Bu senaryonun avantajı, ilişkilerin depolama alanında kalıcı olmasıdır.
- Döngüsel ilişkiler veya kendi kendine başvuruda bulunma varlıkları vardır. Bu düzen genellikle ilişkisel veya belge veritabanlarını kullanırken zorlanır.
- Varlıklar arasında dinamik olarak gelişen ilişkiler vardır. Bu düzen özellikle birçok düzeye sahip hiyerarşik veya ağaç yapılandırılmış veriler için geçerlidir.
- Varlıklar arasında çoka çok ilişkiler vardır.
- Hem varlıklar hem de ilişkiler üzerinde yazma ve okuma gereksinimleri vardır.
Yukarıdaki ölçütler karşılanırsa, graf veritabanı yaklaşımı büyük olasılıkla sorgu karmaşıklığı, veri modeli ölçeklenebilirliği ve sorgu performansı için avantajlar sağlar.
Sonraki adım grafın analiz veya işlem amacıyla kullanılıp kullanılmayacağını belirlemektir. Grafın yoğun hesaplama ve veri işleme iş yükleri için kullanılması amaçlanıyorsa Cosmos DB Spark bağlayıcısını ve GraphX kitaplığını keşfetmeye değer.
Grafik nesnelerini kullanma
Apache Tinkerpop özellik grafı standardı iki tür nesne tanımlar: köşeler ve kenarlar.
Aşağıdakiler, grafik nesnelerindeki özellikler için en iyi yöntemlerdir:
| Nesne | Özellik | Tür | Notlar |
|---|---|---|---|
| Köşe | ID | Dize | Bölüm başına benzersiz olarak zorlanır. Ekleme sırasında bir değer sağlanmazsa, otomatik olarak oluşturulan GUID depolanır. |
| Köşe | Etiketle | Dize | Bu özellik köşenin temsil ettiği varlık türünü tanımlamak için kullanılır. Bir değer sağlanmazsa, varsayılan değer köşesi kullanılır. |
| Köşe | Özellikler | Dize, boole, sayısal | Her köşedeki anahtar-değer çiftleri olarak depolanan ayrı özelliklerin listesi. |
| Köşe | Bölüm anahtarı | Dize, boole, sayısal | Bu özellik, köşenin ve giden kenarlarının nerede depolandığını tanımlar. Graf bölümleme hakkında daha fazla bilgi edinin. |
| Edge | ID | Dize | Bölüm başına benzersiz olarak zorlanır. Varsayılan olarak otomatik olarak oluşturulur. Kenarların genellikle bir kimlik tarafından benzersiz bir şekilde alınması gerekmez. |
| Edge | Etiketle | Dize | Bu özellik, iki köşenin sahip olduğu ilişki türünü tanımlamak için kullanılır. |
| Edge | Özellikler | Dize, boole, sayısal | Her kenarda anahtar-değer çiftleri olarak depolanan ayrı özelliklerin listesi. |
Not
Kenarlar bölüm anahtarı değeri gerektirmez, çünkü değer kaynak köşelerine göre otomatik olarak atanır. Daha fazla bilgi için bkz. Azure Cosmos DB'de bölümlenmiş graf kullanma.
Varlık ve ilişki modelleme yönergeleri
Aşağıdaki yönergeler , Apache Gremlin için Azure Cosmos DB graf veritabanı için veri modellemeye yaklaşmanıza yardımcı olur. Bu yönergelerde, bir veri etki alanının var olan bir tanımı ve bunun için sorgular olduğu varsayılır.
Not
Aşağıdaki adımlar öneri olarak sunulur. Son modeli üretime hazır olarak değerlendirmeden önce değerlendirip test etmelisiniz. Ayrıca öneriler Azure Cosmos DB'nin Gremlin API uygulamasına özeldir.
Köşeleri ve özellikleri modelleme
Graf veri modeli için ilk adım, tanımlanan her varlığı bir köşe nesnesine eşlemektir. Tüm varlıkların köşelere bire bir eşlenmesi ilk adım olmalı ve değiştirilebilir olmalıdır.
Yaygın bir tuzak, tek bir varlığın özelliklerini ayrı köşeler olarak eşlemektir. Aynı varlığın iki farklı şekilde temsil edildiği aşağıdaki örneği göz önünde bulundurun:
Köşe tabanlı özellikler: Bu yaklaşımda varlık, özelliklerini açıklamak için üç ayrı köşe ve iki kenar kullanır. Bu yaklaşım yedekliliği azaltabilir ancak model karmaşıklığını artırır. Model karmaşıklığındaki artış ek gecikme süresi, sorgu karmaşıklığı ve hesaplama maliyetine neden olabilir. Bu model bölümlemede de güçlükler ortaya koyabilir.
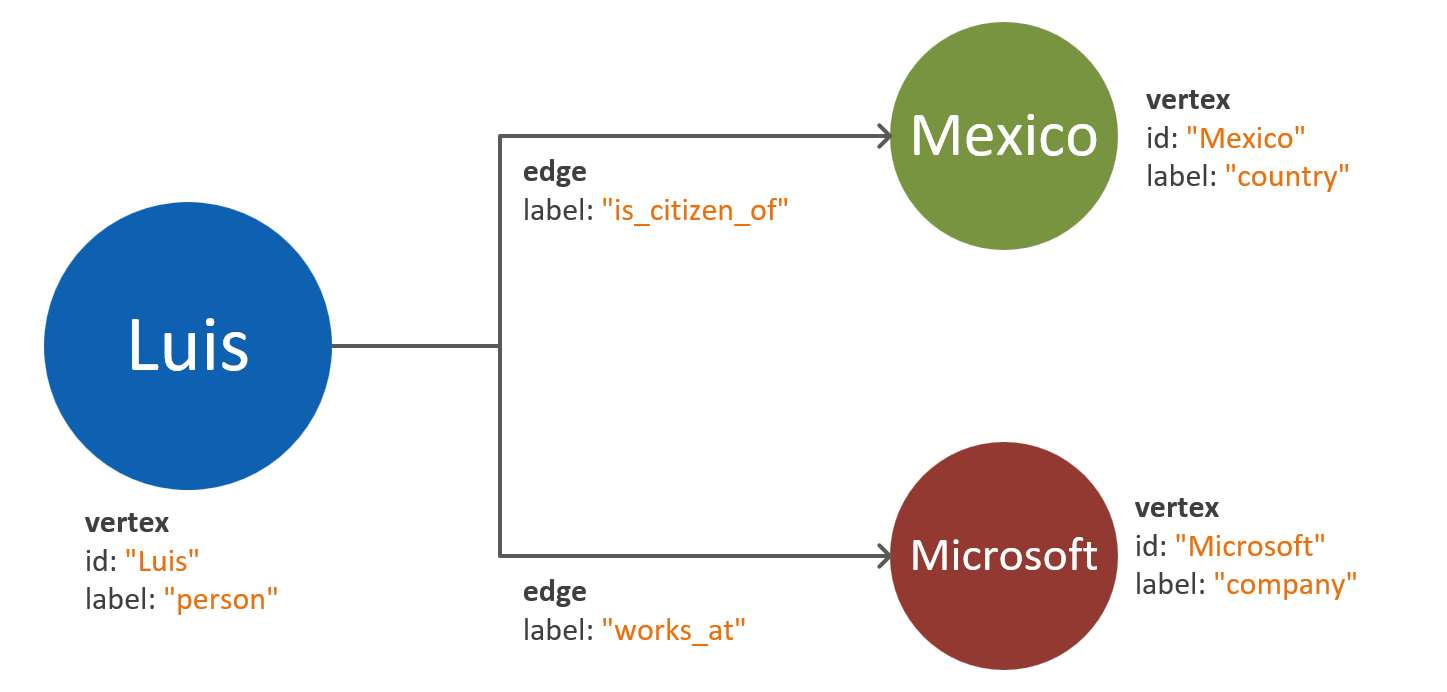
Özellik eklenmiş köşeler: Bu yaklaşım, bir köşe içindeki varlığın tüm özelliklerini temsil etmek için anahtar-değer çifti listesinden yararlanır. Bu yaklaşım model karmaşıklığını azaltarak daha basit sorgulara ve daha uygun maliyetli geçişlere yol açar.

Not
Yukarıdaki diyagramlar, varlık özelliklerini bölmenin yalnızca iki yolunu karşılaştıran basitleştirilmiş bir grafik modeli gösterir.
Özellik eklenmiş köşeler düzeni genellikle daha performanslı ve ölçeklenebilir bir yaklaşım sağlar. Yeni bir graf veri modeline yönelik varsayılan yaklaşım bu desene doğru yerçekimli olmalıdır.
Ancak, bir özelliğe başvurmanın avantaj sağlayabileceği senaryolar vardır. Örneğin, başvuruda bulunan özellik sık sık güncelleştiriliyorsa. Güncelleştirmenin gerektirdiği yazma işlemi miktarını en aza indirmek için sürekli değişen bir özelliği temsil etmek için ayrı bir köşe kullanın.
Uç yönlerini içeren ilişki modelleri
Köşeler modellendikten sonra, aralarındaki ilişkileri belirtmek için kenarlar eklenebilir. Değerlendirilmesi gereken ilk yön , ilişkinin yönüdür.
Edge nesneleri, veya outE() işlevleri kullanılırken out() bir geçiş tarafından izlenen varsayılan bir yöne sahiptir. Tüm köşeler giden kenarlarıyla depolandığından bu doğal yönün kullanılması verimli bir işlemle sonuçlanabilir.
Ancak, işlevini kullanarak in() bir kenarın ters yönünde geçiş yaparak her zaman bölümler arası sorgu elde edebilirsiniz. Graf bölümleme hakkında daha fazla bilgi edinin. İşlevi kullanarak in() sürekli geçiş yapmanız gerekiyorsa her iki yönde de kenar eklemeniz önerilir.
Gremlin adımıyla .addE() veya .from() koşullarını kullanarak .to() kenar yönünü belirleyebilirsiniz. Veya Gremlin API için toplu yürütücü kitaplığını kullanarak.
Not
Edge nesnelerinin varsayılan olarak yönü vardır.
İlişki etiketleri
Açıklayıcı ilişki etiketlerini kullanmak, kenar çözümleme işlemlerinin verimliliğini artırabilir. Bu düzeni aşağıdaki yollarla uygulayabilirsiniz:
- Bir ilişkiyi etiketlemek için genel olmayan terimler kullanın.
- Kaynak köşenin etiketini hedef köşenin etiketiyle ilişki adıyla ilişkilendirin.
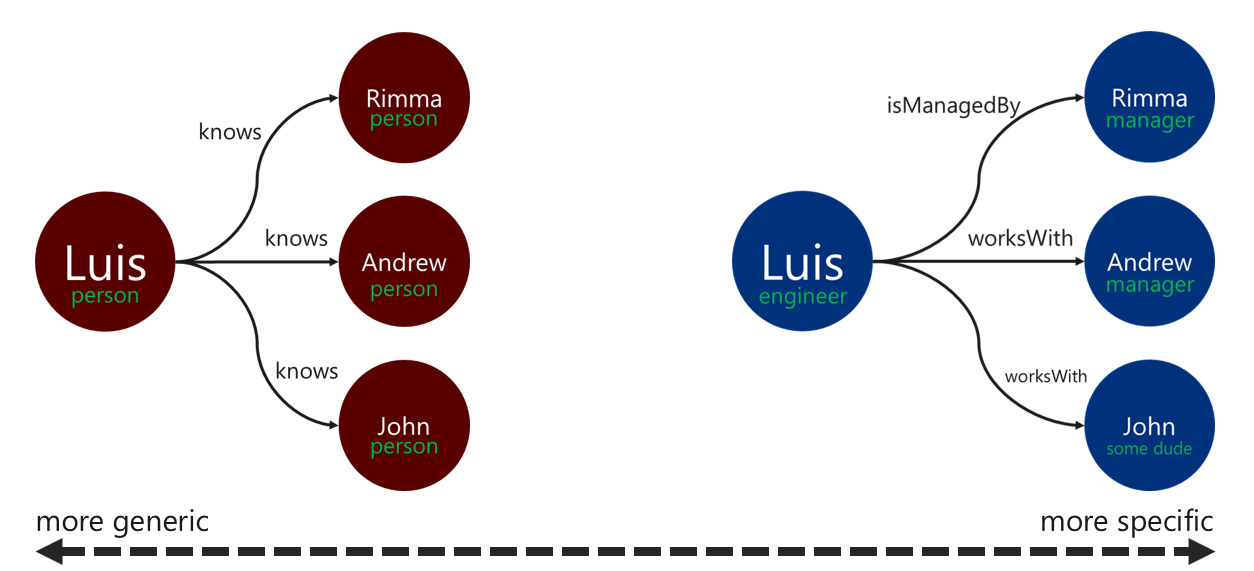
Çapraz geçişin kenarları filtrelemek için kullandığı etiket ne kadar belirgin olursa o kadar iyi olur. Bu kararın sorgu maliyeti üzerinde de önemli bir etkisi olabilir. executionProfile adımını kullanarak istediğiniz zaman sorgu maliyetini değerlendirebilirsiniz.
Sonraki adımlar
- Desteklenen Gremlin adımlarının listesine göz atın.
- Büyük ölçekli grafiklerle ilgilenmek için graf veritabanı bölümlemeyi öğrenin.
- Yürütme profili adımını kullanarak Gremlin sorgularınızı değerlendirin.
- Üçüncü taraf grafik tasarım veri modeli.