Azure Cosmos DB'de dizine genel bakış
ŞUNLAR IÇIN GEÇERLIDIR:![]() Nosql
Nosql![]() MongoDB
MongoDB![]() Cassandra
Cassandra![]() Gremlin
Gremlin![]() Tablo
Tablo
Azure Cosmos DB, şema veya dizin yönetimiyle uğraşmak zorunda kalmadan uygulamanızda yineleme yapmanızı sağlayan şemadan bağımsız bir veritabanıdır. Varsayılan olarak, Azure Cosmos DB herhangi bir şema tanımlamak veya ikincil dizinleri yapılandırmak zorunda kalmadan kapsayıcınızdaki tüm öğeler için her özelliği otomatik olarak dizinler.
Bu makalenin amacı Azure Cosmos DB'nin verileri nasıl dizine aldığını ve sorgu performansını geliştirmek için dizinleri nasıl kullandığını açıklamaktır. Dizin oluşturma ilkelerini özelleştirmeyi keşfetmeden önce bu bölümün üzerinden geçmeniz önerilir.
Öğelerden ağaçlara
Bir öğe kapsayıcıda her depolandığında, içeriği JSON belgesi olarak yansıtılır ve ardından ağaç gösterimine dönüştürülür. Bu dönüştürme, söz konusu öğenin her özelliğinin bir ağaçtaki düğüm olarak temsil edilir anlamına gelir. Öğenin tüm birinci düzey özelliklerinin üst öğesi olarak bir sahte kök düğüm oluşturulur. Yaprak düğümler, bir öğe tarafından taşınan gerçek skaler değerleri içerir.
Örneğin, şu öğeyi göz önünde bulundurun:
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
Bu ağaç örnek JSON öğesini temsil eder:
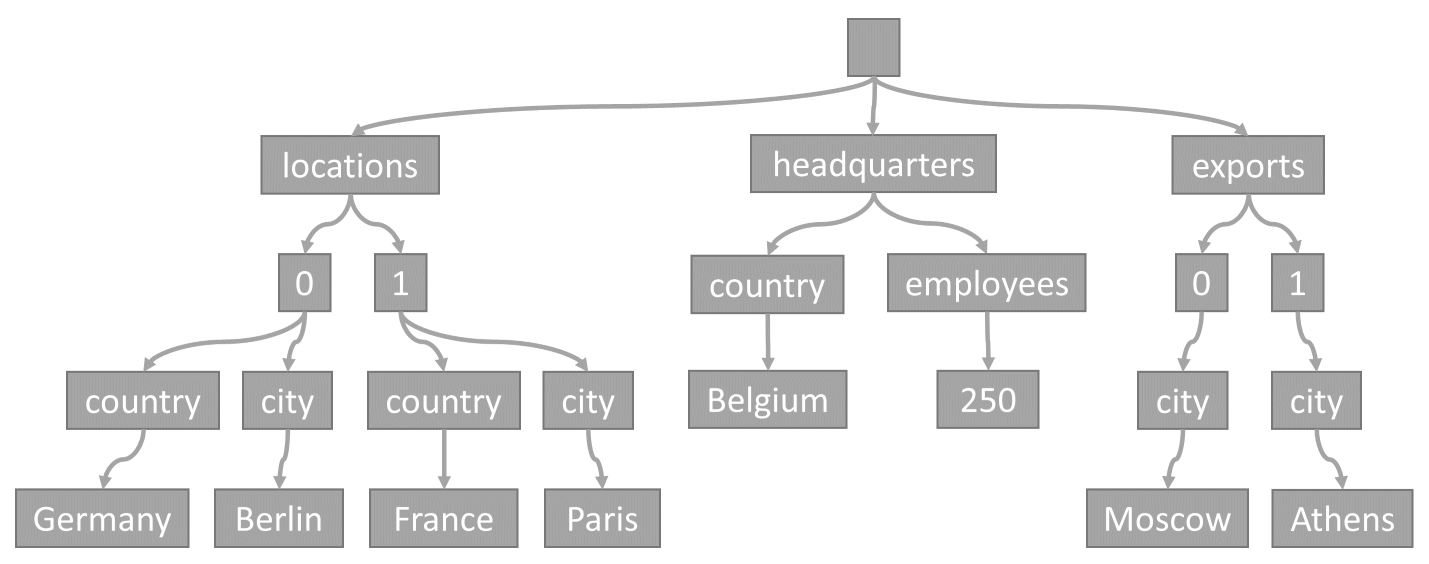
Dizilerin ağaçta nasıl kodlandığına dikkat edin: Bir dizideki her girdi, dizi içindeki bu girdinin diziniyle etiketlenmiş bir ara düğüm alır (0, 1 vb.).
Ağaçlardan özellik yollarına
Azure Cosmos DB'nin öğeleri ağaçlara dönüştürmesinin nedeni, sistemin bu ağaçlar içindeki yollarını kullanarak özelliklere başvurmasına izin vermesidir. Bir özelliğin yolunu almak için kök düğümden bu özelliğe ağaçtan geçiş yapabilir ve geçirilen her düğümün etiketlerini birleştirebiliriz.
Aşağıda, daha önce açıklanan örnek öğeden her özelliğin yolları verilmiştir:
/locations/0/country: "Almanya"/locations/0/city: "Berlin"/locations/1/country: "Fransa"/locations/1/city: "Paris"/headquarters/country: "Belçika"/headquarters/employees: 250/exports/0/city: "Moskova"/exports/1/city: "Atina"
Azure Cosmos DB, bir öğe yazıldığında her özelliğin yolunu ve buna karşılık gelen değerini etkili bir şekilde dizinler.
Dizin türleri
Azure Cosmos DB şu anda üç dizin türünü desteklemektedir. Dizin oluşturma ilkesini tanımlarken bu dizin türlerini yapılandırabilirsiniz.
Aralık Dizini
Aralık dizinleri sıralı ağaç benzeri bir yapıyı temel alır. Aralık dizin türü aşağıdakiler için kullanılır:
Eşitlik sorguları:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")Dizi öğesinde eşitlik eşleşmesi
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")Aralık sorguları:
SELECT * FROM container c WHERE c.property > 'value'Not
(, ,
<,>=,<=!=için çalışır>)Bir özelliğin varlığı denetleniyor:
SELECT * FROM c WHERE IS_DEFINED(c.property)Dize sistemi işlevleri:
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")ORDER BYSorgu:SELECT * FROM container c ORDER BY c.propertyJOINSorgu:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
Aralık dizinleri skaler değerlerde (dize veya sayı) kullanılabilir. Yeni oluşturulan kapsayıcıların varsayılan dizin oluşturma ilkesi tüm dizeler veya sayılar için aralık dizinlerini zorunlu tutar. Aralık dizinlerini yapılandırmayı öğrenmek için bkz . Aralık dizin oluşturma ilkesi örnekleri
Not
ORDER BY Tek bir özelliğe göre sipariş veren bir yan tümce her zaman bir aralık dizinine ihtiyaç duyar ve başvurduğunu yolun bir dizini yoksa başarısız olur. Benzer şekilde, birden çok özelliğe göre sıralanan bir ORDER BY sorgu için her zaman bileşik dizin gerekir.
Uzamsal dizin
Uzamsal dizinler noktalar, çizgiler, çokgenler ve çok kutuplu gibi jeo-uzamsal nesneler üzerinde verimli sorgular sağlar. Bu sorgular ST_DISTANCE, ST_WITHIN ST_INTERSECTS anahtar sözcükleri kullanır. Uzamsal dizin türünü kullanan bazı örnekler aşağıda verilmiştir:
Jeo-uzamsal uzaklık sorguları:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40Sorgular içinde jeo-uzamsal:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })Jeo-uzamsal kesişen sorgular:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
Uzamsal dizinler doğru biçimlendirilmiş GeoJSON nesnelerinde kullanılabilir. Points, LineStrings, Polygons ve MultiPolygons şu anda desteklenmektedir. Uzamsal dizinleri yapılandırmayı öğrenmek için bkz . Uzamsal dizin oluşturma ilkesi örnekleri
Bileşik dizinler
Bileşik dizinler, birden çok alanda işlem gerçekleştirirken verimliliği artırır. Bileşik dizin türü aşağıdakiler için kullanılır:
ORDER BYbirden çok özellik üzerinde sorgular:SELECT * FROM container c ORDER BY c.property1, c.property2ve
ORDER BYfiltreli sorgular. Bu sorgular, filtre özelliği yan tümcesineORDER BYeklenirse bileşik dizin kullanabilir.SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2En az bir özelliğin eşitlik filtresi olduğu iki veya daha fazla özellikte filtre içeren sorgular
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
Bir filtre koşulu dizin türünden birini kullandığı sürece, sorgu altyapısı geri kalanını taramadan önce bunu değerlendirir. Örneğin, gibi bir SQL sorgunuz varsa SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu")
Yukarıdaki sorgu ilk olarak dizini kullanarak firstName = "Andrew" girişini filtreleyecektir. Ardından, CONTAINS filtre koşulunu değerlendirmek için firstName = "Andrew" girdilerinin tümünü sonraki bir işlem hattından geçirir.
CONTAINS gibi bir tam tarama gerçekleştiren işlevleri kullanırken sorguları hızlandırabilir ve tam kapsayıcı taramalarından kaçınabilirsiniz. Bu sorguları hızlandırmak için dizini kullanan daha fazla filtre koşulu ekleyebilirsiniz. Filtre yan tümcelerinin sırası önemli değildir. Sorgu altyapısı hangi koşulun daha seçici olduğunu anlayıp sorguyu buna göre çalıştırır.
Bileşik dizinleri yapılandırmayı öğrenmek için bkz . Bileşik dizin oluşturma ilkesi örnekleri
Dizin kullanımı
Sorgu altyapısının sorgu filtrelerini en verimliden en az verimliye doğru sıralanmış olarak değerlendirebileceği beş yöntem vardır:
- Dizin arama
- Hassas dizin taraması
- Genişletilmiş dizin taraması
- Tam dizin taraması
- Tam tarama
Özellik yollarını dizine eklediğinizde, sorgu altyapısı dizini otomatik olarak mümkün olduğunca verimli bir şekilde kullanır. Yeni özellik yollarını dizine eklemenin yanı sıra sorguların dizini kullanma biçimini iyileştirmek için herhangi bir yapılandırma yapmanız gerekmez. Sorgunun RU ücreti, hem dizin kullanımından gelen RU ücretinin hem de öğelerin yüklenmesinden kaynaklanan RU ücretinin bir bileşimidir.
Azure Cosmos DB'de dizinlerin farklı kullanım yollarını özetleyen bir tablo aşağıdadır:
| Dizin arama türü | Description | Yaygın Örnekler | Dizin kullanımından RU ücreti | İşlemsel veri deposundan öğe yüklemesinden kaynaklanan RU ücretleri |
|---|---|---|---|---|
| Dizin arama | Yalnızca gerekli dizine alınan değerleri okuyun ve işlem veri deposundan yalnızca eşleşen öğeleri yükleyin | Eşitlik filtreleri, IN | Eşitlik filtresi başına sabit | Sorgu sonuçlarındaki öğe sayısına göre artışlar |
| Hassas dizin taraması | Dizine alınan değerlerin ikili araması ve yalnızca işlem veri deposundan eşleşen öğeleri yükleme | Aralık karşılaştırmaları (>, <, <=veya >=), StartsWith | Dizin arama ile karşılaştırılabilir, dizine alınan özelliklerin kardinalitesine göre biraz artar | Sorgu sonuçlarındaki öğe sayısına göre artışlar |
| Genişletilmiş dizin taraması | Dizine alınan değerler için iyileştirilmiş arama (ancak ikili aramadan daha az verimli) ve işlem veri deposundan yalnızca eşleşen öğeleri yükleme | StartsWith (büyük/küçük harfe duyarlı değil), StringEquals (büyük/küçük harfe duyarlı değil) | Dizine alınan özelliklerin kardinalitesine göre biraz artar | Sorgu sonuçlarındaki öğe sayısına göre artışlar |
| Tam dizin taraması | Ayrı dizinlenmiş değer kümesini okuma ve yalnızca işlem veri deposundan eşleşen öğeleri yükleme | Contains, EndsWith, RegexMatch, LIKE | Dizine alınan özelliklerin kardinalitesine göre doğrusal olarak artırır | Sorgu sonuçlarındaki öğe sayısına göre artışlar |
| Tam tarama | İşlemsel veri deposundaki tüm öğeleri yükleme | Üst, Alt | Yok | Kapsayıcıdaki öğe sayısına göre artışlar |
Sorgu yazarken, dizini mümkün olduğunca verimli bir şekilde kullanan filtre koşullarını kullanmanız gerekir. Örneğin, StartsWithContains veya kullanım örneğiniz için işe yarasaydı, tam dizin taraması yerine kesin bir dizin taraması yaptığı için StartsWith bunu tercih etmelisiniz.
Dizin kullanım ayrıntıları
Bu bölümde sorguların dizinleri nasıl kullandığı hakkında daha fazla ayrıntı ele alınmaktadır. Azure Cosmos DB'yi kullanmaya başlamayı öğrenmek için bu ayrıntı düzeyi gerekli değildir, ancak meraklı kullanıcılar için ayrıntılı olarak belgelenmiştir. Bu belgenin önceki bölümlerinde paylaşılan örnek öğeye başvuruyoruz:
Örnek öğeler:
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
Azure Cosmos DB ters dizin kullanır. Dizin, her JSON yolunu bu değeri içeren öğe kümesine eşleyerek çalışır. Öğe kimliği eşlemesi, kapsayıcı için birçok farklı dizin sayfasında temsil edilir. Aşağıda, iki örnek öğe içeren bir kapsayıcının ters çevrilmiş dizininin örnek diyagramı verilmiştir:
| Yol | Değer | Öğe kimliklerinin listesi |
|---|---|---|
| /locations/0/country | Almanya | 1 |
| /locations/0/country | İrlanda | 2 |
| /locations/0/city | Berlin | 1 |
| /locations/0/city | Dublin | 2 |
| /locations/1/country | Fransa | 1 |
| /locations/1/city | Paris | 1 |
| /genel merkez/ülke | Belçika | 1, 2 |
| /headquarters/employees | 200 | 2 |
| /headquarters/employees | 250 | 1 |
Ters çevrilmiş dizinin iki önemli özniteliği vardır:
- Belirli bir yol için değerler artan düzende sıralanır. Bu nedenle, sorgu altyapısı dizinden kolayca hizmet
ORDER BYverebilir. - Belirli bir yol için sorgu altyapısı, sonuçların bulunduğu dizin sayfalarını tanımlamak için farklı olası değerler kümesini tarar.
Sorgu altyapısı ters dizini dört farklı şekilde kullanabilir:
Dizin arama
Şu sorguyu inceleyin:
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'`
Sorgu koşulu (herhangi bir konumda ülke/bölge olarak "Fransa" bulunan öğelere göre filtreleme), bu diyagramda vurgulanan yol ile eşleşir:
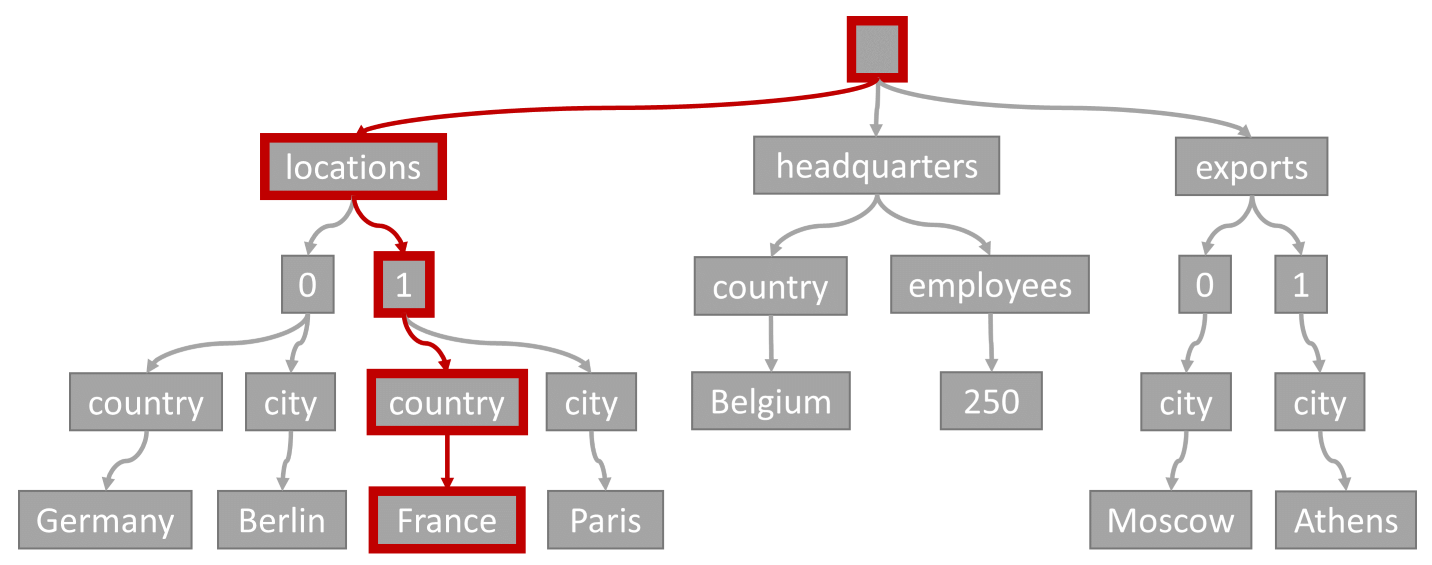
Bu sorgunun bir eşitlik filtresi olduğundan, bu ağaçtan geçtikten sonra sorgu sonuçlarını içeren dizin sayfalarını hızla tanımlayabiliriz. Bu durumda, sorgu altyapısı Öğe 1'i içeren dizin sayfalarını okur. Dizin arama, dizini kullanmanın en verimli yoludur. Dizin aramasıyla yalnızca gerekli dizin sayfalarını okur ve yalnızca sorgu sonuçlarındaki öğeleri yükleriz. Bu nedenle, toplam veri hacmi ne olursa olsun, dizin arama süresi ve dizin aramasından gelen RU ücreti inanılmaz derecede düşüktür.
Hassas dizin taraması
Şu sorguyu inceleyin:
SELECT *
FROM company
WHERE company.headquarters.employees > 200
Sorgu koşulu (200'den fazla çalışanın bulunduğu öğelere göre filtreleme), yolun tam dizin taramasıyla headquarters/employees değerlendirilebilir. Kesin bir dizin taraması yaparken sorgu altyapısı, yolun değerinin konumunu 200 bulmak için farklı olası değerler kümesinin ikili aramasını headquarters/employees yaparak başlar. Her yol için değerler artan düzende sıralandığından, sorgu altyapısının ikili arama yapması kolaydır. Sorgu altyapısı değerini 200buldukta kalan tüm dizin sayfalarını okumaya başlar (artan yönde devam eder).
Sorgu altyapısı gereksiz dizin sayfalarını taramaktan kaçınmak için ikili arama gerçekleştirebildiğinden, kesin dizin taramaları dizin arama işlemleri için benzer gecikme süresine ve RU ücretlerine sahip olma eğilimindedir.
Genişletilmiş dizin taraması
Şu sorguyu inceleyin:
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
Sorgu koşulu (büyük/küçük harfe duyarlı olmayan "United" ile başlayan bir konumda genel merkezi olan öğelere göre filtreleme), yolun genişletilmiş dizin taramasıyla headquarters/country değerlendirilebilir. Genişletilmiş dizin taraması yapılan işlemler, her dizin sayfasını tarama gereksinimini önlemeye yardımcı olabilecek iyileştirmelere sahiptir, ancak kesin bir dizin taramasının ikili aramasından biraz daha pahalıdır.
Örneğin, büyük/küçük harfe duyarsız StartsWithdeğerini değerlendirirken sorgu altyapısı, büyük ve küçük harf değerlerinin farklı olası bileşimleri için dizini denetler. Bu iyileştirme, sorgu altyapısının dizin sayfalarının çoğunu okumasını önlemesini sağlar. Farklı sistem işlevleri, her dizin sayfasının okunmasını önlemek için kullanabileceği farklı iyileştirmelere sahiptir, bu nedenle genişletilmiş dizin taraması olarak geniş bir kategoriye ayrılmıştır.
Tam dizin taraması
Şu sorguyu inceleyin:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Sorgu koşulu (merkezi "United" içeren bir konumda bulunan öğelere göre filtreleme), yolun dizin taramasıyla headquarters/country değerlendirilebilir. Tam dizin taramasının aksine, tam dizin taraması sonuçların bulunduğu dizin sayfalarını tanımlamak için her zaman farklı olası değerler kümesini tarar. Bu durumda, Contains dizinde çalıştırılır. Dizin taramaları için dizin arama süresi ve RU ücreti, yolun kardinalitesi arttıkça artar. Başka bir deyişle, sorgu altyapısının taraması gereken olası benzersiz değerler ne kadar fazla olursa, tam dizin taraması sırasında gecikme süresi ve RU ücreti de o kadar yüksek olur.
Örneğin, iki özelliği göz önünde bulundurun: town ve country. Şehrin kardinalitesi 5.000 ve kardinalitesi country 200'dür. Aşağıda, her biri özelliğinde tam dizin taraması yapmış bir Contains system işlevine sahip iki örnek sorgu verilmiştir town . şehrin kardinalitesi değerinden yüksek olduğundan ilk sorgu ikinci sorgudan countrydaha fazla RU kullanır.
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
Tam tarama
Bazı durumlarda, sorgu altyapısı dizini kullanarak bir sorgu filtresini değerlendiremeyebilir. Bu durumda sorgu filtresinin değerlendirilmesi için sorgu altyapısının işlem deposundaki tüm öğeleri yüklemesi gerekir. Tam taramalar dizini kullanmaz ve toplam veri boyutuyla doğrusal olarak artan bir RU ücretine sahiptir. Neyse ki, tam tarama gerektiren işlemler nadirdir.
Karmaşık filtre ifadelerine sahip sorgular
Önceki örneklerde yalnızca basit filtre ifadelerine sahip sorguları (örneğin, yalnızca tek bir eşitliğe veya aralık filtresine sahip sorgular) ele almıştık. Gerçekte, çoğu sorguda çok daha karmaşık filtre ifadeleri vardır.
Şu sorguyu inceleyin:
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
Bu sorguyu yürütmek için sorgu altyapısının üzerinde headquarters/employees bir dizin araması ve üzerinde headquarters/countrytam dizin taraması yapması gerekir. Sorgu altyapısı, sorgu filtresi ifadesini mümkün olduğunca verimli bir şekilde değerlendirmek için kullandığı iç buluşsal yöntemlere sahiptir. Bu durumda sorgu altyapısı, önce dizin aramasını yaparak gereksiz dizin sayfalarını okuma gereksinimini ortadan kaldıracak. Örneğin, eşitlik filtresiyle yalnızca 50 öğe eşleştiyse, sorgu altyapısının yalnızca bu 50 öğeyi içeren dizin sayfalarında değerlendirmesi Contains gerekir. Kapsayıcının tamamının tam dizin taraması gerekmez.
Skaler toplama işlevleri için dizin kullanımı
Toplama işlevlerine sahip sorguların kullanılabilmesi için yalnızca dizine bağlı olması gerekir.
Bazı durumlarda dizin hatalı pozitif sonuçlar döndürebilir. Örneğin, dizinde değerlendirme Contains yaparken, dizindeki eşleşmelerin sayısı sorgu sonuçlarının sayısını aşabilir. Sorgu altyapısı tüm dizin eşleşmelerini yükler, yüklenen öğelerdeki filtreyi değerlendirir ve yalnızca doğru sonuçları döndürür.
Çoğu sorguda hatalı pozitif dizin eşleşmelerinin yüklenmesi dizin kullanımı üzerinde belirgin bir etkiye sahip değildir.
Örneğin, aşağıdaki sorguyu göz önüne alın:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Contains Sistem işlevi bazı hatalı pozitif eşleşmeler döndürebilir, bu nedenle sorgu altyapısının yüklenen her öğenin filtre ifadesiyle eşleşip eşleşmediğini doğrulaması gerekir. Bu örnekte sorgu altyapısının yalnızca fazladan birkaç öğe yüklemesi gerekebilir, bu nedenle dizin kullanımı ve RU ücreti üzerindeki etkisi çok azdır.
Ancak, toplama işlevlerine sahip sorguların kullanabilmesi için yalnızca dizine bağlı olması gerekir. Örneğin, toplama ile Count aşağıdaki sorguyu göz önünde bulundurun:
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
İlk örnekte olduğu gibi, Contains sistem işlevi bazı hatalı pozitif eşleşmeler döndürebilir. Ancak sorgudan SELECT * farklı olarak, Count sorgu yüklenen öğelerdeki filtre ifadesini değerlendirerek tüm dizin eşleşmelerini doğrulayamaz. Sorgunun Count yalnızca dizine bağlı olması gerektiğinden, filtre ifadesinin hatalı pozitif eşleşmeler döndürme olasılığı varsa, sorgu altyapısı tam taramaya başvurur.
Aşağıdaki toplama işlevlerine sahip sorguların yalnızca dizine bağlı olması gerektiğinden, bazı sistem işlevlerinin değerlendirilmesi tam tarama gerektirir.
Sonraki adımlar
Dizin oluşturma hakkında daha fazla bilgiyi aşağıdaki makalelerde bulabilirsiniz: