Azure Cosmos DB'de veri modelleme
ŞUNUN IÇIN GEÇERLIDIR: ![]() NoSQL
NoSQL
Azure Cosmos DB gibi şemasız veritabanları yapılandırılmamış ve yarı yapılandırılmış verileri depolamayı ve sorgulamayı çok kolaylaştırırken, performans, ölçeklenebilirlik ve en düşük maliyet açısından hizmetten en iyi şekilde yararlanmak için veri modelinizi düşünmek için biraz zaman harcamanız gerekir.
Veriler nasıl depolanacak? Uygulamanız verileri nasıl alacak ve sorgulayacak? Uygulamanız yoğun okuma veya yazma yoğun mu?
Bu makaleyi okuduktan sonra aşağıdaki soruları yanıtlayabileceksiniz:
- Veri modelleme nedir ve neden önemsemeliyim?
- Azure Cosmos DB'deki verileri modellemenin ilişkisel veritabanından farkı nedir?
- İlişkisel olmayan bir veritabanında veri ilişkilerini ifade Nasıl yaparım??
- Verileri ne zaman eklerim ve verilere ne zaman bağlanırım?
JSON'daki sayılar
Azure Cosmos DB belgeleri JSON'a kaydeder. Bu da sayıları json içinde depolamadan önce dizelere dönüştürmenin gerekli olup olmadığını dikkatle belirlemek gerektiği anlamına gelir. IEEE 754 binary64'e göre çift duyarlıklı sayıların sınırlarının dışında olma olasılığı varsa, tüm sayılar ideal olarak içine Stringdönüştürülmelidir. Json belirtimi, genel olarak bu sınırın dışındaki sayıları kullanmanın, birlikte çalışabilirlik sorunları nedeniyle JSON'da kötü bir uygulama olmasının nedenlerini ortaya çıkarır. Bu endişeler özellikle bölüm anahtarı sütunu için geçerlidir, çünkü sabittir ve daha sonra değiştirmek için veri geçişi gerektirir.
Veri ekleme
Azure Cosmos DB'de verileri modellemeye başladığınızda varlıklarınızı JSON belgeleri olarak temsil edilen bağımsız öğeler olarak işlemeyi deneyin.
Karşılaştırma için öncelikle ilişkisel veritabanındaki verileri nasıl modelleyebileceğimizi görelim. Aşağıdaki örnekte, bir kişinin ilişkisel veritabanında nasıl depolanabileceği gösterilmektedir.
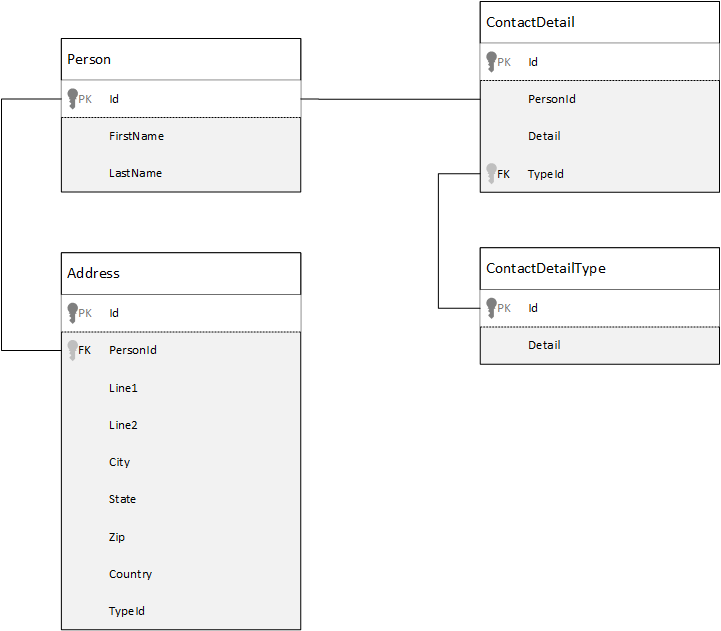
strateji, ilişkisel veritabanlarıyla çalışırken tüm verilerinizi normalleştirmektir. Verilerinizi normalleştirmek için genellikle kişi gibi bir varlığı alıp ayrı bileşenlere ayırmanız gerekir. Yukarıdaki örnekte, bir kişinin birden çok kişi ayrıntı kaydı ve birden çok adres kaydı olabilir. Kişi ayrıntıları, tür gibi ortak alanlar daha fazla ayıklanarak daha ayrıntılı olarak ayrılabilir. Aynı durum adres için de geçerlidir; her kayıt Ev veya İş türünde olabilir.
Verileri normalleştirirken yol gösteren şirket, her kayıtta yedekli verilerin depolanmasını önlemek ve verilere başvurmaktır. Bu örnekte, bir kişiyi tüm kişi ayrıntıları ve adresleriyle okumak için, çalışma zamanında verilerinizi etkili bir şekilde oluşturmak (veya normalleştirmesini azaltmak) için JOINS kullanmanız gerekir.
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
Tek bir kişinin kişi ayrıntılarını ve adreslerini güncelleştirmek için birçok ayrı tabloda yazma işlemleri gereklidir.
Şimdi Azure Cosmos DB'de kendi içinde bulunan bir varlıkla aynı verileri nasıl modellediğimize göz atalım.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
Yukarıdaki yaklaşımı kullanarak, kişi ayrıntıları ve adresleri gibi bu kişiyle ilgili tüm bilgileri tek bir JSON belgesine ekleyerek kişi kaydını normal durumdan çıkardık. Ayrıca, sabit bir şemayla sınırlı kalmadığımız için, tamamen farklı şekillerin iletişim ayrıntılarına sahip olma gibi işlemler yapma esnekliğine sahibiz.
Veritabanından tam bir kişi kaydı almak artık tek bir kapsayıcıda ve tek bir öğe için tek bir okuma işlemidir . Kişi kaydının kişi ayrıntılarını ve adreslerini güncelleştirmek de tek bir öğeye karşı tek bir yazma işlemidir .
Verileri normalleştirilmişlikten çıkararak uygulamanızın yaygın işlemleri tamamlamak için daha az sorgu ve güncelleştirme gerçekleştirmesi gerekebilir.
Ekleme zamanları
Genel olarak, aşağıdaki durumlarda eklenmiş veri modellerini kullanın:
- Varlıklar arasında kapsanan ilişkiler vardır.
- Varlıklar arasında bire birkaç ilişki vardır.
- Seyrek değişen ekli veriler vardır.
- Bağlı olmadan büyümeyen ekli veriler vardır.
- Birlikte sık sık sorgulanan ekli veriler vardır.
Not
Normal olmayan veri modelleri genellikle daha iyi okuma performansı sağlar.
Ekleme yapılmadığında
Azure Cosmos DB'de temel kural, her şeyi normal dışı bırakma ve tüm verileri tek bir öğeye ekleme olsa da, bu durum kaçınılması gereken bazı durumlara yol açabilir.
Bu JSON parçacığını alın.
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
Tipik bir blogu veya CMS sistemini modellediğimizde, ekli açıklamaları olan bir gönderi varlığı böyle görünebilir. Bu örnekteki sorun, açıklamalar dizisinin ilişkisiz olması, yani tek bir gönderinin sahip olabileceği açıklama sayısı için (pratik) bir sınır olmamasıdır. Öğenin boyutu sonsuz büyük olabileceğinden bu bir sorun haline gelebilir, bu nedenle kaçınmanız gereken bir tasarımdır.
Öğenin boyutu büyüdükçe, verileri kablo üzerinden iletme ve öğeyi okuma ve güncelleştirme özelliği arttıkça büyük ölçekte etkilenecektir.
Bu durumda, aşağıdaki veri modelini göz önünde bulundurmak daha iyi olacaktır.
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
Bu model, gönderi tanımlayıcısını içeren bir özelliğe sahip her açıklama için bir belgeye sahiptir. Bu, gönderilerin herhangi bir sayıda yorum içermesine olanak tanır ve verimli bir şekilde büyüyebilir. En son açıklamalardan daha fazlasını görmek isteyen kullanıcılar bu kapsayıcıyı postId değerini geçirerek sorgular ve bu da açıklamalar kapsayıcısının bölüm anahtarı olmalıdır.
Veri eklemenin iyi bir fikir olmadığı bir diğer durum da, katıştırılmış verilerin öğeler arasında sık sık kullanılması ve sık sık değişmesidir.
Bu JSON parçacığını alın.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
Bu, bir kişinin hisse senedi portföyünü temsil edebilir. Hisse senedi bilgilerini her portföy belgesine eklemeyi seçtik. Hisse senedi alım satım uygulaması gibi ilgili verilerin sıklıkla değiştiği bir ortamda, sık değişen verileri eklemek, her hisse senedi alım satımında her portföy belgesini sürekli güncelleştirdiğiniz anlamına gelir.
Hisse senedi zbzb tek bir günde yüzlerce kez takas edilebilir ve binlerce kullanıcı portföyünde zbzb olabilir. Yukarıdakine benzer bir veri modeliyle, iyi ölçeklendirilmeyecek bir sisteme yol açan binlerce portföy belgesini her gün birçok kez güncelleştirmemiz gerekir.
Başvuru verileri
Verileri eklemek birçok durumda düzgün çalışır, ancak verilerinizi normal durumdan çıkarmanın değerinden daha fazla soruna neden olacağı senaryolar vardır. Şimdi ne yapacağız?
varlıklar arasında ilişki oluşturabileceğiniz tek yer ilişkisel veritabanları değildir. Belge veritabanında, bir belgede diğer belgelerdeki verilerle ilgili bilgilere sahip olabilirsiniz. Azure Cosmos DB'deki ilişkisel veritabanı veya başka bir belge veritabanı için daha uygun sistemler oluşturmanızı önermeyiz, ancak basit ilişkiler uygundur ve yararlı olabilir.
Aşağıdaki JSON'da daha önceki bir hisse senedi portföyü örneğini kullanmayı seçtik ancak bu kez portföye eklemek yerine portföydeki hisse senedi öğesine başvuruyoruz. Bu şekilde, hisse senedi maddesi gün boyunca sık sık değiştiğinde, güncelleştirilmesi gereken tek belge tek hisse senedi belgesidir.
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
Ancak bu yaklaşımın hemen bir dezavantajı, uygulamanızın bir kişinin portföyünü görüntülerken tutulan her hisse senedi hakkında bilgi göstermesinin gerekli olmasıdır; bu durumda, her bir hisse senedi belgesinin bilgilerini yüklemek için veritabanına birden çok seyahat yapmanız gerekir. Burada gün boyunca sık gerçekleşen ancak bu sistemin performansı üzerinde daha az etkiye sahip olabilecek okuma işlemleri üzerinde tehlikeye atılan yazma işlemlerinin verimliliğini artırma kararı aldık.
Not
Normalleştirilmiş veri modelleri, sunucuya daha fazla gidiş dönüş gerektirebilir .
Yabancı anahtarlar ne olacak?
Şu anda kısıtlama, yabancı anahtar veya başka bir kavram olmadığından, belgelerde sahip olduğunuz belgeler arası ilişkiler etkili bir şekilde "zayıf bağlantılardır" ve veritabanı tarafından doğrulanamaz. Belgenin başvurduğunu verilerin gerçekten var olduğundan emin olmak istiyorsanız, bunu uygulamanızda veya Azure Cosmos DB'de sunucu tarafı tetikleyicileri veya saklı yordamları kullanarak yapmanız gerekir.
Ne zaman başvurulacak?
Genel olarak, aşağıdaki durumlarda normalleştirilmiş veri modellerini kullanın:
- Bire çok ilişkileri temsil eder.
- Çoka çok ilişkilerini temsil eder.
- İlgili veriler sık sık değişir.
- Başvuruda bulunılan veriler ilişkisiz olabilir.
Not
Normalleştirme genellikle daha iyi yazma performansı sağlar.
İlişkiyi nereye koymalıyım?
İlişkinin büyümesi, başvurunun depolandığı belgeyi belirlemeye yardımcı olur.
Aşağıdaki JSON'a baktığımızda yayımcılar ve kitaplar modellenmiştir.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over the world one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
Yayıncı başına kitap sayısı sınırlı büyüme ile küçükse, kitap başvurularını yayıncı belgesinin içinde depolamak yararlı olabilir. Ancak, yayımcı başına kitap sayısı ilişkisizse, bu veri modeli yukarıdaki örnek yayımcı belgesinde olduğu gibi değişken ve artan dizilere yol açabilir.
Bazı şeyleri biraz değiştirmek, yine de aynı verileri temsil eden ancak şimdi bu büyük değiştirilebilir koleksiyonları önleyen bir modele neden olur.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over the world one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
Yukarıdaki örnekte, yayımcı belgesine ilişkisiz koleksiyonu bıraktık. Bunun yerine, her kitap belgesinde yayıncıya bir başvurumuz var.
Çoka çok ilişkileri Nasıl yaparım? modellesiniz?
İlişkisel veritabanında çoka çok ilişkiler genellikle diğer tablolardaki kayıtları birleştiren birleştirme tablolarıyla modellenir.
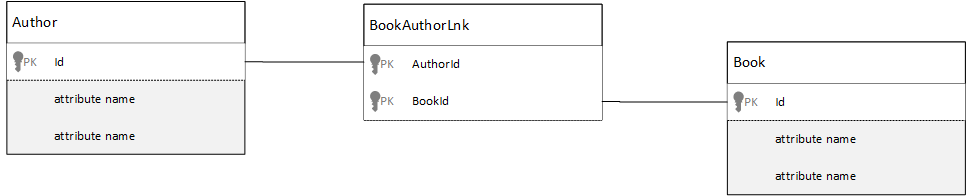
Belgeleri kullanarak aynı şeyi çoğaltmak ve aşağıdakine benzer bir veri modeli oluşturmak isteyebilirsiniz.
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over the world one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
Bu işe yarayacaktı. Ancak, bir yazarı kendi kitaplarıyla birlikte yüklemek veya yazarıyla birlikte bir kitap yüklemek için veritabanında her zaman en az iki ek sorgu gerekir. Birleştirme belgesine bir sorgu ve sonra birleştirilen gerçek belgeyi getirmek için başka bir sorgu.
Bu birleştirme yalnızca iki veri parçasını birbirine yapıştırıyorsa neden tamamen bırakmıyor? Aşağıdaki örneği inceleyin.
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
Şimdi, bir yazarım olsaydı, hangi kitapları yazdıklarını hemen biliyorum ve tersine bir kitap belgesi yüklemiş olsaydım yazarların kimliklerini bilirim. Bu, birleştirme tablosuna yönelik ara sorguyu kaydederek uygulamanızın yapması gereken sunucu gidiş dönüşlerinin sayısını azaltır.
Karma veri modelleri
Şimdi verileri ekleme (veya normalleştirmeyi kaldırma) ve verilere başvurmayı (veya normalleştirmeyi) inceledik. Her yaklaşımın başaşağı ve ödünleri vardır.
Her zaman ya da olmak zorunda değildir.
Uygulamanızın belirli kullanım düzenlerine ve iş yüklerine bağlı olarak, eklenen ve başvuruda bulunılan verileri karıştırmanın anlamlı olduğu ve daha az sunucu gidiş dönüşlü daha basit uygulama mantığına yol açabileceği ve iyi bir performans düzeyi sağlamaya devam ettiği durumlar olabilir.
Aşağıdaki JSON'yi göz önünde bulundurun.
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
Burada (çoğunlukla) diğer varlıklardaki verilerin üst düzey belgeye eklendiği ancak diğer verilere başvurulduğu eklenmiş modeli izledik.
Kitap belgesine bakarsanız, yazar dizisine baktığımızda birkaç ilginç alan görebiliriz. Bir yazar belgesine başvurmak için kullandığımız alan olan bir id alan var, normalleştirilmiş modelde standart uygulama, ancak ardından ve thumbnailUrldeğerlerine de sahibizname. "Bağlantı" kullanarak ilgili yazar belgesinden gereken ek bilgileri almak için uygulamaya takılıp id kalabilirdik, ancak uygulamamız yazarın adını ve her kitabın görüntülendiği bir küçük resim resmini görüntülediğinden, yazardan bazı verileri normal dışı bırakarak listedeki kitap başına sunucuya gidiş dönüş kaydedebiliriz.
Elbette, yazarın adı değiştiyse veya fotoğrafını güncelleştirmek isterse, şimdiye kadar yayımladığı her kitabı güncelleştirmemiz gerekirdi, ancak uygulamamız için yazarların adlarını sık sık değiştirmedikleri varsayımı temelinde, bu kabul edilebilir bir tasarım kararıdır.
Örnekte, okuma işleminde pahalı işlemlerden tasarruf etmek için önceden hesaplanmış toplama değerleri vardır. Örnekte, yazar belgesine eklenen verilerden bazıları çalışma zamanında hesaplanan verilerdir. Yeni bir kitap her yayımlandığında bir kitap belgesi oluşturulur ve countOfBooks alanı, belirli bir yazar için var olan kitap belgelerinin sayısına göre hesaplanan bir değere ayarlanır. Bu iyileştirme, okumaları iyileştirmek için yazma işlemlerinde hesaplama yapmayı göze alabildiğimiz okuma ağır sistemlerinde iyi olacaktır.
Azure Cosmos DB çok belgeli işlemleri desteklediğinden, önceden hesaplanmış alanlara sahip bir modele sahip olma özelliği mümkündür. Birçok NoSQL deposu belgeler arasında işlem yapamaz ve bu nedenle bu sınırlama nedeniyle "her zaman her şeyi ekleme" gibi tasarım kararlarını savunur. Azure Cosmos DB ile sunucu tarafı tetikleyicilerini veya bir ACID işlemi içinde kitap ekleyen ve yazarları güncelleştiren saklı yordamları kullanabilirsiniz. Artık verilerinizin tutarlı olduğundan emin olmak için her şeyi tek bir belgeye eklemek zorunda değilsiniz.
Farklı belge türleri arasında ayrım
Bazı senaryolarda, aynı koleksiyonda farklı belge türlerini karıştırmak isteyebilirsiniz; Bu durum genellikle birden çok ilgili belgenin aynı bölümde olmasını istediğinizde geçerli olur. Örneğin, hem kitapları hem de kitap incelemelerini aynı koleksiyona ekleyip ile bookIdbölümleyebilirsiniz. Böyle bir durumda, genellikle belgelerinizi ayırt etmek için türlerini tanımlayan bir alanla belgelerinize eklemek istersiniz.
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
},
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
Azure Synapse Link ve Azure Cosmos DB analiz deposu için veri modelleme
Azure Cosmos DB için Azure Synapse Bağlantısı, Azure Cosmos DB'deki işletimsel veriler üzerinde gerçek zamanlıya yakın analizler çalıştırmanızı sağlayan bulutta yerel bir hibrit işlem ve analiz işleme (HTAP) özelliğidir. Azure Synapse Link, Azure Cosmos DB ile Azure Synapse Analytics arasında sıkı bir sorunsuz tümleştirme oluşturur.
Bu tümleştirme, işlem iş yüklerinizi etkilemeden büyük ölçekli analize olanak tanıyan işlem verilerinizin sütunlu bir gösterimi olan Azure Cosmos DB analiz deposu aracılığıyla gerçekleşir. Bu analiz deposu, verileri kopyalamadan ve işlem iş yüklerinizin performansını etkilemeden büyük işletimsel veri kümelerindeki hızlı, uygun maliyetli sorgular için uygundur. Analiz deposu etkinleştirilmiş bir kapsayıcı oluşturduğunuzda veya mevcut bir kapsayıcıda analiz deposunu etkinleştirdiğinizde, tüm işlemsel eklemeler, güncelleştirmeler ve silmeler analiz deposuyla neredeyse gerçek zamanlı olarak eşitlenir; Değişiklik Akışı veya ETL işi gerekmez.
Azure Synapse Link ile artık Azure Synapse Analytics'ten Azure Cosmos DB kapsayıcılarınıza doğrudan bağlanabilir ve analiz deposuna İstek Birimleri (istek birimleri) maliyeti olmadan erişebilirsiniz. Azure Synapse Analytics şu anda Synapse Apache Spark ve sunucusuz SQL havuzları ile Azure Synapse Link'i desteklemektedir. Genel olarak dağıtılmış bir Azure Cosmos DB hesabınız varsa, bir kapsayıcı için analiz deposunu etkinleştirdikten sonra bu hesap tüm bölgelerde kullanılabilir.
Analiz deposu otomatik şema çıkarımı
Azure Cosmos DB işlem deposu satır odaklı yarı yapılandırılmış veriler olarak kabul edilse de analiz deposu sütunlu ve yapılandırılmış biçime sahiptir. Bu dönüştürme, analiz deposu için şema çıkarım kuralları kullanılarak müşteriler için otomatik olarak yapılır. Dönüştürme işleminde sınırlar vardır: en fazla iç içe düzey sayısı, en fazla özellik sayısı, desteklenmeyen veri türleri ve daha fazlası.
Not
Analiz deposu bağlamında aşağıdaki yapıları özellik olarak değerlendiririz:
- JSON "elements" veya "string-value pair separated by a
:". - ve
}ile{sınırlandırılmış JSON nesneleri. - ve
]ile[sınırlandırılmış JSON dizileri.
Aşağıdaki teknikleri kullanarak şema çıkarımı dönüştürmelerinin etkisini en aza indirip analiz yeteneklerinizi en üst düzeye çıkarabilirsiniz.
Normalleştirme
Azure Synapse Bağlantı ile T-SQL veya Spark SQL kullanarak kapsayıcılarınız arasında katılabileceğinizden normalleştirme anlamsız hale gelir. Normalleştirmenin beklenen avantajları şunlardır:
- Hem işlem hem de analiz deposunda daha küçük veri ayak izi.
- Daha küçük işlemler.
- Belge başına daha az özellik.
- Daha az iç içe düzeye sahip veri yapıları.
Bu son iki faktörün(daha az özellik ve daha az düzey) analitik sorgularınızın performansına yardımcı olduğunu, ancak verilerinizin parçalarının analiz deposunda temsil edilmeme olasılığını azalttığını unutmayın. Otomatik şema çıkarımı kuralları makalesinde açıklandığı gibi, analiz deposunda temsil edilen düzey ve özellik sayısının sınırları vardır.
Normalleştirme için bir diğer önemli faktör de, Azure Synapse'deki SQL sunucusuz havuzların en fazla 1000 sütun içeren sonuç kümelerini desteklemesi ve iç içe sütunların kullanıma sunulduktan sonra bu sınıra doğru sayılmasıdır. Başka bir deyişle hem analiz deposu hem de Synapse SQL sunucusuz havuzları 1000 özellik sınırına sahiptir.
Ancak normal dışıleştirme, Azure Cosmos DB için önemli bir veri modelleme tekniği olduğundan ne yapmalı? Bunun yanıtı, işlemsel ve analitik iş yükleriniz için doğru dengeyi bulmanız gerektiğidir.
Bölüm Anahtarı
Azure Cosmos DB bölüm anahtarınız (PK) analiz deposunda kullanılmaz. Artık analiz deposu özel bölümlemesini kullanarak istediğiniz PK'yi kullanarak analiz deposunun kopyalarını kullanabilirsiniz. Bu yalıtım nedeniyle işlem verileriniz için veri alımına ve nokta okumalarına odaklanan bir PK seçebilir, bölümler arası sorgular ise Azure Synapse Bağlantı ile yapılabilir. Bir örnek görelim:
Varsayımsal bir küresel IoT senaryosunda, device id tüm cihazlar benzer bir veri hacmine sahip olduğundan ve bu nedenle sık erişimli bölümleme sorununuz olmayacağından iyi bir PK'dir. Ancak "dünkü tüm veriler" veya "şehir başına toplamlar" gibi birden fazla cihazın verilerini analiz etmek istiyorsanız, bunlar bölümler arası sorgular olduğundan sorunlarla karşılaşabilirsiniz. Bu sorgular, çalıştırmak için istek birimlerinde aktarım hızınızın bir kısmını kullandığından işlem performansınızı etkileyebilir. Ancak Azure Synapse Bağlantı ile bu analiz sorgularını istek birimi maliyeti olmadan çalıştırabilirsiniz. Analiz deposu sütunlu biçimi analiz sorguları için iyileştirilmiştir ve Azure Synapse Link bu özelliği uygulayarak Azure Synapse Analytics çalışma zamanlarında harika performans sağlar.
Veri türleri ve özellik adları
Otomatik şema çıkarımı kuralları makalesinde desteklenen veri türleri listelenir. Desteklenmeyen veri türü analiz deposunda gösterimi engellese de desteklenen veri türleri Azure Synapse çalışma zamanları tarafından farklı şekilde işlenebilir. Örneklerden biri: ISO 8601 UTC standardına uyan DateTime dizeleri kullanılırken, Azure Synapse'deki Spark havuzları bu sütunları dize olarak, sql sunucusuz havuzları ise Azure Synapse bu sütunları varchar(8000) olarak temsil eder.
Diğer bir zorluk da tüm karakterlerin Azure Synapse Spark tarafından kabul edilmemesidir. Beyaz boşluklar kabul edilirken iki nokta üst üste, aksan ve virgül gibi karakterler kabul edilir. Belgenizde "Ad, Soyadı" adlı bir özellik olduğunu varsayalım. Bu özellik analiz deposunda temsil edilir ve Synapse SQL sunucusuz havuzu bunu sorunsuz bir şekilde okuyabilir. Ancak analiz deposunda olduğundan, Azure Synapse Spark diğer tüm özellikler de dahil olmak üzere analiz deposundan veri okuyamaz. Günün sonunda, adlarındaki desteklenmeyen karakterleri kullanan bir özelliğiniz olduğunda Azure Synapse Spark'ı kullanamazsınız.
Veri düzleştirme
Azure Cosmos DB verilerinizin kök düzeyindeki tüm özellikler analiz deposunda sütun olarak, belge veri modelinizin daha derin düzeylerinde olan diğer her şey de iç içe yapılarda JSON olarak temsil edilir. İç içe yerleştirilmiş yapılar, verileri yapılandırılmış biçimde düzleştirmeye yönelik Azure Synapse çalışma zamanlarından ek işleme talep eder. Bu, büyük veri senaryolarında zor olabilir.
Aşağıdaki belgede analiz deposunda id yalnızca iki sütun bulunur ve contactDetails. ve diğer tüm verilerin emailphoneayrı ayrı okunmasını sağlamak için SQL işlevleri aracılığıyla ek işlem gerektirir.
{
"id": "1",
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555"}
]
}
Aşağıdaki belgede analiz deposunda , ve phoneolmak üzere idemailüç sütun bulunur. Tüm verilere doğrudan sütun olarak erişilebilir.
{
"id": "1",
"email": "thomas@andersen.com",
"phone": "+1 555 555-5555"
}
Veri katmanlama
Azure Synapse Bağlantısı, maliyetleri aşağıdaki açılardan azaltmanıza olanak tanır:
- İşlem veritabanınızda çalışan daha az sorgu.
- Veri alımı ve nokta okumaları için iyileştirilmiş bir PK, veri ayak izini, sık erişimli bölüm senaryolarını ve bölüm bölmelerini azaltır.
- Analitik yaşam süresi (attl) işlemsel yaşam süresinden (tttl) bağımsız olduğundan veri katmanlama. İşlem verilerinizi birkaç gün, hafta, ay boyunca işlem deposunda tutabilir ve verileri yıllar boyunca veya sonsuza kadar analiz deposunda tutabilirsiniz. Analitik depo sütunlu biçimi, %50'den %90'a kadar doğal bir veri sıkıştırması getirir. Gb başına maliyeti ise işlemsel mağaza gerçek fiyatının yaklaşık %10'unu oluşturur. Geçerli yedekleme sınırlamaları hakkında daha fazla bilgi için bkz . analiz deposuna genel bakış.
- Ortamınızda çalışan ETL işi yok, yani bunlar için istek birimleri sağlamanız gerekmez.
Denetimli yedeklilik
Bu, bir veri modelinin zaten mevcut olduğu ve değiştirilebildiği durumlar için harika bir alternatiftir. Ayrıca iç içe düzeylerin sınırı veya maksimum özellik sayısı gibi otomatik şema çıkarımı kuralları nedeniyle mevcut veri modeli analiz deposuna uygun değildir. Sizin durumunuz buysa, verilerinizi başka bir kapsayıcıya çoğaltmak için Azure Cosmos DB Değişiklik Akışı'nı kullanabilir ve Azure Synapse Bağlantı dostu veri modeli için gerekli dönüştürmeleri uygulayabilirsiniz. Bir örnek görelim:
Senaryo
Müşteri ve ürün ayrıntıları dahil olmak üzere satır içi siparişleri depolamak için kapsayıcı CustomersOrdersAndItems kullanılır: fatura adresi, teslimat adresi, teslimat yöntemi, teslimat durumu, ürün fiyatı vb. Yalnızca ilk 1000 özellik temsil edilir ve analiz deposuna önemli bilgiler eklenmediğinden Bağlantı kullanımı Azure Synapse engellenir. Kapsayıcıda kayıt FI'leri var, uygulamayı değiştirmek ve verileri yeniden modellemek mümkün değildir.
Sorunun bir diğer perspektifi de büyük veri hacmidir. Analiz Departmanı tarafından sürekli olarak kullanılan milyarlarca satır, eski veri silme işlemlerinde tttl kullanmalarını engelliyor. Analiz gereksinimleri nedeniyle işlem veritabanında veri geçmişinin tamamının korunması, bunları istek birimi sağlamayı sürekli artırmaya zorlayarak maliyetleri etkiler. İşlemsel ve analitik iş yükleri aynı anda aynı kaynaklar için rekabet eder.
Ne yapmalı?
Değişiklik Akışı ile çözüm
- Mühendislik ekibi, üç yeni kapsayıcıyı doldurmak için Değişiklik Akışı'nı kullanmaya karar verdi:
Customers,OrdersveItems. Değişiklik Akışı ile verileri normalleştirir ve düzleştirir. Veri modelinden gereksiz bilgiler kaldırılır ve her kapsayıcının 100'e yakın özelliği vardır ve otomatik şema çıkarımı sınırları nedeniyle veri kaybını önler. - Bu yeni kapsayıcılarda analiz deposu etkinleştirildi ve analiz departmanı verileri okumak için Synapse Analytics'i kullanıyor ve analiz sorguları Synapse Apache Spark ve sunucusuz SQL havuzlarında gerçekleştiğinden istek birimi kullanımını azaltıyor.
- Azure
CustomersOrdersAndItemsCosmos DB'de GB başına en az 10 istek birimi bulunduğundan kapsayıcıda artık verileri yalnızca altı ay boyunca tutacak şekilde ayarlanmış tttl vardır ve bu da başka bir istek birimi kullanımını azaltmaya olanak tanır. Daha az veri, daha az istek birimi.
Paketler
Bu makaleden en önemli bilgiler, şemasız bir dünyada veri modellemenin her zamanki gibi önemli olduğunu anlamaktır.
Ekranda bir veri parçasını temsil etmenin tek bir yolu olmadığı gibi, verilerinizi modellemenin tek bir yolu yoktur. Uygulamanızı ve verilerin nasıl üretileceğini, tüketileceğini ve işlendiğini anlamanız gerekir. Ardından, burada sunulan bazı yönergeleri uygulayarak uygulamanızın hemen gereksinimlerini karşılayan bir model oluşturma hakkında ayarlayabilirsiniz. Uygulamalarınızın değişmesi gerektiğinde, bu değişikliği benimsemek ve veri modelinizi kolayca geliştirmek için şemasız veritabanının esnekliğini kullanabilirsiniz.
Sonraki adımlar
Azure Cosmos DB hakkında daha fazla bilgi edinmek için hizmetin belgeler sayfasına bakın .
Verilerinizi birden çok bölüme nasıl parçalayacağınızı anlamak için bkz. Azure Cosmos DB'de Verileri Bölümleme.
Gerçek bir örnek kullanarak Azure Cosmos DB'de verileri modellemeyi ve bölümlemeyi öğrenmek için veri modelleme ve bölümleme - Real-World örneği bölümüne bakın.
Azure Cosmos DB'de verilerinizi modelleme ve bölümleme hakkında eğitim modülüne bakın.
Azure Cosmos DB için Azure Synapse Bağlantısını yapılandırın ve kullanın.
Azure Cosmos DB'ye geçiş için kapasite planlaması yapmaya mı çalışıyorsunuz? Kapasite planlaması için mevcut veritabanı kümeniz hakkındaki bilgileri kullanabilirsiniz.
- Tek bildiğiniz mevcut veritabanı kümenizdeki sanal çekirdek ve sunucu sayısıysa, sanal çekirdek veya vCPU kullanarak istek birimlerini tahmin etme hakkında bilgi edinin
- Geçerli veritabanı iş yükünüz için tipik istek oranlarını biliyorsanız Azure Cosmos DB kapasite planlayıcısı kullanarak istek birimlerini tahmin etme hakkındaki bilgileri okuyun