sparklyr
Azure Databricks not defterlerinde, işlerde ve RStudio Desktop'ta sparklyr'ı destekler. Bu makalede sparklyr'ı nasıl kullanabileceğiniz açıklanır ve çalıştırabileceğiniz örnek betikler sağlanır. Daha fazla bilgi için bkz . Apache Spark için R arabirimi.
Gereksinimler
Azure Databricks, sparklyr'ın en son kararlı sürümünü her Databricks Runtime sürümüyle dağıtır. Sparklyr'ın yüklü sürümünü içeri aktararak Sparklyr'ı Azure Databricks R not defterlerinde veya Azure Databricks'te barındırılan RStudio Server'ın içinde kullanabilirsiniz.
RStudio Desktop'ta Databricks Bağlan sparklyr'ı yerel makinenizden Azure Databricks kümelerine bağlamanıza ve Apache Spark kodu çalıştırmanıza olanak tanır. Bkz. Databricks Bağlan ile sparklyr ve RStudio Desktop kullanma.
Azure Databricks kümelerine sparklyr Bağlan
Sparklyr bağlantısı kurmak için içinde bağlantı yöntemi spark_connect()olarak kullanabilirsiniz"databricks".
Spark bir Azure Databricks kümesinde spark_connect() zaten yüklü olduğundan ek parametre gerekmez ve çağrı spark_install() yapılması gerekmez.
# Calling spark_connect() requires the sparklyr package to be loaded first.
library(sparklyr)
# Create a sparklyr connection.
sc <- spark_connect(method = "databricks")
Sparklyr ile ilerleme çubukları ve Spark kullanıcı arabirimi
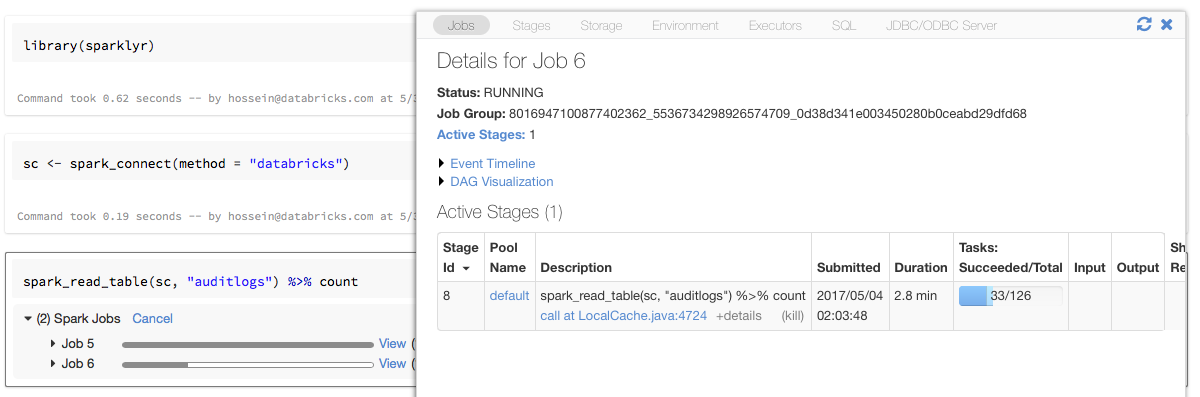
Sparklyr bağlantı nesnesini yukarıdaki örnekteki gibi adlı sc bir değişkene atarsanız, Spark işlerini tetikleyen her komutun ardından not defterinde Spark ilerleme çubukları görürsünüz.
Ayrıca, ilerleme çubuğunun yanındaki bağlantıya tıklayarak verilen Spark işiyle ilişkili Spark kullanıcı arabirimini görüntüleyebilirsiniz.
Sparklyr kullanma
Sparklyr'ı yükleyip bağlantıyı kurduktan sonra diğer tüm sparklyr API'leri normalde olduğu gibi çalışır. Bazı örnekler için örnek not defterine bakın.
sparklyr genellikle dplyr gibi diğer düzenli paketler ile birlikte kullanılır. Bu paketlerin çoğu, kolaylık sağlamak için Databricks'e önceden yüklenmiştir. Bunları içeri aktarabilir ve API'yi kullanmaya başlayabilirsiniz.
Sparklyr ve SparkR'ı birlikte kullanma
SparkR ve sparklyr tek bir not defterinde veya işte birlikte kullanılabilir. SparkR'yi sparklyr ile birlikte içeri aktarabilir ve işlevini kullanabilirsiniz. Azure Databricks not defterlerinde SparkR bağlantısı önceden yapılandırılmıştır.
SparkR'daki işlevlerden bazıları dplyr'de bir dizi işlevi maskeler:
> library(SparkR)
The following objects are masked from ‘package:dplyr’:
arrange, between, coalesce, collect, contains, count, cume_dist,
dense_rank, desc, distinct, explain, filter, first, group_by,
intersect, lag, last, lead, mutate, n, n_distinct, ntile,
percent_rank, rename, row_number, sample_frac, select, sql,
summarize, union
SparkR'yi dplyr'yi içeri aktardıktan sonra içeri aktarırsanız, tam adları kullanarak dplyr'deki işlevlere başvurabilirsiniz; örneğin, dplyr::arrange().
Benzer şekilde, SparkR'den sonra dplyr'yi içeri aktarırsanız, SparkR'deki işlevler dplyr tarafından maskelenir.
Alternatif olarak, ihtiyacınız olmasa da iki paketin birini seçmeli olarak ayırabilirsiniz.
detach("package:dplyr")
Ayrıca bkz. SparkR ve sparklyr karşılaştırması.
Spark-submit işlerinde sparklyr kullanma
Küçük kod değişiklikleriyle spark-submit işleri olarak Azure Databricks'te sparklyr kullanan betikleri çalıştırabilirsiniz. Yukarıdaki yönergelerden bazıları Azure Databricks'teki spark-submit işlerinde sparklyr kullanımı için geçerli değildir. Özellikle, Spark ana URL'sini için spark_connectsağlamanız gerekir. Örneğin:
library(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
...
Desteklenmeyen özellikler
Azure Databricks, ve gibi spark_web()spark_log() yerel bir tarayıcı gerektiren sparklyr yöntemlerini desteklemez. Ancak Spark kullanıcı arabirimi Azure Databricks'te yerleşik olduğundan Spark işlerini ve günlüklerini kolayca inceleyebilirsiniz.
Bkz . İşlem sürücüsü ve çalışan günlükleri.
Örnek not defteri: Sparklyr gösterimi
Sparklyr not defteri
Ek örnekler için bkz . R'de DataFrame'lerle ve tablolarla çalışma.