AutoML tahmini ile derin öğrenme
Bu makalede AutoML'de zaman serisi tahmini için derin öğrenme yöntemlerine odaklanmaktadır. AutoML'deki eğitim tahmin modellerine yönelik yönergeler ve örnekler , zaman serisi tahmini için AutoML'yi ayarlama makalemizde bulunabilir.
Derin öğrenme, dil modellemedenprotein katlamaya kadar birçok alanda önemli bir etki yaratmıştır. Zaman serisi tahminleri de aynı şekilde derin öğrenme teknolojisindeki son gelişmelerden yararlanmıştır. Örneğin derin sinir ağı (DNN) modelleri, yüksek profilli Makridakis tahmin yarışmasının dördüncü ve beşinci yinelemelerinden en iyi performans gösteren modellerde göze çarpmaktadır.
Bu makalede, modeli senaryonuza en iyi şekilde uygulamanıza yardımcı olmak için AutoML'de TCNForecaster modelinin yapısını ve çalışmasını açıklayacağız.
TCNForecaster'a Giriş
TCNForecaster, zaman serisi verileri için özel olarak tasarlanmış bir DNN mimarisine sahip olan zamansal bir kıvrımlı ağ veya TCN'dir. Model, hedefin olasılığa dayalı tahminlerini belirtilen bir tahmin ufkunu oluşturmak için ilgili özelliklerle birlikte bir hedef miktar için geçmiş verilerini kullanır. Aşağıdaki görüntüde TCNForecaster mimarisinin ana bileşenleri gösterilmektedir:
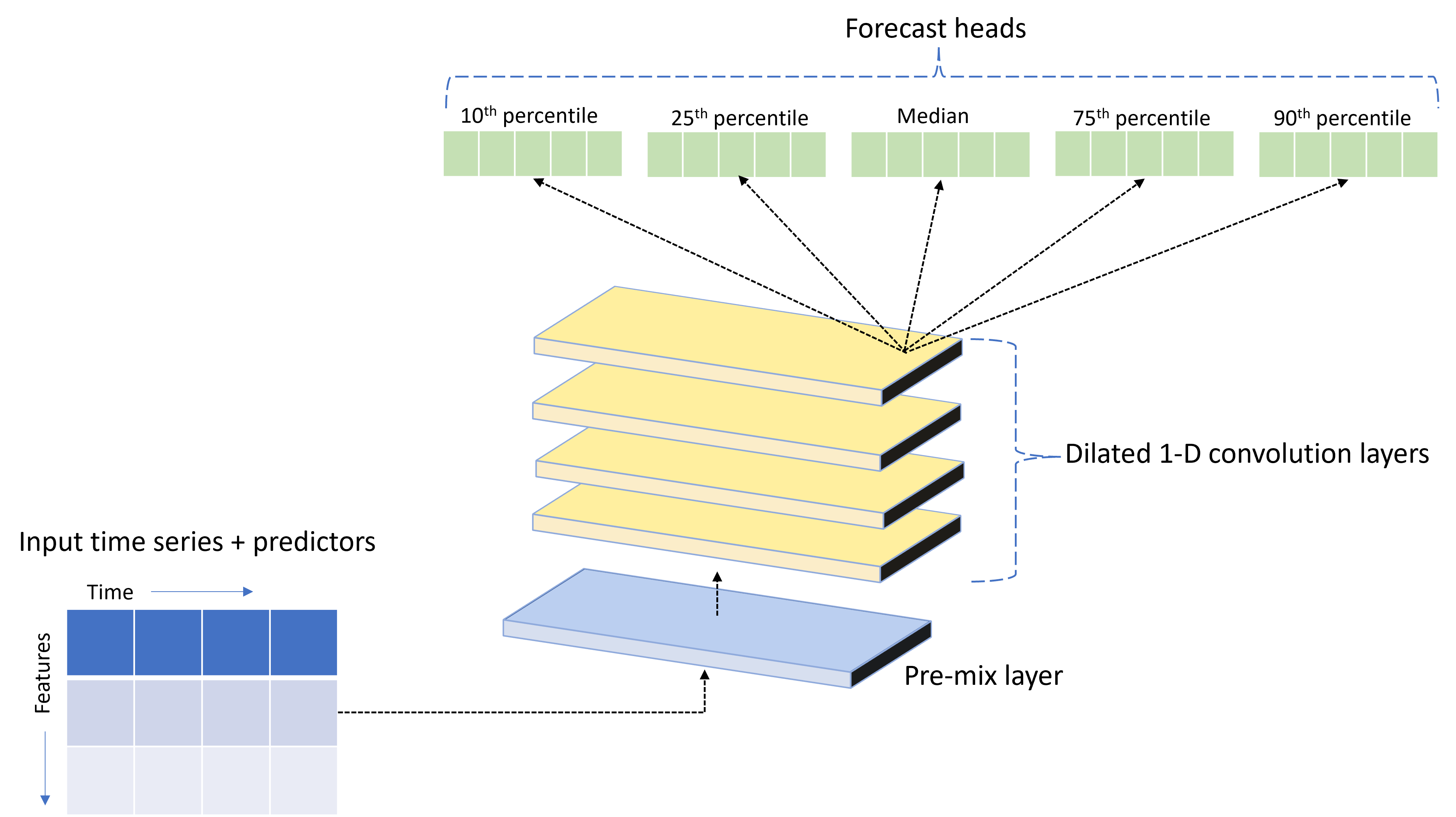
TCNForecaster aşağıdaki ana bileşenlere sahiptir:
- Giriş zaman serisini ve özellik verilerini, kıvrımlı yığının işleyecekleri bir dizi sinyal kanalında bir araya getiren bir ön karışım katmanı.
- Kanal dizisini sıralı olarak işleyen genişlemiş kıvrım katmanları yığını; yığındaki her katman, yeni bir kanal dizisi oluşturmak için önceki katmanın çıkışını işler. Bu çıkıştaki her kanal, giriş kanallarından gelen kıvrımlı filtrelenmiş sinyallerin bir karışımını içerir.
- Konvolüsyon katmanlarından gelen çıkış sinyallerini birleştirilmiş ve bu gizli gösterimden hedef miktarın tahminlerini oluşturan tahmin baş birimleri koleksiyonu. Her baş birim, tahmin dağılımının niceli için ufuk çizgisine kadar tahminler üretir.
Genişlemiş nedensel konvolüsyon
TCN'nin merkezi çalışması, giriş sinyalinin zaman boyutu boyunca genişlemiş, nedensel bir kıvrımdır . Sezgisel olarak, konvolüsyon girişteki yakındaki zaman noktalarından değerleri bir araya getirir. Karışımdaki oranlar, konvolüsyonun çekirdeği veya ağırlıkları, karışımdaki noktalar arasındaki ayrım ise genişlemedir. Çıkış sinyali giriş boyunca çekirdeğin zaman içinde kaydırılması ve karışımın her konumda birikerek girişten oluşturulur. Nedensel konvolüsyon, çekirdeğin her çıkış noktasına göre geçmişteki giriş değerlerini karıştırarak çıkışın geleceğe "bakmasını" önlediği bir işlemdir.
Genişlemiş kıvrımların yığınlanması, TCN'ye nispeten az çekirdek ağırlığına sahip giriş sinyallerinde uzun süreler boyunca bağıntıları modelleme olanağı sağlar. Örneğin, aşağıdaki görüntüde her katmanda iki ağırlıklı bir çekirdek içeren üç yığılmış katman ve üstel olarak artan dilasyon faktörleri gösterilmektedir:
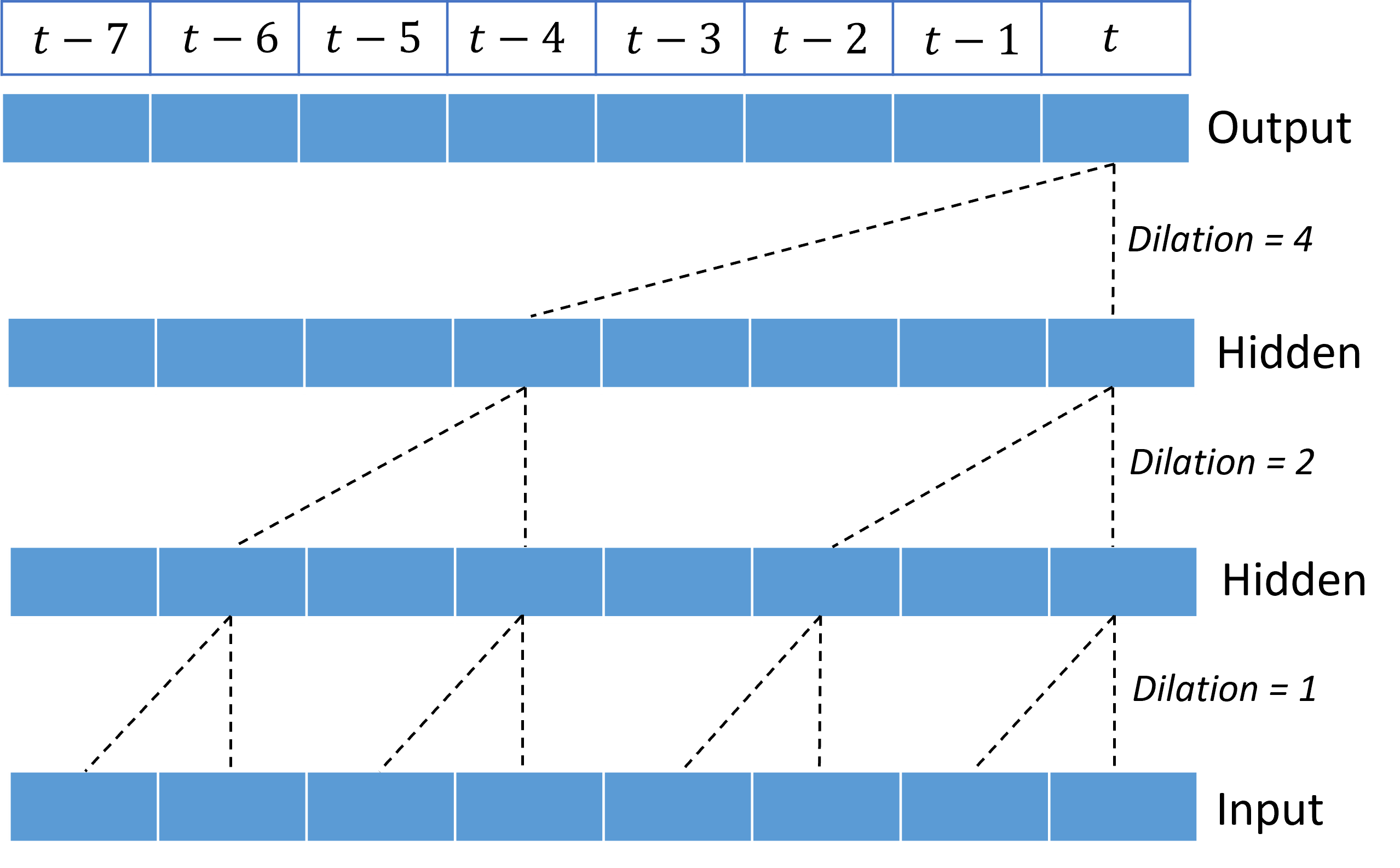
Kesikli çizgiler, ağ üzerinden çıkışta $t$ bir zamanda biten yolları gösterir. Bu yollar girişteki son sekiz noktayı kapsar ve her çıkış noktasının girişteki en son sekiz noktanın bir işlevi olduğunu gösterir. Bir kıvrımlı ağın tahminde bulunmak için kullandığı geçmiş uzunluğu veya "geriye bak", alıcı alan olarak adlandırılır ve tamamen TCN mimarisi tarafından belirlenir.
TCNForecaster mimarisi
TCNForecaster mimarisinin temeli, ön karışım ile tahmin kafaları arasındaki kıvrımlı katmanlar yığınıdır. Yığın mantıksal olarak bloklar olarak adlandırılan ve artık hücrelerden oluşan yinelenen birimlere ayrılır. Artık hücre, normalleştirme ve doğrusal olmayan aktivasyon ile birlikte bir küme genişlemesinde nedensel konvolutasyonlar uygular. Daha da önemlisi, her artık hücre, artık bağlantı olarak adlandırılan bir bağlantı kullanarak çıktısını girişine ekler. Bu bağlantıların, ağ üzerinden daha verimli bilgi akışını kolaylaştırdığı için DNN eğitiminden yararlandığı gösterilmiştir. Aşağıdaki görüntüde, her blokta iki blok ve üç artık hücre bulunan örnek bir ağ için kıvrımlı katmanların mimarisi gösterilmektedir:
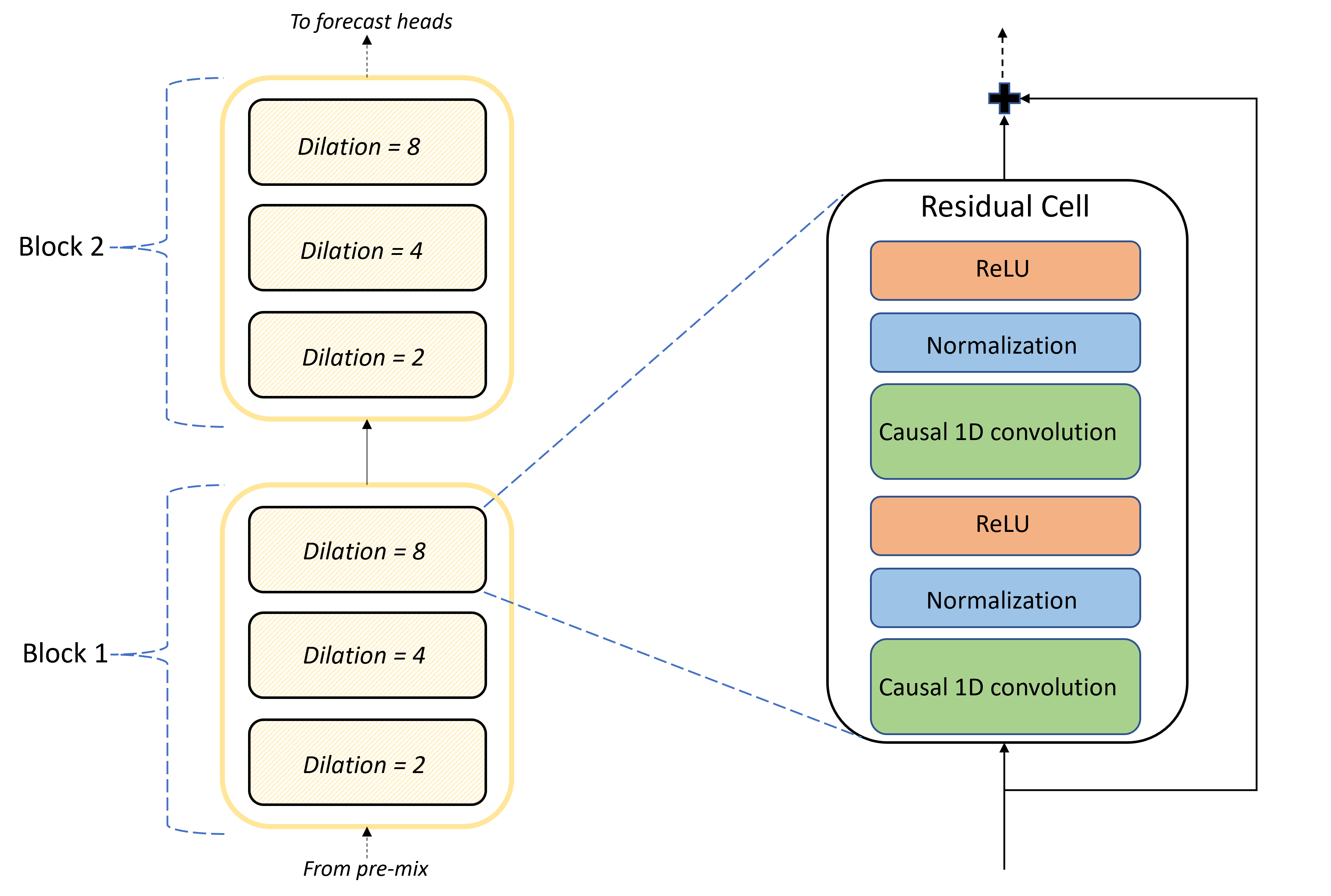
Blok ve hücre sayısı, her katmandaki sinyal kanallarının sayısıyla birlikte ağın boyutunu denetler. TCNForecaster'ın mimari parametreleri aşağıdaki tabloda özetlenir:
| Parametre | Açıklama |
|---|---|
| $n_{b}$ | Ağdaki blok sayısı; derinlik olarak da adlandırılır |
| $n_{c}$ | Her bloktaki hücre sayısı |
| $n_{\text{ch}}$ | Gizli katmanlardaki kanal sayısı |
Alıcı alan derinlik parametrelerine bağlıdır ve formül tarafından verilir,
$t_{\text{rf}} = 4n_{b}\left(2^{n_{c}} - 1\right) + 1.$
Formüller açısından TCNForecaster mimarisinin daha kesin bir tanımını verebiliriz. $X$ her satırın giriş verilerinden özellik değerleri içerdiği bir giriş dizisi olmasına izin verin. $X$ değerini $X_{\text{num}}$ ve $X_{\text{cat}}$ sayısal ve kategorik özellik dizilerine bölebiliriz. Ardından, TCNForecaster formülleri tarafından verilir,
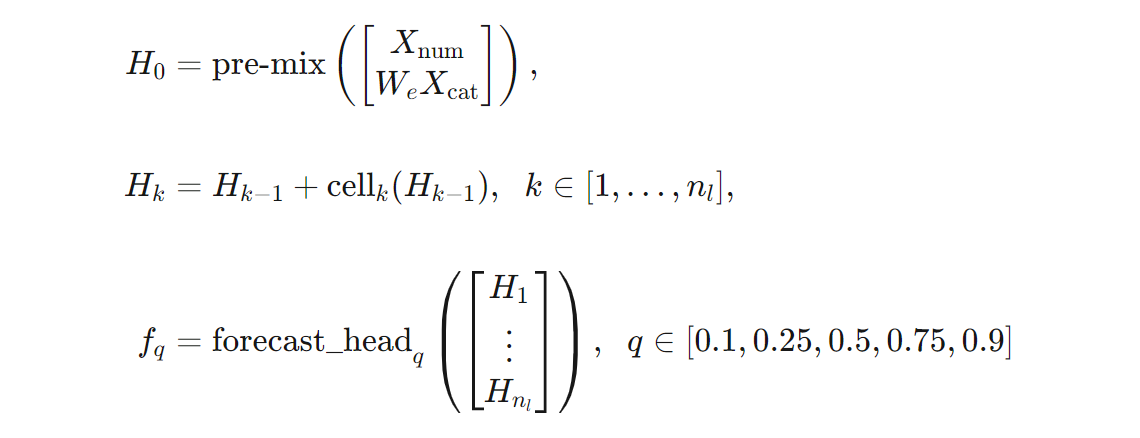
burada $W_{e}$ kategorik özellikler için bir ekleme matrisidir; $n_{l} = n_{b}n_{c}$ toplam artık hücre sayısıdır, $H_{k}$ gizli katman çıkışlarını belirtir ve $f_{q}$ tahmin dağılımının belirli nicelleri için tahmin çıkışlarıdır. Bu değişkenlerin boyutları anlaşılmasına yardımcı olmak için aşağıdaki tabloda yer alır:
| Değişken | Açıklama | Boyutlar |
|---|---|---|
| $X$ | Giriş dizisi | $n_{\text{input}} \times t_{\text{rf}}$ |
| $H_{i}$ | $i=0,1,\ldots,n_{l}$ için gizli katman çıkışı | $n_{\text{ch}} \times t_{\text{rf}}$ |
| $f_{q}$ | Miktar $q$ için tahmin çıkışı | $h$ |
Tabloda $n_{\text{input}} = n_{\text{features}} + 1$, tahmin aracı/özellik değişkenlerinin sayısı ve hedef miktar. TCNForecaster'ın doğrudan tahminci olması için, tahmin başlıkları en yüksek ufuk çizgisine ($h$) kadar olan tüm tahminleri tek bir geçişte oluşturur.
AutoML'de TCNForecaster
TCNForecaster, AutoML'de isteğe bağlı bir modeldir. Kullanmayı öğrenmek için bkz. Derin öğrenmeyi etkinleştirme.
Bu bölümde AutoML'nin verilerinizle birlikte TCNForecaster modellerini nasıl derlediğinden bahsedeceğiz. Bunlar arasında veri ön işleme, eğitim ve model arama açıklamaları da yer alır.
Veri ön işleme adımları
AutoML, model eğitimine hazırlanmak için verilerinizde birkaç ön işlem adımı yürütür. Aşağıdaki tabloda bu adımlar gerçekleştirildikleri sırayla açıklanmaktadır:
| Adım | Açıklama |
|---|---|
| Eksik verileri doldurma | Eksik değerleri ve gözlem boşluklarını ve isteğe bağlı olarak kısa zaman serisini doldurma veya bırakma |
| Takvim özellikleri oluşturma | Giriş verilerini, haftanın günü ve isteğe bağlı olarak belirli bir ülke/bölge için tatiller gibi takvimden türetilen özelliklerle genişletin. |
| Kategorik verileri kodlama | Etiket kodlama dizeleri ve diğer kategorik türler; bu, tüm zaman serisi kimlik sütunlarını içerir. |
| Hedef dönüştürme | İsteğe bağlı olarak, belirli istatistiksel testlerin sonuçlarına bağlı olarak hedefe doğal logaritma işlevini uygulayın. |
| Normalleştirme | Z puanı tüm sayısal verileri normalleştirir; normalleştirme, zaman serisi kimlik sütunları tarafından tanımlandığı şekilde özellik ve zaman serisi grubu başına gerçekleştirilir. |
Bu adımlar AutoML'nin dönüştürme işlem hatlarına dahil edildiğinden, çıkarım zamanında gerektiğinde otomatik olarak uygulanır. Bazı durumlarda, bir adıma ters işlem çıkarım işlem hattına dahil edilir. Örneğin, AutoML eğitim sırasında hedefe $\log$ dönüşümü uyguladıysa, ham tahminler çıkarım işlem hattında üstelleştirilir.
Eğitim
TCNForecaster, görüntü ve dildeki diğer uygulamalar için yaygın olarak kullanılan DNN eğitim en iyi uygulamalarını izler. AutoML, önceden işlenmiş eğitim verilerini karıştırılan ve toplu iş olarak birleştirilen örneklere böler. Ağ, ağ ağırlıklarını kayıp işlevine göre iyileştirmek için geri yayma ve stokastik gradyan azalmasını kullanarak toplu işlemleri sırayla işler. Eğitim, tam eğitim verilerinden birçok geçiş gerektirebilir; her geçişe dönem adı verilir.
Aşağıdaki tabloda TCNForecaster eğitimi için giriş ayarları ve parametreleri listelenmiş ve açıklanmıştır:
| Eğitim girişi | Description | Değer |
|---|---|---|
| Doğrulama verileri | Ağ iyileştirmeye yol göstermek ve sığdırmayı azaltmak için eğitimden alınan verilerin bir kısmı. | Kullanıcı tarafından sağlanır veya sağlanmazsa eğitim verilerinden otomatik olarak oluşturulur. |
| Birincil ölçüm | Her eğitim döneminin sonundaki doğrulama verilerine ilişkin ortanca değer tahminlerinden hesaplanan ölçüm; erken durdurma ve model seçimi için kullanılır. | Kullanıcı tarafından seçilir; normalleştirilmiş kök ortalama kare hatası veya normalleştirilmiş ortalama mutlak hata. |
| Eğitim dönemleri | Ağ ağırlığı iyileştirmesi için çalıştırılacak en fazla dönem sayısı. | 100; otomatik erken durdurma mantığı, eğitimi daha az sayıda dönemle sonlandırabilir. |
| Erken durdurulan sabır | Eğitim durdurulmadan önce birincil ölçüm geliştirmesinin bekleştirilmesi gereken dönemlerin sayısı. | 20 |
| Loss işlevi | Ağ ağırlığı iyileştirmesi için amaç işlevi. | Nicel kayıp ortalaması 10, 25, 50, 75 ve 90.yüzdebirlik tahminlerde bulundu. |
| Toplu iş boyutu | Toplu işlemdeki örnek sayısı. Her örnekte $n_{\text{input}} \times t_{\text{rf}}$ ve çıkış için $h$ boyutları vardır. | Eğitim verilerindeki toplam örnek sayısından otomatik olarak belirlenir; 1024 maksimum değeri. |
| Boyutları ekleme | Kategorik özellikler için ekleme alanlarının boyutları. | Her özellikteki ayrı değerlerin sayısının dördüncü köküne otomatik olarak ayarlanır ve en yakın tamsayıya yuvarlanmış olur. Eşikler en az 3 ve en fazla 100 değerinde uygulanır. |
| Ağ mimarisi* | Ağın boyutunu ve şeklini denetleen parametreler: derinlik, hücre sayısı ve kanal sayısı. | Model arama tarafından belirlenir. |
| Ağ ağırlıkları | Sinyal karışımlarını, kategorik eklemeleri, kıvrım çekirdeği ağırlıklarını ve tahmin değerlerine eşlemeleri denetleen parametreler. | Rastgele başlatıldı, ardından kayıp işlevine göre iyileştirildi. |
| Öğrenme oranı* | Her gradyan azalma yinelemesinde ağ ağırlıklarının ne kadar ayarlanabileceğini denetler; yakınsama yakınında dinamik olarak azaltıldı . | Model arama tarafından belirlenir. |
| Bırakma oranı* | Ağ ağırlıklarına uygulanan bırakma düzenlileştirme derecesini denetler. | Model arama tarafından belirlenir. |
Yıldız işareti (*) ile işaretlenmiş girişler, sonraki bölümde açıklanan bir hiper parametre araması tarafından belirlenir.
Model arama
AutoML, aşağıdaki hiper parametrelerin değerlerini bulmak için model arama yöntemlerini kullanır:
- Ağ derinliği veya kıvrımlı blok sayısı,
- Blok başına hücre sayısı,
- Her gizli katmandaki kanal sayısı,
- Ağ düzenlileştirme için bırakma oranı,
- Öğrenme oranı.
Bu parametreler için en uygun değerler, sorun senaryosuna ve eğitim verilerine bağlı olarak önemli ölçüde farklılık gösterebilir, bu nedenle AutoML hiper parametre değerleri alanında birkaç farklı modeli eğiter ve doğrulama verilerindeki birincil ölçüm puanına göre en iyi olanı seçer.
Model aramasının iki aşaması vardır:
- AutoML, 12 "yer işareti" modeli üzerinde arama yapar. Yer işareti modelleri statiktir ve hiper parametre alanına makul bir şekilde yayılması için seçilir.
- AutoML, rastgele bir arama kullanarak hiper parametre alanında aramaya devam eder.
Durdurma ölçütleri karşılandığında arama sonlandırılır. Durdurma ölçütleri tahmin eğitim işi yapılandırmasına bağlıdır, ancak bazı örnekler arasında zaman sınırları, gerçekleştirilecek arama denemesi sayısı sınırları ve doğrulama ölçümü geliştirilmediğinde erken durdurma mantığı sayılabilir.
Sonraki adımlar
- Zaman serisi tahmin modelini eğitmek için AutoML'yi ayarlamayı öğrenin.
- AutoML'de tahmin metodolojisi hakkında bilgi edinin.
- AutoML'de tahmin hakkında sık sorulan sorulara göz atın.