AutoML'de tahmin yöntemlerine genel bakış
Bu makalede, AutoML'nin zaman serisi verilerini hazırlamak ve tahmin modelleri oluşturmak için kullandığı yöntemlere odaklanmaktadır. AutoML'de eğitim tahmin modellerine yönelik yönergeler ve örnekler, zaman serisi tahmini için AutoML'yi ayarlama makalemizde bulunabilir.
AutoML, zaman serisi değerlerini tahmin etmek için çeşitli yöntemler kullanır. Bu yöntemler kabaca iki kategoriye atanabilir:
- Geleceğe yönelik tahminlerde bulunmak için hedef miktarın geçmiş değerlerini kullanan zaman serisi modelleri.
- Hedefin değerlerini tahmin etmek için tahmin değişkeni kullanan regresyon veya açıklayıcı modeller.
Örneğin, bir marketten belirli bir portakal suyu markasına yönelik günlük talebi tahmin etme sorununu düşünün. $y_t$ $t$ gününde bu markaya olan talebi temsil etmesine izin verin. Zaman serisi modeli , geçmiş talebin bazı işlevlerini kullanarak talebi $t+1$ olarak tahmin eder.
$y_{t+1} = f(y_t, y_{t-1}, \ldots, y_{t-s})$.
$f$ işlevi genellikle geçmişteki gözlemlenen talebi kullanarak ayarladığımız parametrelere sahiptir. $f$ değerinin tahminlerde bulunmak için kullandığı geçmiş miktarı ($s$) modelin parametresi olarak da kabul edilebilir.
Portakal suyu talebi örneğindeki zaman serisi modeli, yalnızca geçmiş taleple ilgili bilgileri kullandığından yeterince doğru olmayabilir. Fiyat, haftanın günü ve tatil olup olmadığı gibi gelecekteki talebi etkileyebilecek birçok faktör daha vardır. Bu tahmin aracı değişkenlerini kullanan bir regresyon modeli düşünün,
$y = g(\text{price}, \text{haftanın günü}, \text{holiday})$.
Yine $g$ genellikle, AutoML'nin talebin ve tahmincilerin geçmiş değerlerini kullanarak ayarlandığı, normalleştirmeyi yönetenler de dahil olmak üzere bir dizi parametreye sahiptir. Regresyon modelinin tahminlerde bulunmak için eş değer olarak tanımlanmış değişkenler arasındaki bağıntısal desenleri kullandığını vurgumak için ifadeden $t$ değerini atlıyoruz. Yani, $g$ üzerinden $y_{t+1}$ tahmini yapmak için, haftanın hangi günü $t+1$ olduğunu, tatil olup olmadığını ve $t+1$ gündeki portakal suyu fiyatını bilmemiz gerekir. İlk iki bilgi parçası her zaman bir takvime başvurarak kolayca bulunur. Perakende fiyatı genellikle önceden ayarlanmıştır, bu nedenle portakal suyunun fiyatı muhtemelen bir gün ileride de bilinir. Ancak, fiyat gelecekte 10 gün bilinmeyebilir! Bu regresyonun yardımcı programının tahminlere ne kadar ihtiyaç duyacağımız (tahmin ufku olarak da adlandırılır) ve tahmincilerin gelecekteki değerlerini ne derece bildiğimizle sınırlı olduğunu anlamak önemlidir.
Önemli
AutoML'nin tahmin regresyon modelleri, kullanıcı tarafından sağlanan tüm özelliklerin en azından tahmin ufkuna kadar gelecekte bilindiğini varsayar.
AutoML'nin tahmin regresyon modelleri, hedefin ve tahmincilerin geçmiş değerlerini kullanacak şekilde de artırılabilir. Sonuç, bir zaman serisi modelinin özelliklerine ve saf regresyon modeline sahip bir karma modeldir. Geçmiş miktarlar regresyondaki ek tahmin değişkenleridir ve bunlara gecikmeli miktarlar olarak adlandırıyoruz. Gecikme sırası , değerin ne kadar geri bilindiği anlamına gelir. Örneğin, portakal suyu talebi örneğimiz için hedefin sipariş-iki gecikmesinin geçerli değeri, iki gün önce gözlemlenen meyve suyu talebidir.
Zaman serisi modelleri ile regresyon modelleri arasındaki bir diğer önemli fark da tahmin oluşturma şeklidir. Zaman serisi modelleri genellikle özyineleme ilişkileri tarafından tanımlanır ve teker teker tahminler üretir. Geleceğe yönelik birçok dönem tahmin etmek için tahmin ufkuna kadar yinelenir ve önceki tahminleri modele geri besleyerek gerektiğinde bir dönem öncesinden sonraki tahmini oluştururlar. Buna karşılık regresyon modelleri, ufka kadar tüm tahminleri tek seferde oluşturan doğrudan tahminciler olarak adlandırılır. Özyinelemeli modeller önceki tahminleri modele geri aktardığında bileşik tahmin hatası oluştuğundan, doğrudan tahminciler özyinelemeli olanlar için tercih edilebilir. Gecikme özellikleri dahil edildiğinde AutoML, regresyon modellerinin doğrudan tahminciler olarak çalışabilmesi için eğitim verilerinde bazı önemli değişiklikler yapar. Diğer ayrıntılar için gecikme özellikleri makalesine bakın.
AutoML'de modelleri tahmin etme
Aşağıdaki tabloda AutoML'de uygulanan tahmin modelleri ve bunların hangi kategoriye ait olduğu listelenmiştir:
| Zaman Serisi Modelleri | Regresyon Modelleri |
|---|---|
| Naive, MevsimSel Naive, Ortalama, MevsimSel Ortalama, ARIMA(X), Üstel Düzeltme | Doğrusal SGD, LARS LASSO, Elastik Ağ, Kahin, K En Yakın Komşular, Karar Ağacı, Rastgele Orman, Aşırı Rastgele Ağaçlar, Gradyan Artırılmış Ağaçlar, LightGBM, XGBoost, TCNForecaster |
Her kategorideki modeller, ekleyebildikleri desenlerin karmaşıklığı (model kapasitesi olarak da bilinir) sırasıyla kabaca listelenir. Yalnızca gözlemlenen son değeri tahmin eden Naive modeli düşük kapasiteye sahipken, milyonlarca ayarlanabilir parametreye sahip derin bir sinir ağı olan Zamana Bağlı Kıvrımlı Ağ (TCNForecaster) yüksek kapasiteye sahiptir.
Daha da önemlisi AutoML, doğruluğu daha da geliştirmek için en iyi performansa sahip modellerin ağırlıklı birleşimlerini oluşturan grup modellerini de içerir. Tahmin için, Caruana Grubu Seçim Algoritması aracılığıyla kompozisyonun ve ağırlıkların bulunduğu yumuşak oylama grubu kullanırız.
Dekont
Tahmin modeli toplulukları için iki önemli uyarı vardır:
- TCN şu anda topluluklara eklenemez.
- AutoML varsayılan olarak, AutoML'deki varsayılan regresyon ve sınıflandırma görevlerine dahil edilen yığın grubu olan başka bir grup yöntemini devre dışı bırakır. Yığın grubu, grup ağırlıklarını bulmak için en iyi model tahminlerine bir meta model sığdırıyor. İç karşılaştırmada bu stratejinin zaman serisi verilerine uyma eğiliminin arttığını tespit ettik. Bu, düşük genelleştirmeye neden olabileceğinden yığın grubu varsayılan olarak devre dışı bırakılır. Ancak, AutoML yapılandırmasında istenirse etkinleştirilebilir.
AutoML verilerinizi nasıl kullanır?
AutoML, zaman serisi verilerini tablosal, "geniş" biçimde kabul eder; başka bir ifadeyle, her değişkenin kendi karşılık gelen sütunu olmalıdır. AutoML, tahmin sorunu için sütunlardan birinin zaman ekseni olmasını gerektirir. Bu sütun bir tarih saat türünde ayrıştırılabilir olmalıdır. En basit zaman serisi veri kümesi bir zaman sütunundan ve sayısal bir hedef sütundan oluşur. Hedef, geleceğe yönelik tahminde bulunan değişkendir. Aşağıda, bu basit örnekteki biçimin bir örneği verilmiştir:
| timestamp | miktardan fazla |
|---|---|
| 2012-01-01 | Kategori 100 |
| 2012-01-02 | 97 |
| 2012-01-03 | 106 |
| ... | ... |
| 2013-12-31 | 347 |
Daha karmaşık durumlarda, veriler zaman diziniyle hizalanmış başka sütunlar içerebilir.
| timestamp | SKU | price | Reklamı | miktardan fazla |
|---|---|---|---|---|
| 2012-01-01 | MEYVE SUYU1 | 3.5 | 0 | 100 |
| 2012-01-01 | EKMEK3 | 5.76 | 0 | 47 |
| 2012-01-02 | MEYVE SUYU1 | 3.5 | 0 | 97 |
| 2012-01-02 | EKMEK3 | 5.5 | 1 | 68 |
| ... | ... | ... | ... | ... |
| 2013-12-31 | MEYVE SUYU1 | 3.75 | 0 | 347 |
| 2013-12-31 | EKMEK3 | 5.7 | 0 | 94 |
Bu örnekte bir SKU, perakende satış fiyatı ve zaman damgasına ve hedef miktara ek olarak bir öğenin tanıtılıp tanıtılmadığını gösteren bir bayrak vardır. Bu veri kümesinde biri JUICE1 SKU, biri DE BREAD3 SKU'su için olan iki seri vardır. SKU sütunu bir zaman serisi kimliği sütunudur çünkü gruplandırma ölçütü her biri tek bir seri içeren iki gruba verir. AutoML, modelleri incelemeden önce giriş yapılandırmasının ve verilerinin temel doğrulamasını yapar ve mühendislik özellikleri ekler.
Veri uzunluğu gereksinimleri
Tahmin modelini eğitmek için yeterli miktarda geçmiş veriniz olmalıdır. Bu eşik miktarı eğitim yapılandırmasına göre değişir. Doğrulama verileri sağladıysanız, zaman serisi başına gereken en az eğitim gözlemi sayısı,
$T_{\text{user validation}} = H + \text{max}(l_{\text{max}}, s_{\text{window}}) + 1$,
burada $H$ tahmin ufkudur, $l_{\text{max}}$ en yüksek gecikme sırasıdır ve $s_{\text{window}}$ sıralı toplama özelliklerinin pencere boyutudur. Çapraz doğrulama kullanıyorsanız, en az gözlem sayısı şu şekildedir:
$T_{\text{CV}} = 2H + (n_{\text{CV}} - 1) n_{\text{step}} + \text{max}(l_{\text{max}}, s_{\text{window}}) + 1$,
burada $n_{\text{CV}}$ çapraz doğrulama katlamalarının sayısıdır ve $n_{\text{step}}$ CV adım boyutu veya CV katlamaları arasındaki uzaklıktır. Bu formüllerin arkasındaki temel mantık, gecikmeler ve çapraz doğrulama bölmeleri için bazı doldurmalar da dahil olmak üzere her zaman serisi için en az bir eğitim gözlemleri ufkuna sahip olmanız gerektiğidir. Tahmin için çapraz doğrulama hakkında daha fazla ayrıntı için bkz . tahmin modeli seçimi .
Eksik veri işleme
AutoML'nin zaman serisi modelleri, zaman içinde düzenli aralıklı gözlemler gerektirir. Düzenli aralıklı, burada, gözlemler arasındaki gün sayısının değişebileceği aylık veya yıllık gözlemler gibi durumları içerir. Modellemeden önce AutoML, eksik seri değerleri olmadığından ve gözlemlerin düzenli olduğundan emin olmalıdır. Bu nedenle, iki eksik veri durumu vardır:
- Tablo verilerindeki bazı hücrelerde bir değer eksik
- Zaman serisi sıklığı göz önüne alındığında beklenen gözleme karşılık gelen bir satır eksik
İlk durumda, AutoML ortak, yapılandırılabilir teknikleri kullanarak eksik değerleri açar.
Aşağıdaki tabloda eksik, beklenen bir satır örneği gösterilmiştir:
| timestamp | miktardan fazla |
|---|---|
| 2012-01-01 | Kategori 100 |
| 2012-01-03 | 106 |
| 2012-01-04 | 103 |
| ... | ... |
| 2013-12-31 | 347 |
Bu serinin günlük bir sıklığı vardır, ancak 2 Ocak 2012'de gözlem yoktur. Bu durumda AutoML, 2 Ocak 2012 için yeni bir satır ekleyerek verileri doldurmaya çalışır. Sütun için quantity yeni değer ve verilerdeki diğer sütunlar, diğer eksik değerler gibi işaretlenir. AutoML'nin bunun gibi gözlem boşluklarını doldurabilmesi için seri sıklığını bilmesi gerektiği açıktır. AutoML bu sıklığı otomatik olarak algılar veya isteğe bağlı olarak kullanıcı bunu yapılandırmada sağlayabilir.
Eksik değerleri doldurmak için imputation yöntemi girişte yapılandırılabilir. Varsayılan yöntemler aşağıdaki tabloda listelenmiştir:
| Sütun Türü | Varsayılan Imputation Yöntemi |
|---|---|
| Hedef | İleri dolgu (son gözlem ileriye taşındı) |
| Sayısal Özellik | Ortanca değer |
Kategorik özelliklerin eksik değerleri, eksik bir değere karşılık gelen ek bir kategori eklenerek sayısal kodlama sırasında işlenir. Imputation bu örnekte örtük bir işlemdir.
Otomatik özellik mühendisliği
AutoML genellikle modelleme doğruluğunu artırmak için kullanıcı verilerine yeni sütunlar ekler. Mühendislik özelliği şunları içerebilir:
| Özellik Grubu | Varsayılan/İsteğe Bağlı |
|---|---|
| Zaman dizininden türetilen takvim özellikleri (örneğin, haftanın günü) | Varsayılan |
| Zaman serisi kimliklerinden türetilen kategorik özellikler | Varsayılan |
| Kategorik türleri sayısal türe kodlama | Varsayılan |
| Belirli bir ülke veya bölgeyle ilişkili tatiller için gösterge özellikleri | İsteğe bağlı |
| Hedef miktarın gecikmeleri | İsteğe bağlı |
| Özellik sütunlarının gecikmeleri | İsteğe bağlı |
| Hedef miktarın sıralı pencere toplamaları (örneğin, sıralı ortalama) | İsteğe bağlı |
| Mevsimsel ayrıştırma (STL) | İsteğe bağlı |
Özellik geliştirmeyi AutoML SDK'sından ForecastingJob sınıfı aracılığıyla veya Azure Machine Learning stüdyosu web arabiriminden yapılandırabilirsiniz.
Sabit olmayan zaman serisi algılama ve işleme
Zaman içinde ortalama ve varyans değişiminin sabit olmayan olarak adlandırıldığı zaman serisi. Örneğin, stokastik eğilimler sergileyen zaman serisi doğası gereği sabit değildir. Bunu görselleştirmek için aşağıdaki görüntüde genellikle yukarı doğru eğilim gösteren bir seri çizilir. Şimdi serinin ilk ve ikinci yarısı için ortalama (ortalama) değerleri hesaplayın ve karşılaştırın. Aynı mı? Burada, çizimin ilk yarısındaki serinin ortalaması ikinci yarıdan önemli ölçüde daha küçüktür. Serinin ortalamasının, birinin baktığı zaman aralığına bağlı olması, zaman değişen anlara bir örnektir. Burada serinin ortalaması ilk anındır.
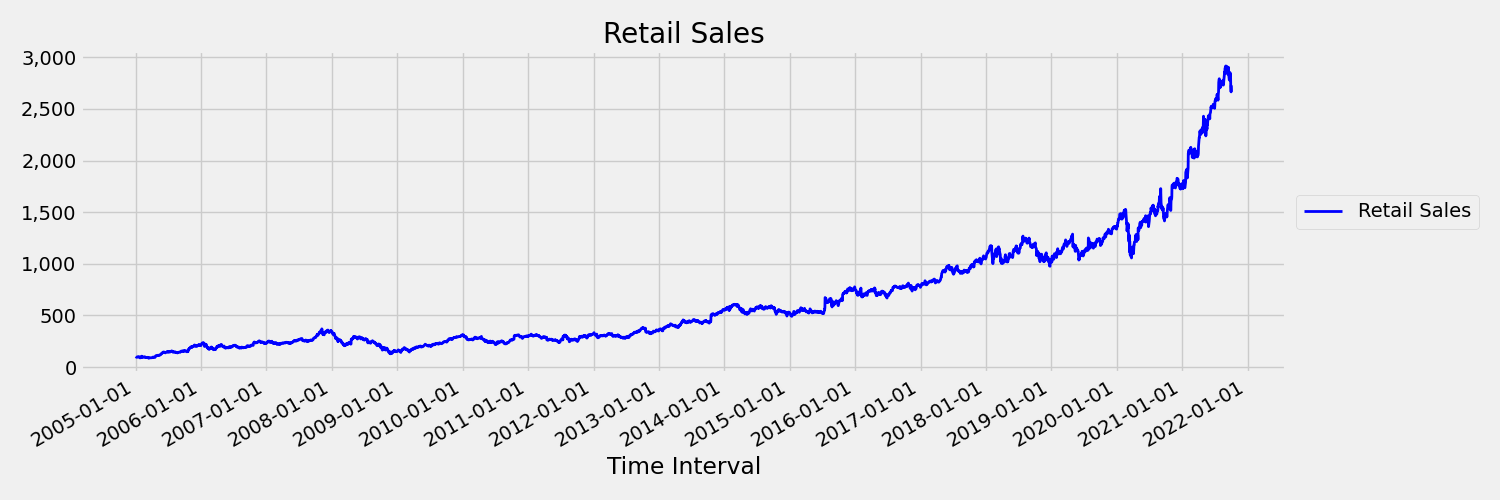
Şimdi özgün seriyi ilk farklar olan $\Delta y_{t} = y_t - y_{t-1}$ olarak çizen aşağıdaki görüntüyü inceleyelim. Serinin ortalaması zaman aralığı boyunca kabaca sabitken, varyans farklılık gösterir. Bu nedenle, bu bir ilk sipariş sabit zaman serisi örneğidir.
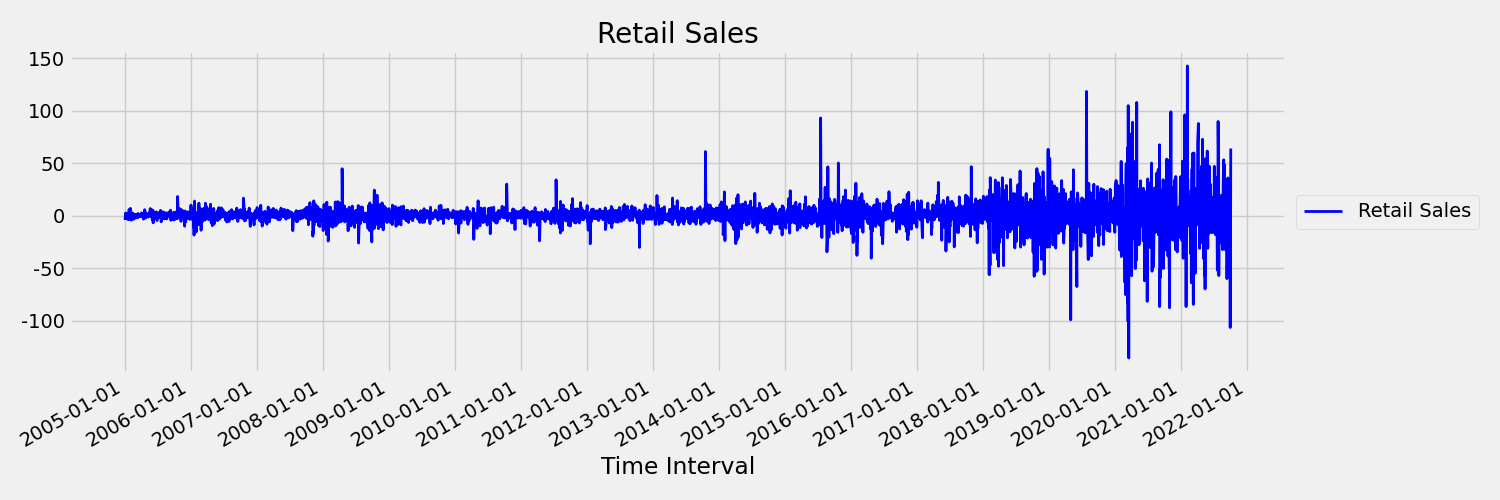
AutoML regresyon modelleri, stokastik eğilimlerle veya sabit olmayan zaman serisiyle ilişkili diğer iyi bilinen sorunlarla doğal olarak başa çıkamaz. Sonuç olarak, bu eğilimler mevcutsa örnek dışı tahmin doğruluğu zayıf olabilir.
AutoML, sabitliği belirlemek için zaman serisi veri kümesini otomatik olarak analiz eder. Sabit olmayan zaman serisi algılandığında AutoML, sabit olmayan davranışların etkisini azaltmak için otomatik olarak bir fark kayıt dönüşümü uygular.
Model süpürme
Veriler eksik veri işleme ve özellik mühendisliğiyle hazırlandıktan sonra AutoML, model öneri hizmetini kullanarak bir dizi modeli ve hiper parametreyi tarar. Modeller doğrulama veya çapraz doğrulama ölçümlerine göre sıralanır ve ardından isteğe bağlı olarak en iyi modeller bir topluluk modelinde kullanılabilir. En iyi model veya eğitilen modellerden herhangi biri, gerektiğinde tahminler üretmek için incelenebilir, indirilebilir veya dağıtılabilir. Daha fazla ayrıntı için model süpürme ve seçim makalesine bakın.
Model gruplandırma
Veri kümesinde verilen veri örneğinde olduğu gibi birden fazla zaman serisi bulunduğunda, bu verileri modellemenin birden çok yolu vardır. Örneğin, zaman serisi kimlik sütunlarına göre gruplandırabilir ve her seri için bağımsız modeller eğitebiliriz. Daha genel bir yaklaşım, verileri her biri birden çok büyük olasılıkla ilgili seri içerebilecek gruplar halinde bölümlendirmek ve grup başına bir model eğitmektir. AutoML tahminleri varsayılan olarak model gruplandırma için karma bir yaklaşım kullanır. Zaman serisi modellerinin yanı sıra ARIMAX ve Peygamber, bir seriyi bir gruba, diğer regresyon modellerini ise tüm serileri tek bir gruba atar. Aşağıdaki tablo, model gruplandırmalarını bire bir ve çoka bir olmak üzere iki kategoride özetler:
| Kendi Grubundaki Her Seri (1:1) | Tek Gruptaki Tüm Seriler (N:1) |
|---|---|
| Naive, Mevsimsel Naive, Ortalama, Mevsim Ortalaması, Üstel Düzeltme, ARIMA, ARIMAX, Peygamber | Doğrusal SGD, LARS LASSO, Elastik Ağ, K En Yakın Komşular, Karar Ağacı, Rastgele Orman, Aşırı Rastgele Ağaçlar, Gradyan Artırılmış Ağaçlar, LightGBM, XGBoost, TCNForecaster |
AutoML'nin Çok Modelli çözümü aracılığıyla daha genel model gruplandırmaları mümkündür; Bkz. Çok Modelli- Otomatik ML not defteri.
Sonraki adımlar
- AutoML'de tahmin için derin öğrenme modelleri hakkında bilgi edinin
- AutoML'de tahmin için model süpürme ve seçim hakkında daha fazla bilgi edinin.
- AutoML'nin takvimden özellikleri nasıl oluşturduğunu öğrenin.
- AutoML'nin gecikme özelliklerini nasıl oluşturduğu hakkında bilgi edinin.
- AutoML'de tahmin hakkında sık sorulan soruların yanıtlarını okuyun.