Azure Machine Learning'de Apache Spark ile Etkileşimli Veri Düzenleme
Veri düzenleme, makine öğrenmesi projelerindeki en önemli adımlardan biri haline gelir. Azure Synapse Analytics ile Azure Machine Learning tümleştirmesi, Azure Machine Learning Not Defterlerini kullanarak etkileşimli veri düzenleme için Azure Synapse tarafından desteklenen bir Apache Spark havuzuna erişim sağlar.
Bu makalede, kullanarak veri düzenleme gerçekleştirmeyi öğreneceksiniz
- Sunucusuz Spark işlem
- Ekli Synapse Spark havuzu
Önkoşullar
- Azure aboneliği; Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun.
- Azure Machine Learning çalışma alanı. Bkz . Çalışma alanı kaynakları oluşturma.
- Azure Data Lake Depolama (ADLS) 2. Nesil depolama hesabı. Bkz. Azure Data Lake Depolama (ADLS) 2. Nesil depolama hesabı oluşturma.
- (İsteğe bağlı): Azure Key Vault. Bkz . Azure Key Vault oluşturma.
- (İsteğe bağlı): Hizmet Sorumlusu. Bkz. Hizmet Sorumlusu Oluşturma.
- (İsteğe bağlı): Azure Machine Learning çalışma alanında ekli bir Synapse Spark havuzu.
Verilerinizi düzenleme görevlerine başlamadan önce gizli dizileri depolama işlemi hakkında bilgi edinin
- Azure Blob depolama hesabı erişim anahtarı
- Paylaşılan Erişim İmzası (SAS) belirteci
- Azure Data Lake Depolama (ADLS) 2. Nesil hizmet sorumlusu bilgileri
öğesini seçin. Ayrıca Azure depolama hesaplarındaki rol atamalarını işlemeyi de bilmeniz gerekir. Aşağıdaki bölümlerde bu kavramlar gözden geçirildi. Ardından, Azure Machine Learning Not Defterleri'ndeki Spark havuzlarını kullanarak etkileşimli veri hazırlamanın ayrıntılarını keşfedeceğiz.
İpucu
Azure depolama hesabı rol atama yapılandırması hakkında bilgi edinmek için veya kullanıcı kimliği geçişini kullanarak depolama hesaplarınızdaki verilere erişiyorsa bkz . Azure depolama hesaplarında rol atamaları ekleme.
Apache Spark ile Etkileşimli Veri Düzenleme
Azure Machine Learning, Azure Machine Learning Not Defterlerinde Apache Spark ile etkileşimli veri düzenleme için sunucusuz Spark işlem ve ekli Synapse Spark havuzu sunar. Sunucusuz Spark işlemi, Azure Synapse çalışma alanında kaynak oluşturulmasını gerektirmez. Bunun yerine, tam olarak yönetilen sunucusuz Spark işlemleri Azure Machine Learning Not Defterlerinde doğrudan kullanılabilir hale gelir. Sunucusuz Spark işlemi kullanmak, Azure Machine Learning'de Spark kümesine erişmek için en kolay yaklaşımdır.
Azure Machine Learning Not Defterlerinde Sunucusuz Spark işlem
Sunucusuz Spark işlemi varsayılan olarak Azure Machine Learning Not Defterleri'nde kullanılabilir. Not defterinden erişmek için İşlem seçim menüsünden Azure Machine Learning Sunucusuz Spark altında Sunucusuz Spark İşlem'iseçin.
Not Defterleri kullanıcı arabirimi, sunucusuz Spark işlem için Spark oturum yapılandırması seçenekleri de sağlar. Spark oturumu yapılandırmak için:
- Ekranın üst kısmındaki Oturumu yapılandır'ı seçin.
- Açılan menüden Apache Spark sürümü'ne tıklayın.
Önemli
Apache Spark için Azure Synapse Runtime: Duyurular
- Apache Spark 3.2 için Azure Synapse Runtime:
- EOLA Duyuru Tarihi: 8 Temmuz 2023
- Destek Sonu Tarihi: 8 Temmuz 2024. Bu tarihten sonra çalışma zamanı devre dışı bırakılır.
- Sürekli destek ve en iyi performans için Apache Spark 3.3'e geçmenizi öneririz.
- Apache Spark 3.2 için Azure Synapse Runtime:
- Açılan menüden Örnek türü'nü seçin. Şu anda aşağıdaki örnek türleri desteklenmektedir:
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
- Dakika cinsinden bir Spark Oturumu zaman aşımı değeri girin.
- Yürütücülerin dinamik olarak ayrılıp ayrılmayacağını seçin
- Spark oturumu için Yürütücü sayısını seçin.
- Açılan menüden Yürütücü boyutu'nu seçin.
- Açılan menüden Sürücü boyutu'nu seçin.
- Spark oturumu yapılandırmak için Conda dosyası kullanmak için Conda dosyasını karşıya yükle onay kutusunu işaretleyin. Ardından Gözat'ı seçin ve istediğiniz Spark oturumu yapılandırmasını içeren Conda dosyasını seçin.
- Özellik ve Değer metin kutularına Yapılandırma ayarları özelliklerini, giriş değerlerini ekleyin ve Ekle'yi seçin.
- Uygula'yı seçin.
- Yeni oturumu yapılandır? açılır penceresinde Oturumu durdur'u seçin.
Oturum yapılandırma değişiklikleri devam eder ve sunucusuz Spark işlemi kullanılarak başlatılan başka bir not defteri oturumunda kullanılabilir hale gelir.
İpucu
Oturum düzeyinde Conda paketleri kullanıyorsanız, yapılandırma değişkenini spark.hadoop.aml.enable_cache true olarak ayarlarsanız Spark oturumu soğuk başlangıç süresini geliştirebilirsiniz. Oturum düzeyi Conda paketleriyle oturum başlatma işlemi genellikle ilk kez başlatıldığında 10-15 dakika sürer. Ancak, sonraki oturum soğuğu, yapılandırma değişkeninin true olarak ayarlanmasıyla başlar ve genellikle üç-beş dakika sürer.
Azure Data Lake Depolama (ADLS) 2. Nesil'den verileri içeri aktarma ve düzenleme
Azure Data Lake Depolama (ADLS) 2. Nesil depolama hesaplarında abfss:// depolanan verilere iki veri erişim mekanizmasından birini izleyerek veri URI'leriyle erişebilir ve verileri düzenleyebilirsiniz:
- Kullanıcı kimliği geçişi
- Hizmet sorumlusu tabanlı veri erişimi
İpucu
Sunucusuz Spark işlem ile veri düzenleme ve Azure Data Lake Depolama (ADLS) 2. Nesil depolama hesabındaki verilere erişmek için kullanıcı kimliği geçişi, en az sayıda yapılandırma adımı gerektirir.
Kullanıcı kimliği geçişiyle etkileşimli veri düzenlemeye başlamak için:
Kullanıcı kimliğinin Azure Data Lake Depolama (ADLS) 2. Nesil depolama hesabında Katkıda Bulunan ve Depolama Blob Veri Katkıda Bulunanırol atamalarına sahip olduğunu doğrulayın.
Sunucusuz Spark işlemini kullanmak için İşlem seçim menüsünden Azure Machine Learning Sunucusuz Spark altında Sunucusuz Spark İşlem'iseçin.
Ekli bir Synapse Spark havuzu kullanmak için İşlem seçim menüsünden Synapse Spark havuzları altında ekli bir Synapse Spark havuzu seçin.
Bu Titanik veri düzenleme kodu örneği, ve
pyspark.ml.feature.Imputerilepyspark.pandasbiçimindeabfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>bir veri URI'sinin kullanımını gösterir.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled", index_col="PassengerId", )Not
Bu Python kod örneği kullanır
pyspark.pandas. Yalnızca Spark çalışma zamanı sürüm 3.2 veya üzeri bunu destekler.
Hizmet sorumlusu aracılığıyla erişime göre verileri düzenlemek için:
Hizmet sorumlusunun Azure Data Lake Depolama (ADLS) 2. Nesil depolama hesabında Katkıda Bulunan ve Depolama Blob Veri Katkıda Bulunanırol atamalarına sahip olduğunu doğrulayın.
Hizmet sorumlusu kiracı kimliği, istemci kimliği ve istemci gizli anahtarı değerleri için Azure Key Vault gizli dizileri oluşturun.
İşlem seçim menüsünden Azure Machine Learning Sunucusuz Spark'ın altında Sunucusuz Spark işlem'iseçin veya İşlem seçim menüsünden Synapse Spark havuzlarıaltında ekli bir Synapse Spark havuzu seçin.
Yapılandırmada hizmet sorumlusu kiracı kimliğini, istemci kimliğini ve istemci gizli dizisini ayarlamak ve aşağıdaki kod örneğini yürütmek için.
get_secret()Koddaki çağrı, Azure Key Vault'un adına ve hizmet sorumlusu kiracı kimliği, istemci kimliği ve istemci gizli dizisi için oluşturulan Azure Key Vault gizli dizilerinin adlarına bağlıdır. Yapılandırmada ilgili özellik adını/değerlerini ayarlayın:- İstemci Kimliği özelliği:
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - İstemci gizli anahtarı özelliği:
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Kiracı Kimliği özelliği:
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Kiracı Kimliği değeri:
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary # Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>") # Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set( "fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_id, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_secret, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", )- İstemci Kimliği özelliği:
Titanik verilerini kullanarak kod örneğinde gösterildiği gibi veri URI'sini
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>kullanarak verileri içeri aktarın ve düzenleyin.
Azure Blob depolamadan verileri içeri aktarma ve düzenleme
Azure Blob depolama verilerine depolama hesabı erişim anahtarı veya paylaşılan erişim imzası (SAS) belirteci ile erişebilirsiniz. Bu kimlik bilgilerini Azure Key Vault'ta gizli dizi olarak depolamalı ve bunları oturum yapılandırmasında özellik olarak ayarlamalısınız.
Etkileşimli veri düzenlemeye başlamak için:
Sol Azure Machine Learning stüdyosu panelde Not Defterleri'ni seçin.
İşlem seçim menüsünden Azure Machine Learning Sunucusuz Spark'ın altında Sunucusuz Spark işlem'iseçin veya İşlem seçim menüsünden Synapse Spark havuzlarıaltında ekli bir Synapse Spark havuzu seçin.
Azure Machine Learning Not Defterlerinde veri erişimi için depolama hesabı erişim anahtarını veya paylaşılan erişim imzası (SAS) belirtecini yapılandırmak için:
Erişim anahtarı için bu kod parçacığında gösterildiği gibi özelliği
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netayarlayın:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key )SAS belirteci için, bu kod parçacığında gösterildiği gibi özelliği
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netayarlayın:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", sas_token, )Not
get_secret()Yukarıdaki kod parçacıklarındaki çağrılar, Azure Key Vault'un adını ve Azure Blob depolama hesabı erişim anahtarı veya SAS belirteci için oluşturulan gizli dizilerin adlarını gerektirir
Veri düzenleme kodunu aynı not defterinde yürütür. Veri URI'sini, bu kod parçacığının gösterdiğine benzer şekilde
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>olarak biçimlendirin:import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled", index_col="PassengerId", )Not
Bu Python kod örneği kullanır
pyspark.pandas. Yalnızca Spark çalışma zamanı sürüm 3.2 veya üzeri bunu destekler.
Azure Machine Learning Veri Deposu'ndan verileri içeri aktarma ve düzenleme
Azure Machine Learning Veri Deposu'ndan verilere erişmek için URI biçimindeazureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA> veri deposundaki verilere yönelik bir yol tanımlayın. Bir Notebooks oturumunda Azure Machine Learning Veri Deposundaki verileri etkileşimli olarak düzenlemek için:
İşlem seçim menüsünden Azure Machine Learning Sunucusuz Spark'ın altında Sunucusuz Spark işlem'iseçin veya İşlem seçim menüsünden Synapse Spark havuzlarıaltında ekli bir Synapse Spark havuzu seçin.
Bu kod örneği, veri deposu URI'sini
pyspark.pandaskullanarakazureml://bir Azure Machine Learning Veri Deposundan Titanik verilerini okuma vepyspark.ml.feature.Imputerdüzenlemeyi gösterir.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "azureml://datastores/workspaceblobstore/paths/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "azureml://datastores/workspaceblobstore/paths/data/wrangled", index_col="PassengerId", )Not
Bu Python kod örneği kullanır
pyspark.pandas. Yalnızca Spark çalışma zamanı sürüm 3.2 veya üzeri bunu destekler.
Azure Machine Learning veri depoları, Azure depolama hesabı kimlik bilgilerini kullanarak verilere erişebilir
- erişim anahtarı
- SAS belirteci
- hizmet sorumlusu
veya kimlik bilgisi olmayan veri erişimi sağlayın. Veri deposu türüne ve temel alınan Azure depolama hesabı türüne bağlı olarak, veri erişimini sağlamak için uygun bir kimlik doğrulama mekanizması seçin. Bu tablo, Azure Machine Learning veri depolarındaki verilere erişmek için kimlik doğrulama mekanizmalarını özetler:
| Storage account type | Kimlik bilgisi olmayan veri erişimi | Veri erişim mekanizması | Rol atamaları |
|---|---|---|---|
| Azure Blob | Hayır | Erişim anahtarı veya SAS belirteci | Rol ataması gerekmez |
| Azure Blob | Yes | Kullanıcı kimliği geçişi* | Kullanıcı kimliğinin Azure Blob depolama hesabında uygun rol atamaları olmalıdır |
| Azure Data Lake Depolama (ADLS) 2. Nesil | Hayır | Hizmet sorumlusu | Hizmet sorumlusunun Azure Data Lake Depolama (ADLS) 2. Nesil depolama hesabında uygun rol atamaları olmalıdır |
| Azure Data Lake Depolama (ADLS) 2. Nesil | Yes | Kullanıcı kimliği geçişi | Kullanıcı kimliği, Azure Data Lake Depolama (ADLS) 2. Nesil depolama hesabında uygun rol atamalarına sahip olmalıdır |
*Kullanıcı kimliği geçişi, yalnızca geçici silme etkinleştirilmemişse Azure Blob depolama hesaplarına işaret eden kimlik bilgisi olmayan veri depoları için çalışır.
Varsayılan dosya paylaşımındaki verilere erişme
Varsayılan dosya paylaşımı hem sunucusuz Spark işlemine hem de bağlı Synapse Spark havuzlarına bağlanır.
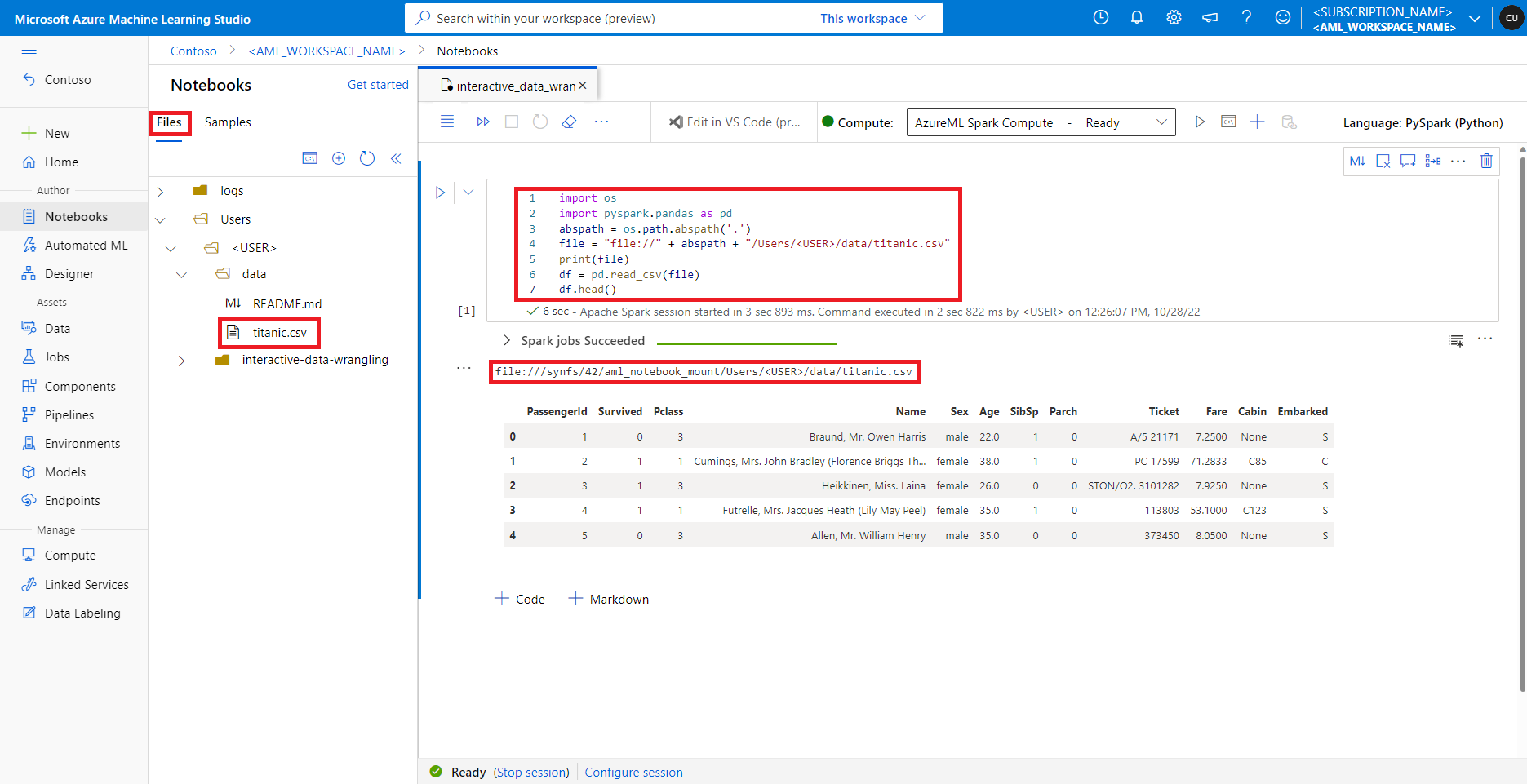
Azure Machine Learning stüdyosu, varsayılan dosya paylaşımındaki dosyalar Dosyalar sekmesinin altındaki dizin ağacında gösterilir. Not defteri kodu, daha fazla yapılandırma olmadan dosyanın mutlak yolu ile birlikte protokolle file:// bu dosya paylaşımında depolanan dosyalara doğrudan erişebilir. Bu kod parçacığı, varsayılan dosya paylaşımında depolanan bir dosyaya nasıl eriş yapılacağını gösterir:
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
abspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(
inputCols=["Age"],
outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
Not
Bu Python kod örneği kullanır pyspark.pandas. Yalnızca Spark çalışma zamanı sürüm 3.2 veya üzeri bunu destekler.