Hızlı Başlangıç: Azure Machine Learning'i kullanmaya başlama
ŞUNLAR IÇIN GEÇERLIDIR:  Python SDK'sı azure-ai-ml v2 (geçerli)
Python SDK'sı azure-ai-ml v2 (geçerli)
Bu öğretici, Azure Machine Learning hizmetinin en çok kullanılan özelliklerinden bazılarına giriş niteliğindedir. Bu modelde bir model oluşturacak, kaydedecek ve dağıtacaksınız. Bu öğretici, Azure Machine Learning'in temel kavramlarını ve bunların en yaygın kullanımını öğrenmenize yardımcı olur.
Ölçeklenebilir bir işlem kaynağında eğitim işini çalıştırmayı, sonra dağıtmayı ve son olarak dağıtımı test etmeyi öğreneceksiniz.
Veri hazırlamayı işlemek, modeli eğitmek ve kaydetmek için bir eğitim betiği oluşturacaksınız. Modeli eğitdikten sonra bir uç nokta olarak dağıtacak ve ardından çıkarım için uç noktayı çağıracaksınız.
Uygulayabileceğiniz adımlar şunlardır:
- Azure Machine Learning çalışma alanınıza tanıtıcı ayarlama
- Eğitim betiğinizi oluşturma
- Ölçeklenebilir bir işlem kaynağı, işlem kümesi oluşturma
- İşlem kümesinde uygun iş ortamıyla yapılandırılmış eğitim betiğini çalıştıracak bir komut işi oluşturma ve çalıştırma
- Eğitim betiğinizin çıktısını görüntüleme
- Yeni eğitilen modeli uç nokta olarak dağıtma
- Çıkarım için Azure Machine Learning uç noktasını çağırma
Bu hızlı başlangıçtaki adımlara genel bakış için bu videoyu izleyin.
Önkoşullar
-
Azure Machine Learning'i kullanmak için öncelikle bir çalışma alanı gerekir. Bir çalışma alanınız yoksa, çalışma alanı oluşturmaya başlamak ve bu çalışma alanını kullanma hakkında daha fazla bilgi edinmek için ihtiyacınız olan kaynakları oluşturma'yı tamamlayın.
-
Stüdyoda oturum açın ve henüz açık değilse çalışma alanınızı seçin.
-
Çalışma alanınızda bir not defteri açın veya oluşturun:
- Hücrelere kod kopyalamak/yapıştırmak istiyorsanız yeni bir not defteri oluşturun.
- Veya studio'nun Örnekler bölümünde tutorials/get-started-notebooks/quickstart.ipynb dosyasını açın. Ardından Kopyala'yı seçerek not defterini Dosyalarınıza ekleyin. (Bkz. Örneklerin bulunacağı yer.)
Çekirdeğinizi ayarlama
Açık not defterinizin üst çubuğunda, henüz yoksa bir işlem örneği oluşturun.

İşlem örneği durdurulduysa İşlemi başlat'ı seçin ve çalışana kadar bekleyin.

Sağ üst kısımda bulunan çekirdeğin olduğundan
Python 3.10 - SDK v2emin olun. Aksi takdirde, bu çekirdeği seçmek için açılan listeyi kullanın.
Kimliğinizin doğrulanması gerektiğini belirten bir başlık görürseniz Kimliği Doğrula'yı seçin.



Önemli
Bu öğreticinin geri kalanı, öğretici not defterinin hücrelerini içerir. Bunları kopyalayıp yeni not defterinize yapıştırın veya kopyaladıysanız şimdi not defterine geçin.
Çalışma alanına tanıtıcı oluşturma
Kodu incelemeden önce çalışma alanınıza başvurmak için bir yönteme ihtiyacınız vardır. Çalışma alanı Azure Machine Learning'in en üst düzey kaynağıdır. Azure Machine Learning'i kullanırken oluşturduğunuz tüm yapıtlarla çalışmak için merkezi bir konum sağlar.
Çalışma alanının tanıtıcısı için oluşturacaksınız ml_client . Daha sonra kaynakları ve işleri yönetmek için kullanacaksınız ml_client .
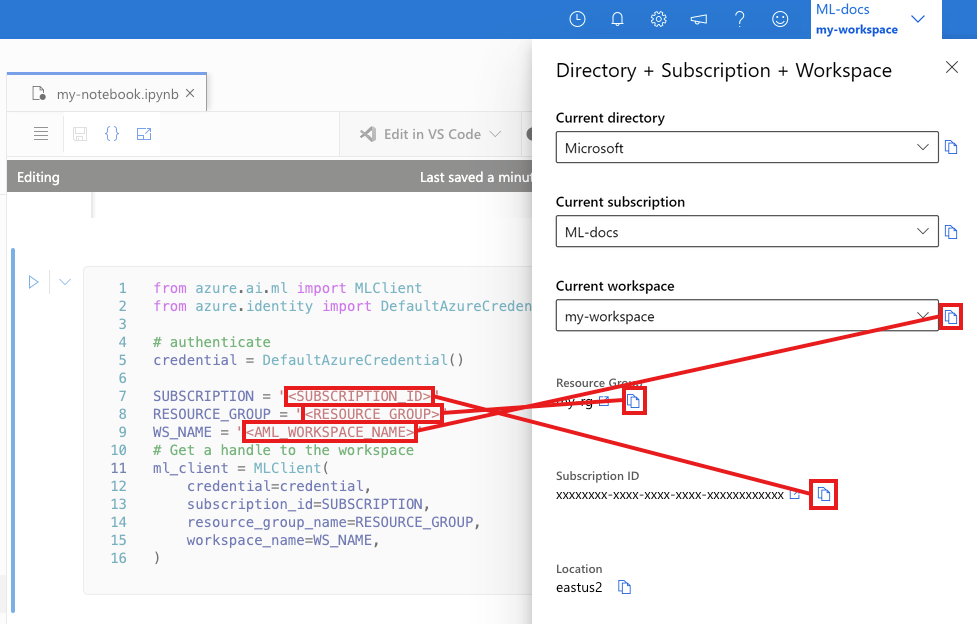
Sonraki hücreye Abonelik Kimliğinizi, Kaynak Grubu adınızı ve Çalışma Alanı adınızı girin. Bu değerleri bulmak için:
- Sağ üst Azure Machine Learning stüdyosu araç çubuğunda çalışma alanı adınızı seçin.
- Çalışma alanı, kaynak grubu ve abonelik kimliğinin değerini koda kopyalayın.
- Bir değeri kopyalamanız, alanı kapatıp yapıştırmanız ve ardından bir sonraki değer için geri dönmeniz gerekir.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Not
MLClient oluşturma çalışma alanına bağlanmaz. İstemci başlatma yavaştır, ilk kez çağrı yapmasını bekler (bu bir sonraki kod hücresinde gerçekleşir).
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
Eğitim betiği oluşturma
Başlangıç olarak python dosyasını main.py eğitim betiğini oluşturalım.
İlk olarak betik için bir kaynak klasör oluşturun:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Bu betik, verilerin önceden işlenmesini işler ve verileri test ve eğitme işlemine böler. Ardından bu verileri kullanarak ağaç tabanlı modeli eğitir ve çıkış modelini döndürür.
İŞLEM hattı çalıştırmamız sırasında parametreleri ve ölçümleri günlüğe kaydetmek için MLFlow kullanılacaktır.
Aşağıdaki hücre, az önce oluşturduğunuz dizine eğitim betiğini yazmak için IPython magic kullanır.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Bu betikte görebileceğiniz gibi, model eğitildikten sonra model dosyası kaydedilir ve çalışma alanına kaydedilir. Artık uç noktaları çıkarsamada kayıtlı modeli kullanabilirsiniz.
Yeni klasörü ve betiği Dosyalarınızda görmek için Yenile'yi seçmeniz gerekebilir.
Komutu yapılandırma
Artık istenen görevleri gerçekleştirebilen bir betiğiniz ve betiği çalıştırmak için bir işlem kümeniz olduğuna göre, komut satırı eylemlerini çalıştırabilen genel amaçlı bir komut kullanacaksınız. Bu komut satırı eylemi doğrudan sistem komutlarını çağırabilir veya bir betik çalıştırabilir.
Burada giriş verilerini, bölme oranını, öğrenme oranını ve kayıtlı model adını belirtmek için giriş değişkenleri oluşturacaksınız. Komut betiği:
- Eğitim betiği için gereken yazılım ve çalışma zamanı kitaplıklarını tanımlayan bir ortam kullanın. Azure Machine Learning, yaygın eğitim ve çıkarım senaryoları için yararlı olan birçok seçilmiş veya hazır ortam sağlar. Bu ortamlardan birini burada kullanacaksınız. Öğretici: Azure Machine Learning'de model eğitme bölümünde özel ortam oluşturmayı öğreneceksiniz.
- Bu durumda komut satırı eyleminin kendisini
python main.pyyapılandırın. Girişlere/çıkışlara komutta gösterimi aracılığıyla${{ ... }}erişilebilir. - Bu örnekte verilere İnternet'teki bir dosyadan erişiyoruz.
- İşlem kaynağı belirtilmediğinden betik, otomatik olarak oluşturulan sunucusuz bir işlem kümesinde çalıştırılır.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="credit_default_prediction",
)
İşi gönderme
Şimdi Azure Machine Learning'de çalıştırılacak işi gönderme zamanı geldi. Bu kez üzerinde ml_clientkullanacaksınızcreate_or_update.
ml_client.create_or_update(job)
İş çıktısını görüntüleme ve işin tamamlanmasını bekleme
önceki hücrenin çıkışındaki bağlantıyı seçerek işi Azure Machine Learning stüdyosu görüntüleyin.
Bu işin çıktısı Azure Machine Learning stüdyosu şöyle görünür. Ölçümler, çıkışlar vb. gibi çeşitli ayrıntılar için sekmeleri keşfedin. İşlem tamamlandıktan sonra iş, eğitimin bir sonucu olarak çalışma alanınıza bir model kaydeder.
Önemli
Devam etmek için bu not defterine dönmeden önce işin durumunun tamamlanmasını bekleyin. İşin çalıştırılması 2-3 dakika sürer. İşlem kümesinin ölçeği sıfır düğüme düşürüldüyse ve özel ortam hala derleniyorsa bu işlem daha uzun sürebilir (10 dakikaya kadar).
Modeli çevrimiçi uç nokta olarak dağıtma
Şimdi makine öğrenmesi modelinizi Azure bulutunda bir web hizmeti olarak dağıtın online endpoint.
Makine öğrenmesi hizmetini dağıtmak için kaydettiğiniz modeli kullanacaksınız.
Yeni bir çevrimiçi uç nokta oluşturma
Artık kayıtlı bir modeliniz olduğuna göre çevrimiçi uç noktanızı oluşturmanın zamanı geldi. Uç nokta adının Azure bölgesinin tamamında benzersiz olması gerekir. Bu öğretici için kullanarak UUIDbenzersiz bir ad oluşturacaksınız.
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Uç noktayı oluşturun:
# Expect the endpoint creation to take a few minutes
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
"model_type": "sklearn.GradientBoostingClassifier",
},
)
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
print(f"Endpoint {endpoint.name} provisioning state: {endpoint.provisioning_state}")
Not
Uç nokta oluşturma işleminin birkaç dakika sürmesini bekleyin.
Uç nokta oluşturulduktan sonra aşağıdaki gibi alabilirsiniz:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Modeli uç noktaya dağıtma
Uç nokta oluşturulduktan sonra modeli giriş betiğiyle dağıtın. Her uç noktanın birden çok dağıtımı olabilir. Bu dağıtımlara doğrudan trafik, kurallar kullanılarak belirtilebilir. Burada gelen trafiğin %100'lerini işleyen tek bir dağıtım oluşturacaksınız. Dağıtım için mavi, yeşil, kırmızı dağıtımlar gibi rastgele bir renk adı seçtik.
Kayıtlı modelinizin en son sürümünü belirlemek için Azure Machine Learning stüdyosu'da Modeller sayfasını kontrol edebilirsiniz. Alternatif olarak, aşağıdaki kod kullanmanız için en son sürüm numarasını alır.
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(f'Latest model is version "{latest_model_version}" ')
Modelin en son sürümünü dağıtın.
# picking the model to deploy. Here we use the latest version of our registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# Expect this deployment to take approximately 6 to 8 minutes.
# create an online deployment.
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()
Not
Bu dağıtımın yaklaşık 6-8 dakika sürmesini bekleyebilirsiniz.
Dağıtım tamamlandığında test etmeye hazır olursunuz.
Örnek sorguyla test edin
Model uç noktaya dağıtıldıktan sonra çıkarım ile çalıştırabilirsiniz.
Puan betiğindeki çalıştırma yönteminde beklenen tasarımı izleyerek örnek bir istek dosyası oluşturun.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
deployment_name="blue",
)
Kaynakları temizleme
Uç noktayı kullanmayacaksanız, kaynağı kullanmayı durdurmak için silin. Silmeden önce başka hiçbir dağıtımın uç nokta kullanmadığından emin olun.
Not
Tam silme işleminin yaklaşık 20 dakika sürmesini bekleyin.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)
İşlem örneğini durdurma
Şimdi kullanmayacaksanız işlem örneğini durdurun:
- Stüdyoda, sol gezinti alanında İşlem'i seçin.
- Üst sekmelerde İşlem örnekleri'ni seçin
- Listeden işlem örneğini seçin.
- Üst araç çubuğunda Durdur'u seçin.
Tüm kaynakları silme
Önemli
Oluşturduğunuz kaynaklar, diğer Azure Machine Learning öğreticileri ve nasıl yapılır makaleleri için önkoşul olarak kullanılabilir.
Oluşturduğunuz kaynaklardan hiçbirini kullanmayı planlamıyorsanız, ücret ödememek için bunları silin:
Azure portalının en sol tarafındaki Kaynak gruplarını seçin.
Listeden, oluşturduğunuz kaynak grubunu seçin.
Kaynak grubunu sil'i seçin.
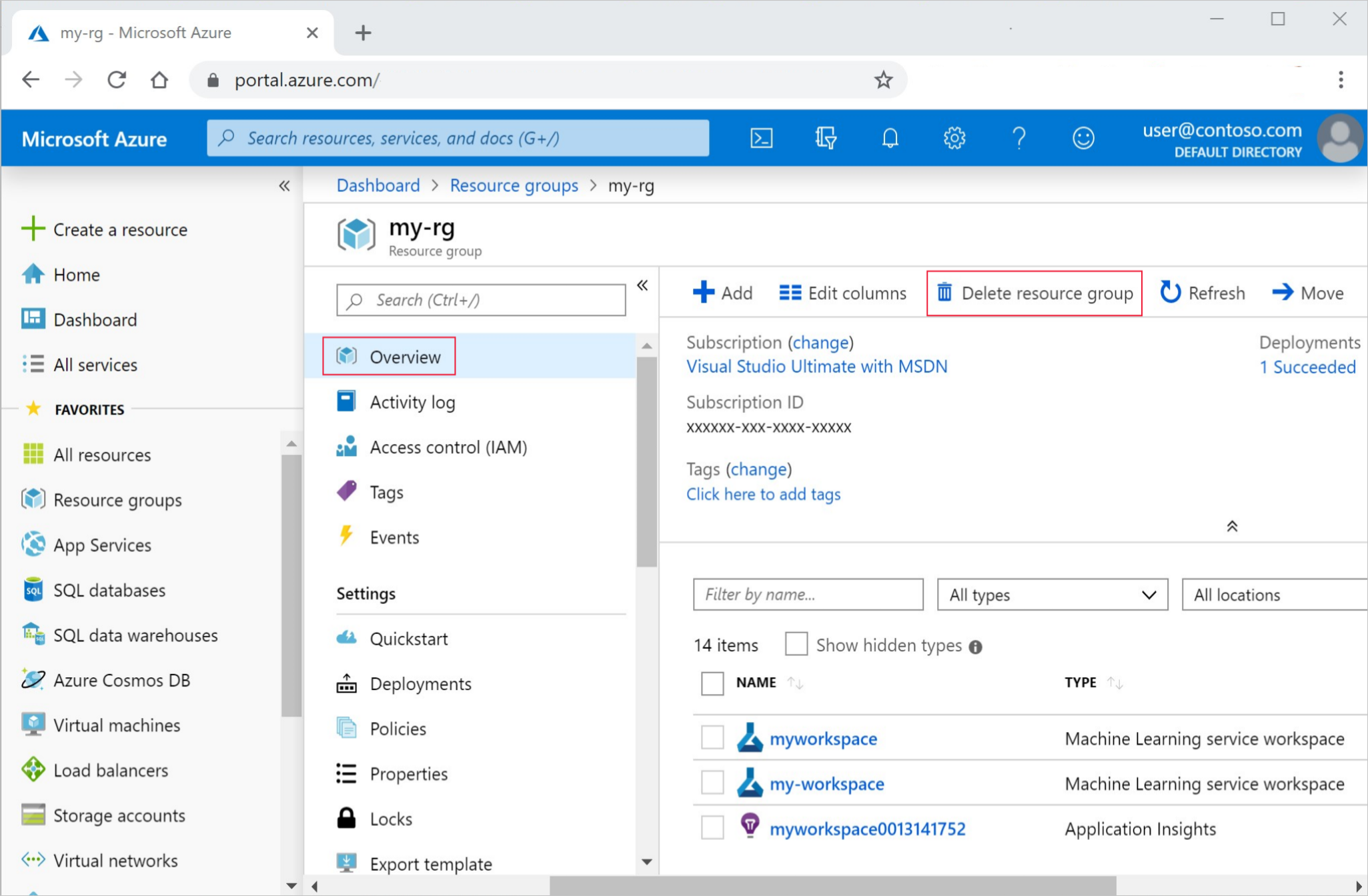
Kaynak grubu adını girin. Ardından Sil'i seçin.
Sonraki adımlar
Artık bir modeli eğitme ve dağıtma ile ilgili bir fikriniz olduğuna göre, bu öğreticilerde süreç hakkında daha fazla bilgi edinin:
| Öğretici | Açıklama |
|---|---|
| Azure Machine Learning'de verilerinizi karşıya yükleme, erişme ve keşfetme | Büyük verileri bulutta depolama ve not defterlerinden ve betiklerden alma |
| Bulut iş istasyonunda model geliştirme | Makine öğrenmesi modellerini prototipleme ve geliştirmeye başlama |
| Azure Machine Learning'de model eğitin | Modeli eğitmeye ilişkin ayrıntılara göz atın |
| Modeli çevrimiçi uç nokta olarak dağıtma | Modeli dağıtmanın ayrıntılarına göz atın |
| Üretim makine öğrenmesi işlem hatları oluşturma | Eksiksiz bir makine öğrenmesi görevini çok adımlı bir iş akışına bölün. |