SAP uygulamalarıyla en iyi ağ gecikme süresi için yapılandırma seçenekleri
Önemli
Kasım 2021'de, yakınlık yerleştirme gruplarının bölgesel dağıtımlarda SAP iş yüküyle nasıl kullanılması gerektiği konusunda önemli değişiklikler yaptık.
SAP NetWeaver veya SAP S/4HANA mimarisini temel alan SAP uygulamaları, SAP uygulama katmanı ile SAP veritabanı katmanı arasındaki ağ gecikme süresine duyarlıdır. Bu duyarlılık, uygulama katmanında çalışan iş mantığının çoğunun sonucudur. SAP uygulama katmanı iş mantığını çalıştırdığından, veritabanı katmanına yüksek sıklıkta ve saniyede bin veya on binlik bir hızda sorgular yayınlar. Çoğu durumda, bu sorguların doğası basittir. Bunlar genellikle veritabanı katmanında 500 mikrosaniye veya daha az sürede çalıştırılabilir.
Ağ üzerinde uygulama katmanından veritabanı katmanına böyle bir sorgu göndermek ve geri gönderilen sonucu almak için harcanan süre, iş süreçlerinin çalıştırılması için gereken süre üzerinde önemli bir etkiye sahiptir. Bu ağ gecikme süresine duyarlılık, SAP dağıtım projelerinde belirli bir minimum ağ gecikme süresi elde etmek istemenize neden olabilir. Ağ gecikmesini sınıflandırma yönergeleri için bkz . SAP Notu #1100926 - SSS: Ağ performansı .
Birçok Azure bölgesinde veri merkezi sayısı artmıştır. Aynı zamanda, özellikle üst düzey SAP sistemleri için müşteriler, Mv2 veya Mv3 ailesi ve daha yenileri gibi daha özel VM aileleri kullanıyor. Bu Azure sanal makine türleri, bir Azure bölgesine toplanan veri merkezlerinin her birinde her zaman kullanılamaz. Bu olgular, SAP uygulama katmanı ile SAP DBMS katmanı arasındaki ağ gecikme süresini iyileştirme fırsatları oluşturabilir.
Azure, SAP iş yükleri için farklı dağıtım seçenekleri sağlar. Seçilen dağıtım türü için gerekirse ağ gecikme süresini iyileştirme seçenekleriniz vardır. Her seçenekle ilgili ayrıntılı bilgiler bu makalenin aşağıdaki bölümlerinde ayrıntılı olarak açıklanmıştır:
Yakınlık Yerleştirme Grupları
Yakınlık yerleştirme grupları , farklı VM türlerinin tek bir ağ omurgası altında gruplandırılmasını sağlayarak aralarında en uygun düşük ağ gecikme süresini sağlar. İlk VM yakın yerleştirme grubuna dağıtıldığında, bu VM belirli bir ağ omurgasına bağlanır. Aynı yakınlık yerleştirme grubuna dağıtılacak diğer tüm VM'ler gibi, bu VM'ler de aynı ağ omurgası altında gruplandırılır. Bu potansiyel durum kulağa cazip gelse de, yapı kullanımı bazı kısıtlamalar ve tuzaklar da getirmektedir:
- Tüm Azure VM türlerinin her azure veri merkezinde veya her ağ omurgasında kullanılabilir olduğunu varsayamazsınız. Sonuç olarak, bir yakınlık yerleştirme grubundaki farklı VM türlerinin birleşimi ciddi şekilde kısıtlanabilir. Bu kısıtlamalar, belirli bir VM türünü çalıştırmak için gereken konak donanımının, yakınlık yerleştirme grubunun atandığı veri merkezinde veya ağ omurgasının altında bulunmaması nedeniyle oluşur
- Bir yakınlık yerleştirme grubu içindeki VM'lerin parçalarını yeniden boyutlandırdığınızda, her durumda yeni VM türünün aynı veri merkezinde veya ağ omurgasının altında yakınlık yerleştirme grubunun atandığı varsayılamaz
- Azure donanımları kullanımdan kaldırdıkça, yakınlık yerleştirme grubunun belirli VM'lerini başka bir Azure veri merkezine veya başka bir ağ omurgasına zorlayabilir. Bu olayı kapsayan ayrıntılar için Yakınlık yerleştirme grupları belgesini okuyun
Önemli
Olası kısıtlamaların bir sonucu olarak, yakınlık yerleştirme grupları yalnızca kullanılmalıdır:
- Belirli senaryolarda gerektiğinde (daha sonra bakın)
- Uygulama katmanı ile DBMS katmanı arasındaki ağ gecikme süresi çok yüksek olduğunda ve iş yükünü etkilediyse
- Yalnızca tek bir SAP sisteminin ayrıntı düzeyindedir ve tüm sistem ortamı veya eksiksiz bir SAP ortamı için değildir
- Farklı VM türlerini ve yakınlık yerleştirme grubundaki VM sayısını en düşük düzeyde tutmak için
Yakınlık yerleştirme gruplarının ağ gecikme süresini iyileştirmek için kullanılabildiği senaryolar:
- SAP iş yükünüzün kritik kaynaklarını farklı kullanılabilirlik alanlarına dağıtmak istiyorsunuz ve diğer yandan her bir bölgede kullanılabilirlik kümelerini kullanarak farklı hata etki alanlarına dağıtılacak uygulama katmanı VM'lerine ihtiyacınız var. Bu durumda, daha sonra belgede açıklandığı gibi, yakınlık yerleştirme grupları gerekli tutkaldır.
- SAP iş yükünü kullanılabilirlik kümeleriyle dağıtırsınız. SAP veritabanı katmanı, SAP uygulama katmanı ve ASCS/SCS VM'leri üç farklı kullanılabilirlik kümesinde gruplandırılır. Böyle bir durumda kullanılabilirlik kümelerinin tüm Azure bölgesine yayılmadığından emin olmak istersiniz çünkü bu, Azure bölgesine bağlı olarak SAP iş yükünü olumsuz etkileyebilecek ağ gecikme süresine neden olabilir.
- VM'lerde barındırılan hizmetler arasında mümkün olan en düşük ağ gecikme süresini elde etmek üzere VM'leri birlikte gruplandırmak için yakınlık yerleştirme gruplarını kullanırsınız. Örneğin, bir kullanılabilirlik alanı içindeki gecikme süresi yalnızca uygulama gereksinimlerini karşılamaz.
Dağıtım senaryosu #2'ye gelince, birçok bölgede, özellikle kullanılabilirlik alanları olmayan bölgelerde ve kullanılabilirlik alanları olan bölgelerin çoğunda, VM'lerin bulunduğu yerden bağımsız ağ gecikme süresi kabul edilebilir. Azure'ın bazı bölgeleri, yakınlık yerleştirme grupları kullanılmadan üç farklı kullanılabilirlik kümesinin yerini belirlemeden yeterince iyi bir deneyim sağlayamıyor.
Yakınlık yerleştirme grupları nelerdir?
Azure yakınlık yerleştirme grubu mantıksal bir yapıdır. Yakınlık yerleştirme grubu tanımlandığında, bir Azure bölgesine ve bir Azure kaynak grubuna bağlıdır. VM'ler dağıtıldığında, aşağıdakiler tarafından bir yakınlık yerleştirme grubuna başvurulur:
- Birçok Azure işlem birimine ve düşük ağ gecikme süresine sahip bir ağ omurgası altında dağıtılan ilk Azure VM. Böyle bir ağ omurgası genellikle tek bir Azure veri merkeziyle eşleşir. İlk sanal makineyi, sonunda dağıtım parametreleriyle birleştirilen Azure ayırma algoritmalarını temel alan bir işlem ölçek birimine dağıtılan bir "kapsam VM" olarak düşünebilirsiniz.
- Yakınlık yerleştirme grubuna başvuran sonraki tüm VM'ler ilk sanal makineyle aynı ağ omurgası altında dağıtılacaktır.
Not
İlk VM'nin yerleştirildiği ağ omurgasının altında belirli bir VM türünü çalıştırabilecek dağıtılmış bir konak donanımı yoksa, istenen VM türünün dağıtımı başarılı olmaz. Vm'nin yakınlık yerleştirme grubunun çevresi içinde desteklenmediğini belirten bir ayırma hatası iletisi alırsınız.
Yukarıdakilerin riskini azaltmak için yakınlık yerleştirme grubunu oluştururken amaç seçeneğini kullanmanız önerilir. Amaç seçeneği, yakınlık yerleştirme grubuna eklemeyi planladığınız VM türlerini listelemenizi sağlar. Bu VM türlerini barındıran en iyi veri merkezini bulmak için bu VM türlerinin listesi alınacaktır. Böyle bir veri merkezi bulunursa PPG oluşturulur ve kapsamı VM SKU gereksinimlerini karşılayan veri merkezi için belirlenmiştir. Böyle bir veri merkezi bulunmazsa yakınlık yerleştirme grubu oluşturulamaz. Belgelerde daha fazla bilgi bulabilirsiniz PPG - VM boyutlarını belirtmek için amacı kullanma. Amaç seçeneği tarafından tetiklenen denetimlerde gerçek kapasite durumlarının dikkate alınmadığını unutmayın. Sonuç olarak, hala yetersiz kapasitede köklenen ayırma hataları olabilir.
Tek bir Azure kaynak grubuna atanmış birden çok yakınlık yerleştirme grubu olabilir. Ancak yakınlık yerleştirme grubu yalnızca bir Azure kaynak grubuna atanabilir.
Yakın yerleştirme grupları hakkında daha fazla bilgi ve dağıtım örnekleri için kullanılabilir belgelere bakın.
Bölgesel dağıtımlarla yakınlık yerleştirme grupları
SAP uygulama katmanı ile DBMS katmanı arasında makul düzeyde düşük bir ağ gecikme süresi sağlamak önemlidir. Çoğu durumda bölgesel dağıtım yalnızca bu gereksinimi karşılar. Sınırlı sayıda senaryo için tek başına bölgesel dağıtım, uygulama gecikme süresi gereksinimlerini karşılamayabilir. Bu gibi durumlarda VM yerleşimi mümkün olduğunca yakın ve düşük ağ gecikme süresine olanak tanır. Böyle bir SAP sistemi için azure yakınlık yerleştirme grubu tanımlanabilir.
Birkaç SAP üretim veya üretim dışı sistemi tek bir yakınlık yerleştirme grubuna paketlemekten kaçının. YAKıNlık yerleştirme grubunda ne kadar çok sistem gruplandırdığınızdan, sap sistemlerinin paketlerinden kaçının:
- Yakınlık yerleştirme grubunun atandığı ağ omurgası altında bulunmayan bir VM türüne ihtiyacınız vardır.
- M Serisi VM'ler gibi, sanal makine sayısını zaman içinde yakınlık yerleştirme grubuna genişletmeniz gerektiğinde, bu sanal makine akışı olmayan VM'lerin kaynakları sonunda tamamlanabiliyordu.
Bir Azure kullanılabilirlik alanı içindeki ağ gecikme süresini azaltmak için Microsoft tarafından Azure bölgelerine dağıtılan birçok iyileştirmeye dayanarak, bölgesel dağıtımlar için yakın yerleştirme grupları kullanılırken dağıtım kılavuzu şöyle görünür:
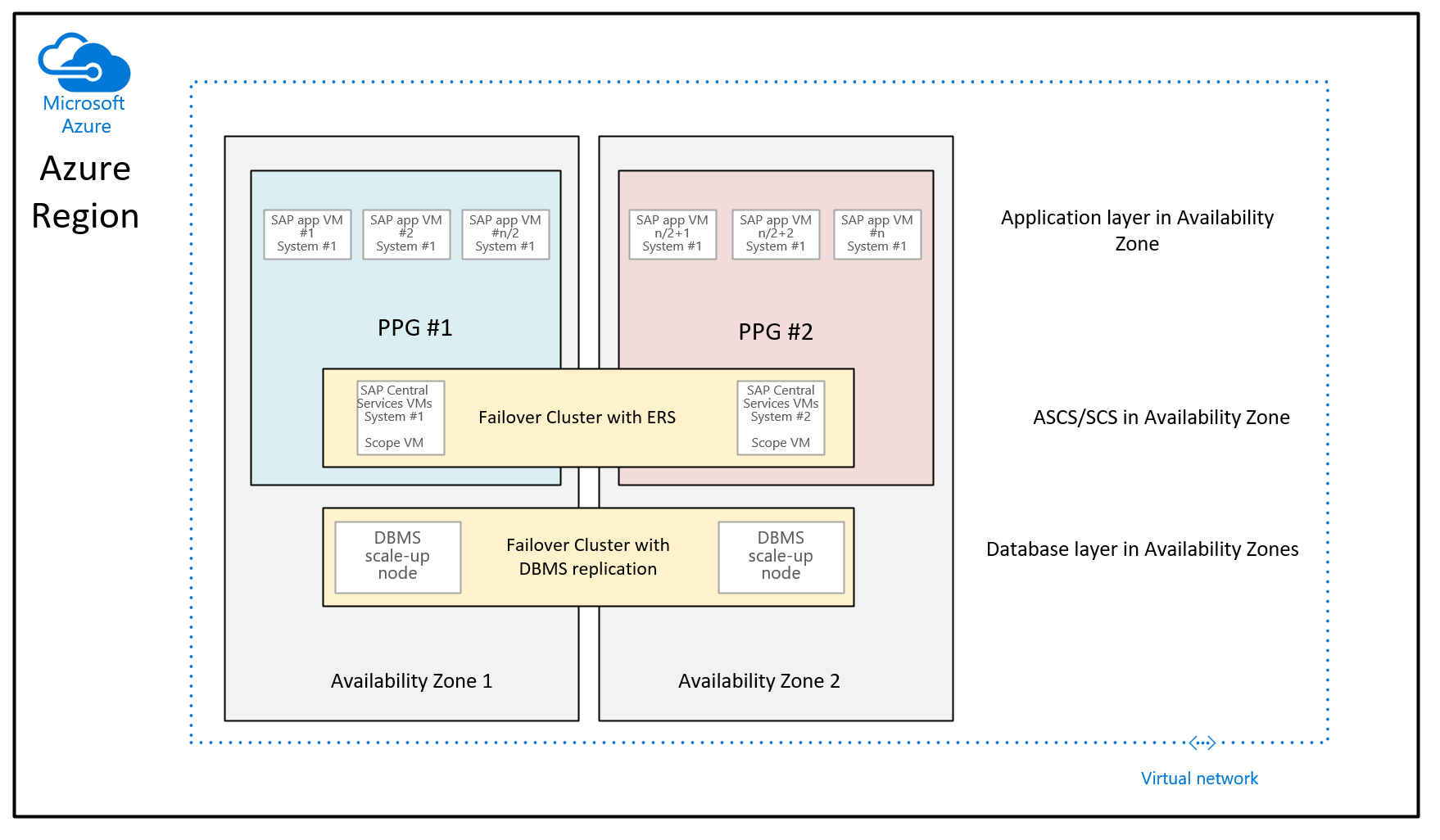
Şu ana kadar verilen önerinin farkı, iki bölgede yer alan veritabanı VM'lerinin yakınlık yerleştirme gruplarının bir parçası olmamasıdır. Bölge başına yakınlık yerleştirme gruplarının kapsamı artık SAP ASCS/SCS örneklerini çalıştıran VM'nin dağıtımıyla belirlenmiştir. Bu, kullanılabilirlik alanlarının birden çok veri merkezi tarafından toplandığı bölgeler için ASCS/SCS örneği ile uygulama katmanının bir ağ omurgası altında çalışabileceği ve veritabanı VM'lerinin başka bir ağ omurgası altında çalışabileceği anlamına da gelir. Yapılan ağ geliştirmeleriyle birlikte, SAP uygulama katmanı ile DBMS katmanı arasındaki ağ gecikme süresi yine de yeterince iyi performans ve aktarım hızı için yeterli olmalıdır. Bu yeni yapılandırmanın avantajı, VM'leri yeniden boyutlandırma veya DBMS katmanı veya/ve SAP sisteminin uygulama katmanı ile yeni VM türlerine geçme konusunda daha fazla esnekliğe sahip olmanızdır.
DBMS ortamı için Azure NetApp Files (ANF) kullanma özel durumu ve SAP HANA için Azure NetApp Files uygulama birimi grubunun ANF ile ilgili yeni işlevselliği ve yakınlık yerleştirme grupları için gerekliliği için, SAP HANA için Azure NetApp Files'da NFS v4.1 birimleri belgesini gözden geçirin.
Kullanılabilirlik kümesi dağıtımlarıyla yakınlık yerleştirme grupları
Bu durumda amaç, farklı kullanılabilirlik kümeleri aracılığıyla dağıtılan VM'leri birlikte dağıtmak için yakınlık yerleştirme gruplarını kullanmaktır. Bu kullanım senaryosunda, bir bölgedeki farklı kullanılabilirlik alanlarında denetimli dağıtım kullanmazsınız. Bunun yerine kullanılabilirlik kümelerini kullanarak SAP sistemini dağıtmak istiyorsunuz. Sonuç olarak DBMS VM'leri, ASCS/SCS VM'leri ve uygulama katmanı VM'leri için en az bir kullanılabilirlik kümeniz vardır. Vm'nin dağıtım zamanında bir kullanılabilirlik kümesi ve kullanılabilirlik alanı belirtemezseniz, farklı kullanılabilirlik kümelerindeki VM'lerin nereye ayrılacağını denetleyemezsiniz. Bu, bazı Azure bölgelerinde farklı VM'ler arasındaki ağ gecikme süresinin yeterince iyi bir performans deneyimi sunmak için çok yüksek olmasına neden olabilir. Bu nedenle ortaya çıkan mimari şöyle görünür:
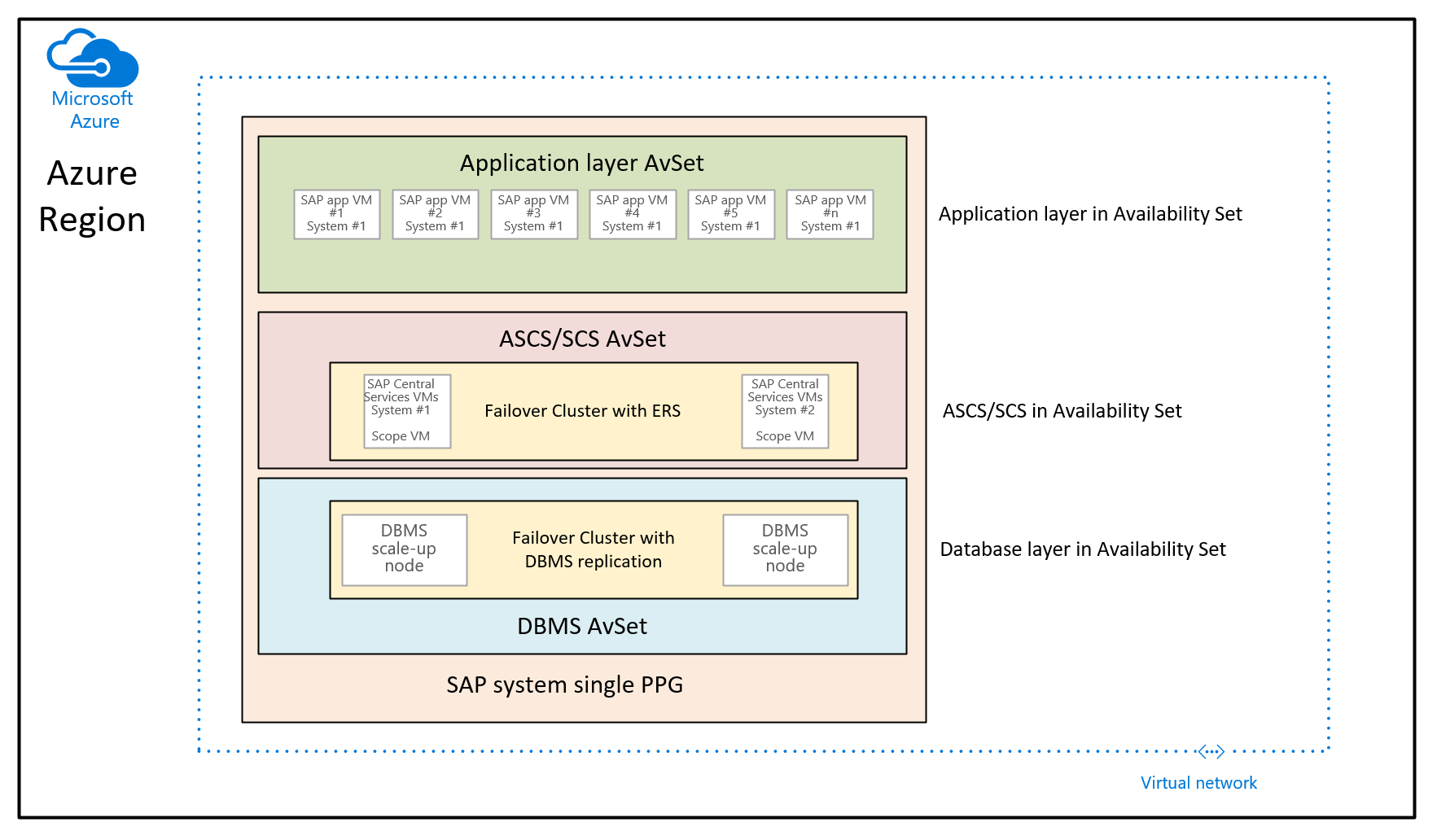
Bu grafikte, tek bir SAP sistemine tek bir yakınlık yerleştirme grubu atanır. Bu PPG üç kullanılabilirlik kümesine atanır. Yakınlık yerleştirme grubunun kapsamı, ilk veritabanı katmanı VM'leri DBMS kullanılabilirlik kümesine dağıtılarak kullanılmaktadır. Bu mimari önerisi, aynı ağ omurgası altındaki tüm VM'leri birleştirir. Bu makalenin önceki bölümlerinde belirtilen kısıtlamalara giriş niteliğindedir. Bu nedenle, yakınlık yerleştirme grubu mimarisi seyrek kullanılmalıdır.
Kullanılabilirlik kümelerini ve kullanılabilirlik alanlarını yakınlık yerleştirme gruplarıyla birleştirme
SAP sistem dağıtımları için kullanılabilirlik alanlarını kullanmanın sorunlarından biri, belirli kullanılabilirlik alanı içindeki kullanılabilirlik kümelerini kullanarak SAP uygulama katmanını dağıtamamanızdır. SAP uygulama katmanının SAP ASCS/SCS VM'leriyle aynı bölgelere dağıtılmasını istiyorsunuz. Tek bir VM dağıtırken bir kullanılabilirlik alanına ve kullanılabilirlik kümesine başvurmak şu ana kadar mümkün değildir. Ancak yalnızca kullanılabilirlik alanına yönerge veren bir VM dağıttığınızda, uygulama katmanı VM'lerinin farklı güncelleştirme ve hata etki alanlarına yayıldığından emin olma özelliğini kaybedersiniz.
Yakınlık yerleştirme gruplarını kullanarak bu kısıtlamayı atlayabilirsiniz. Dağıtım dizisi şöyledir:
- Yakınlık yerleştirme grubu oluşturun.
- Bir kullanılabilirlik alanına başvurarak ASCS/SCS VM olması önerilen bağlantı VM'nizi dağıtın.
- Azure yakınlık yerleştirme grubuna başvuran bir kullanılabilirlik kümesi oluşturun. (Bu makalenin devamında bulunan komutuna bakın.)
- Kullanılabilirlik kümesine ve yakınlık yerleştirme grubuna başvurarak uygulama katmanı VM'lerini dağıtın.
Önemli
Uygulama katmanı VM'lerinin disklerinin, VM'lerin yakınlık yerleştirme grubunu kullanmaya yönlendirilmesiyle aynı kullanılabilirlik alanında ayrılma garantisi verilmediğini anlamak önemlidir. Sonraki adımlarda gösterilen dağıtımın sonucu, VM'lerin aynı ağ omurgasında ve bağlantı VM'siyle aynı kullanılabilirlik alanında ayrılması olabilir. Ancak respctive diskler (temel VHD ve bağlı Azure blok depolama diskleri) aynı ağ omurgası veya hatta aynı kullanılabilirlik bölgesi altında ayrılmayabilir. Bunun yerine bu VM'lerin diskleri belirli bir bölgenin veri merkezlerinden herhangi birinde tahsis edilebilir. Bir bölge tanımlanarak dağıtılan bağlantı VM'sinin diskleri, VM'nin dağıtılmasıyla aynı bölgede dağıtılacaktır.
Önceki bölümde gösterildiği gibi ilk VM'yi dağıtmak yerine, VM'yi dağıtırken bir kullanılabilirlik alanına ve yakınlık yerleştirme grubuna başvurursunuz:
New-AzVm -ResourceGroupName "ppgexercise" -Name "centralserviceszone1" -Location "westus2" -OpenPorts 80,3389 -Zone "1" -ProximityPlacementGroup "collocate" -Size "Standard_E8s_v4"
Bu sanal makinenin başarılı bir dağıtımı, SAP sisteminin ASCS/SCS örneğini tek bir kullanılabilirlik alanında barındıracak. Bu durumda, VM ve VM'nin temel VHD'si ve bağlı olabilecek Azure blok depolama diskleri aynı kullanılabilirlik alanı içinde ayrılır. Yakınlık yerleştirme grubunun kapsamı, tanımladığınız kullanılabilirlik alanındaki ağ omurgalarından birine sabittir.
Sonraki adımda, SAP sisteminizin uygulama katmanı için kullanmak istediğiniz kullanılabilirlik kümelerini oluşturmanız gerekir.
Yakınlık yerleştirme grubunu tanımlayın ve oluşturun. Kullanılabilirlik kümesini oluşturma komutu, yakınlık yerleştirme grubu kimliğine (ad için değil) ek bir başvuru gerektirir. Bu komutu kullanarak yakınlık yerleştirme grubunun kimliğini alabilirsiniz:
Get-AzProximityPlacementGroup -ResourceGroupName "ppgexercise" -Name "collocate"
Kullanılabilirlik kümesini oluştururken, yönetilen diskler (aksi belirtilmedikçe varsayılan) ve yakınlık yerleştirme grupları kullanırken ek parametreleri göz önünde bulundurmanız gerekir:
New-AzAvailabilitySet -ResourceGroupName "ppgexercise" -Name "ppgavset" -Location "westus2" -ProximityPlacementGroupId "/subscriptions/my very long ppg id string" -sku "aligned" -PlatformUpdateDomainCount 3 -PlatformFaultDomainCount 2
İdeal olarak üç hata etki alanı kullanmanız gerekir. Ancak desteklenen hata etki alanlarının sayısı bölgeden bölgeye farklılık gösterebilir. Bu durumda, belirli bölgeler için mümkün olan en fazla hata etki alanı sayısı ikidir. Uygulama katmanı VM'lerinizi dağıtmak için, burada gösterildiği gibi kullanılabilirlik kümesi adınıza ve yakınlık yerleştirme grubu adına bir başvuru eklemeniz gerekir:
New-AzVm -ResourceGroupName "ppgexercise" -Name "appinstance1" -Location "westus2" -OpenPorts 80,3389 -AvailabilitySetName "myppgavset" -ProximityPlacementGroup "collocate" -Size "Standard_E16s_v4"
Not
Yukarıdaki kullanılabilirlik kümesine dağıtılan VM'lerin diskleri, VM ile aynı kullanılabilirlik alanında ayrılmaya zorlanmaz. Uygulama katmanı VM'lerinin bağlantı VM'sinin ayrıldığı ağ omurgası altında farklı hata etki alanlarına yayıldığını başarmış olsanız da, diskler farklı hata etki alanlarında ayrılmış olsa da, bölge genelindeki farklı konumlarda ayrılabilir.
Bu dağıtımın sonucu:
- Belirli bir kullanılabilirlik alanında bulunan SAP sisteminiz için Merkezi Hizmetler.
- SAP Central hizmetleri (ASCS/SCS) VM'leri veya VM'leriyle aynı ağ omurgasında bulunan kullanılabilirlik kümeleri aracılığıyla bulunan bir SAP uygulama katmanı.
Not
Yüksek kullanılabilirlik yapılandırmaları oluşturmak için bir DBMS ve ASCS/SCS VM'sini bir bölgeye, ikinci DBMS ve ASCS/SCS VM'lerini de başka bir bölgeye dağıttığınız için, bölgelerin her biri için farklı bir yakınlık yerleştirme grubuna ihtiyacınız olacaktır. Aynı durum, kullandığınız tüm kullanılabilirlik kümeleri için de geçerlidir.
Mevcut bir sistemin yakınlık yerleştirme grubu yapılandırmalarını değiştirme
Yakın yerleştirme gruplarını şu ana kadar verilen öneriler doğrultusunda uyguladıysanız ve yeni yapılandırmaya uyum sağlamak istiyorsanız, bunu şu makalelerde açıklanan yöntemlerle yapabilirsiniz:
- Azure CLI kullanarak VM'leri yakın yerleştirme gruplarına dağıtın.
- PowerShell kullanarak VM'leri yakın yerleştirme gruplarına dağıtın.
Yakınlık yerleştirme grubunda mevcut bir VM ile yeni bir VM türüne geçememenize neden olan durumlarda ayırma hataları alıyorsanız bu komutları da kullanabilirsiniz.
Esnek düzenleme ile Sanal Makine Ölçek Kümesi
Yakınlık yerleştirme grubuyla ilgili sınırlamaları önlemek için FD=1 ile esnek ölçek kümesi kullanarak SAP iş yükünün kullanılabilirlik alanları arasında dağıtılması önerilir. Bu dağıtım stratejisi, her bölgeye dağıtılan VM'lerin tek bir veri merkezi veya ağ omurgası ile sınırlı olmamasını ve veritabanları, ASCS/ERS ve uygulama katmanı gibi tüm SAP sistem bileşenlerinin kapsamının bir bölge içinde olmasını sağlar. Tüm SAP sistem bileşenlerinin kapsamı bölgesel düzeyde belirlenirken, yeterli performans ve aktarım hızı sağlamak için tek bir SAP sisteminin farklı bileşenleri arasındaki ağ gecikme süresi yeterli olmalıdır. FD=1 ile esnek ölçek kümesine sahip bu yeni dağıtım seçeneğinin temel avantajı, VM'leri yeniden boyutlandırma veya SAP sisteminin tüm katmanları için yeni VM türlerine geçiş yapma konusunda daha fazla esneklik sağlamasıdır. Ayrıca, ölçek kümesi vm'leri tek bir bölge içindeki birden çok hata etki alanı arasında ayırır ve bu, her bölgede uygulama katmanının birden çok VM'sini çalıştırmak için idealdir. Daha fazla bilgi için bkz . SAP iş yükü için sanal makine ölçek kümesi belgesi.

Üretim dışı veya HA olmayan bir ortamda, FD=1 ile esnek bir ölçek kümesi kullanarak veritabanı, ASCS ve uygulama katmanı dahil olmak üzere tüm SAP sistem bileşenlerini tek bir bölgeye dağıtmak mümkündür.
Önceden önerilen dağıtım seçenekleri
Bu bölüm, SAP için ağ gecikme süresini iyileştirmek için önceden önerilen dağıtım seçenekleri hakkındaki ayrıntıları içerir. Yeni özellikler ve zaman içinde Azure'ın büyümesiyle, bu bölümdeki ayrıntılar yalnızca nadir durumlarda uygulanmalıdır.
Bölgesel dağıtımlarla sap sisteminin tamamı için yakınlık yerleştirme grupları
Şu ana kadar önerdiğimiz yakınlık yerleştirme grubu kullanımı, bu grafikte olduğu gibi görünür.

SAP sisteminizi dağıtmış olduğunuz iki kullanılabilirlik alanının her birinde bir yakınlık yerleştirme grubu (PPG) oluşturursunuz. Belirli bir bölgenin tüm VM'leri, söz konusu bölgenin tek tek yakınlık yerleştirme grubunun bir parçasıdır. PPG'yi kapsamak için DBMS VM'sini dağıtarak her bölgeden başlarsınız ve ardından ASCS VM'sini aynı bölge ve PPG'ye dağıtırsınız. Üçüncü adımda bir Azure kullanılabilirlik kümesi oluşturur, kullanılabilirlik kümesini kapsamlı PPG'ye atar ve SAP uygulama katmanını buna dağıtırsınız. Bu yapılandırmanın avantajı, tüm bileşenlerin aynı ağ omurgasının altına düzgün bir şekilde hizalanmış olmasıydı. Büyük dezavantaj, sanal makineleri yeniden boyutlandırma esnekliğinizin sınırlı olmasıdır.
Bir Azure kullanılabilirlik alanı içindeki ağ gecikme süresini azaltmak için Microsoft tarafından Azure bölgelerine dağıtılan birçok iyileştirmeye dayanarak, bu makaledeki bölgesel dağıtımlar için geçerli dağıtım kılavuzu mevcuttur.
Yakınlık yerleştirme grupları ve HANA Büyük Örnekleri
SAP sistemlerinizden bazıları veritabanı katmanı için HANA Büyük Örnekleri kullanıyorsa, Düzeltme 4 satır veya damgalarında dağıtılan HANA Büyük Örnekler birimlerini kullanırken HANA Büyük Örnekler birimi ile Azure VM'leri arasındaki ağ gecikme süresinde önemli geliştirmeler yaşayabilirsiniz. Bir iyileştirme, HANA Büyük Örnekleri birimlerinin dağıtıldıklarında yakınlık yerleştirme grubuyla dağıtılmasıdır. Uygulama katmanı VM'lerinizi dağıtmak için bu yakınlık yerleştirme grubunu kullanabilirsiniz. Sonuç olarak, bu VM'ler HANA Büyük Örnekler biriminizi barındıran veri merkezine dağıtılır.
HANA Büyük Örnekler biriminizin Bir Düzeltme 4 damgasında veya satırında dağıtılıp dağıtılmadığını belirlemek için Azure portalı üzerinden Azure HANA Büyük Örnekler denetimi makalesini gözden geçirin. HANA Büyük Örnekler biriminizin özniteliklere genel bakış bölümünde yakınlık yerleştirme grubunun adını da belirleyebilirsiniz çünkü BU grup, HANA Büyük Örnekler biriminiz dağıtıldığında oluşturulmuştur. Özniteliklere genel bakış bölümünde görünen ad, uygulama katmanı VM'lerinizi dağıtmanız gereken yakınlık yerleştirme grubunun adıdır.
Yalnızca Azure sanal makinelerini kullanan SAP sistemlerine kıyasla, HANA Büyük Örnekleri kullandığınızda, kaç Azure kaynak grubu kullanacağınıza karar verirken daha az esnekliğe sahip olursunuz. HaNA Büyük Örnekler kiracısının tüm HANA Büyük Örnekler birimleri, bu makalede açıklandığı gibi tek bir kaynak grubunda gruplandırılır. Üretim ve üretim dışı sistemler veya diğer sistemler gibi farklı kiracılara dağıtmadığınız sürece, tüm HANA Büyük Örnekler birimleriniz tek bir HANA Büyük Örnekleri kiracısında dağıtılır. Bu kiracının kaynak grubuyla bire bir ilişkisi var. Ancak, tek birimlerin her biri için ayrı bir yakınlık yerleştirme grubu tanımlanır.
Sonuç olarak, tek bir kiracı için Azure kaynak grupları ve yakınlık yerleştirme grupları arasındaki ilişkiler burada gösterildiği gibi olacaktır:

Sonraki adımlar
Belgelere göz atın: