OneLake'i Azure HDInsight ile tümleştirme
Azure HDInsight , kuruluşların büyük miktarlardaki verileri işlemesine yardımcı olan, büyük veri analizi için yönetilen bulut tabanlı bir hizmettir. Bu öğreticide Bir Azure HDInsight kümesinden Jupyter not defteriyle OneLake'e nasıl bağlandığınız gösterilmektedir.
Azure HDInsight'ı kullanma
HDInsight kümesinden Jupyter not defteriyle OneLake'e bağlanmak için:
HDInsight (HDI) Spark kümesi oluşturun. Şu yönergeleri izleyin: HDInsight'ta kümeleri ayarlama.
Küme bilgilerini sağlarken, kümeye daha sonra erişmeleri gerektiğinden Küme oturum açma Kullanıcı Adı ve Parola bilgilerinizi unutmayın.
Kullanıcı tarafından atanan yönetilen kimlik (UAMI) oluşturma: Azure HDInsight için oluşturma - UAMI ve Depolama ekranında kimlik olarak seçin.

Bu UAMI'ye öğelerinizi içeren Doku çalışma alanına erişim verin. En iyi rolü belirleme konusunda yardım için bkz . Çalışma alanı rolleri.
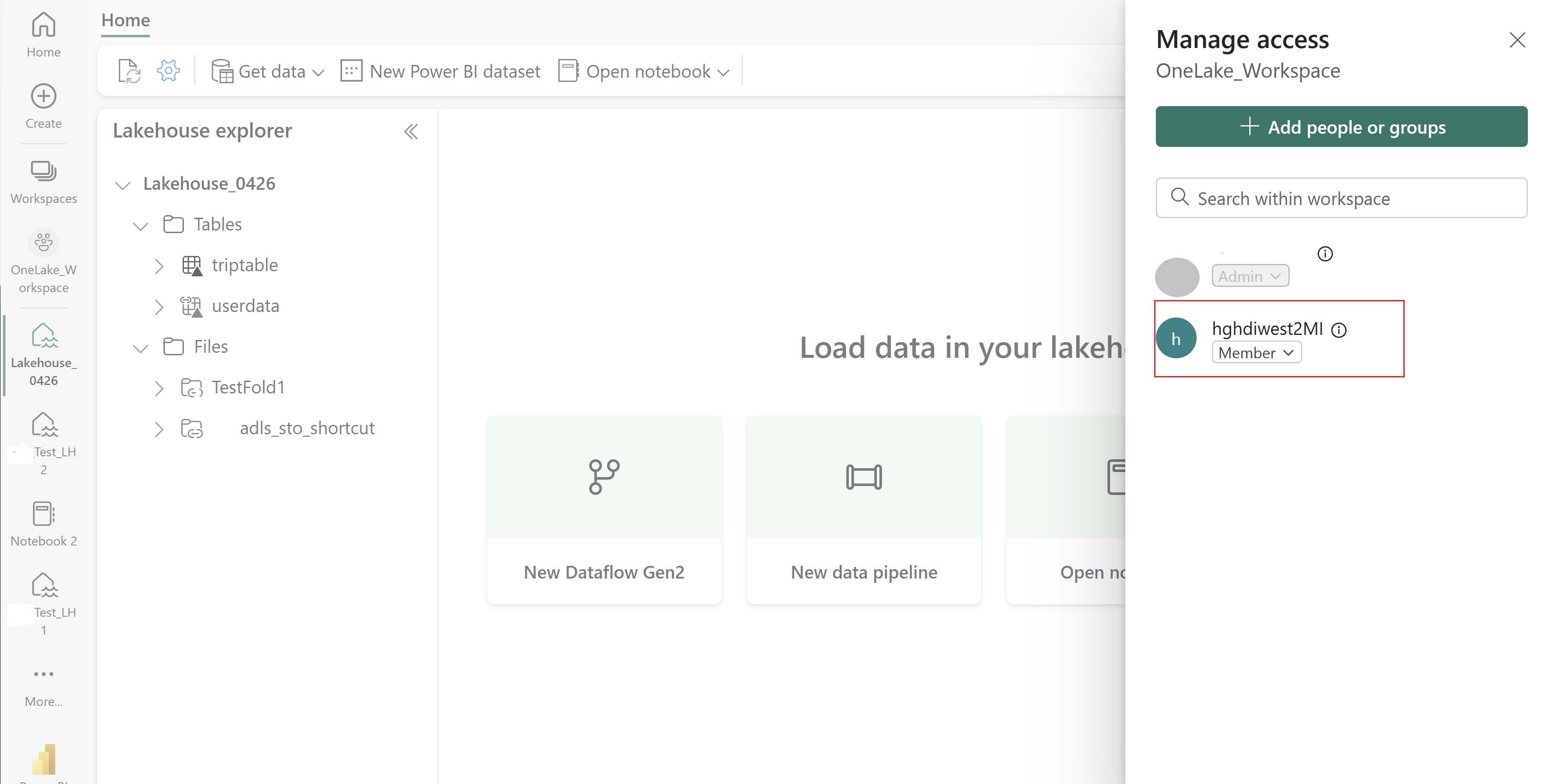
Lakehouse'unuza gidin ve çalışma alanınızın ve lakehouse'unuzun adını bulun. Bunları lakehouse'unuzun URL'sinde veya bir dosyanın Özellikler bölmesinde bulabilirsiniz.
Azure portalında kümenizi arayın ve not defterini seçin.

Kümeyi oluştururken sağladığınız kimlik bilgileri girin.
Yeni bir Spark not defteri oluşturun.
Çalışma alanı ve göl evi adlarını not defterinize kopyalayın ve lakehouse'unuz için OneLake URL'sini oluşturun. Artık bu dosya yolundan herhangi bir dosyayı okuyabilirsiniz.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()Göle veri yazmayı deneyin.
writecsvdf = df.write.format("csv").save(fp + "out.csv")Lakehouse'unuzu denetleyerek veya yeni yüklenen dosyanızı okuyarak verilerinizin başarıyla yazıldığını test edin.




Artık HdI Spark kümesindeki Jupyter not defterinizi kullanarak OneLake'te verileri okuyabilir ve yazabilirsiniz.
İlgili içerik
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin