你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
模型自定义(版本 4.0 预览版)
通过模型自定义,你可针对自己的用例训练专用图像分析模型。 自定义模型可以执行图像分类(标记应用于整个图像)或对象检测(标记应用于图像的特定区域)。 创建并训练自定义模型后,它属于视觉资源,可以使用分析图像 API 调用它。
按照快速入门快速轻松地实现模型自定义:
重要
可以使用自定义视觉服务或具有模型自定义功能的图像分析 4.0 服务来训练自定义模型。 下表对这两项服务进行了比较。
| Areas | 自定义视觉服务 | 图像分析 4.0 服务 | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 任务 | 图像分类对象检测 | 图像分类对象检测 | ||||||||||||||||||||||||||||||||||||
| 基础模型 | CNN | 转换器模型 | ||||||||||||||||||||||||||||||||||||
| 标记 | Customvision.ai | AML Studio | ||||||||||||||||||||||||||||||||||||
| Web 门户 | Customvision.ai | Vision Studio | ||||||||||||||||||||||||||||||||||||
| 库 | REST、SDK | REST、Python 示例 | ||||||||||||||||||||||||||||||||||||
| 所需的最少训练数据 | 每个类别 15 个图像 | 每个类别 2-5 个图像 | ||||||||||||||||||||||||||||||||||||
| 训练数据存储 | 上传到服务 | 客户的 blob 存储帐户 | ||||||||||||||||||||||||||||||||||||
| 模型托管 | 云和边缘 | 仅云托管,边缘容器托管即将推出 | ||||||||||||||||||||||||||||||||||||
| AI 质量 |
|
|
||||||||||||||||||||||||||||||||||||
| 定价 | 自定义视觉定价 | 图像分析定价 |
方案组件
模型自定义系统的主要组件是训练图像、COCO 文件、数据集对象和模型对象。
训练图像
训练图像集应包含要检测的每个标签的多个示例。 此外还需要收集一些额外的图像,以便在训练后测试模型。 图像需要存储在 Azure 存储容器中,以便模型可以访问。
为了有效地训练模型,请使用具有视觉多样性的图像。 选择在以下方面有所不同的图像:
- 照相机角度
- 照明
- background
- 视觉样式
- 个人/分组主题
- 大小
- type
此外,请确保所有训练图像满足以下条件:
- 图像必须以 JPEG、PNG、GIF、BMP、WEBP、ICO、TIFF 或 MPO 格式显示。
- 图像的文件大小必须小于 20 MB。
- 图像的尺寸必须大于 50 x 50 像素,小于 16,000 x 16,000 像素。
COCO 文件
COCO 文件引用所有训练图像,并将其与其标记信息相关联。 对于对象检测,它指定每个图像上每个标记的边界框坐标。 此文件必须采用 COCO 格式,这是特定类型的 JSON 文件。 COCO 文件应与训练映像存储在同一 Azure 存储容器中。
提示
关于 COCO 文件
COCO 文件是包含特定必填字段的 JSON 文件:"images"、"annotations" 和 "categories"。 示例 COCO 文件如下所示:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
COCO 文件字段引用
如果要从头开始生成自己的 COCO 文件,请确保所有必填字段都填充了正确的详细信息。 下表描述了 COCO 文件中的每个字段:
“图像”
| 密钥 | 类型 | 说明 | 必需? |
|---|---|---|---|
id |
integer | 唯一图像 ID,从 1 开始 | 是 |
width |
integer | 图像的宽度(以像素为单位) | 是 |
height |
integer | 图像的高度(以像素为单位) | 是 |
file_name |
字符串 | 图像的唯一名称 | 是 |
absolute_url 或 coco_url |
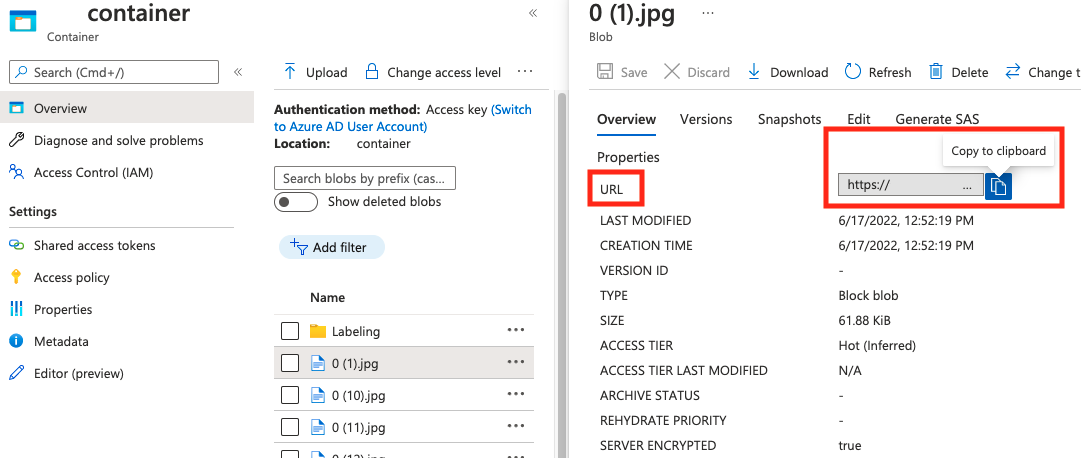
字符串 | 用作 Blob 容器中 Blob 的绝对 URI 的图像路径。 视觉资源必须有权读取注释文件和所有引用的图像文件。 | 是 |
可以在 Blob 容器的属性中找到 absolute_url 的值:
“注释”
| 密钥 | 类型 | 说明 | 必需? |
|---|---|---|---|
id |
integer | 注释的 ID | 是 |
category_id |
integer | categories 部分中定义的类别的 ID |
是 |
image_id |
integer | 图像的 ID | 是 |
area |
integer | “宽度”x“高度”的值(bbox 的第三和第四个值) |
否 |
bbox |
list[float] | 边界框的相对坐标(0 到 1),按“左”、“上”、“宽度”、“高度”的顺序排列 | 是 |
“类别”
| 密钥 | 类型 | 说明 | 必需? |
|---|---|---|---|
id |
integer | 每个类别(标签类)的唯一 ID。 这些内容应出现在 annotations 部分中。 |
是 |
name |
字符串 | 类别(标签类)的名称 | 是 |
COCO 文件验证
可以使用 Python 示例代码检查 COCO 文件的格式。
数据集对象
数据集对象是由引用关联文件的图像分析服务存储的数据结构。 需要先创建数据集对象,然后才能创建和训练模型。
Model 对象
模型对象是由表示自定义模型的图像分析服务存储的数据结构。 它必须与数据集相关联才能执行初始训练。 训练后,可以通过在分析图像 API 调用的 model-name 查询参数中输入模型名称来查询模型。
配额限制
下表描述了自定义模型项目的规模限制。
| 类别 | 通用图像分类器 | 通用对象检测器 |
|---|---|---|
| 最大训练小时数 | 288(12天) | 288(12天) |
| 最大训练图像数 | 1,000,000 | 200,000 |
| 最大评估图像数 | 100,000 | 100,000 |
| 每个类别的最少训练图像数 | 2 | 2 |
| 每个图像的最大标记数 | 多类:1 | NA |
| 每个图像的最大区域数 | NA | 1,000 |
| 最大类别数 | 2,500 | 1,000 |
| 最少类别数 | 2 | 1 |
| 最大图像大小(训练) | 20 MB | 20 MB |
| 最大图像大小(预测) | 同步:6 MB,批处理:20 MB | 同步:6 MB,批处理:20 MB |
| 最大图像宽度/高度(训练) | 10,240 | 10,240 |
| 最小图像宽度/高度(预测) | 50 | 50 |
| 可用区域 | 美国西部 2、美国东部、西欧 | 美国西部 2、美国东部、西欧 |
| 接受的图像类型 | jpg、png、bmp、gif、jpeg | jpg、png、bmp、gif、jpeg |
常见问题
从 Blob 存储导入时,为什么 COCO 文件导入失败?
目前,Microsoft 正着手解决在 Vision Studio 中启动时大型数据集的 COCO 文件导入失败这一问题。 若要使用大型数据集进行训练,建议改用 REST API。
为什么训练花费的时间比指定的预算长/短?
指定的训练预算是校准的计算时间,而不是时钟时间。 差异的一些常见原因如下:
长于指定预算:
- 图像分析的训练流量较高,GPU 资源可能十分紧张。 作业可能在队列中等待或在训练期间被搁置。
- 后端训练过程遇到意外故障,导致重试逻辑。 失败的运行不会消耗预算,但这通常会导致训练时间更长。
- 数据存储在与视觉资源不同的区域中,这将导致数据传输时间更长。
短于指定预算:以下因素可加快训练速度,但代价是在某些时钟时间使用更多预算。
- 图像分析有时使用多个 GPU 进行训练,具体取决于数据。
- 图像分析有时会在多个 GPU 上同时训练多个探索试验。
- 图像分析有时使用顶级(更快的)GPU SKU 进行训练。
为什么我的训练失败了?我该怎么做?
下面是训练失败的一些常见原因:
diverged:训练无法从数据中学习有意义的内容。 一些常见原因如下:- 数据不够:提供更多数据应该会有所帮助。
- 数据质量不佳:检查是否图像分辨率低、纵横比过大或者注释错误。
notEnoughBudget:指定的预算不足以满足正在训练的数据集和模型类型的大小。 请指定更大的预算。datasetCorrupt:通常,这意味着你提供的图像无法访问,或者注释文件的格式不正确。datasetNotFound:找不到数据集unknown:这可能是后端问题。 请联系支持人员进行调查。
哪些指标用于评估模型?
使用以下指标:
- 图像分类:平均精度、准确度前 1、准确度前 5
- 对象检测:平均精度均值 @ 30、平均精度均值 @ 50、平均精度均值 @ 75
为什么我的数据集注册失败?
API 响应应提供足够的信息。 它们是:
DatasetAlreadyExists:存在具有相同名称的数据集DatasetInvalidAnnotationUri:在数据集注册时注释 URI 中提供了无效的 URI。
合理/良好/最佳模型质量需要多少个图像?
尽管 Florence 模型具有少样本学习功能(在可用数据有限的情况下实现出色模型性能),但是总体而言,数据越多,所训练的模型更好、更可靠。 一些场景需要的数据很少(例如,将苹果与香蕉分类),但有些场景需要更多数据(例如,在热带雨林中检测 200 种昆虫)。 这使得很难提供单个建议。
如果数据标记预算受到限制,则建议重复以下步骤:
按类收集
N图像,其中N图像易于收集(例如N=3)训练模型并在评估集上对其进行测试。
如果模型性能:
- 足够好(性能优于预期,或者性能接近上一个试验,但收集的数据较少):请在此处停止并使用此模型。
- 不佳(性能仍然低于预期,或者优于之前的试验,但在合理的范围内收集的数据较少):
- 为每个类收集更多图像(一个易于收集的数字),然后返回到步骤 2。
- 如果发现几次迭代后性能仍未改善,可能是因为:
- 此问题定义不明确或太难。 请联系我们进行个案分析。
- 训练数据的质量可能较低:检查是否存在注释错误或者像素非常低的图像。
应指定多少培训预算?
应指定你愿意消耗的预算上限。 图像分析在其后端使用 AutoML 系统来尝试不同的模型和训练配方,以查找最适合你的用例的模型。 提供的预算越多,找到更好模型的机会就越大。
如果 AutoML 系统认为没有必要再次尝试,则即使仍有剩余预算,它也会自动停止。 因此,它并不总是耗尽指定的预算。 保证不会向你收取超出指定预算的费用。
是否可以控制超参数或在训练中使用自己的模型?
否,图像分析模型自定义服务使用低代码 AutoML 训练系统,该系统在后端处理超参数搜索和基本模型选择。
训练后是否可以导出模型?
仅通过云服务支持预测 API。
为什么我的对象检测模型评估失败?
可能的原因如下:
internalServerError:发生未知错误。 请稍后再试。modelNotFound:找不到指定的模型。datasetNotFound:找不到指定的数据集。datasetAnnotationsInvalid:尝试下载或分析与测试数据集关联的标定真实注释时出错。datasetEmpty:测试数据集不包含任何“标定真实”注释。
使用自定义模型进行预测的预期延迟是多少?
不建议将自定义模型用于业务关键型环境,因为可能发生较高延迟。 当客户在 Vision Studio 中训练自定义模型时,这些自定义模型属于在其下训练它们的 Azure AI 视觉资源,客户可以使用分析图像 API 调用这些模型。 当它们进行这些调用时,自定义模型将加载到内存中,并初始化预测基础结构。 发生这种情况时,客户在接收预测结果时可能会经历比预期更长的延迟。
数据隐私和安全性
与所有 Azure AI 服务一样,使用图像分析模型自定义的开发人员应该了解 Microsoft 针对客户数据的策略。 请参阅 Microsoft 信任中心的“Azure AI 服务”页面来了解详细信息。