你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
什么是图像分析?
Azure AI 视觉图像分析服务可以从图像中提取各种视觉特征。 例如,该服务可以确定图像是否包含成人内容、查找特定的品牌或对象,或查找人脸。
最新版本的图像分析(4.0 现已正式发布)具有同步 OCR 和人员检测等新功能。 我们建议你继续使用此版本。
你可以通过客户端库 SDK,或者直接调用 REST API 使用图像分析。 按快速入门的说明开始使用。
或者,可以使用 Vision Studio 快速轻松地在浏览器中试用图像分析的功能。
本文档包含以下类型的文章:
- 快速入门是分步说明,可按照其调用服务,并在短时间内获得结果。
- 操作指南包含以更具体的方式或自定义方式使用服务的说明。
- 概念性文章对服务的功能和特性进行了深入说明。
- 教程是较长的指南,向你演示了如何在更广泛的业务解决方案中使用此服务作为组件。
如果需要更加结构化的方法,请遵循适用于图像分析的训练模块。
图像分析版本
重要
选择最符合要求的图像分析 API 版本。
| 版本 | 可用的功能 | 建议 |
|---|---|---|
| 4.0 版 | 读取文本, 描述文字, 细致说明, 标记, 物体检测, 自定义图像分类/物体检测, 人员, 智能裁剪 | 更出色的模型;如果版本 4.0 支持你的用例,请使用该版本。 |
| 版本 3.2 | 标记, 物体, 说明, 品牌, 人脸, 图像类型, 配色方案, 地标, 名人, 成人内容, 智能裁剪 | 更广泛的功能;如果版本 4.0 尚不支持你的用例,请使用版本 3.2 |
如果图像分析 4.0 API 支持你的用例,我们建议使用该版本。 如果版本 4.0 尚不支持你的用例,请使用版本 3.2。
如果要生成图像描述文字,并且你的视觉资源位于以下 Azure 区域之外,则也需要使用版本 3.2:美国东部、法国中部、韩国中部、北欧、东南亚、西欧、美国西部、东亚。 图像分析 4.0 中的图像描述文字生成功能仅适用于这些 Azure 地区。 版本 3.2 中的图像描述文字生成适用于所有 Azure AI 视觉区域。
分析图像
可以分析图像,以便提供有关视觉特性和特征的见解。 此列表中的所有特性均由分析图像 API 提供。 按快速入门的说明开始操作。
| 名称 | 说明 | 概念页 |
|---|---|---|
| 模型自定义(仅限 4.0 预览版) | 你可以创建和训练自定义模型,以进行图像分类或物体检测。 请自带图像,并为这些图像添加自定义标记。图像分析将会训练出一个为你的用例量身定制的模型。 | 模型自定义 |
| 从图像读取文本(仅限 v4.0) | 图像分析 4.0 预览版可从图像中提取可读文本。 与异步计算机视觉 3.2 读取 API 相比,新版本作为性能增强的统一同步 API 提供了熟悉的读取 OCR 引擎,这样便可通过单个 API 调用轻松获取 OCR 和其他见解。 | 图像 OCR |
| 检测图像中的人物(仅限 v4.0) | 图像分析版本 4.0 提供检测图像中人员的功能。 将返回检测到的每个人物的边界框坐标以及置信度分数。 | 人物检测 |
| 生成图像描述文字 | 以人类能够读懂的语言生成图像的描述文字,并采用完整句子的形式。 计算机视觉的算法将根据在图像中识别的物体生成各种描述文字。 版本 4.0 的图像描述文字生成模型是一种更高级的实现,适用于更广泛的输入图像。 该模型仅在以下地区可用:美国东部、法国中部、韩国中部、欧洲北部、东南亚、欧洲西部、美国西部。 版本 4.0 还允许使用密集描述文字生成,可为图像中的各个物体生成详细的描述文字。 该 API 会返回图像中每个物体的边界框坐标(以像素为单位)以及一段描述文字。 你可以使用此功能生成有关图像各个部分的说明。 
|
生成图像描述文字 (v3.2) (v4.0) |
| 检测物体 | 对象检测类似于添加标记,但 API 返回应用于每个标记的边框坐标。 例如,如果图像包含狗、猫和人,检测操作将列出这些对象及其在图像中的坐标。 可以使用此功能进一步处理图像中各对象之间的关系。 当图像中有多个相同标记的实例时,还会通知你。 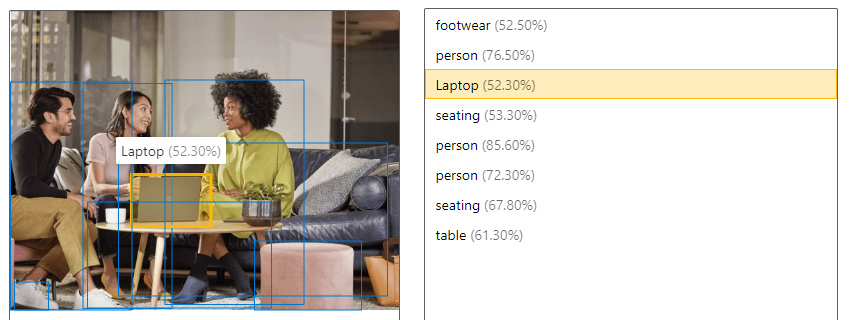
|
检测物体 (v3.2) (v4.0) |
| 标记视觉特性 | 根据数千个可识别对象、生物、风景和操作识别并标记图像中的视觉特征。 如果标记含混不清或者不常见,API 响应会做出提示,阐明上下文或标记。 标记并不局限于主体(如前景中的人员),还包括设置(室内或室外)、家具、工具、植物、动物、附件、小配件等。
|
标记视觉特性 (v3.2) (v4.0) |
| 获取感兴趣区域/智能裁剪 | 分析图像的内容以返回与指定纵横比匹配的感兴趣区域的坐标。 计算机视觉返回该区域的边框坐标,因此,进行调用的应用程序可以根据需要修改原始图像。 版本 4.0 的智能裁剪模型是一种更高级的实现,适用于更广泛的输入图像。 该模型仅在以下地区可用:美国东部、法国中部、韩国中部、欧洲北部、东南亚、欧洲西部、美国西部。 |
生成缩略图 (v3.2) (v4.0 预览版) |
| 检测品牌(仅限版本 3.2) | 根据一个包含数千全球徽标的数据库,确定图像或视频中的商业品牌。 可以使用此功能来执行特定的操作,例如,发现哪些品牌在社交媒体上最受欢迎,或者哪些品牌在社交产品排名上最靠前。 | 检测品牌 |
| 对图像进行分类(仅限版本 3.2) | 使用具有父/子遗传层次结构的类别分类对整个图像进行标识和分类。 类别可单独使用或与我们的新标记模型结合使用。 目前,英语是唯一可以对图像进行标记和分类的语言。 |
对图像分类 |
| 检测人脸(仅限版本 3.2) | 检测图像中的人脸,提供每个检测到的人脸的相关信息。 Azure AI 视觉可返回每个检测到的人脸的坐标、矩形、性别和年龄。 还可以将专用人脸 API 用于这些目的。 它提供更详细的分析,如面部识别和姿势检测。 |
检测人脸 |
| 检测图像类型(仅限版本 3.2) | 检测图像特征,例如图像是否为素描,或者图像是剪贴画的可能性。 | 检测图像类型 |
| 检测特定领域的内容(仅限版本 3.2) | 使用域模型来检测和标识图像中特定领域的内容,例如名人和地标。 例如,如果图像中包含人物,Azure AI 视觉可以使用针对名人的域模型来确定图像中检测到的人物是否为已知名人。 | 检测特定领域的内容 |
| 检测配色方案(仅限版本 3.2) | 分析图像中的颜色使用情况。 Azure AI 视觉可以确定图像是黑白的还是彩色的,也可以确定彩色图像的主要颜色和强调色。 | 检测颜色方案 |
| 审查图像中的内容(仅限版本 3.2) | 可使用 Azure AI 视觉来检测图像中的成人内容,并返回不同分类的置信度分数。 可以在滑尺上设置标记内容的阈值,以适应首选项。 | 检测成人内容 |
提示
可以通过 Azure OpenAI 服务使用图像分析的“读取文本”和“物体检测”功能。 使用 GPT-4 Turbo with Vision 模型,可以与能够分析所共享图像的 AI 助手聊天,并且视觉增强选项使用可图像分析为 AI 助手提供有关图像的更多详细信息(可读文本和对象位置)。 有关详细信息,请参阅 GPT-4 Turbo with Vision 快速入门。
产品识别(仅限 v4.0 预览版)
借助产品识别 API,可以分析零售商店中货架的照片。 可以检测产品是否存在,并获取其边界框坐标。 将其与模型自定义结合使用,以训练模型来识别特定产品。 还可以将产品识别结果与商店的货架图文档进行比较。
多模式嵌入(仅限 v4.0)
多模式嵌入 API 支持对图像和文本查询进行矢量化。 这些 API 可将图像转换为多维矢量空间中的坐标。 然后,传入的文本查询也可以转换为矢量,并且图像可以根据语义接近度与文本进行匹配。 这样,用户使用文本就能搜索一组图像,而无需使用图像标记或其他元数据完成这一操作。 语义接近通常会在搜索中产生更好的结果。
2024-02-01 API 包括一个支持通过 102 种语言进行文本搜索的多语言模型。 初始的纯英文模型仍然可用,但不能与同一搜索索引中的新模型组合使用。 如果你使用纯英文模型对文本和图像进行了矢量化,则这些矢量将与多语言文本和图像矢量不兼容。
这些 API 仅在以下地区可用:美国东部、法国中部、韩国中部、欧洲北部、东南亚、欧洲西部、美国西部。
背景移除(仅限 4.0 预览版)
图像分析 4.0(预览版)提供了移除图像背景的功能。 此功能可以输出检测到的前景物体的图像(具有透明背景),也可以输出显示检测到的前景物体的不透明度的灰度 alpha 哑光图像。
| 原始图像 | 移除背景后 | 前景蒙版 |
|---|---|---|

|

|

|
图像要求
图像分析可以处理符合以下要求的图像:
- 图像必须以 JPEG、PNG、GIF、BMP、WEBP、ICO、TIFF 或 MPO 格式显示
- 图像的文件大小必须不到 20 兆字节 (MB)
- 图像的尺寸必须大于 50 x 50 像素,小于 16,000 x 16,000 像素
提示
多模式嵌入的输入要求有所不同,已在多模式嵌入中列出
数据隐私和安全性
与所有 Azure AI 服务一样,使用 Azure AI 视觉服务的开发人员应了解 Microsoft 关于客户数据的策略。 请参阅 Microsoft 信任中心上的“Azure AI 服务”页面来了解详细信息。
后续步骤
参阅使用首选开发语言的快速入门指南,开始使用图像分析: