你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
什么是自定义神经语音?
神经网络定制声音 (CNV) 是一种文本转语音功能,可用于为应用程序创建独一无二的定制合成声音。 借助神经网络定制声音,可以通过提供人类语音样本作为训练数据来为品牌或角色生成听起来非常自然的声音。
现成的文字转语音可以与每种受支持的语言的预生成神经语音一起使用。 如果不需要独特的语音,则预生成的神经网络语音在大多数文本转语音方案中都能很好地工作。
神经网络定制声音基于神经文本转语音技术和多语言、多说话人的通用模型。 你可以创建具有丰富说话风格或适应性十足的跨语言的合成语音。 神经网络定制声音逼真的自然语音可以表示品牌、拟人化算机,并支持用户与应用程序以对话方式进行交互。 请参阅自定义神经语音支持的语言。
它是如何工作的?
若要创建自定义神经声音,请使用 Speech Studio 上传录制的音频和相应的脚本,训练模型,然后将语音部署到自定义终结点。
提示
在投资专业录音以创建更高质量的语音之前,可试用神经网络定制声音 (CNV) 精简版来演示和评估 CNV。
要创建优秀的神经网络定制声音,就需要在从语音设计和数据准备到将声音模型部署到系统的每个步骤中,仔细进行质量控制。
在开始使用 Speech Studio 之前,需要注意以下事项:
- 使用角色简介文档设计表示你的品牌的一种声音角色。 本文档定义了一些元素,如声音功能和声音后面的字符。 这样有助于指导神经网络定制声音模型的创建过程,包括定义脚本、选择发音人、训练和声音优化。
- 选择表示语音的用户方案的录制内容脚本。 例如,如果要创建客户服务机器人,可使用机器人会话中的短语作为录制内容的脚本。 在脚本中包括不同的语句类型,包括陈述句、疑问句和感叹句。
下面概述了在 Speech Studio 中创建神经网络定制声音的步骤:
- 创建一个项目来包含你的数据、语音模型、测试和终结点。 每个项目特定于一个国家/区域和语言。 如果要创建多个语音,建议为每个语音创建一个项目。
- 设置发音人。 在训练神经语音之前,必须提交发音人的同意声明的录音。 发音人声明是发音人阅读同意使用其语音数据来训练自定义语音模型的声明的记录。
- 以正确的格式准备训练数据。 最好在专业的录音棚中捕获录音内容,以获得较高的信噪比。 声音模型的质量很大程度取决于你的训练数据。 需要一致的音量、语速、音调和一致的语音表达风格。
- 训练你的声音模型。 至少选择 300 个语句才能创建神经网络定制声音。 上传后,系统会自动执行一系列数据质量检查。 若要生成高质量的声音模型,应修复所有错误并再次提交。
- 测试你的声音。 为声音模型准备测试脚本,其中应涵盖应用的不同用例。 最好在训练数据集内部和外部使用脚本,以便可以更广泛地测试不同内容的质量。
- 在应用中部署和使用你的声音模型。
你可以优化、调整和使用自定义语音,就像使用预生成的神经语音一样。 实时将文本转换为语音,或者使用文本输入来脱机生成音频内容。 使用 REST API、语音 SDK或 Speech Studio。
经过训练的声音模型的风格和特征取决于用于训练的发音人的录音风格和质量。 但在向声音模型发出 API 调用以生成合成语音时,可使用 SSML(语音合成标记语言)进行几项调整。 SSML 是标记语言,用于与文本转语音服务通信以将文本转换为音频。 可以进行的调整包括改变音调、语速、声调和发音纠正。 如果声音模型是用多种风格生成的,也可使用 SSML 来切换风格。
组件序列
神经网络定制声音包括三个主要组件:文本分析器、神经网络声学模型和神经网络声码器。 为了从文本生成自然合成语音,文本会首先输入到文本分析器中,后者以音素序列的形式提供输出。 音素是一种基本声音单位,可区分特定语言中的不同字词。 音素序列定义文本中提供的字词的发音。
接下来,音素序列会进入神经网络声学模型,以预测定义语音信号的声学特征。 声学特征包括音色、说话风格、语速、语调和重音模式。 最后,神经网络声码器会将声学特性转换为可听见的波形,以便生成合成语音。
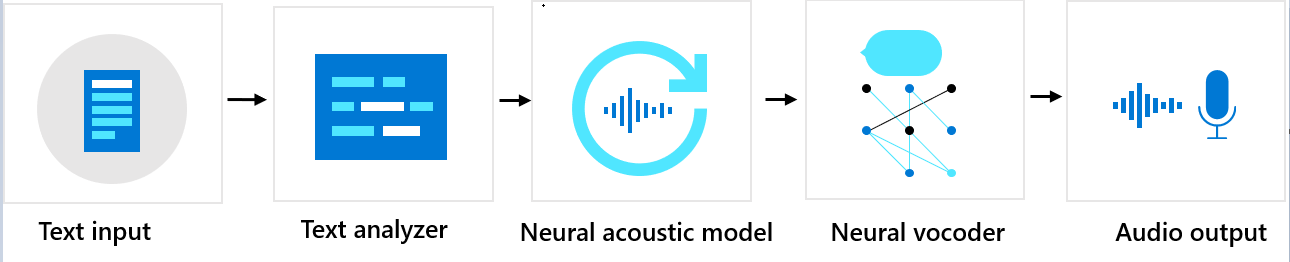
神经网络文本转语音模型基于人类声音的录制样本,使用深度神经网络进行训练。 有关详细信息,请参阅此 Microsoft 博客文章。 若要详细了解如何训练神经网络声码器,请参阅此 Microsoft 博客文章。
迁移到自定义神经语音
如果使用的是旧版本的自定义语音(该版本计划将于 2024 年 2 月停用),请参阅如何迁移到神经网络定制声音。
负责任 AI
AI 系统不仅包括技术,还包括使用它的人员、受其影响的人员以及部署它的环境。 阅读透明度说明,了解如何在系统中负责任地使用和部署 AI。
- 神经网络定制声音的透明度说明和用例
- 使用神经网络定制声音的特征和限制
- 对神经网络定制声音的受限访问
- 合成语音技术的负责任的部署指南
- 针对发音人披露
- 披露设计准则
- 披露设计模式
- 文本转语音集成的行为准则
- 神经网络定制声音的数据、隐私和安全性