你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
什么是自定义语音识别?
借助自定义语音识别可以评估并改善应用程序与产品的语音识别准确度。 自定义语音模型可用于实时语音转文本、语音翻译和批量听录。
现成的语音识别可利用通用语言模型作为一个基本模型(使用 Microsoft 自有数据进行训练),并反映常用的口语。 此基础模型使用那些代表各常见领域的方言和发音进行了预先训练。 发出语音识别请求时,默认使用每个支持的语言的最新基础模型。 基础模型在大多数语音识别场景中都效果良好。
通过提供文本数据来训练模型,自定义模型可用于扩充基本模型,以提高对特定于应用程序的特定领域词汇的识别。 它还可用于通过为音频数据提供参考听录内容,来改进基于应用程序的特定音频条件的识别。
当数据遵循某个模式时,你还可以使用结构化文本来训练模型,以指定自定义发音,并使用自定义反向文本规范化、自定义重写和自定义脏话过滤来自定义显示文本格式。
它是如何工作的?
使用自定义语音识别,你可以上传自己的数据、测试和训练自定义模型、比较模型之间的准确度,以及将模型部署到自定义终结点。
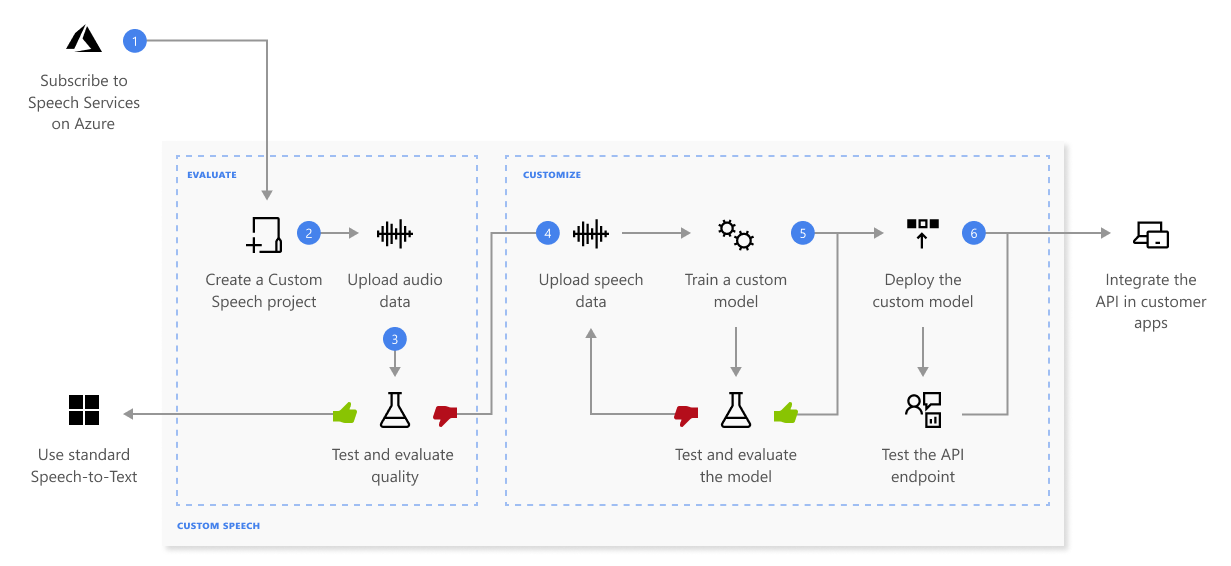
下面详细介绍了上述关系图显示的步骤序列:
- 创建项目并选择模型。 使用你在 Azure 门户中创建的语音资源。 如果要使用音频数据训练自定义模型,请选择具备语音数据训练专用硬件的语音资源区域。 有关详细信息,请参阅区域表中的脚注。
- 上传测试数据。 上传测试数据,以便针对你的应用程序、工具和产品评估语音转文本产品/服务。
- 测试识别质量。 使用 Speech Studio 播放上传的音频,检查测试数据的语音识别质量。
- 量化测试模型。 评估和提高语音转文本模型的准确度。 语音服务会提供定量的字词错误率 (WER),该指标可以用来确定是否需要更多的训练。
- 训练模型。 提供书面脚本和相关文本以及相应的音频数据。 可以选择在训练之前和之后测试模型,但建议这样做。
注意
你将为自定义语音识别模型使用量和终结点托管付费。 如果基础模型创建于 2023 年 10 月 1 日及之后,则还需要为自定义语音识别模型训练付费。 如果基础模型是在 2023 年 10 月之前创建的,则无需支付训练费用。 有关详细信息,请参阅 Azure AI 语音定价和语音转文本 3.2 迁移指南中的适配收费部分。
- 部署模型。 对测试结果感到满意后,将模型部署到自定义终结点。 除了批量听录之外,还必须部署自定义终结点才能使用自定义语音模型。
负责任的 AI
AI 系统不仅包括技术,还包括使用它的人员、受其影响的人员以及部署它的环境。 阅读透明度说明,了解如何在系统中负责任地使用和部署 AI。