Microsoft Purview 中的扫描和引入
本文概述了 Microsoft Purview 中的扫描和引入功能。 这些功能将 Microsoft Purview 帐户连接到源,以填充数据映射和数据目录,以便你可以开始通过 Microsoft Purview 浏览和管理数据。
- 扫描 从 数据源 捕获元数据并将其带到 Microsoft Purview。
- 引入处理 元数据并将其存储在数据目录中,这两者都包括:
- 数据源扫描 - 扫描的元数据将添加到Microsoft Purview 数据映射。
- 世系连接 - 转换资源将有关其源、输出和活动的元数据添加到Microsoft Purview 数据映射。
扫描
在 Microsoft Purview 帐户中 注册 数据源后,下一步是扫描数据源。 扫描过程与数据源建立连接,并捕获技术元数据,如名称、文件大小、列等。 它还提取结构化数据源的架构,对架构应用分类,并在Microsoft Purview 数据映射连接到Microsoft Purview 合规门户时应用敏感度标签。 扫描过程可以立即触发,也可以计划定期运行,以使 Microsoft Purview 帐户保持最新状态。
对于每次扫描,可以应用自定义项,以便仅扫描所需的信息,而不是整个源。
为扫描选择身份验证方法
默认情况下,Microsoft Purview 是安全的。 没有密码或机密直接存储在 Microsoft Purview 中,因此你需要为源选择身份验证方法。 可通过多种可能的方法对 Microsoft Purview 帐户进行身份验证,但并非每个数据源都支持所有方法。
- 托管标识
- 服务主体
- SQL 身份验证
- Windows 身份验证
- 角色 ARN
- 委托身份验证
- 使用者密钥
- 帐户密钥或基本身份验证
尽可能使用托管标识作为首选身份验证方法,因为它无需存储和管理单个数据源的凭据。 这可以大大减少你和你的团队在设置和排查扫描身份验证问题时花费的时间。 为 Microsoft Purview 帐户启用托管标识时,标识在 Azure Active Directory 中创建,并绑定到帐户的生命周期。
确定扫描范围
扫描源时,可以选择扫描整个数据源,或仅选择特定实体 (文件夹/表) 进行扫描。 可用选项取决于要扫描的源,并且可以为一次性扫描和计划扫描定义。
例如,在为Azure SQL数据库创建和运行扫描时,可以选择要扫描的表或选择整个数据库。
对于每个实体 (文件夹/表) ,将有三种选择状态:完全选择、部分选择和未选择。 在下面的示例中,如果在文件夹层次结构中选择“部门 1”,则“部门 1”被视为完全选定。 “部门 1”的父实体(如“公司”和“示例”)被视为部分选定,因为同一父级下的其他实体尚未选择,例如“部门 2”。 对于具有不同选择状态的实体,UI 上将使用不同的图标。
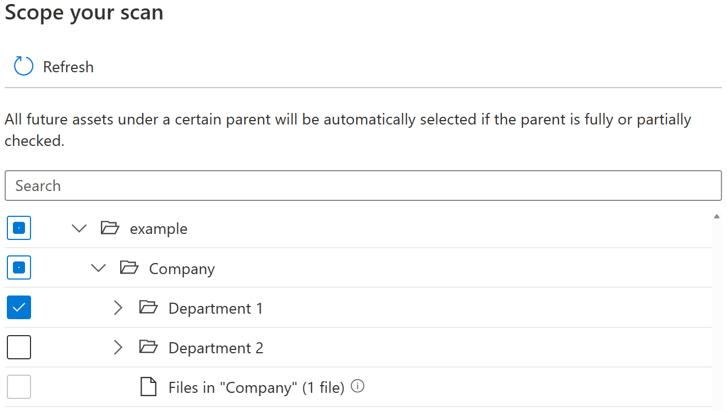
运行扫描后,源系统中可能会添加新资产。 默认情况下,如果在再次运行扫描时完全或部分选择了父级,则将自动选择某个父级下的未来资产。 在上面的示例中,选择“部门 1”并运行扫描后,再次运行扫描时,将包括文件夹“Department 1”下或“公司”和“示例”下的任何新资产。
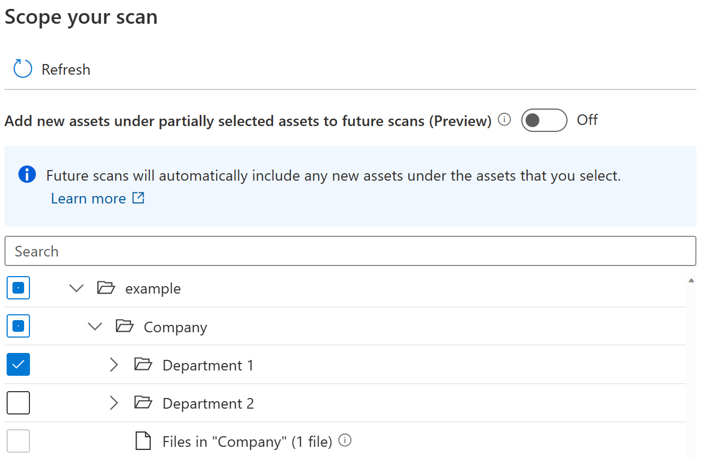
引入了切换按钮,供用户控制部分选定父级下新资产的自动包含。 默认情况下,关闭切换开关,并禁用部分选定父级的自动包含行为。 在关闭切换开关的同一示例中,再次运行扫描时,部分选择的父级下的任何新资产(如“公司”和“示例”)将不包括,将来的扫描中只会包含“部门 1”下的新资产。
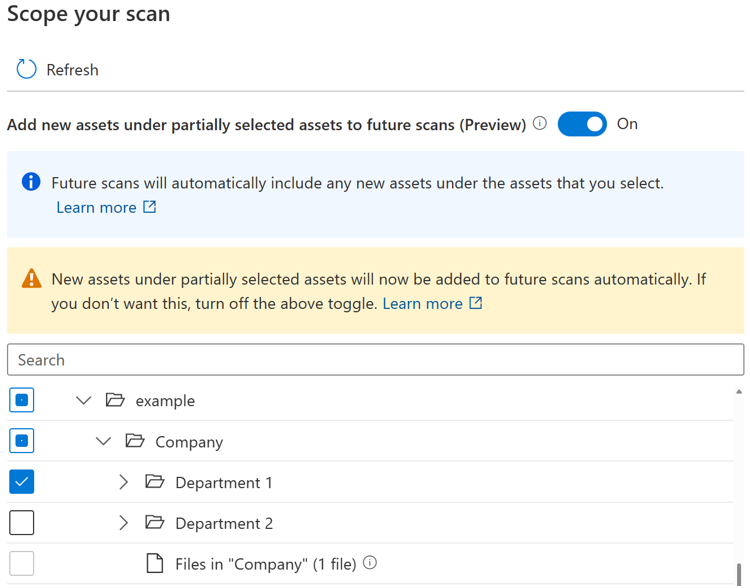
如果打开切换按钮,则当你再次运行扫描时,如果父级已完全或部分选择,则会自动选择某个父级下的新资产。 包含行为将与引入切换按钮之前相同。
注意
- 切换按钮的可用性取决于数据源类型。 目前,它以公共预览版提供,包括 Azure Blob 存储、Azure Data Lake Storage Gen 1、Azure Data Lake Storage Gen 2、Azure 文件存储 和 Azure 专用 SQL 池 (以前是 SQL DW) 。
- 对于在引入切换按钮之前创建或计划的任何扫描,切换状态设置为“打开”且无法更改。 对于在引入切换按钮后创建或计划的任何扫描,在保存扫描后无法更改切换状态。 需要创建新的扫描才能更改切换状态。
- 关闭切换按钮后,对于存储类型的源(如 Azure Data Lake Storage Gen 2),可能需要长达 4 小时才能在扫描作业完成后,按源类型浏览体验完全可用。
已知限制
关闭切换按钮时:
- 不会扫描部分选定父级下的文件实体。
- 如果显式选择了父级下的所有现有实体,则父级将被视为完全选定,并且再次运行扫描时,将包含父级下的所有新资产。
扫描规则集
扫描规则集确定扫描针对其中一个源运行时将查找的信息类型。 可用规则取决于要扫描的源类型,但包括应扫描的 文件类型 以及所需的 分类 类型等内容。
系统 扫描规则集 已可用于许多数据源类型,但你也可以 创建自己的扫描规则集 ,以便为组织定制扫描。
计划扫描
Microsoft Purview 让你可以选择在所选的特定时间每周或每月扫描一次。 每周扫描可能适用于具有积极开发或经常更改的结构的数据源。 每月扫描更适合不经常更改的数据源。 最佳做法是与要扫描的源的管理员合作,确定源上的计算需求较低的时间。
扫描如何检测已删除的资产
Microsoft Purview 目录仅在运行扫描时知道数据存储的状态。 要使目录知道文件、表或容器是否已删除,它会将上次扫描输出与当前扫描输出进行比较。 例如,假设上次扫描Azure Data Lake Storage Gen2帐户时,该帐户包含名为 folder1 的文件夹。 再次扫描同一帐户时, 缺少 folder1 。 因此,目录假定文件夹已被删除。
检测已删除的文件
检测缺失文件的逻辑适用于同一用户和不同用户的多次扫描。 例如,假设用户对文件夹 A、B 和 C 上的Data Lake Storage Gen2数据存储运行一次性扫描。稍后,同一帐户中的其他用户对同一数据存储的文件夹 C、D 和 E 运行不同的一次性扫描。 由于文件夹 C 已扫描两次,因此目录会检查其是否可能删除。 但是,仅扫描一次文件夹 A、B、D 和 E,目录不会为已删除的资产检查它们。
若要将已删除的文件保留在目录中,请务必定期运行扫描。 扫描间隔很重要,因为目录在运行另一个扫描之前无法检测到已删除的资产。 因此,如果每月在特定存储中运行一次扫描,则在一个月后运行下一次扫描之前,目录无法检测该存储中的任何已删除的数据资产。
枚举大型数据存储(如 Data Lake Storage Gen2)时,有多种方法 (包括枚举错误和丢失信息) 删除的事件。 特定扫描可能会错过创建或删除文件。 因此,除非目录确定文件已删除,否则它不会从目录中删除该文件。 此策略意味着,如果扫描的数据存储中不存在的文件仍存在于目录中,则可能存在错误。 在某些情况下,可能需要对数据存储进行两次或三次扫描,然后才能捕获某些已删除的资产。
注意
- 标记为要删除的资产在成功扫描后被删除。 在处理和删除已删除资产之前,已删除的资产可能会在目录中持续显示一段时间。
- 目前,以下源不支持源删除检测:Azure Databricks、Amazon Redshift、Cassandra、DB2、Erwin、Google BigQuery、Hive 元存储、Looker、MongoDB、MySQL、Oracle、PostgreSQL、Salesforce、SAP BW、SAP ECC、SAP HANA、SAP S/4HANA、Snowflake 和 Teradata。 从数据源中删除对象后,后续扫描不会自动删除 Microsoft Purview 中的相应资产。
摄入
引入是负责使用通过各种进程收集的元数据填充数据映射的过程。
从扫描引入
然后,扫描过程标识的技术元数据或分类将发送到引入。 引入分析扫描中的输入, 应用资源集模式,填充可用的 世系 信息,然后自动加载数据映射。 只有在引入完成后,才能发现或策展资产/架构。 因此,如果扫描已完成,但尚未在数据映射或目录中看到资产,则需要等待引入过程完成。
从世系连接引入
Azure 数据工厂和Azure Synapse等资源可以连接到 Microsoft Purview,将数据源和世系信息引入Microsoft Purview 数据映射。 例如,当复制管道在已连接到 Microsoft Purview 的Azure 数据工厂中运行时,有关输入源、活动和输出源的元数据将在 Microsoft Purview 中引入,并将信息添加到数据映射中。
如果已通过扫描将数据源添加到数据映射,则有关该活动的世系信息将添加到现有源。 如果数据源尚未添加到数据映射,则世系引入过程会将其及其世系信息添加到根集合。
有关可用世系连接的详细信息,请参阅 世系用户指南。
后续步骤
有关详细信息或有关扫描源的具体说明,请遵循以下链接。
- 若要了解资源集,请参阅 资源集一文。
- 如何管理Azure SQL数据库
- Microsoft Purview 中的世系
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈