您可以通过遵循与预构建指标相同的模式,扩展定义和计算自定义指标的能力。
生成聚合表
根据您要计算的指标,以下两种场景中的一种适用。 按照适用于您的场景的步骤操作。
场景 1
预构建的聚合表支持所需的测量数据和维度集,因此无需对聚合表进行修改。
按照生成聚合表中的说明生成预构建聚合表。
刷新 DatasetForMetricsMeasures_DTST 语义模型。
场景 2
预构建聚合表支持所需的测量数据,但缺少所需的维度。
通过更新包含聚合表计算逻辑的记事本中的计算逻辑,向预构建聚合表添加所需的维度。 例如,如果 EmissionsAggregate 表的计算逻辑需要更新,则更新 CreateAggregateForEmissionsMetrics_INTB 中的逻辑。
运行包含更新后计算逻辑的记事本以生成聚合表。
备注
不要删除预构建聚合表中的任何现有维度,以避免影响预构建指标的计算。
在 DatasetForMetricsMeasures_DTST 语义模型中更新聚合表:
从工作区页面下载 DatasetForMetricsMeasures_DTST 语义模型,并在 Power BI Desktop 中打开该模型。
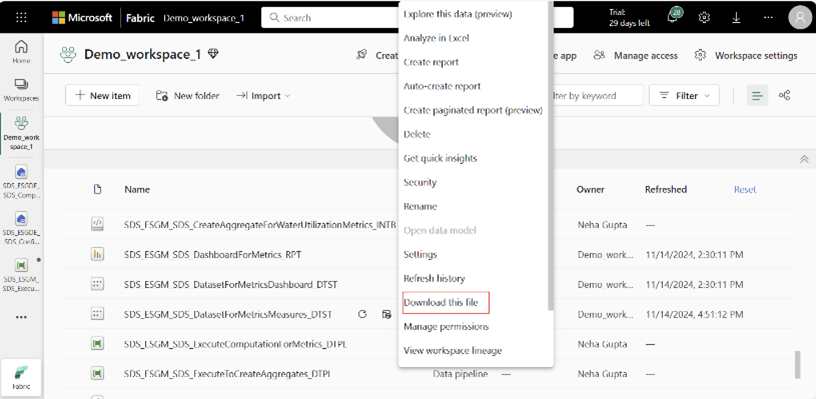
在 Power BI Desktop 中,右键点击更新后的聚合表,选择编辑查询以打开 Power Query 编辑器。
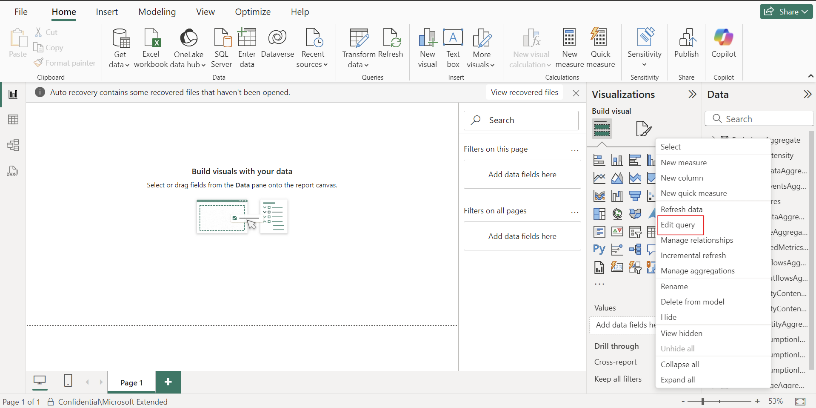
在 Power Query 编辑器中,通过在功能区上选择高级编辑器来打开高级编辑器。
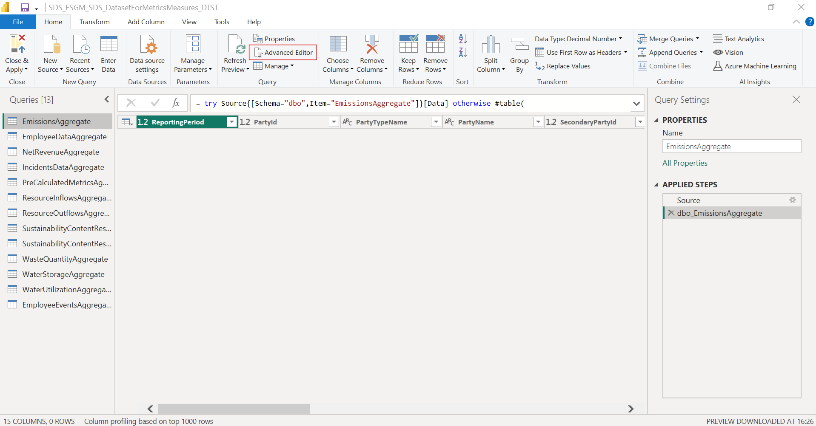
在任何引用列的步骤中更新查询代码以包含新列,并根据需要调整新列的错误处理。 选择完成。
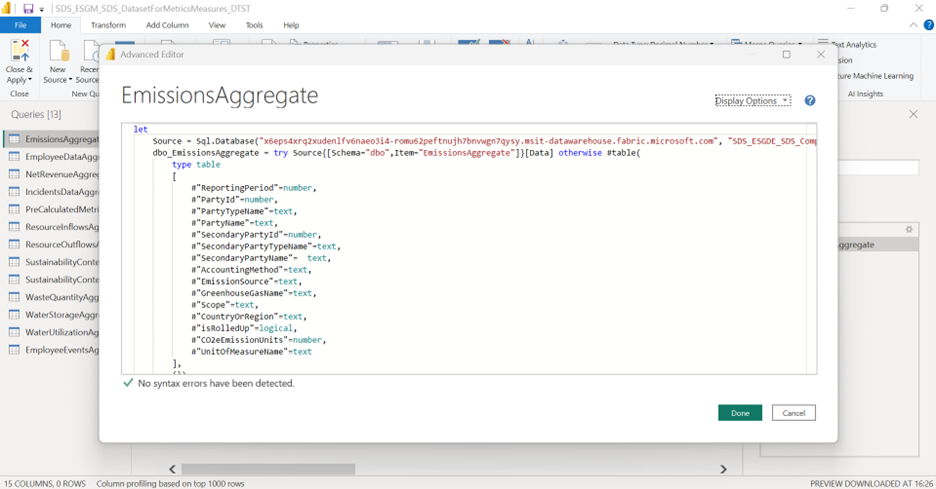
选择刷新预览以查看更新后的数据。 确认后,选择关闭并应用以将更改应用到数据模型。
保存包含新增度量和架构更改的更新后 Power BI 文件。 将更新后的语义模型发布到 Power BI 服务中的目标工作区,覆盖工作区中的先前版本。




场景 3
预构建的聚合表不支持所需的度量数据:
通过在记事本中定义计算逻辑(使用与预构建聚合表类似的模式)创建自定义聚合表。
运行记事本以在 computedESGMetrics_LH 湖屋中生成聚合表。
将自定义聚合表添加到 DatasetForMetricsMeasures_DTST:
从工作区页面下载语义模型并在 Power BI Desktop 中打开该模型。
在 Power BI Desktop 中,选择 OneLake 数据枢纽,选择湖屋,然后在弹出窗口中选择 ComputedESGMetrics 湖屋。 点击连接按钮旁的下拉箭头,然后选择连接到 SQL 端点。
在语义模型中选择要导入的自定义聚合表。 点击加载将表导入 Power BI Desktop。
在窗口提示中,将连接设置设置为导入模式,以将数据导入模型,然后选择确定。
当表加载到数据窗格时,右键单击新添加的表并选择编辑查询以打开 Power Query 编辑器。
在查询编辑器窗格中打开高级编辑器以查看查询代码。 添加必要的错误处理代码以管理任何意外的数据问题。
默认情况下,此代码出现在查询编辑器窗格中:
let Source = Sql.Database("x6eps4xrq2xudenlfv6naeo3i4-lzqqwvhquhb2e7afwzp3ge4.msit-datawarehouse.fabric.microsoft.com", "SDS_ESGDE_ems_ComputedESGMetrics_LH"), <Table Name>= Source{[Schema="dbo",Item="<Table Name from the Lakehouse>"]}[Data] in <Table Name>用以下代码替换此查询,并根据自定义聚合表中的表和列进行必要修改:
let Source = Sql.Database("x6eps4xrq2xudenlfv6naeo3i4-lzqqwvhquhb2e7afwzp3ge4.msit-datawarehouse.fabric.microsoft.com", "SDS_ESGDE_ems_ComputedESGMetrics_LH"), dbo_EmissionsAggregate = try Source{[Schema="dbo",Item="EmissionsAggregate"]}[Data] otherwise #table( type table [ #"ReportingPeriod"=number, #"PartyId"=number, #"PartyTypeName"=text, #"PartyName"=text, #"SecondaryPartyId"=number, #"SecondaryPartyTypeName"=text, #"SecondaryPartyName"=text, #"EmissionSource"=text, #"isRolledUp"=logical, #"CO2eEmission"=number, #"UnitOfMeasureName"=text ], {}) in dbo_EmissionsAggregate要保存更改,请选择完成。
要应用更改,请在 Power Query 编辑器中选择关闭并应用。
在模型视图中,如果需要,添加新添加的表之间的关系。
保存更新的 Power BI Desktop 文件。 通过选择文件 > 发布 > 发布到 Power BI 并选择目标工作区,将模型发布到 Power BI 服务中的工作区。 此操作将覆盖工作区中的现有语义模型,但不会更改模型的 ID。
创建另一个 Power BI 度量用于计算自定义指标
如计算和存储指标数据中所述,ESG 指标的计算是通过 Power BI 度量、过滤器和维度来指定的。
您可以查看预构建的度量列表,并检查是否可以复用现有度量来计算自定义指标。 如果可以复用现有度量,可以跳过此步骤。
如果无法使用现有度量,请在 DatasetForMetricsMeasures_DTST 中创建另一个 Power BI 度量。
从工作区列表视图中选择 DatasetForMetricsMeasures_DTST 语义模型项。
在语义模型页面中选择打开数据模型。
备注
如果打开数据模型呈灰色不可用,请导航至工作区设置。 打开 Power BI/常规,并打开用户可以在 Power BI 服务中编辑数据模型设置。
从数据侧边栏中选择 ESG_Measures,然后选择新建度量以创建度量。
更新度量名称,然后使用数据分析表达式(DAX)查询添加计算逻辑。 要了解更多关于 Power BI 度量的信息,请参阅 Power BI 文档中的在 Power BI Desktop 中创建用于数据分析的度量。

创建指标定义
您可以使用预构建的实用程序函数 create_metric_definition() 来创建指标定义。 有关此函数的更多信息,请参阅 create_metric_definition。
在函数参数中,将指标属性指定为 JSON 文件。 例如,您可能希望计算高水风险和极高水风险区域内设施的用水量。 预构建的指标仅提供水风险区域的总体用水量,但不提供设施级别的细分。 您可以使用以下代码片段创建一个水风险区域内按设施划分的总用水量自定义指标定义。
%run SDS_ESGM_SDS_UtilitiesForMetrics_INTB
metrics_manager = MetricsManager()
metrics_manager.create_metric_definition(
{
"metric_name": "Total water consumption in areas at water risk facility wise",
"measure_name": "WaterConsumption",
"dimensions": [
"WaterUtilizationAggregate[ReportingPeriod]",
"WaterUtilizationAggregate[UnitOfMeasureName]",
"WaterUtilizationAggregate[PartyName]",
"WaterUtilizationAggregate[PartyTypeName]"
],
"filters": {
"WaterUtilizationAggregate[isRolledUp]": [
"False"
],
"WaterUtilizationAggregate[WaterRiskIndexName]": [
"Extremely High",
"High"
],
"WaterUtilizationAggregate[UnitOfMeasureName]": [
"Cubic metres"
]
},
"sustainability_area": "Water and marine resources",
"labels": {
"Reporting standard": [
"CSRD"
],
"Disclosure datapoint": [
"E3-4_02"
]
}
})
当函数成功运行时,指标定义将作为一行添加到 MetricsDefinitions 表中,该表位于 ComputedESGMetrics_LH 湖屋中。
备注
每个指标的名称必须是唯一的。 如果您创建的自定义指标名称与 MetricsDefinitions 表中现有指标名称相同,函数将报错。
在指标定义的 JSON 文件中,如果您不需要这些属性,可以省略指定过滤器和标签属性。
生成和存储指标数据
使用与预构建指标相同的步骤来生成和存储指标数据。 在 metric_names 参数中指定在上一步骤中创建的自定义指标名称。
使用指标数据
当自定义指标数据在 ComputedESGMetrics 表中可用时,您可以用于以下场景:
可视化和分析自定义指标数据
您可以按照可视化和分析自定义指标数据中的步骤,在预构建的 Power BI 仪表盘中可视化和分析自定义指标数据。
如果自定义指标除了报告周期和计量单位名称外还有其他维度,预构建的仪表盘可以处理一个其他维度作为切片器,以及两个其他维度作为多行过滤器。

您可以在 translate_metrics_output_for_report_config.json 文件中指定指标表的维度,以用于切片器和多行过滤器。
例如,您创建温室气体排放分解 – 按国家/地区作为自定义指标,包含以下列:
- 价值
- Country
- 作用域
- 会计核算方法
- 报告期
- 计量单位名称
要在预构建仪表盘上可视化此指标,您可以在配置中指定数据如下:
{ "metric_name": "Disaggregation of GHG emissions - by country", "dimensions_for_multiple_lines": [ "Scope", "AccountingMethod" ], "dimension_for_slicer": "CountryOrRegion" }此代码片段在仪表盘上添加了 CountryOrRegion 维度作为切片器。 范围和 AccountingMethod 维度通过下划线(_)连接,然后作为基本过滤器(或多行过滤器)添加到仪表盘上。
配置更新后,您可以按照此处指定的步骤可视化预构建指标的数据。 TranslateOutputOfMetricsForReport_INTB 记事本。
刷新 DatasetForMetricsDashboard_DTST 语义模型。
打开 DashboardForMetrics_RPT 项。 您应在四个标签页中的一个找到自定义指标,具体取决于指标映射的可持续性领域。
备注
如果可持续性领域指定为除气候变化、社会、治理、水和海洋资源或资源使用和循环经济,则需要自定义预构建的 Power BI 报告。
在合规管理器中发布指标数据以进行审计
对于自定义指标,通过添加包含以下详细信息的对象来更新 translate_metrics_output_for_CM_config.json:
metricName:指标名称。
metricExtractDataPath:在 ReportingData/year 文件夹中创建的指标文件夹名称,该文件夹位于 ComputedESGMetrics_LH 湖屋中,包含该指标的翻译后 JSON 文件。
备注
指标提取数据路径不支持特殊字符或空格。
disclosureRequirements:CSRD 模板合规管理器中的披露要求(改进措施)名称。 合规管理器可读取此值,并将指标数据映射到合规管理器 CSRD 评估中的正确改进措施。
列:每个指标列的列显示名称,用于在下游应用程序中显示指标数据的用户友好列名称。
当配置更新时,使用以下参数运行 TranslateOutputOfMetricsForCM_INTB 记事本:
metric_names:生成的自定义指标名称。
reporting_period:指标数据的报告年份。
num_previous_years:与 reporting_period 数据一起发送的比较年份数据的数量。
记事本运行后,指标数据以 JSON 文件形式存储在 ComputedESGMetrics.json 文件部分的 ReportingData 文件夹中。 现在,您可以使用可持续性数据连接器在合规管理器中导入已发布的指标数据。
