快速入门:通过 SQL 机器学习在 R 中创建预测模型并对其进行评分
适用于:![]() SQL Server 2016 (13.x) 及更高版本
SQL Server 2016 (13.x) 及更高版本 ![]() Azure SQL 托管实例
Azure SQL 托管实例
在本快速入门中,你将使用 T 创建和训练预测模型。将此模型保存到 SQL Server 实例中的表,然后在 SQL Server 机器学习服务中或大数据群集上使用此模型基于新数据来预测值。
在本快速入门中,你将使用 T 创建和定型预测模型。将此模型保存到 SQL Server 实例中的表,然后通过 SQL Server 机器学习服务使用此模型来通过新数据预测值。
在本快速入门中,你将使用 T 创建和训练预测模型。将此模型保存到 SQL Server 实例中的表,然后通过 SQL Server R Services 使用此模型基于新数据来预测值。
在本快速入门中,你将使用 T 创建和定型预测模型。将此模型保存到 SQL Server 实例中的表,然后通过 Azure SQL 托管实例机器学习服务使用此模型来通过新数据预测值。
你将创建并执行 SQL 中运行的两个存储过程。 第一个存储过程使用 R 中包含的 mtcars 数据集,并生成一个简单的通用线性模型 (GLM),此模型会预测车辆与手动变速的拟合概率。 第二个存储过程用于评分,它调用第一个过程中生成的模型,从而根据新数据输出一组预测。 通过将 R 代码放入 SQL 存储过程,操作会包含在 SQL 中,可重复使用,并且可以由其他存储过程和客户端应用程序调用。
提示
如果需要对线性模型进行回顾,请尝试以下教程,其中介绍了使用 rxLinMod 拟合模型的过程:拟合线性模型
完成本快速入门后,你将了解以下内容:
- 如何在存储过程中嵌入 R 代码
- 如何通过存储过程上的输入将输入传递给你的代码
- 如何将存储过程用于操作模型
先决条件
若要运行本快速入门,需要具备以下先决条件。
- SQL Server 机器学习服务。 如需安装机器学习服务,请参阅 Windows 安装指南或 Linux 安装指南。 还可以启用 SQL Server 大数据群集上的机器学习服务。
- SQL Server 机器学习服务。 如需安装机器学习服务,请参阅 Windows 安装指南。
- SQL Server 2016 R Services。 如需安装 R Services,请参阅 Windows 安装指南。
- Azure SQL 托管实例机器学习服务。 有关信息,请参阅 Azure SQL 托管实例机器学习服务概述。
- 一个用于运行包含 R 脚本的 SQL 查询的工具。 本快速入门使用 Azure Data Studio。
创建模型
若要创建模型,你需要创建用于训练的源数据,创建模型并使用数据对其进行训练,然后将该模型存储在数据库中,以便用它来通过新数据生成预测。
创建源数据
打开 Azure Data Studio,连接到你的实例,然后打开一个新的查询窗口。
创建用于保存定型数据的表。
CREATE TABLE dbo.MTCars( mpg decimal(10, 1) NOT NULL, cyl int NOT NULL, disp decimal(10, 1) NOT NULL, hp int NOT NULL, drat decimal(10, 2) NOT NULL, wt decimal(10, 3) NOT NULL, qsec decimal(10, 2) NOT NULL, vs int NOT NULL, am int NOT NULL, gear int NOT NULL, carb int NOT NULL );插入内置数据集
mtcars中的数据。INSERT INTO dbo.MTCars EXEC sp_execute_external_script @language = N'R' , @script = N'MTCars <- mtcars;' , @input_data_1 = N'' , @output_data_1_name = N'MTCars';提示
R 运行时随附许多数据集,有大有小。 若要获取随 R 一起安装的数据集列表,请在 R 命令提示符下键入
library(help="datasets")。
创建和定型模型
车速数据包含两个数值列:马力 (hp) 和重量 (wt)。 通过此数据,你将创建一个通用线性模型 (GLM),用于估计车辆与手动变速拟合的概率。
若要生成模型,请在 R 代码中定义公式,然后将数据作为输入参数传递。
DROP PROCEDURE IF EXISTS generate_GLM;
GO
CREATE PROCEDURE generate_GLM
AS
BEGIN
EXEC sp_execute_external_script
@language = N'R'
, @script = N'carsModel <- glm(formula = am ~ hp + wt, data = MTCarsData, family = binomial);
trained_model <- data.frame(payload = as.raw(serialize(carsModel, connection=NULL)));'
, @input_data_1 = N'SELECT hp, wt, am FROM MTCars'
, @input_data_1_name = N'MTCarsData'
, @output_data_1_name = N'trained_model'
WITH RESULT SETS ((model VARBINARY(max)));
END;
GO
glm的第一个参数是 formula 参数,定义与hp + wt相关的am。- 输入数据存储在由 SQL 查询填充的
MTCarsData变量中。 如果不为输入数据分配特定的名称,则默认变量名称为 InputDataSet。
将模型存储在数据库中
接下来,将模型存储在数据库中,以便可以使用它进行预测或对它进行重新训练。
创建用于存储模型的表。
创建模型的 R 包的输出通常是一个二进制对象。 因此,存储模型的表必须提供 varbinary(max) 类型的列。
CREATE TABLE GLM_models ( model_name varchar(30) not null default('default model') primary key, model varbinary(max) not null );运行以下 Transact-SQL 语句以调用存储过程,生成模型,然后将其保存到所创建的表中。
INSERT INTO GLM_models(model) EXEC generate_GLM;提示
如果再次运行此代码,将出现以下错误:"PRIMARY KEY 约束冲突 ...无法在对象 stopping_distance_models "中插入重复键。 若要避免此错误,一个选择是更新每个新模型的名称。 例如,可以将名称更改为更具说明性的名称,并且包括模型类型、创建日期等。
UPDATE GLM_models SET model_name = 'GLM_' + format(getdate(), 'yyyy.MM.HH.mm', 'en-gb') WHERE model_name = 'default model'
使用已定型的模型对新数据进行评分
评分是数据科学领域使用的术语,用于表示根据馈送到已定型的模型中的新数据生成预测、概率或其他值。 你将使用在上一节中创建的模型来对新数据的预测进行评分。
创建新数据的表
首先,使用新数据创建一个表。
CREATE TABLE dbo.NewMTCars(
hp INT NOT NULL
, wt DECIMAL(10,3) NOT NULL
, am INT NULL
)
GO
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (110, 2.634)
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (72, 3.435)
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (220, 5.220)
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (120, 2.800)
GO
预测手动变速
若要基于模型获取预测,请编写一个执行以下操作的 SQL 脚本:
- 获取所需的模型
- 获取新的输入数据
- 调用与该模型兼容的 R 预测函数
随时间的推移,此表中可能包含多个 R 模型,其中的所有模型都是使用不同的参数或算法构建的,或者已根据不同的数据子集进行了定型。 在此示例中,我们将使用名为 default model 的模型。
DECLARE @glmmodel varbinary(max) =
(SELECT model FROM dbo.GLM_models WHERE model_name = 'default model');
EXEC sp_execute_external_script
@language = N'R'
, @script = N'
current_model <- unserialize(as.raw(glmmodel));
new <- data.frame(NewMTCars);
predicted.am <- predict(current_model, new, type = "response");
str(predicted.am);
OutputDataSet <- cbind(new, predicted.am);
'
, @input_data_1 = N'SELECT hp, wt FROM dbo.NewMTCars'
, @input_data_1_name = N'NewMTCars'
, @params = N'@glmmodel varbinary(max)'
, @glmmodel = @glmmodel
WITH RESULT SETS ((new_hp INT, new_wt DECIMAL(10,3), predicted_am DECIMAL(10,3)));
上面的脚本执行以下步骤:
使用 SELECT 语句从表中获取单个模型,然后将其作为输入参数传递。
从表中检索模型以后,在该模型上调用
unserialize函数。将带有适当参数的
predict函数应用到模型,并提供新的输入数据。
注意
在示例中,测试阶段添加了 str 函数,用于检查从 R 返回的数据的架构。之后你可以删除该语句。
R 脚本中使用的列名不必传递到存储过程输出。 此处使用了 WITH RESULTS 子句来定义一些新的列名。
结果
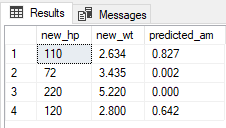
还可以使用 PREDICT (Transact-SQL) 语句基于存储的模型生成预测值或分数。
后续步骤
若要详细了解通过 SQL 机器学习使用 R 的教程,请参阅:
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈