CREATE EXTERNAL TABLE (Transact-SQL)
创建外部表。
本文提供所选任何 SQL 产品的语法、参数、注解、权限和示例。
有关语法约定的详细信息,请参阅 Transact-SQL 语法约定。
选择一个产品
在下面的行中,选择你感兴趣的产品名称,系统将只显示该产品的信息。
* SQL Server *
概述:SQL Server
此命令为 PolyBase 创建一个外部表,以访问存储在 Hadoop 群集或 Azure Blob 存储中的数据(引用存储在 Hadoop 群集或 Azure Blob 存储中的数据的 PolyBase 外部表)。
适用于:SQL Server 2016 或更高版本
使用带有外部数据源的外部表进行 PolyBase 查询。 外部数据源用于建立连接以及支持以下这些用例:
- 使用 PolyBase 执行数据虚拟化和数据加载
- 使用
BULK INSERT或OPENROWSET通过 SQL Server 或 SQL 数据库进行批量加载操作
另请参阅 CREATE EXTERNAL DATA SOURCE 和 DROP EXTERNAL TABLE。
语法
-- Create a new external table
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'folder_or_filepath',
DATA_SOURCE = external_data_source_name,
[ FILE_FORMAT = external_file_format_name ]
[ , <reject_options> [ ,...n ] ]
)
[;]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage
| REJECT_VALUE = reject_value
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
参数
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
要创建的表的一到三部分名称。 对于外部表,SQL 仅存储表元数据以及有关 Hadoop 或 Azure Blob 存储中引用的文件或文件夹的基本统计信息。 在 SQL Server 中不移动或存储任何实际数据。
重要
为了获得最佳性能,如果外部数据源驱动程序支持由三部分组成的名称,则强烈建议提供由三部分组成的名称。
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE 支持配置列名、数据类型、为 Null 性和排序规则的功能。 不能对外部表使用 DEFAULT CONSTRAINT。
列定义(包括数据类型和列数)必须与外部文件中的数据匹配。 如果存在不匹配,则在查询实际数据时会拒绝文件行。
LOCATION = 'folder_or_filepath'
为 Hadoop 或 Azure Blob 存储中的实际数据指定文件夹或文件路径和文件名。 此外,从 SQL Server 2022 (16.x) 开始,支持 S3 兼容对象存储。 位置从根文件夹开始。 根文件夹是外部数据源中指定的数据位置。
在 SQL Server 中,如果路径和文件夹不存在,则 CREATE EXTERNAL TABLE 语句会进行创建。 然后,可使用 INSERT INTO 将数据从本地 SQL Server 表导出到外部数据源。 有关详细信息,请参阅 PolyBase 查询。
如果将 LOCATION 指定为一个文件夹,则从外部表中进行选择的 PolyBase 查询会从该文件夹及其所有子文件夹中检索文件。 正如 Hadoop 一样,PolyBase 不返回隐藏文件夹。 它也不返回文件名以下划线 (_) 或句点 (.) 开头的文件。
在下图示例中,如果 LOCATION='/webdata/',则 PolyBase 查询会从 mydata.txt 和 mydata2.txt 返回行。 它不会返回 mydata3.txt,因为它是隐藏子文件夹中的文件。 它不返回 _hidden.txt,因为这是隐藏文件。
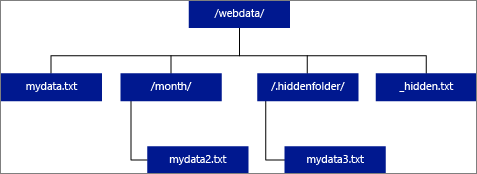
若要更改默认值并且只从根文件夹进行读取,请在 core-site.xml 配置文件中将属性 <polybase.recursive.traversal> 设置为“false”。 此文件位于 SQL Server 的 bin 根的 <SqlBinRoot>\PolyBase\Hadoop\Conf 下。 例如,C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn。
DATA_SOURCE = external_data_source_name
指定包含外部数据位置的外部数据源的名称。 此位置是 Hadoop 文件系统 (HDFS)、Azure Blob 存储容器或 Azure Data Lake Store。 要创建外部数据源,请使用 CREATE EXTERNAL DATA SOURCE。
FILE_FORMAT = external_file_format_name
指定用于存储外部数据的文件类型和压缩方法的外部文件格式对象的名称。 若要创建外部文件格式,请使用 CREATE EXTERNAL FILE FORMAT。
外部文件格式可由多个类似的外部文件重复使用。
拒绝选项
此选项只能用于类型为 HADOOP 的外部数据源。
可以指定用于确定 PolyBase 如何处理它从外部数据源检索的脏记录的拒绝参数。 如果实际数据类型或列数与外部表的列定义不匹配,则数据记录被视为“脏”记录。
未指定或更改拒绝值时,PolyBase 会使用默认值。 使用 CREATE EXTERNAL TABLE 语句创建外部表时,有关拒绝参数的此信息会存储为附加元数据。 在将来的 SELECT 语句或 SELECT INTO SELECT 语句从外部表中选择数据时,PolyBase 会使用拒绝选项确定在实际查询失败之前可以拒绝的行数或行百分比。 查询会返回(部分)结果,直到超出拒绝阈值。 查询随后失败,并出现相应的错误消息。
REJECT_TYPE = value | percentage
说明 REJECT_VALUE 选项是指定为文本值还是百分比。
value
REJECT_VALUE 是文本值,而非百分比。 当拒绝的行数超过 reject_value 时,此查询会失败。
例如,如果 REJECT_VALUE = 5 且 REJECT_TYPE = value,则 SELECT 查询将在拒绝五行后失败。
percentage
REJECT_VALUE 是百分比,而非文本值。 当失败行的百分比超过 reject_value 时,查询会失败。 每隔一段时间计算失败行的百分比。
REJECT_VALUE = reject_value
指定在查询失败之前可以拒绝的行数的值或百分比。
对于 REJECT_TYPE = value,reject_value 必须是介于 0 与 2,147,483,647 之间的整数。
对于 REJECT_TYPE = percentage,reject_value 必须是介于 0 与 100 之间的浮点数。
REJECT_SAMPLE_VALUE = reject_sample_value
当指定 REJECT_TYPE = percentage 时,此属性是必需的。 它确定在 PolyBase 重新计算拒绝的行的百分比之前要尝试检索的行数。
Reject_sample_value 参数必须是介于 0 与 2,147,483,647 之间的整数。
例如,如果 REJECT_SAMPLE_VALUE = 1000,则 PolyBase 会在尝试从外部数据文件导入 1000 行后计算失败行的百分比。 如果失败行的百分比小于 reject_value,则 PolyBase 会尝试检索另外 1000 行。 它在尝试导入每个另外 1000 行后会继续重新计算失败行的百分比。
注意
由于 PolyBase 按间隔计算失败行的百分比,因此失败行的实际百分比可能会超过 reject_value。
示例:
此示例演示三个 REJECT 选项相互之间如何交互。 例如,如果 REJECT_TYPE = percentage、REJECT_VALUE = 30、REJECT_SAMPLE_VALUE = 100,可能出现以下情况:
- PolyBase 尝试检索前 100 行;25 行失败,75 行成功。
- 失败行的百分比计算结果为 25%,小于 30% 的拒绝值。 因此,PolyBase 会继续从外部数据源检索数据。
- PolyBase 尝试加载下一个 100 行;这次 25 行成功,75 行失败。
- 重新计算的失败行的百分比为 50%。 失败行的百分比已超过 30% 的拒绝值。
- 在尝试返回前 200 行之后,PolyBase 查询失败,拒绝的行为 50%。 请注意,匹配行在 PolyBase 查询检测到超过拒绝阈值之前已返回。
REJECTED_ROW_LOCATION = 目录位置
适用于:SQL Server 2019 CU6 及更高版本、Azure Synapse Analytics。
指定应该写入拒绝行和对应错误文件的外部数据源中的目录。
如果指定的路径不存在,PolyBase 将代你创建一个。 创建名称为“_rejectedrows”的子目录。 除非在位置参数中明确命名,否则,“_”字符将确保对该目录转义以进行其他数据处理。 在此目录中,有一个根据负载提交时间创建的文件夹,其格式为 YearMonthDay -HourMinuteSecond(例如 20230330-173205)。 在此文件夹中,将写入两种文件类型,_原因文件和数据文件。 此选项只能用于 TYPE = HADOOP 的外部数据源,以及使用 DELIMITEDTEXT FORMAT_TYPE 的外部表。 有关详细信息,请参阅 CREATE EXTERNAL DATA SOURCE 和 CREATE EXTERNAL FILE FORMAT。
原因文件和数据文件均包含与 CTAS 语句关联的 queryID。 因为数据和原因位于单独的文件中,相应的文件具有匹配的后缀。
权限
需要以下用户权限:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT(仅适用于 Hadoop 和 Azure 存储外部数据源)
- CONTROL DATABASE(仅适用于 Hadoop 和 Azure 存储外部数据源)
注意,在 CREATE EXTERNAL TABLE 命令中使用的 DATABASE SCOPED CREDENTIAL 中指定的远程登录必须对 LOCATION 参数中指定的外部数据源的路径/表/集合具有读取权限。 如果计划使用此 EXTERNAL TABLE 将数据导出到 Hadoop 或 Azure 存储外部数据源,则指定的登录名必须对 LOCATION 中指定的路径具有写入权限。 请注意,SQL Server 2022 (16.x) 当前不支持 Hadoop。
对于 Azure Blob 存储,在 Azure 门户、Azure Blob 存储或 ADLS Gen2 存储帐户中配置访问密钥和共享访问签名 (SAS) 时,将“允许的权限”配置为至少授予读取和写入权限。 跨文件夹搜索时可能还需要列表权限。 还必须同时选择“容器”和“对象”作为允许的资源类型。
重要
ALTER ANY EXTERNAL DATA SOURCE 权限授予任何主体创建和修改任何外部数据源对象的能力,因此,它还授予访问数据库上所有数据库作用域凭据的能力。 必须将此权限视为高度特权,因此必须仅授予系统中受信任的主体。
错误处理。
执行 CREATE EXTERNAL TABLE 语句时,PolyBase 会尝试连接到外部数据源。 如果连接尝试失败,则该语句会失败且不会创建外部表。 由于 PolyBase 在使查询最终失败之前会重新尝试连接,因此命令需要一分钟或更多时间才会失败。
注解
在即席查询方案(例如 SELECT FROM EXTERNAL TABLE)中,PolyBase 会将从外部数据源检索的行存储在临时表中。 查询完成之后,PolyBase 会移除并删除临时表。 任何永久数据都不会存储在 SQL 表中。
相反,在导入方案(例如 SELECT INTO FROM EXTERNAL TABLE)中,PolyBase 会将从外部数据源检索的行作为永久数据存储在 SQL 表中。 当 PolyBase 检索外部数据时,会在查询执行期间创建新表。
PolyBase 可以将某些查询计算推送到 Hadoop 以提高查询性能。 此操作称为谓词下推。 若要启用它,请在 CREATE EXTERNAL DATA SOURCE 中指定 Hadoop 资源管理器位置选项。
可以创建许多引用相同或不同外部数据源的外部表。
限制和局限
外部表的数据不受 SQL Server 直接控制,因此可随时通过外部进程更改或删除这些数据。 因此,针对外部表的查询结果不保证具有确定性。 相同查询可能会在每次针对外部表运行时返回不同结果。 同样,如果外部数据已移动或删除,则查询可能会失败。
可以创建各自引用不同外部数据源的多个外部表。 如果同时针对不同 Hadoop 数据源运行查询,则每个 Hadoop 源都必须使用相同的“hadoop 连接”服务器配置设置。 例如,不能同时针对 Cloudera Hadoop 群集和 Hortonworks Hadoop 群集运行查询,因为这些群集使用不同的配置设置。 有关配置设置和受支持的组合,请参阅 PolyBase 连接配置。
当外部表使用DELIMITEDTEXT、CSV、PARQUET 或 DELTA 作为数据类型时,外部表仅支持每个 CREATE STATISTICS 命令一列的统计信息。
外部表上仅允许使用以下这些数据定义语言 (DDL) 语句:
- CREATE TABLE 和 DROP TABLE
- CREATE STATISTICS 和 DROP STATISTICS
- CREATE VIEW 和 DROP VIEW
不支持构造和操作:
- 外部表列上的 DEFAULT 约束
- 删除、插入和更新的数据操作语言 (DML) 操作
查询限制
运行 32 个并发 PolyBase 查询时,每个文件夹中 PolyBase 最多可使用 33000 个文件。 此最大数量包括每个 HDFS 文件夹中的文件和子文件夹。 如果并发度小于 32,用户可以针对 HDFS 中包含超过 33000 个文件的文件夹运行 PolyBase 查询。 建议保持外部文件路径简短,并且每个 HDFS 文件夹不超过 30000 个文件。 当引用太多文件时,可能会发生 Java 虚拟机 (JVM) 内存不足异常。
表宽度限制
基于表定义中单个有效行的最大大小,SQL Server 2016 中的 PolyBase 具有 32 KB 的行宽限制。 如果列架构的总和大于 32 KB,则 PolyBase 无法查询数据。
数据类型限制
以下数据类型不能在 PolyBase 外部表中使用:
geographygeometryhierarchyidimagetextnTextxml- 任何用户定义类型
数据源特定限制
Oracle
不支持将 Oracle 同义词用于 PolyBase。
包含数组的 MongoDB 集合的外部表
若要创建包含数组的 MongoDB 集合的外部表,应使用 Azure Data Studio 的数据虚拟化扩展,基于 PolyBase ODBC Driver for MongoDB 检测到的架构生成 CREATE EXTERNAL TABLE 语句。 驱动程序会自动执行平展操作。 或者,可使用 sp_data_source_objects (Transact-SQL) 来检测集合架构(列)并手动创建外部表。 sp_data_source_table_columns 存储过程还通过 PolyBase ODBC Driver for MongoDB 驱动程序自动执行平展。 Azure Data Studio 的数据虚拟化扩展和 sp_data_source_table_columns 使用相同的内部存储过程来查询外部架构。
锁定
SCHEMARESOLUTION 对象上的共享锁。
安全性
外部表的数据文件存储在 Hadoop 或 Azure Blob 存储中。 这些数据文件由你自己的进程进行创建和管理。 由你负责管理外部数据的安全。
示例
A. 创建外部表,其中包含采用带分隔符的文本格式的数据
此示例演示创建包含采用带分隔符的文本文件设置格式的数据的外部表所需的所有步骤。 它定义外部数据源 mydatasource 和外部文件格式 myfileformat。 这些数据库级别对象随后会在 CREATE EXTERNAL TABLE 语句中进行引用。 有关详细信息,请参阅 CREATE EXTERNAL DATA SOURCE 和 CREATE EXTERNAL FILE FORMAT。
CREATE EXTERNAL DATA SOURCE mydatasource
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR ='|')
);
CREATE EXTERNAL TABLE ClickStream (
url varchar(50),
event_date date,
user_IP varchar(50)
)
WITH (
LOCATION='/webdata/employee.tbl',
DATA_SOURCE = mydatasource,
FILE_FORMAT = myfileformat
)
;
B. 创建外部表,其中包含采用 RCFile 格式的数据
此示例演示创建包含格式为 RCFile 的数据的外部表所需的所有步骤。 它定义外部数据源 mydatasource_rc 和外部文件格式 myfileformat_rc。 这些数据库级别对象随后会在 CREATE EXTERNAL TABLE 语句中进行引用。 有关详细信息,请参阅 CREATE EXTERNAL DATA SOURCE 和 CREATE EXTERNAL FILE FORMAT。
CREATE EXTERNAL DATA SOURCE mydatasource_rc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_rc
WITH (
FORMAT_TYPE = RCFILE,
SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
)
;
CREATE EXTERNAL TABLE ClickStream_rc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/employee_rc.tbl',
DATA_SOURCE = mydatasource_rc,
FILE_FORMAT = myfileformat_rc
)
;
C. 创建外部表,其中包含采用 ORC 格式的数据
此示例演示创建包含格式为 ORC 的数据的外部表所需的所有步骤。 它定义外部数据源 mydatasource_orc 和外部文件格式 myfileformat_orc 。 这些数据库级别对象随后会在 CREATE EXTERNAL TABLE 语句中进行引用。 有关详细信息,请参阅 CREATE EXTERNAL DATA SOURCE 和 CREATE EXTERNAL FILE FORMAT。
CREATE EXTERNAL DATA SOURCE mydatasource_orc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_orc
WITH (
FORMAT = ORC,
COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
;
CREATE EXTERNAL TABLE ClickStream_orc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/',
DATA_SOURCE = mydatasource_orc,
FILE_FORMAT = myfileformat_orc
)
;
D. 查询 Hadoop 数据
ClickStream 是连接到 Hadoop 群集上带分隔符的文本文件 employee.tbl 的外部表。 下面的查询看上去如同针对标准表的查询。 但是,此查询从 Hadoop 检索数据,然后计算结果。
SELECT TOP 10 (url) FROM ClickStream WHERE user_ip = 'xxx.xxx.xxx.xxx';
E. 将 Hadoop 数据与 SQL 数据联接
此查询看上去如同两个 SQL 表上的标准 JOIN。 区别在于,PolyBase 从 Hadoop 检索点击流数据,然后将数据联接到 UrlDescription 表。 一个表是外部表,另一个表是标准 SQL 表。
SELECT url.description
FROM ClickStream cs
JOIN UrlDescription url ON cs.url = url.name
WHERE cs.url = 'msdn.microsoft.com';
F. 将数据从 Hadoop 导入 SQL 表中
此示例创建新 SQL 表 ms_user,此表将永久存储在标准 SQL 表 user 和外部表 ClickStream 之间进行联接的结果。
SELECT DISTINCT user.FirstName, user.LastName
INTO ms_user
FROM user INNER JOIN (
SELECT * FROM ClickStream WHERE cs.url = 'www.microsoft.com'
) AS ms
ON user.user_ip = ms.user_ip;
G. 为 SQL Server 创建外部表
创建数据库范围凭据之前,用户数据库必须具有用于保护凭据的主密钥。 有关详细信息,请参阅 CREATE MASTER KEY 和 CREATE DATABASE SCOPED CREDENTIAL。
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';
GO
/* specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL SqlServerCredentials
WITH IDENTITY = 'username', Secret = 'password';
GO
创建名为 SQLServerInstance 的新外部数据源,以及名为 sqlserver.customer 的外部表:
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE SQLServerInstance
WITH (
LOCATION = 'sqlserver://SqlServer',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = SQLServerCredentials
);
GO
CREATE SCHEMA sqlserver;
GO
/* LOCATION: sql server table/view in 'database_name.schema_name.object_name' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE sqlserver.customer(
C_CUSTKEY INT NOT NULL,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INT NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL
)
WITH (
LOCATION='tpch_10.dbo.customer',
DATA_SOURCE=SqlServerInstance
);
I. 为 Oracle 创建外部表
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/*
* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = 'oracle://<server address>[:<port>]',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name)
/*
* LOCATION: Oracle table/view in '<database_name>.<schema_name>.<object_name>' format. Note this may be case sensitive in the Oracle database.
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_ORDERPRIORITY] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_CLERK] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_SHIPPRIORITY] DECIMAL(38) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='DB1.mySchema.customer',
DATA_SOURCE= external_data_source_name
);
J. 为 Teradata 创建外部表
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = teradata://<server address>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL =credential_name
);
/* LOCATION: Teradata table/view in '<database_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customer(
L_ORDERKEY INT NOT NULL,
L_PARTKEY INT NOT NULL,
L_SUPPKEY INT NOT NULL,
L_LINENUMBER INT NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR NOT NULL,
L_LINESTATUS CHAR NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
K. 为 MongoDB 创建外部表
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<type>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = mongodb://<server>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name
);
/* LOCATION: MongoDB table/view in '<database_name>.<schema_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
L. 通过外部表查询 S3 兼容对象存储
适用于:SQL Server 2022 (16.x) 及更高版本
以下示例演示如何使用 T-SQL 通过查询外部表查询存储在 S3 兼容的对象存储中的 parquet 文件。 示例使用外部数据源中的相对路径。
CREATE EXTERNAL DATA SOURCE s3_ds
WITH
( LOCATION = 's3://<ip_address>:<port>/'
, CREDENTIAL = s3_dc
);
GO
CREATE EXTERNAL FILE FORMAT ParquetFileFormat WITH(FORMAT_TYPE = PARQUET);
GO
CREATE EXTERNAL TABLE Region(
r_regionkey BIGINT,
r_name CHAR(25),
r_comment VARCHAR(152) )
WITH (LOCATION = '/region/', DATA_SOURCE = 's3_ds',
FILE_FORMAT = ParquetFileFormat);
GO
后续步骤
通过以下文章详细了解相关概念:
* Azure SQL 数据库 *
概述:Azure SQL Database
在 Azure SQL 数据库中,针对弹性查询(预览版)创建外部表。
另请参阅 CREATE EXTERNAL DATA SOURCE。
语法
-- Create a table for use with elastic query
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH ( <sharded_external_table_options> )
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<sharded_external_table_options> ::=
DATA_SOURCE = external_data_source_name,
SCHEMA_NAME = N'nonescaped_schema_name',
OBJECT_NAME = N'nonescaped_object_name',
[DISTRIBUTION = SHARDED(sharding_column_name) | REPLICATED | ROUND_ROBIN]]
)
[;]
参数
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
要创建的表的一到三部分名称。 对于外部表,SQL 仅存储表元数据以及有关 Azure SQL 数据库中引用的文件或文件夹的基本统计信息。 在 Azure SQL 数据库中不移动或存储任何实际数据。
重要
为了获得最佳性能,如果外部数据源驱动程序支持由三部分组成的名称,则强烈建议提供由三部分组成的名称。
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE 支持配置列名、数据类型、为 Null 性和排序规则的功能。 不能对外部表使用 DEFAULT CONSTRAINT。
注意
对于 Azure SQL 数据库,Text、nText 和 XML 不是受外部表中的列支持的数据类型。
列定义(包括数据类型和列数)必须与外部文件中的数据匹配。 如果存在不匹配,则在查询实际数据时会拒绝文件行。
分片外部表选项
为弹性查询指定外部数据源(非 SQL Server 数据源)和分发方法。
DATA_SOURCE
DATA_SOURCE 子句定义用于外部表的外部数据源(分片映射)。 有关示例,请参阅创建外部表。
重要
Azure SQL 数据库支持对外部数据源类型 RDMS 和 SHARD_MAP_MANAGER 创建外部表。 Azure SQL 数据库不支持对 Azure Blob 存储创建外部表。
SCHEMA_NAME 和 OBJECT_NAME
SCHEMA_NAME 和 OBJECT_NAME 子句将外部表定义映射到不同架构的表。 如果省略,则假定远程对象的架构是“dbo”,并假定其名称与所定义的外部表名称相同。 如果远程表的名称已在要在其中创建外部表的数据库中使用,那么该做法很有用。 例如,你希望定义一个外部表,用于获取扩展数据层上目录视图或 DMV 的聚合视图。 由于目录视图和 DMV 已在本地存在,因此不能在外部表定义中使用其名称。 而是改用不同名称,并在 SCHEMA_NAME 和/或 OBJECT_NAME 子句中使用目录视图或 DMV 的名称。 有关示例,请参阅创建外部表。
分发
可选。 只有 SHARD_MAP_MANAGER 类型的数据库才需要此参数。 此参数控制表是被视为分片表还是复制表。 使用 SHARDED(列名)表时,来自不同表的数据不会重叠。 REPLICATED 指定表在每个分片上具有相同数据。 ROUND_ROBIN 指示将特定于应用程序的方法用于分发数据。
DISTRIBUTION 子句指定用于此表的数据分布。 查询处理器利用 DISTRIBUTION 子句中提供的信息来构建最有效的查询计划。
- SHARDED 表示数据在各数据库之间横向分区。 数据分布的分区键位于
sharding_column_name参数中。 - REPLICATED 表示每个数据库都存在表的相同副本。 要负责确保各数据库上的副本是相同的。
- ROUND_ROBIN 表示使用依赖于应用程序的分发方法对表进行横向分区。
权限
有权访问外部表的用户在使用外部数据源定义中提供的凭据时自动获得对基础远程表的访问权。 避免通过外部数据源的凭据进行不必要的权限提升。 将外部表当作常规表,在其中使用 GRANT 或 REVOKE。 定义外部数据源和外部表后,可以对外部表使用完整的 T-SQL。
错误处理。
在执行 CREATE EXTERNAL TABLE 语句时,如果连接尝试失败,则该语句会失败且不会创建外部表。 由于 SQL 数据库在使查询最终失败之前会重新尝试连接,因此命令需要一分钟或更多时间才会失败。
注解
在即席查询方案(例如 SELECT FROM EXTERNAL TABLE)中,SQL 数据库会将从外部数据源检索的行存储在临时表中。 查询完成之后,SQL 数据库会移除并删除临时表。 任何永久数据都不会存储在 SQL 表中。
相反,在导入方案(例如 SELECT INTO FROM EXTERNAL TABLE)中,SQL 数据库会将从外部数据源检索的行作为永久数据存储在 SQL 表中。 当 SQL 数据库检索外部数据时,会在查询执行期间创建新表。
可以创建许多引用相同或不同外部数据源的外部表。
限制和局限
通过外部表访问数据不符合 SQL Server 中的隔离语义。 这意味着查询外部数据源不会施加任何锁定或快照隔离,因此,如果外部数据源中的数据更改,则返回的数据也可能更改。 相同查询可能会在每次针对外部表运行时返回不同结果。 同样,如果外部数据已移动或删除,则查询可能会失败。
可以创建各自引用不同外部数据源的多个外部表。
外部表上仅允许使用以下这些数据定义语言 (DDL) 语句:
- CREATE TABLE 和 DROP TABLE。
- CREATE VIEW 和 DROP VIEW。
不支持构造和操作:
- 外部表列上的 DEFAULT 约束。
- 删除、插入和更新的数据操作语言 (DML) 操作。
- 外部表列上的动态数据掩码。
- Azure SQL 数据库中的外部表不支持游标。
仅查询中定义的文本谓词才能下推到外部数据源。 这不同于链接服务器以及访问可使用在查询执行过程中确定的谓词的位置,即,在查询计划中与嵌套循环一起使用时。 这通常会导致在本地复制整个外部表并随后联接到外部表。
-- Assuming External.Orders is an external table and Customer is a local table.
-- This query will copy the whole of the external locally as the predicate needed
-- to filter isn't known at compile time. Its only known during execution of the query
SELECT Orders.OrderId, Orders.OrderTotal
FROM External.Orders
WHERE CustomerId IN (
SELECT TOP 1 CustomerId
FROM Customer
WHERE CustomerName = 'MyCompany'
);
使用外部表可防止在查询计划中使用并行。
外部表作为远程查询实现,因此,估计的返回行数通常为 1000 行,还有基于用于筛选外部表的谓词类型的其他规则。 它们是基于规则的估计,而不是基于外部表中的实际数据的估计。 优化器不会通过访问远程数据源来获取更准确的估计。
数据类型限制
以下数据类型不能在 PolyBase 外部表中使用:
geographygeometryhierarchyidimagetextnTextxml- 任何用户定义类型
锁定
SCHEMARESOLUTION 对象上的共享锁。
示例
A. 为 Azure SQL 数据库创建外部表
CREATE EXTERNAL TABLE [dbo].[CustomerInformation]
( [CustomerID] [int] NOT NULL,
[CustomerName] [varchar](50) NOT NULL,
[Company] [varchar](50) NOT NULL)
WITH
( DATA_SOURCE = MyElasticDBQueryDataSrc)
B. 为分片数据源创建外部表
此示例使用 SCHEMA_NAME 和 OBJECT_NAME 子句将远程 DMV 重映射到外部表。
CREATE EXTERNAL TABLE [dbo].[all_dm_exec_requests]([session_id] smallint NOT NULL,
[request_id] int NOT NULL,
[start_time] datetime NOT NULL,
[status] nvarchar(30) NOT NULL,
[command] nvarchar(32) NOT NULL,
[sql_handle] varbinary(64),
[statement_start_offset] int,
[statement_end_offset] int,
[cpu_time] int NOT NULL)
WITH
(
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'sys',
OBJECT_NAME = 'dm_exec_requests',
DISTRIBUTION=ROUND_ROBIN
);
后续步骤
通过以下文章详细了解 Azure SQL 数据库中的外部表:
* Azure Synapse
Analytics *
概述:Azure Synapse Analytics
使用外部表可:
- 专用 SQL 池可以从 Hadoop、Azure Blob 存储以及 Azure Data Lake Storage Gen1 和 Gen2 查询、导入和存储数据。
- 无服务器 SQL 池可以从 Azure Blob 存储以及 Azure Data Lake Storage Gen1 和 Gen2 查询、导入和存储数据。 无服务器不支持
TYPE=Hadoop。
另请参阅 CREATE EXTERNAL DATA SOURCE 和 DROP EXTERNAL TABLE。
有关将外部表与 Azure Synapse 配合使用的更多指导和示例,请参阅将外部表与 Synapse SQL 配合使用。
语法
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
参数
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
要创建的表的一到三部分名称。 对于外部表,仅需要表元数据以及有关 Azure Data Lake、Hadoop 或 Azure Blob 存储中引用的文件或文件夹的基本统计信息。 创建外部表时,不会移动或存储任何实际数据。
重要
为了获得最佳性能,如果外部数据源驱动程序支持由三部分组成的名称,则强烈建议提供由三部分组成的名称。
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE 支持配置列名、数据类型、为 Null 性和排序规则的功能。 不能对外部表使用 DEFAULT CONSTRAINT。
注意
已弃用的数据类型 text、ntext 和 XML 是 Synapse Analytics 外部表中的列不支持的数据类型。
- 读取带分隔符的文件时,列定义(包括数据类型和列数)必须与外部文件中的数据匹配。 如果存在不匹配,则在查询实际数据时会拒绝文件行。
- 从 Parquet 文件读取数据时,可以仅指定所要读取的列,并跳过其余的列。
LOCATION = 'folder_or_filepath'
为 Azure Data Lake、Hadoop 或 Azure Blob 存储中的实际数据指定文件夹或文件路径和文件名。 位置从根文件夹开始。 根文件夹是外部数据源中指定的数据位置。 如果路径和文件夹不存在,则 CREATE EXTERNAL TABLE AS SELECT 语句会进行创建。 CREATE EXTERNAL TABLE 不会创建路径和文件夹。
如果将 LOCATION 指定为一个文件夹,则从外部表中进行选择的 PolyBase 查询会从该文件夹及其所有子文件夹中检索文件。 正如 Hadoop 一样,PolyBase 不返回隐藏文件夹。 它也不返回文件名以下划线 (_) 或句点 (.) 开头的文件。
在下图示例中,如果 LOCATION='/webdata/',则 PolyBase 查询会从 mydata.txt 和 mydata2.txt 返回行。 它不会返回 mydata3.txt,因为它位于隐藏文件夹的子文件夹中。 它不返回 _hidden.txt,因为这是隐藏文件。
与 Hadoop 外部表不同的是,除非在路径末尾指定 /**,否则本机外部表不返回子文件夹。 在此示例中,如果 LOCATION='/webdata/',则无服务器 SQL 池查询将返回 mydata.txt 中的行。 它不返回 mydata2.txt 和 mydata3.txt,因为这些文件位于子文件夹中。 Hadoop 表将返回任何子文件夹中的所有文件。
Hadoop 和本机外部表均会跳过名称以下划线 (_) 或句点 (.) 开头的文件。
DATA_SOURCE = external_data_source_name
指定包含外部数据位置的外部数据源的名称。 此位置位于 Azure Data Lake 中。 要创建外部数据源,请使用 CREATE EXTERNAL DATA SOURCE。
FILE_FORMAT = external_file_format_name
指定用于存储外部数据的文件类型和压缩方法的外部文件格式对象的名称。 若要创建外部文件格式,请使用 CREATE EXTERNAL FILE FORMAT。
TABLE_OPTIONS
指定描述如何读取基础文件的选项集。 目前,唯一可用的选项是 {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]},它指示外部表忽略对基础文件进行的更新,即使这可能导致一些不一致的读取操作。 仅在经常追加文件的特殊情况下使用此选项。 此选项在 CSV 格式的无服务器 SQL 池中可用。
REJECT 选项
Azure Synapse Analytics 中无服务器 SQL 池的拒绝选项处于预览状态。
此选项只能用于类型为 HADOOP 的外部数据源。
可以指定用于确定 PolyBase 如何处理它从外部数据源检索的脏记录的拒绝参数。 如果实际数据类型或列数与外部表的列定义不匹配,则数据记录被视为“脏”记录。
未指定或更改拒绝值时,PolyBase 会使用默认值。 使用 CREATE EXTERNAL TABLE 语句创建外部表时,有关拒绝参数的此信息会存储为附加元数据。 在将来的 SELECT 语句或 SELECT INTO SELECT 语句从外部表中选择数据时,PolyBase 会使用拒绝选项确定在实际查询失败之前可以拒绝的行数或行百分比。 查询会返回(部分)结果,直到超出拒绝阈值。 查询随后失败,并出现相应的错误消息。
PARSER_VERSION 格式选项仅在无服务器 SQL 池中受支持。
REJECT_TYPE = value | percentage
说明 REJECT_VALUE 选项是指定为文本值还是百分比。
value
REJECT_VALUE 是文本值,而非百分比。 当拒绝的行数超过 reject_value 时,PolyBase 查询会失败。
例如,如果 REJECT_VALUE = 5 并且 REJECT_TYPE = value,则 PolyBase SELECT 查询会在拒绝了 5 行之后失败。
percentage
REJECT_VALUE 是百分比,而非文本值。 当失败行的百分比超过 reject_value 时,PolyBase 查询会失败。 每隔一段时间计算失败行的百分比。
REJECT_VALUE = reject_value
指定在查询失败之前可以拒绝的行数的值或百分比。
- 对于 REJECT_TYPE = value,reject_value 必须是介于 0 与 2,147,483,647 之间的整数。
- 对于 REJECT_TYPE = percentage,reject_value 必须是介于 0 与 100 之间的浮点数。 百分比仅对专用 SQL 池有效,其中
TYPE=HADOOP。
当拒绝的行数超过 reject_value 时,此查询会失败。 例如,如果 REJECT_VALUE = 5 且 REJECT_TYPE = value,则 SELECT 查询将在拒绝五行后失败。
REJECT_SAMPLE_VALUE = reject_sample_value
当指定 REJECT_TYPE = percentage 时,此属性是必需的。 它确定在 PolyBase 重新计算拒绝的行的百分比之前要尝试检索的行数。
Reject_sample_value 参数必须是介于 0 与 2,147,483,647 之间的整数。
例如,如果 REJECT_SAMPLE_VALUE = 1000,则 PolyBase 会在尝试从外部数据文件导入 1000 行后计算失败行的百分比。 如果失败行的百分比小于 reject_value,则 PolyBase 会尝试检索另外 1000 行。 它在尝试导入每个另外 1000 行后会继续重新计算失败行的百分比。
注意
由于 PolyBase 按间隔计算失败行的百分比,因此失败行的实际百分比可能会超过 reject_value。
示例:
此示例演示三个 REJECT 选项相互之间如何交互。 例如,如果 REJECT_TYPE = percentage、REJECT_VALUE = 30、REJECT_SAMPLE_VALUE = 100,可能出现以下情况:
- PolyBase 尝试检索前 100 行;25 行失败,75 行成功。
- 失败行的百分比计算结果为 25%,小于 30% 的拒绝值。 因此,PolyBase 会继续从外部数据源检索数据。
- PolyBase 尝试加载下一个 100 行;这次 25 行成功,75 行失败。
- 重新计算的失败行的百分比为 50%。 失败行的百分比已超过 30% 的拒绝值。
- 在尝试返回前 200 行之后,PolyBase 查询失败,拒绝的行为 50%。 请注意,匹配行在 PolyBase 查询检测到超过拒绝阈值之前已返回。
REJECTED_ROW_LOCATION = 目录位置
指定应该写入拒绝行和对应错误文件的外部数据源中的目录。
如果指定路径不存在,将进行创建。 创建名称为“_rejectedrows”的子目录。 除非在位置参数中明确命名,否则,“_”字符将确保对该目录转义以进行其他数据处理。
- 在无服务器 SQL 池中,路径为
YearMonthDay_HourMinuteSecond_StatementID。 可以使用语句 ID 将文件夹与生成它的查询相关联。 - 在专用 SQL 池中,创建的路径基于格式为
YearMonthDay -HourMinuteSecond的加载提交时间,例如20180330-173205。
在此文件夹中,将写入两种文件类型,_reason 文件和数据文件。
有关详细信息,请参阅 CREATE EXTERNAL DATA SOURCE。
原因文件和数据文件均包含与 CTAS 语句关联的 queryID。 因为数据和原因位于单独的文件中,相应的文件具有匹配的后缀。
在无服务器 SQL 池中,error.json 文件包含一个 JSON 数组,其中包含与被拒绝的行相关的错误。 表示错误的每个元素都包含以下属性:
| Attribute | 说明 |
|---|---|
| 错误 | 拒绝行的原因。 |
| 行 | 文件中拒绝的行序号。 |
| 列 | 拒绝的列序号。 |
| 值 | 拒绝的列值。 如果值大于 100 个字符,则只显示前 100 个字符。 |
| 文件 | 行所属的文件的路径。 |
权限
需要以下用户权限:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
注意
仅创建 MASTER KEY、DATABASE SCOPED CREDENTIAL 和 EXTERNAL DATA SOURCE 时需要 CONTROL DATABASE 权限
请注意,创建外部数据源的登录名必须有权对位于 Hadoop 或 Azure Blob 存储中的外部数据源进行读取和写入。
重要
ALTER ANY EXTERNAL DATA SOURCE 权限授予任何主体创建和修改任何外部数据源对象的能力,因此,它还授予访问数据库上所有数据库作用域凭据的能力。 必须将此权限视为高度特权,因此必须仅授予系统中受信任的主体。
错误处理。
执行 CREATE EXTERNAL TABLE 语句时,PolyBase 会尝试连接到外部数据源。 如果连接尝试失败,则该语句会失败且不会创建外部表。 由于 PolyBase 在使查询最终失败之前会重新尝试连接,因此命令需要一分钟或更多时间才会失败。
注解
在即席查询方案(例如 SELECT FROM EXTERNAL TABLE)中,PolyBase 会将从外部数据源检索的行存储在临时表中。 查询完成之后,PolyBase 会移除并删除临时表。 任何永久数据都不会存储在 SQL 表中。
相反,在导入方案(例如 SELECT INTO FROM EXTERNAL TABLE)中,PolyBase 会将从外部数据源检索的行作为永久数据存储在 SQL 表中。 当 PolyBase 检索外部数据时,会在查询执行期间创建新表。
PolyBase 可以将某些查询计算推送到 Hadoop 以提高查询性能。 此操作称为谓词下推。 若要启用它,请在 CREATE EXTERNAL DATA SOURCE 中指定 Hadoop 资源管理器位置选项。
可以创建许多引用相同或不同外部数据源的外部表。
请注意使用 UTF-8 排序规则的源数据。 对于使用 UTF-8 排序规则的任何源数据,必须在 CREATE EXTERNAL TABLE 语句中手动为每个 UTF-8 列提供非 UTF-8 排序规则。 这是因为 UTF-8 支持不会扩展到外部表。 尝试使用 UTF-8 排序规则创建外部表时,将收到 Unsupported collation 错误消息。 如果外部表的数据库排序规则是 UTF-8 排序规则,则外部表创建将失败,除非提供显式的非 UTF-8 列排序规则,例如 [UTF8_column] varchar(128) COLLATE LATIN1_GENERAL_100_CI_AS_KS_WS NOT NULL,。
Azure Synapse Analytics 中的无服务器和专用 SQL 池使用不同的代码库执行数据虚拟化。 无服务器 SQL 池支持本机数据虚拟化技术。 专用 SQL 池支持本机和 PolyBase 数据虚拟化。 使用 TYPE=HADOOP 创建 EXTERNAL DATA SOURCE 时,将使用 PolyBase 数据虚拟化。
限制和局限
外部表的数据不受 Azure Synapse 直接控制,这些数据可以随时通过外部进程进行更改或删除。 因此,针对外部表的查询结果不保证具有确定性。 相同查询可能会在每次针对外部表运行时返回不同结果。 同样,如果外部数据已移动或删除,则查询可能会失败。
可以创建各自引用不同外部数据源的多个外部表。
外部表上仅允许使用以下这些数据定义语言 (DDL) 语句:
- CREATE TABLE 和 DROP TABLE
- CREATE STATISTICS 和 DROP STATISTICS
- CREATE VIEW 和 DROP VIEW
不支持构造和操作:
- 外部表列上的 DEFAULT 约束
- 删除、插入和更新的数据操作语言 (DML) 操作
- 外部表列上的动态数据掩码
查询限制
建议每个文件夹不超过 30,000 个文件。 如果引用的文件过多,可能会出现 Java 虚拟机 (JVM) 内存不足异常或性能下降的问题。
表宽度限制
基于表定义中单个有效行的最大大小,Azure 数据仓库中的 PolyBase 具有 1 MB 的行宽限制。 如果列架构的总和大于 1 MB,则 PolyBase 无法查询数据。
数据类型限制
以下数据类型不能在 PolyBase 外部表中使用:
geographygeometryhierarchyidimagetextnTextxml- 任何用户定义类型
锁定
SCHEMARESOLUTION 对象上的共享锁。
示例
A. 将数据从 ADLS Gen 2 导入 Azure Synapse Analytics
有关 Gen ADLS Gen 1 的示例,请参阅创建外部数据源。
-- These values come from your Azure Active Directory Application used to authenticate to ADLS Gen 2.
CREATE DATABASE SCOPED CREDENTIAL ADLUser
WITH IDENTITY = '<clientID>@\<OAuth2.0TokenEndPoint>',
SECRET = '<KEY>' ;
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH (TYPE = HADOOP,
LOCATION = 'abfss://data@pbasetr.azuredatalakestore.net'
);
CREATE EXTERNAL FILE FORMAT TextFileFormat
WITH
(
FORMAT_TYPE = DELIMITEDTEXT
, FORMAT_OPTIONS ( FIELD_TERMINATOR = '|'
, STRING_DELIMITER = ''
, DATE_FORMAT = 'yyyy-MM-dd HH:mm:ss.fff'
, USE_TYPE_DEFAULT = FALSE
)
);
CREATE EXTERNAL TABLE [dbo].[DimProduct_external]
( [ProductKey] [int] NOT NULL,
[ProductLabel] nvarchar NULL,
[ProductName] nvarchar NULL )
WITH
(
LOCATION='/DimProduct/' ,
DATA_SOURCE = AzureDataLakeStore ,
FILE_FORMAT = TextFileFormat ,
REJECT_TYPE = VALUE ,
REJECT_VALUE = 0
);
CREATE TABLE [dbo].[DimProduct]
WITH (DISTRIBUTION = HASH([ProductKey] ) )
AS SELECT * FROM
[dbo].[DimProduct_external] ;
B. 将数据从 Parquet 导入 Azure Synapse Analytics
以下示例创建一个外部表。 然后它返回第一行:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
);
GO
SELECT TOP 1 * FROM census_external_table;
后续步骤
通过以下文章详细了解外部表和相关概念:
* Analytics
Platform System (PDW) *
概述:分析平台系统
使用外部表可:
- 通过 Transact-SQL 语句查询 Hadoop 或 Azure Blob 存储数据。
- 将数据从 Hadoop 或 Azure Blob 存储导入并存储到 Analytics Platform System 中。
另请参阅 CREATE EXTERNAL DATA SOURCE 和 DROP EXTERNAL TABLE。
语法
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
}
参数
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
要创建的表的一到三部分名称。 对于外部表,Analytics Platform System 仅存储表元数据以及有关 Hadoop 或 Azure Blob 存储中引用的文件或文件夹的基本统计信息。 在 Analytics Platform System 中不移动或存储任何实际数据。
重要
为了获得最佳性能,如果外部数据源驱动程序支持由三部分组成的名称,则强烈建议提供由三部分组成的名称。
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE 支持配置列名、数据类型、为 Null 性和排序规则的功能。 不能对外部表使用 DEFAULT CONSTRAINT。
列定义(包括数据类型和列数)必须与外部文件中的数据匹配。 如果存在不匹配,则在查询实际数据时会拒绝文件行。
LOCATION = 'folder_or_filepath'
为 Hadoop 或 Azure Blob 存储中的实际数据指定文件夹或文件路径和文件名。 位置从根文件夹开始。 根文件夹是外部数据源中指定的数据位置。
在 Analytics Platform System 中,如果路径和文件夹不存在,则 CREATE EXTERNAL TABLE AS SELECT 语句会进行创建。 CREATE EXTERNAL TABLE 不会创建路径和文件夹。
如果将 LOCATION 指定为一个文件夹,则从外部表中进行选择的 PolyBase 查询会从该文件夹及其所有子文件夹中检索文件。 正如 Hadoop 一样,PolyBase 不返回隐藏文件夹。 它也不返回文件名以下划线 (_) 或句点 (.) 开头的文件。
在下图示例中,如果 LOCATION='/webdata/',则 PolyBase 查询会从 mydata.txt 和 mydata2.txt 返回行。 它不会返回 mydata3.txt,因为它位于隐藏文件夹的子文件夹中。 它不返回 _hidden.txt,因为这是隐藏文件。
若要更改默认值并且只从根文件夹进行读取,请在 core-site.xml 配置文件中将属性 <polybase.recursive.traversal> 设置为“false”。 此文件位于 SQL Server 的 bin 根的 <SqlBinRoot>\PolyBase\Hadoop\Conf\ 下。 例如,C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn\。
DATA_SOURCE = external_data_source_name
指定包含外部数据位置的外部数据源的名称。 此位置是 Hadoop 或 Azure Blob 存储。 要创建外部数据源,请使用 CREATE EXTERNAL DATA SOURCE。
FILE_FORMAT = external_file_format_name
指定用于存储外部数据的文件类型和压缩方法的外部文件格式对象的名称。 若要创建外部文件格式,请使用 CREATE EXTERNAL FILE FORMAT。
拒绝选项
此选项只能用于类型为 HADOOP 的外部数据源。
可以指定用于确定 PolyBase 如何处理它从外部数据源检索的脏记录的拒绝参数。 如果实际数据类型或列数与外部表的列定义不匹配,则数据记录被视为“脏”记录。
未指定或更改拒绝值时,PolyBase 会使用默认值。 使用 CREATE EXTERNAL TABLE 语句创建外部表时,有关拒绝参数的此信息会存储为附加元数据。 在将来的 SELECT 语句或 SELECT INTO SELECT 语句从外部表中选择数据时,PolyBase 会使用拒绝选项确定在实际查询失败之前可以拒绝的行数或行百分比。 查询会返回(部分)结果,直到超出拒绝阈值。 查询随后失败,并出现相应的错误消息。
REJECT_TYPE = value | percentage
说明 REJECT_VALUE 选项是指定为文本值还是百分比。
value
REJECT_VALUE 是文本值,而非百分比。 当拒绝的行数超过 reject_value 时,PolyBase 查询会失败。
例如,如果 REJECT_VALUE = 5 并且 REJECT_TYPE = value,则 PolyBase SELECT 查询会在拒绝了 5 行之后失败。
percentage
REJECT_VALUE 是百分比,而非文本值。 当失败行的百分比超过 reject_value 时,PolyBase 查询会失败。 每隔一段时间计算失败行的百分比。
REJECT_VALUE = reject_value
指定在查询失败之前可以拒绝的行数的值或百分比。
对于 REJECT_TYPE = value,reject_value 必须是介于 0 与 2,147,483,647 之间的整数。
对于 REJECT_TYPE = percentage,reject_value 必须是介于 0 与 100 之间的浮点数。
REJECT_SAMPLE_VALUE = reject_sample_value
当指定 REJECT_TYPE = percentage 时,此属性是必需的。 它确定在 PolyBase 重新计算拒绝的行的百分比之前要尝试检索的行数。
Reject_sample_value 参数必须是介于 0 与 2,147,483,647 之间的整数。
例如,如果 REJECT_SAMPLE_VALUE = 1000,则 PolyBase 会在尝试从外部数据文件导入 1000 行后计算失败行的百分比。 如果失败行的百分比小于 reject_value,则 PolyBase 会尝试检索另外 1000 行。 它在尝试导入每个另外 1000 行后会继续重新计算失败行的百分比。
注意
由于 PolyBase 按间隔计算失败行的百分比,因此失败行的实际百分比可能会超过 reject_value。
示例:
此示例演示三个 REJECT 选项相互之间如何交互。 例如,如果 REJECT_TYPE = percentage、REJECT_VALUE = 30、REJECT_SAMPLE_VALUE = 100,可能出现以下情况:
- PolyBase 尝试检索前 100 行;25 行失败,75 行成功。
- 失败行的百分比计算结果为 25%,小于 30% 的拒绝值。 因此,PolyBase 会继续从外部数据源检索数据。
- PolyBase 尝试加载下一个 100 行;这次 25 行成功,75 行失败。
- 重新计算的失败行的百分比为 50%。 失败行的百分比已超过 30% 的拒绝值。
- 在尝试返回前 200 行之后,PolyBase 查询失败,拒绝的行为 50%。 请注意,匹配行在 PolyBase 查询检测到超过拒绝阈值之前已返回。
权限
需要以下用户权限:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
- CONTROL DATABASE
请注意,创建外部数据源的登录名必须有权对位于 Hadoop 或 Azure Blob 存储中的外部数据源进行读取和写入。
重要
ALTER ANY EXTERNAL DATA SOURCE 权限授予任何主体创建和修改任何外部数据源对象的能力,因此,它还授予访问数据库上所有数据库作用域凭据的能力。 必须将此权限视为高度特权,因此必须仅授予系统中受信任的主体。
错误处理。
执行 CREATE EXTERNAL TABLE 语句时,PolyBase 会尝试连接到外部数据源。 如果连接尝试失败,则该语句会失败且不会创建外部表。 由于 PolyBase 在使查询最终失败之前会重新尝试连接,因此命令需要一分钟或更多时间才会失败。
注解
在即席查询方案(例如 SELECT FROM EXTERNAL TABLE)中,PolyBase 会将从外部数据源检索的行存储在临时表中。 查询完成之后,PolyBase 会移除并删除临时表。 任何永久数据都不会存储在 SQL 表中。
相反,在导入方案(例如 SELECT INTO FROM EXTERNAL TABLE)中,PolyBase 会将从外部数据源检索的行作为永久数据存储在 SQL 表中。 当 PolyBase 检索外部数据时,会在查询执行期间创建新表。
PolyBase 可以将某些查询计算推送到 Hadoop 以提高查询性能。 此操作称为谓词下推。 若要启用它,请在 CREATE EXTERNAL DATA SOURCE 中指定 Hadoop 资源管理器位置选项。
可以创建许多引用相同或不同外部数据源的外部表。
限制和局限
外部表的数据不受设备直接控制,这些数据可以随时通过外部进程进行更改或删除。 因此,针对外部表的查询结果不保证具有确定性。 相同查询可能会在每次针对外部表运行时返回不同结果。 同样,如果外部数据已移动或删除,则查询可能会失败。
可以创建各自引用不同外部数据源的多个外部表。 如果同时针对不同 Hadoop 数据源运行查询,则每个 Hadoop 源都必须使用相同的“hadoop 连接”服务器配置设置。 例如,不能同时针对 Cloudera Hadoop 群集和 Hortonworks Hadoop 群集运行查询,因为这些群集使用不同的配置设置。 有关配置设置和受支持的组合,请参阅 PolyBase 连接配置。
外部表上仅允许使用以下这些数据定义语言 (DDL) 语句:
- CREATE TABLE 和 DROP TABLE
- CREATE STATISTICS 和 DROP STATISTICS
- CREATE VIEW 和 DROP VIEW
不支持构造和操作:
- 外部表列上的 DEFAULT 约束
- 删除、插入和更新的数据操作语言 (DML) 操作
- 外部表列上的动态数据掩码
查询限制
运行 32 个并发 PolyBase 查询时,每个文件夹中 PolyBase 最多可使用 33000 个文件。 此最大数量包括每个 HDFS 文件夹中的文件和子文件夹。 如果并发度小于 32,用户可以针对 HDFS 中包含超过 33000 个文件的文件夹运行 PolyBase 查询。 建议保持外部文件路径简短,并且每个 HDFS 文件夹不超过 30000 个文件。 当引用太多文件时,可能会发生 Java 虚拟机 (JVM) 内存不足异常。
表宽度限制
基于表定义中单个有效行的最大大小,SQL Server 2016 中的 PolyBase 具有 32 KB 的行宽限制。 如果列架构的总和大于 32 KB,则 PolyBase 无法查询数据。
在 Azure Synapse Analytics 中,此限制已提高到 1 MB。
数据类型限制
以下数据类型不能在 PolyBase 外部表中使用:
geographygeometryhierarchyidimagetextnTextxml- 任何用户定义类型
锁定
SCHEMARESOLUTION 对象上的共享锁。
安全性
外部表的数据文件存储在 Hadoop 或 Azure Blob 存储中。 这些数据文件由你自己的进程进行创建和管理。 由你负责管理外部数据的安全。
示例
A. 将 HDFS 数据与 Analytics Platform System 数据连接起来
SELECT cs.user_ip FROM ClickStream cs
JOIN [User] u ON cs.user_ip = u.user_ip
WHERE cs.url = 'www.microsoft.com';
B. 将行数据从 HDFS 导入分布式 Analytics Platform System 表中
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = HASH (url) )
AS SELECT url, event_date, user_ip FROM ClickStream;
C. 将行数据从 HDFS 导入复制的 Analytics Platform System 表中
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = REPLICATE )
AS SELECT url, event_date, user_ip
FROM ClickStream;
后续步骤
通过以下文章详细了解 Analytics Platform System 中的外部表:
* Azure SQL 托管实例 *
概述:Azure SQL 托管实例
在 Azure SQL 托管实例中创建外部数据表。 有关完整信息,请参阅 Azure SQL 托管实例的数据虚拟化。
借助 Azure SQL 托管实例的数据虚拟化功能,可访问 Azure Data Lake Storage Gen2 或 Azure Blob 存储中各种文件格式的外部数据,并可使用 T-SQL 语句查询这些数据,甚至可使用联接将数据与本地存储的关系数据进行合并。
另请参阅 CREATE EXTERNAL DATA SOURCE 和 DROP EXTERNAL TABLE。
语法
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
参数
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
要创建的表的一到三部分名称。 对于外部表,仅需要表元数据以及有关 Azure Data Lake 或 Azure Blob 存储中引用的文件或文件夹的基本统计信息。 创建外部表时,不会移动或存储任何实际数据。
重要
为了获得最佳性能,如果外部数据源驱动程序支持由三部分组成的名称,则强烈建议提供由三部分组成的名称。
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE 支持配置列名、数据类型、为 Null 性和排序规则的功能。 不能对外部表使用 DEFAULT CONSTRAINT。
列定义(包括数据类型和列数)必须与外部文件中的数据匹配。 如果存在不匹配,则在查询实际数据时会拒绝文件行。
LOCATION = 'folder_or_filepath'
为 Azure Data Lake 或 Azure Blob 存储中的实际数据指定文件夹或文件路径和文件名。 位置从根文件夹开始。 根文件夹是外部数据源中指定的数据位置。 CREATE EXTERNAL TABLE 不会创建路径和文件夹。
如果将 LOCATION 指定为一个文件夹,则从外部表选择的 Azure SQL 托管实例中的查询会从该文件夹中检索文件,而不是从其所有子文件夹中检索文件。
Azure SQL 托管实例在子文件夹或隐藏文件夹中找不到文件。 它也不返回文件名以下划线 (_) 或句点 (.) 开头的文件。
在下图示例中,如果 LOCATION='/webdata/',则查询会从 mydata.txt 返回行。 它不会返回 mydata2.txt,因为它位于子文件夹中;它不会返回 mydata3.txt,因为它位于隐藏文件夹中;并且,它也不会返回 _hidden.txt,因为它是隐藏的文件。
DATA_SOURCE = external_data_source_name
指定包含外部数据位置的外部数据源的名称。 此位置位于 Azure Data Lake 中。 要创建外部数据源,请使用 CREATE EXTERNAL DATA SOURCE。
FILE_FORMAT = external_file_format_name
指定用于存储外部数据的文件类型和压缩方法的外部文件格式对象的名称。 若要创建外部文件格式,请使用 CREATE EXTERNAL FILE FORMAT。
权限
需要以下用户权限:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
注意
仅创建 MASTER KEY、DATABASE SCOPED CREDENTIAL 和 EXTERNAL DATA SOURCE 时需要 CONTROL DATABASE 权限
请注意,创建外部数据源的登录名必须有权对位于 Hadoop 或 Azure Blob 存储中的外部数据源进行读取和写入。
重要
ALTER ANY EXTERNAL DATA SOURCE 权限授予任何主体创建和修改任何外部数据源对象的能力,因此,它还授予访问数据库上所有数据库作用域凭据的能力。 必须将此权限视为高度特权,因此必须仅授予系统中受信任的主体。
备注
在即席查询方案(例如 SELECT FROM EXTERNAL TABLE)中,从外部数据源检索的行存储在临时表中。 查询完成后,将删除这些行和临时表。 任何永久数据都不会存储在 SQL 表中。
相反,在导入方案(例如 SELECT INTO FROM EXTERNAL TABLE)中,从外部数据源检索的行作为永久数据存储在 SQL 表中。 检索外部数据时,会在查询执行期间创建新表。
目前,Azure SQL 托管实例的数据虚拟化是只读的。
可以创建许多引用相同或不同外部数据源的外部表。
限制和局限
外部表的数据不受 Azure SQL 托管实例直接控制,这些数据可以随时通过外部进程进行更改或删除。 因此,针对外部表的查询结果不保证具有确定性。 相同查询可能会在每次针对外部表运行时返回不同结果。 同样,如果外部数据已移动或删除,则查询可能会失败。
可以创建各自引用不同外部数据源的多个外部表。
外部表上仅允许使用以下这些数据定义语言 (DDL) 语句:
- CREATE TABLE 和 DROP TABLE
- CREATE STATISTICS 和 DROP STATISTICS
- CREATE VIEW 和 DROP VIEW
不支持构造和操作:
- 外部表列上的 DEFAULT 约束
- 删除、插入和更新的数据操作语言 (DML) 操作
表宽度限制
1 MB 的行宽限制基于表定义中单个有效行的最大大小。 如果列架构的总和大于 1 MB,数据虚拟化查询将失败。
数据类型限制
以下数据类型不能在 Azure SQL 托管实例的外部表中使用:
geographygeometryhierarchyidimagetextnTextxml- 任何用户定义类型
锁定
SCHEMARESOLUTION 对象上的共享锁。
示例
A. 使用外部表从 Azure SQL 托管实例查询外部数据
有关更多示例,请参阅创建外部数据源或 Azure SQL 托管实例的数据虚拟化。
创建数据库主密钥(如果不存在)。
-- Optional: Create MASTER KEY if it doesn't exist in the database: CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Strong Password>' GO使用 SAS 令牌创建数据库范围的凭据。 还可使用托管标识。
CREATE DATABASE SCOPED CREDENTIAL MyCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<KEY>' ; --Removing leading '?' GO使用凭据创建外部数据源。
--Create external data source pointing to the file path, and referencing database-scoped credential: CREATE EXTERNAL DATA SOURCE MyPrivateExternalDataSource WITH ( LOCATION = 'abs://public@pandemicdatalake.blob.core.windows.net/curated/covid-19/bing_covid-19_data/latest' CREDENTIAL = [MyCredential] ) GO创建 EXTERNAL FILE FORMAT 和 EXTERNAL TABLE 来查询数据,就像它是本地表一样。
-- Or, create an EXTERNAL FILE FORMAT and an EXTERNAL TABLE --Create external file format CREATE EXTERNAL FILE FORMAT DemoFileFormat WITH ( FORMAT_TYPE=PARQUET ) GO --Create external table: CREATE EXTERNAL TABLE tbl_TaxiRides( vendorID VARCHAR(100) COLLATE Latin1_General_BIN2, tpepPickupDateTime DATETIME2, tpepDropoffDateTime DATETIME2, passengerCount INT, tripDistance FLOAT, puLocationId VARCHAR(8000), doLocationId VARCHAR(8000), startLon FLOAT, startLat FLOAT, endLon FLOAT, endLat FLOAT, rateCodeId SMALLINT, storeAndFwdFlag VARCHAR(8000), paymentType VARCHAR(8000), fareAmount FLOAT, extra FLOAT, mtaTax FLOAT, improvementSurcharge VARCHAR(8000), tipAmount FLOAT, tollsAmount FLOAT, totalAmount FLOAT ) WITH ( LOCATION = 'yellow/puYear=*/puMonth=*/*.parquet', DATA_SOURCE = NYCTaxiExternalDataSource, FILE_FORMAT = MyFileFormat ); GO --Then, query the data via an external table with T-SQL: SELECT TOP 10 * FROM tbl_TaxiRides; GO
后续步骤
通过以下文章详细了解外部表和相关概念:
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈